索引
- 用 Rust 学习解析器组合器
- 用 Rust 编写 LLVM 的玩具前端
- 使用 nom 解析 url
- Rust 中异步编程实用介绍
- tokio 内幕-自底向上理解 Rust 的异步 IO 框架
- 「转」Rust 中的 Arenas
- 「转」Rust 异步 IO: 从 mio 到 coroutine
- 「转」图解 Rust 所有权与生命周期
- Rust 异步执行器
- 「转」Rust 标准库特征指南
- Rust中的宏: 带有示例的教程
- libp2p 教程: 使用 Rust 构建 p2p 应用
- 「转」Rust 的 Pin 与 Unpin
- 使用 GDB 调试 Rust 中的应用
- 解释 Rust 中的原子性
- Rust 和 TUI:在 Rust 中构建命令行界面
- 在 Android 中运行 Rust
- 「转」Rust 中常见的有关生命周期的误解
- 生命周期型变示例
- Rust 如何实现线程安全
- 无需 fork Clippy 就可以编写 Rust lint
- 使用 Mio 编写底层 TCP 服务器
- 「转」Unsafe Rust 的取舍
- Rust 中的类型强制转换
标准库文档翻译
用 Rust 学习解析器组合子 (combinator)
原文 / 译者: iamazy, Matrixtang
本文向已是 Rust 程序员的人们传授解析器组合子的基础知识。它假定不涉及其他知识,并将解释与 Rust 没有直接关系的所有内容,以及为达到此目的使用 Rust 的一些令人意外的特性。如果你不了解 Rust,他不会教你 Rust 的内容,但是这样的话,同样也无法更好的教你解析器和组合子的知识。如果你想要学习 Rust 语言,我推荐 Rust 编程语言 这本书。
Beginner's Mind
当每个程序员发现自己需要解析器时,它们的生活将变得有意义。
初级程序员将会问:“什么是解析器?”。
中级程序员将会说:“这很简单,我将写一串正则表达式”。
高级程序员将会说:“退一步考虑问题,我知道Lex(词法分析器)和Yacc(语法解析器)”
初级程序员的想法是正确的。
不是说正则表达式不好(但是请不要用正则表达式写复杂的解析器)。使用经过 数千年 (millennia) 磨练至完美的解析器和词法分析生成器之类的强大工具并不是没有乐趣可言。但是从头开始一点一点学习解析器将更有趣。这两者只是对当前实际问题的抽象,如果你直接选择正则表达式或者解析器生成工具,你将失去这一份乐趣。在初学者眼中,正如人们说的:本来(解决这个问题)有很多种方法,但是在专家眼里,已经形成思维定视,只会选择一种他们最习惯的方式。
在本文中我们将从头开始学习如何构建解析器,基于被称为解析器组合子的函数式编程语言的通用技术。一旦你掌握了它们的基本概念,它们的优势将非常巨大,同时又非常接近第一原理。因为这里唯一的抽象是你将在基础的组合子之上构建你自己的抽象。所有这些,你必须先构建它们,才能使用它们。
How To Work Through This Article
强烈建议你初始化一个 Rust 项目,并且在src/lib.rs中书写你阅读到的代码片段(你可以直接从页面上直接复制,但是最好还是自己手敲,因为这样会自动确保你完整阅读代码)。本文将按序介绍你需要的每段代码。请注意,有时会引入你先前编写功能的最新版本,这时,你需要将旧版本替换为新版本。
该代码是使用 2018 年语言版本的rustc的 1.34.0 版本编写的。你应该尽可能使用最新版本的编译器,只要你确保你使用的是 2018 的版本即可(检查Cargo.toml文件中是否包含edition = "2018")。代码不需要任何的外部依赖。
如果要运行本文中的测试用例,请执行cargo test。
The Xcruciating Markup Language
我们将用简化的 XML 格式写一个解析器,如下所示:
<parent-element>
<single-element attribute="value" />
</parent-element>
XML 元素使用<符号开头和一个由字母组成的标志符开头,后面可以根任意数量的字母,数字和-。后面跟一些空格,以及一些属性对的可选列表:前面定义一个标识符,后面跟一个=符号和一个双引号字符串,最后以/>结尾来表示一个没有子节点的单个元素。或者用>表示后面跟了一串子节点,最终是一个以</开头的结束标签,后跟一个必须与开始标识匹配的标志符,然后以>结束。
这就是我们将要支持的特性。没有命名空间,没有文本节点,其余的都没有,并且没有模式校验。我们甚至都不会自寻烦恼,去实现字符串的转义引号(\") - 它们由第一个双引号开始,到下一个双引号结束,就是这样。如果你想在实际字符串中使用双引号,你可以将这个不合理的要求转移到其他地方。
我们将用下面的结构体来解析这些元素。
#![allow(unused)] fn main() { #[derive(Clone, Debug, PartialEq, Eq)] struct Element { name: String, attributes: Vec<(String, String)>, children: Vec<Element>, } }
没有花哨的类型,仅仅用字符串表示名称(那是每个标签开始的标志符),用字符串元组表示属性(标志符和对应的值),还有一个看起来和父元素完全一样的子元素列表。
(如果你正在输入,请加上那一系列的derive,你将在后面用到它们)。
Defining The Parser
好了,是时候编写解析器了。
解析是从数据流中派生结构的过程。解析器就是要弄清楚该结构的工具。
在我们即将探索的知识中,解析器最简单的一种形式就是一个函数,该函数接受一些输入并返回解析后的输出以及输入的其余部分,或者是一个错误信息:“我无法解析该输入”。
事实证明,简而言之,更复杂的解析器看起来也是如此。如果你要获取友好的错误提示,你可能会使输入,输出和错误的含义复杂化,但是解析器的特征依然如此:消费输入并产生解析后的数据以及输入的其余部分,或者会让你知道无法将输入解析成输出。
让我们将其(解析器)写成函数的形式。
#![allow(unused)] fn main() { Fn(Input) -> Result<(Input, Output), Error> }
更具体的说,就我们而言,我们希望可以填充这些类型,就像下面代码块所示。因为我们要做的是将一个字符串转化为Element结构体,并且在这方面我们不想陷入错综复杂的错误提示中,所以当我们不能够解析输入的字符串时,只需返回一段提示错误的字符串即可。
#![allow(unused)] fn main() { Fn(&str) -> Result<(&str, Element), &str> }
我们使用字符串切片(&str),是因为他是指向字符串的有效指针。我们可以进一步对其进行切片,通过切掉已解析的部分来消耗输入,并将余下的输入和结果一起返回。
可能使用&[u8]类型作为输入(一串字节数组,如果将输入的字节限制在ASCII范围内,则u8和char相对应)会看起来更加干净,尤其是字符串切片(&str)的行为和大多数切片的行为有所不同。你不能够通过一个数字来检索它们,你必须使用一个分片input[0..1]。另一方面,它们对于解析字符串有很多有用的函数,而字节切片没有。
事实上,我们通常都需要依赖这些函数而不是像input[0]这样对他进行索引。因为 Rust 的字符串是UTF-8格式的,这些索引并不总是对应于单个字符,所以对于我们来说,让标准库为我们处理这些问题更好。
Our First Parser
让我们来一起写一个解析器,只需要关注字符串中的第一个字符并判断它是否是字母a
#![allow(unused)] fn main() { fn the_letter_a(input: &str) -> Result<(&str, ()), &str> { match input.chars().next() { Some('a') => Ok((&input['a'.len_utf8()..], ())), _ => Err(input), } } }
首先,我们来看一下输入和输入和输出的类型:和上面讨论的一样,我们让字符串切片作为输入,并返回携带(&str, ())元组或者错误类型&str的Result。(&str, ())元组比较有趣:正如我们所说的,我们想要返回一个包含下一次待解析的输入和输出。&str是下一次输入,解析返回的结果仅仅是一个单元类型()。因为如果解析成功,只可能有一种结果(我们找到了字母a),但是这里我们并不需要返回字母a,我们只需要告诉调用者我们成功发现了字母a即可。
然后,让我们看下解析器本身的代码。我们从提取输入的第一个字符开始:input.chars().next()。依靠标准库来避免带来的 Unicode 编码问题并不是在开玩笑 - 我们要求它为字符串的字符提供一个chars()迭代器,然后从中取出第一项。该项是封装在Option中的char类型,因此是Option<char>,如果它的值为None则表示我们尝试在空字符串中提取一个char。
更糟的是,char可能并不是你想的那样是 Unicode 字符。它很可能就是 Unicode 所说的“字素簇”,它可以由几个char组成,实际上代表“标量值”,大约比字素簇低两级。但是这种方式太疯狂了,出于我们(讲解)的目的,我们可能根本不会看到除 ASCII 之外的字符集,所以这种情况我们不做讨论。
我们模式匹配上了Some('a'),这是我们正在寻找的特定结果,如果匹配上,则返回结果Ok((&input['a'.len_utf8()..], ()))。也就是说,我们在字符串切片中删除了刚刚解析的'a'并返回剩余部分以及我们的解析结果(一个空的())。考虑到 Unicode 怪物,我们在切片之前向标准库询问了'a'在 UTF-8 编码中的长度,但是,请永远不要假设 Unicode 怪物。
如果我们匹配到其他的Some(char)或者None,我们将返回一个错误。你可能还记得,我们的错误类型目前还是解析失败时的字符串切片,也就是作为input传入的字符串切片。它不以'a'开头,因此这是我们的错误。但这不是一个大的错误,但是至少比“其他地方出了问题”要好一些。
虽然我们不需要使用此解析器解析 XML,但是我们要做的第一件事就是查找<,因此我们可能需要一些相似的东西。我们还需要专门解析>,/,=,因此我们可以创建一个函数为我们想要的字符构建一个解析器?
A Parser Builder
我们想象一下:编写一个函数,可以为任意长度的静态字符串(而不仅仅是单个字符)生成一个解析器。这种方式甚至更容易,因为一个字符串切片已经是一个合法的 UTF-8 字符串切片,我们不需要再去考虑 Unicode 怪物。
#![allow(unused)] fn main() { fn match_literal(expected: &'static str) -> impl Fn(&str) -> Result<(&str, ()), &str> { move |input| match input.get(0..expected.len()) { Some(next) if next == expected => { Ok((&input[expected.len()..], ())) } _ => Err(input), } } }
这个函数看起来有点不同。
我们先看下类型。我们的函数看起来不再像是一个解析器,它将我们期望的字符串作为参数,并返回一个看似解析器的东西。它是一个返回函数的函数 - 换言之,是一个高阶函数。基本上,我们在编写一个函数,该函数可以构建一个类似之前的the_letter_a函数。
因此,我们不是在函数体中完成工作,而是返回一个闭包用来处理这些事情,该闭包与我们之前解析器的类型签名相匹配。
模式匹配看起来是一样的,除了我们不能直接匹配字符串字面量,因为我们不知道它具体是什么,所以我们使用匹配条件if next == expected代替。否则它和以前完全一样,只是在闭包的主体内。
Testing Our Parser
我们来为它编写测试用例,确保这个函数没有问题。
#![allow(unused)] fn main() { #[test] fn literal_parser() { let parse_joe = match_literal("Hello Joe!"); assert_eq!( Ok(("", ())), parse_joe("Hello Joe!") ); assert_eq!( Ok((" Hello Robert!", ())), parse_joe("Hello Joe! Hello Robert!") ); assert_eq!( Err("Hello Mike!"), parse_joe("Hello Mike!") ); } }
首先,我们构建了一个解析器:match_literal("Hello Joe!")。它应该消耗字符串"Hello Joe!"并返回字符串的剩余部分,或者失败并返回整个字符串。
在第一种情况下,我们为它提供了它期望的确切字符串,并看到它返回了一个空字符串以及()值,这表示“我们解析了期望的字符串,并且不需要将它真的返回”。
在第二种情况下,我们提供了字符串"Hello Joe! Hello Robert!",并且我们看到它确实消耗了字符串"Hello Joe!"并且返回了输入字符串的剩余部分:"Hello Robert!"(包括空格)。
在第三种情况下,我们提供了一个不正确的输入"Hello Mike!",并注意到该函数拒绝了这个输入并返回了一个错误。不是说 Mike 作为一般规则是不正确的,而是它不是此解析器所需要的。
Exercises
- 你能在标准库中找到一个关于
str类型的方法,让你编写match_literal()时不必做麻烦的get索引吗?
A Parser For Something Less Specific
我们可以继续解析<,>,=以及</和/>。我们几乎已经完成了。
<之后需要识别的部分是元素名称。我们不能通过简单的字符串比较做到这一点。但是我们可以使用正则表达式。
但是我们需要克制一下自己,这将是一个很容易在简单代码中复用的正则表达式,我们不需要为此引入regex库。让我们尝试一下是否可以只使用 Rust 标准库来编写自己的解析器。
回顾元素名称标志符的规则:首位是字母,后跟零个或多个字母,数字或-。
#![allow(unused)] fn main() { fn identifier(input: &str) -> Result<(&str, String), &str> { let mut matched = String::new(); let mut chars = input.chars(); match chars.next() { Some(next) if next.is_alphabetic() => matched.push(next), _ => return Err(input), } while let Some(next) = chars.next() { if next.is_alphanumeric() || next == '-' { matched.push(next); } else { break; } } let next_index = matched.len(); Ok((&input[next_index..], matched)) } }
与往常一样,我们首先查看类型。这次我们不是编写函数来构建解析器,只需要编写解析器本身,就像第一次一样。这里显著的区别是,我们返回元组中的String和剩余的输入,而不是()的结果类型。这个String将包含我们刚刚解析的标志符。
考虑到这一点,我们首先创建一个空字符串并将称之为matched。它是我们将要返回的结果值。我们在input中获取一个字符的迭代器,我们将对其进行拆解。
第一步是查看前面是否有字母。我们从迭代器中取出第一个字符并检查它是否是一个字母:next.is_alphabetic()。Rust 标准库当然是帮我们来处理 Unicode 的 - 这将匹配任何字母表中的字母,而不仅仅是 ASCII。如果它是一个字母,我们将它放入我们的matched字符串中,如果不是,显然我们不是在查看元素标志符,所以我们立即返回一个错误。
第二步,我们不断从迭代器中取出字符,将它们放入我们正在构建的字符串中,直到我们找到一个既不是is_alphanumeric()(就像是is_alphabetic(),它只是不能匹配字母表中的任何数字)也不是破折号'-'的字符。
当我们第一次看到不符合这些条件的字符时,意味着我们已经完成了解析,所以我们跳出循环并返回我们构建的String,记住去掉我们在input中消耗的字符。如果迭代器用完了字符,意味着我们到达了input的末尾。
值得注意的是,当我们看到不是字母数字 (alphanumeric) 或破折号(-)的内容时,我们不会返回错误。一旦我们匹配了第一个字母,我们就已经有足够的东西来创建一个有效的标志符。而且在我们解析完标志符以后,输入字符串中有更多待解析的字符是非常正常的,所以我们只是停止解析并返回我们的结果,只有当我们找不到第一个字母时,我们才真正的返回错误,因为在这种情况下,肯定没有标志符。
还记得我们要将 XML 文档解析成的Element结构吗?
#![allow(unused)] fn main() { struct Element { name: String, attributes: Vec<(String, String)>, children: Vec<Element>, } }
我们实际上只是完成了解析器的第一部分,name字段。我们解析器返回的字符串就在那里。它也是解析每个attribute第一部分需要的解析器。
让我们对其进行测试。
#![allow(unused)] fn main() { #[test] fn identifier_parser() { assert_eq!( Ok(("", "i-am-an-identifier".to_string())), identifier("i-am-an-identifier") ); assert_eq!( Ok((" entirely an identifier", "not".to_string())), identifier("not entirely an identifier") ); assert_eq!( Err("!not at all an identifier"), identifier("!not at all an identifier") ); } }
我们可以在第一种情况中看到,字符串"i-am-an-identifier"被完整解析,只留下空的字符串。在第二种情况中,解析器返回"not"作为标志符,并且字符串的剩余部分作为剩余的输入返回。在第三种情况中,解析彻底 (outright) 失败,因为它找到的第一个字符不是字母。
Combinators
现在,我们已经可以解析<,以及之后的标志符了,但是我们需要同时将它们进行解析,以便在这里可以取得进展。因此接下来将编写另一个解析器的构造函数,它将两个解析器作为输入并返回一个新的解析器,并按顺序解析它们。换言之,它是一个解析器组合子,因为它将两个解析器组合成一个新的解析器。让我们看看我们是否能够做到这一点。
#![allow(unused)] fn main() { fn pair<P1, P2, R1, R2>(parser1: P1, parser2: P2) -> impl Fn(&str) -> Result<(&str, (R1, R2)), &str> where P1: Fn(&str) -> Result<(&str, R1), &str>, P2: Fn(&str) -> Result<(&str, R2), &str>, { move |input| match parser1(input) { Ok((next_input, result1)) => match parser2(next_input) { Ok((final_input, result2)) => Ok((final_input, (result1, result2))), Err(err) => Err(err), }, Err(err) => Err(err), } } }
这里有点复杂,但是你知道该怎么做:从查看类型开始。
首先,我们有四种类型变量:P1,P2,R1以及R2。这是 Parser1,Parser2,Result1,Result2 的缩写。P1,P2是函数,你会注意到它们遵循解析器函数的既定模式 (established pattern):就像返回值,它们将&str作为输入并返回一个Result类型,该Result类型可能是一个包含剩余输入以及解析结果的二元组,或者是一个错误。
但是查看每个函数的结果类型:P1如果解析成功,将会产生R1,P2同理会产生R2。最终解析器的结果 - 从我们的函数返回的结果 - 是(R1, R2)。因此该解析器的工作是先在输入上运行解析器P1,然后在P1返回的剩余输入上运行P2,如果这两个解析器都执行成功,则我们将两个解析器返回的结果组合进元组(R1, R2)。
查看代码,我们看到这也正是它所做得。我们首先在输入上运行第一个解析器,然后是第二个解析器,接着将两个结果组合成一个元组并返回。如果这些解析器中的任何一个执行失败,我们会立即返回它给出的错误。
这样,我们应该能够结合之前的两个解析器match_literal和identifier来实际解析 XML 标签的第一部分(<my-first-element/>)。让我们编写测试用例看它是否正确。
#![allow(unused)] fn main() { #[test] fn pair_combinator() { let tag_opener = pair(match_literal("<"), identifier); assert_eq!( Ok(("/>", ((), "my-first-element".to_string()))), tag_opener("<my-first-element/>") ); assert_eq!(Err("oops"), tag_opener("oops")); assert_eq!(Err("!oops"), tag_opener("<!oops")); } }
它看起来成功了!但是看下结果类型:((), String)。很明显,我们只关心右边的值 - String。这种情况相当普遍 - 我们的一些解析器只匹配输入中的模式但不产生值,因此可以安全的忽略他们的输出。为了适应这种模式,我们将使用pair组合子编写另外两个组合子left,它丢弃第一个解析器的结果,只返回第二个,以及它的相反数right,我们想在上面的测试中使用right而不是pair - 它可以丢弃二元组左边的()只保留右边的String。
Enter The Functor
在我们深入讨论之前,先介绍另一个组合子:map,它将使编写这两个解析器更加简单。
这个组合子有一个目的:改变结果的类型。例如,假设你有一个解析器返回((), String),但是你希望能够将其返回值类型修改为String。
为了做到这点,我们传入一个函数,该函数知道如何将原始类型转换成新的类型。在我们的示例中,该函数十分简单:|(_left, right)| right。它的一般格式就像Fn(A) -> B,其中A是解析器的原始类型,B是期望的新类型。
#![allow(unused)] fn main() { fn map<P, F, A, B>(parser: P, map_fn: F) -> impl Fn(&str) -> Result<(&str, B), &str> where P: Fn(&str) -> Result<(&str, A), &str>, F: Fn(A) -> B, { move |input| match parser(input) { Ok((next_input, result)) => Ok((next_input, map_fn(result))), Err(err) => Err(err), } } }
这些类型说明什么?P是我们的解析器。它在成功时将返回A。F是我们将用于将P映射到我们的返回值中的函数,它看起来和P很像,但是它的返回值类型是B而不是A。
在代码中,我们运行parser(input),如果执行成功,我们将拿到result并在其上运行函数map_fn(result),然后将A转换成B。
实际上,我们可以稍微放纵 (indulge) 一下自己并缩短一下这个函数,因为map实际上是处理Result的一种常见模式:
#![allow(unused)] fn main() { fn map<P, F, A, B>(parser: P, map_fn: F) -> impl Fn(&str) -> Result<(&str, B), &str> where P: Fn(&str) -> Result<(&str, A), &str>, F: Fn(A) -> B, { move |input| parser(input) .map(|(next_input, result)| (next_input, map_fn(result))) } }
这种模式在 Haskell 以及范畴论 (category theory) 中被称为”函子 (functor)“。如果你在其中有一个类型为A的东西,并且有一个可用的map函数,你可以将某个函数从A传递到B以将其转换成相同类型的东西,但是在其中使用类型B,这就是一个函子。你可以在 Rust 中很多地方见到它,如在 Option 中,Result 中,Iterator 甚至在 Future 中,但它没有被明确命名。因为在 Rust 的类型系统中,你不能真正的将函子表示为泛化的东西,因为它缺乏更高级的类型,但那是另一回事了,所以我们只需关注这些函子,寻找map函数即可。
Time For A Trait
你可能已经注意到,我们不断重复解析器类型签名的格式:Fn(&str) -> Result<(&str, Output), &str>。你可能已经厌倦了像我写的那样完整的阅读它,所以我认为是时候引入一个 trait,让这些更具有可读性,还可以为解析器添加一些扩展性。
但是首先,我们先为一直使用的返回值类型创建一个类型别名:
#![allow(unused)] fn main() { type ParseResult<'a, Output> = Result<(&'a str, Output), &'a str>; }
现在,我们可以不用一直输入那串冗长的类型,可以直接使用ParseResult<String>。我们可以在这里添加一个生命周期,因为类型的声明需要它,但是大多数时候 Rust 编译器可以帮你推断。通常,可以尝试不添加生命周期,并观察 rustc 是否报错,如果报错则添加生命周期。
在此例中,'a特指input的生命周期。
现在,对于 trait,我们也需要在这里声明生命周期,并且当你使用该 trait 时,生命周期通常也是必须的。这是一个额外的输入,但它击败了以前的版本。
#![allow(unused)] fn main() { trait Parser<'a, Output> { fn parse(&self, input: &'a str) -> ParseResult<'a, Output>; } }
它目前只有一个方法:parse()方法,它看起来似曾相识:它和我们之前编写的解析器函数基本相同。
为了让它更加简单,我们实际上可以为任何匹配解析器签名的函数实现这个 trait。
#![allow(unused)] fn main() { impl<'a, F, Output> Parser<'a, Output> for F where F: Fn(&'a str) -> ParseResult<Output>, { fn parse(&self, input: &'a str) -> ParseResult<'a, Output> { self(input) } } }
通过这种方式,我们不仅可以传递迄今为止已传递的相同函数作为解析器,并完全实现Parser trait,还可以使用其他类型作为解析器。
但是,更重要的是,它把我们从必须一直输入这些函数签名的噩梦中解救了出来。让我们重写map函数,并看它是如何工作的。
#![allow(unused)] fn main() { fn map<'a, P, F, A, B>(parser: P, map_fn: F) -> impl Parser<'a, B> where P: Parser<'a, A>, F: Fn(A) -> B, { move |input| parser.parse(input) .map(|(next_input, result)| (next_input, map_fn(result))) } }
这里需要特别注意的一件事是:我们现在必须执行parser.parse(input),而不是将解析器作为函数调用,因为我们不知道类型P是否是函数,我们只知道它实现了Parser,并且我们必须使用Parser提供的接口。但是函数体看起来完全一样,类型看起来也更加简洁。只是有一个新的额外噪音:生命周期'a,但总的来说是一个很大的改进。
如果我们以相同的方式重新编写pair函数,会看起来更加简洁:
#![allow(unused)] fn main() { fn pair<'a, P1, P2, R1, R2>(parser1: P1, parser2: P2) -> impl Parser<'a, (R1, R2)> where P1: Parser<'a, R1>, P2: Parser<'a, R2>, { move |input| match parser1.parse(input) { Ok((next_input, result1)) => match parser2.parse(next_input) { Ok((final_input, result2)) => Ok((final_input, (result1, result2))), Err(err) => Err(err), }, Err(err) => Err(err), } } }
和之前一样,这里唯一的改变就是类型签名更加简洁,并且需要执行parser.parse(input)而不是parse(input)。
实际上,我们还可以简化pair函数的主题,通过使用map:
#![allow(unused)] fn main() { fn pair<'a, P1, P2, R1, R2>(parser1: P1, parser2: P2) -> impl Parser<'a, (R1, R2)> where P1: Parser<'a, R1>, P2: Parser<'a, R2>, { move |input| { parser1.parse(input).and_then(|(next_input, result1)| { parser2.parse(next_input) .map(|(last_input, result2)| (last_input, (result1, result2))) }) } } }
Result的and_then方法和map类似,不同之处在于map函数不会返回新值到Result内部,而是返回一个新的Result。上面的代码与先前使用match块的版本效果相同。稍后我们将回到and_then,但是现在,既然我们有一个干净简洁的map,我们可以真正实现left,right组合子。
Left And Right
有了pair和map,我们可以非常简洁的编写left和right组合子:
#![allow(unused)] fn main() { fn left<'a, P1, P2, R1, R2>(parser1: P1, parser2: P2) -> impl Parser<'a, R1> where P1: Parser<'a, R1>, P2: Parser<'a, R2>, { map(pair(parser1, parser2), |(left, _right)| left) } fn right<'a, P1, P2, R1, R2>(parser1: P1, parser2: P2) -> impl Parser<'a, R2> where P1: Parser<'a, R1>, P2: Parser<'a, R2>, { map(pair(parser1, parser2), |(_left, right)| right) } }
我们使用pair组合子将两个解析器组合成一个解析器,然后使用map组合子选择其结果元组中我们想要保留的部分。
现在我们需要为元素标签的前两部分重写测试,使它更简洁一些,在此过程中,我们将获得了一些重要的新解析器组合子功能。
不过,我们必须先更新我们的两个解析器以使用Parser和ParseResult。match_literal是更复杂的一个:
#![allow(unused)] fn main() { fn match_literal<'a>(expected: &'static str) -> impl Parser<'a, ()> { move |input: &'a str| match input.get(0..expected.len()) { Some(next) if next == expected => Ok((&input[expected.len()..], ())), _ => Err(input), } } }
除了改变返回值类型之外,我们还必须确保闭包的输入类型是&'a str,否则 rustc 会报错。
对于identifier,只需更改返回值类型即可,编译器会自动为你推断生命周期。
#![allow(unused)] fn main() { fn identifier(input: &str) -> ParseResult<String> {} }
接下来进行测试,可以看见在结果中没有那个笨拙 (ungainly) 的()。
#![allow(unused)] fn main() { #[test] fn right_combinator() { let tag_opener = right(match_literal("<"), identifier); assert_eq!( Ok(("/>", "my-first-element".to_string())), tag_opener.parse("<my-first-element/>") ); assert_eq!(Err("oops"), tag_opener.parse("oops")); assert_eq!(Err("!oops"), tag_opener.parse("<!oops")); } }
One Or More
让我们继续解析元素标签。我们已经解析了<和标志符。然后呢?应该是我们的第一个属性对。
实际上这些属性对是可选的。我们需要找到一种方式来处理这种可选的标记。
等等,实际上在我们得到第一个可选属性对之前我们必须处理一些事情:空格。
在元素名称的末尾以及第一个属性名称(如果存在的话)的开头之间,存在一个空格。我们需要处理这个空格。
甚至更糟的是,我们需要处理一个或多个空格,因为<element attribute="value"/>也是一个合法的语法,即使它的空格很多。所以这似乎是我们考虑是否可以编写一个组合子来表示一个或多个解析器想法的好时机。
我们在identifier解析器中已经处理过这个问题,但是一切都是在那里手动完成的。毫不奇怪,总体思路的代码并没有什么不同。
#![allow(unused)] fn main() { fn one_or_more<'a, P, A>(parser: P) -> impl Parser<'a, Vec<A>> where P: Parser<'a, A>, { move |mut input| { let mut result = Vec::new(); if let Ok((next_input, first_item)) = parser.parse(input) { input = next_input; result.push(first_item); } else { return Err(input); } while let Ok((next_input, next_item)) = parser.parse(input) { input = next_input; result.push(next_item); } Ok((input, result)) } } }
首先,我们构建的解析器返回值类型是A,组合解析器的返回值类型是Vec<A> - 任意数量的A。
这个代码看起来确实和identifier很像。首先,我们解析第一个元素,如果不存在,则返回一个错误。然后我们尽可能多的解析元素,直到解析失败,此时我们返回包含收集元素的向量。
将上述代码修改为支持解析零次或多次的解析器也很简单,只需删除前部分if判断即可:
#![allow(unused)] fn main() { fn zero_or_more<'a, P, A>(parser: P) -> impl Parser<'a, Vec<A>> where P: Parser<'a, A>, { move |mut input| { let mut result = Vec::new(); while let Ok((next_input, next_item)) = parser.parse(input) { input = next_input; result.push(next_item); } Ok((input, result)) } } }
让我们编写测试用例以验证这两个解析器的功能符合预期。
#![allow(unused)] fn main() { #[test] fn one_or_more_combinator() { let parser = one_or_more(match_literal("ha")); assert_eq!(Ok(("", vec![(), (), ()])), parser.parse("hahaha")); assert_eq!(Err("ahah"), parser.parse("ahah")); assert_eq!(Err(""), parser.parse("")); } #[test] fn zero_or_more_combinator() { let parser = zero_or_more(match_literal("ha")); assert_eq!(Ok(("", vec![(), (), ()])), parser.parse("hahaha")); assert_eq!(Ok(("ahah", vec![])), parser.parse("ahah")); assert_eq!(Ok(("", vec![])), parser.parse("")); } }
请注意两者的不同之处:对于one_or_more,解析空字符串时会返回错误,因为它需要找到至少一个满足其子解析器的输入,但是对于zero_or_more,一个空字符串只是意味着没有满足条件的输入,它并不是一个错误。
鉴于此,可以考虑将这两个方法进行泛化,因为一个是另一个的副本,只是移除了一部分功能。用zero_or_more来表示one_or_more可能会很诱人 (tempt)。
#![allow(unused)] fn main() { fn one_or_more<'a, P, A>(parser: P) -> impl Parser<'a, Vec<A>> where P: Parser<'a, A>, { map(pair(parser, zero_or_more(parser)), |(head, mut tail)| { tail.insert(0, head); tail }) } }
在这里,我们遇到了 Rust 的一个问题,我甚至不是指Vec没有cons方法的问题,但我知道每个阅读那段代码的 Lisp 程序员都在思考这个问题:那就是所有权。
我们拥有这个解析器,所以我们不能将其作为参数传递两次,编译器会试图对你大喊,因为你试图移动一个已经移动的值。那么我们可以让组合子代替引用吗?不,事实证明,我们还遇到另一整套借用检查器的问题 - 我们目前不会试图解决这些问题。并且因为这些解析器是函数,所以它们不会实现Clone,该 trait 本来可以帮我们节省一整天的时间,所以我们被困在一个约束中,我们不能在组合子中轻易地复用我们的解析器。
不过,这不是一个大问题。它只是说明我们不能使用组合子来表达one_or_more,但事实证明,这两个通常是你需要的唯一组合子,它们往往会重用解析器,而且,如果你想变得非常花哨,除了解析器,你还可以编写一个带有RangeBound的组合子,并在一个范围内对其进行重复:zero_or_more使用range(0..),one_or_more使用range(1..),five_or_six使用range(5..=6),依此类推。
不过,让我们把它留给读者作为练习。现在我们只需使用zero_or_more和one_or_more即可。
另一个练习可能是找到解决这些所有权问题的方法 - 也许可以通过将解析器包装在Rc中使其支持克隆?
A Predicate Combinator #
我们现在有了需要用 one_or_more 解析空白的 xml 块,并用 zero_or_more 解析属性对。 其实,稍等一下。我们其实不想先解析空格 然后 解析属性 (attributes)。如果你考虑一下,如果没有属性,空格是可选的,我们可能会遇到直接的 > 或 />。但是如果有一个属性,那么必须是空格。幸运的是,每个属性之间也必须有空格,如果有多个,所以我们在这里真正看到的是一系列零或更多出现的一个或多个空格项,然后是属性。
我们首先需要一个解析单个空白项的解析器。我们可以选择下列三种方式之一。
一,我们可以愚蠢地使用我们的 match_literal 解析器和一个只包含一个空格的字符串。为什么这么傻?因为空格也是换行符、制表符和大量呈现为空格的奇怪 Unicode 字符。我们将不得不再次依赖 Rust 的标准库,当然 char 有一个 is_whitespace 方法,就像它有 is_alphabetic 和 is_alphanumeric 一样。
二,我们可以使用 is_whitespace Predicate 写出另外一个解析器,它消耗任意数量的空白字符,就像我们之前编写的 identifier 一样。
三,我们可以写的更加巧妙。编写一个解析器 any_char,它返回一个单一的 char,只要输入中还剩下一个,以及一个组合子 pred,它接受一个解析器和一个谓词 (Predicate)函数,并像这样将两者结合起来:pred (any_char, |c| c.is_whitespace())。这有一个额外的好处,通过它,编写我们将需要的最终的解析器变得非常容易:属性值的引用字符串。 any_char 解析器写起来很简单,但我们得记得注意那些 UTF-8 问题。
#![allow(unused)] fn main() { fn any_char(input: &str) -> ParseResult<char> { match input.chars().next() { Some(next) => Ok((&input[next.len_utf8()..], next)), _ => Err(input), } } }
对 经验丰富 的我们来说, pred 组合子也并没有给我们太多惊喜 。 我们调用解析器,然后我们在解析器成功的情况下调用我们的谓词函数,并且只有当它返回 true 时,我们才真正返回 success,否则我们将返回与解析器失败一致的错误。
#![allow(unused)] fn main() { fn pred<'a, P, A, F>(parser: P, predicate: F) -> impl Parser<'a, A> where P: Parser<'a, A>, F: Fn(&A) -> bool, { move |input| { if let Ok((next_input, value)) = parser.parse(input) { if predicate(&value) { return Ok((next_input, value)); } } Err(input) } } }
写一个快速测试以确保一切正常:
#![allow(unused)] fn main() { #[test] fn predicate_combinator() { let parser = pred(any_char, |c| *c == 'o'); assert_eq!(Ok(("mg", 'o')), parser.parse("omg")); assert_eq!(Err("lol"), parser.parse("lol")); } }
有了这两个组件,我们可以用一个快速的单行代码编写我们的 whitespace_char 解析器:
#![allow(unused)] fn main() { fn whitespace_char<'a>() -> impl Parser<'a, char> { pred(any_char, |c| c.is_whitespace()) } }
并且,现在我们有了whitespace_char,我们也可以用它实现我们之前的想法,一个或多个空白,以及它的姊妹想法,零个或多个空白。 让我们专注于几个简单的地方,并分别称它们为space1和space0。
#![allow(unused)] fn main() { fn space1<'a>() -> impl Parser<'a, Vec<char>> { one_or_more(whitespace_char()) } fn space0<'a>() -> impl Parser<'a, Vec<char>> { zero_or_more(whitespace_char()) } }
Quoted Strings
完成所有这些组件后,我们现在终于可以解析这些属性了吗? 当然啦,我们只需要确保我们拥有所有这些属性组件的单独的解析器。 我们已经为属性名称提供了 identifier(尽管使用 any_char 和 pred 加上我们的 *_or_more 组合子来重写它是很诱人的)。 = 只是 match_literal("=")。 不过,我们只有一个带引号的字符串解析器,所以让我们把它组合起来。 幸运地是,我们已经拥有了完成它所需的所有组合子。
#![allow(unused)] fn main() { fn quoted_string<'a>() -> impl Parser<'a, String> { map( right( match_literal("\""), left( zero_or_more(pred(any_char, |c| *c != '"')), match_literal("\""), ), ), |chars| chars.into_iter().collect(), ) } }
组合子的嵌套在这一点上变得有点烦人,但我们暂时不会重构所有代码来修复它,而是专注于这里发生的事情。
最外面的组合子是一个 map,因为前面提到的烦人的嵌套,从这开始理解代码是很让人困惑的,所以让我们试着找出它真正开始的地方:第一个引号字符。在map里面,有一个right,而right的第一部分就是我们要找的:match_literal("\"")。那是我们的引号的开始 。
right 的第二部分是字符串的其余部分。在 left 里面,我们很快注意到那个 left 的 right 参数,我们一直忽视的那个: 是另一个 match_literal("\"") - 引号的结束。所以左手部分是我们用引号包裹的字符串。
我们在这里利用新的 pred 和 any_char 来获得一个接受除另一个引号之外的任何内容的解析器,并将其放入 zero_or_more 中,因此我们所说的实现如下:
-
一个引号
-
后跟零个或多个不是另一个引号的内容
-
接着是另一个引号
并且,在
right和left之间,我们丢弃结果值中的引号并取回引用的字符串。但是等等,这不是一个字符串。还记得
zero_or_more返回什么吗?内部解析器的返回类型 A 的Vec<A>。对于any_char来说,就是char。那么,我们得到的不是字符串而是Vec<char>。这就是map的用武之地:我们使用它把Vec<char>转换为String,因为你可以从Iterator<Item = char>构建一个String,所以我们可以调用vec_of_chars.into_iter().collect(),并且由于类型推断的强大功能,我们有了String。在我们继续之前,让我们编写一个快速测试以确保一切正常,因为如果我们需要这么多词来解释它,这可能不是我们作为程序员对自己有信心的样子。
#![allow(unused)] fn main() { #[test] fn quoted_string_parser() { assert_eq!( Ok(("", "Hello Joe!".to_string())), quoted_string().parse("\"Hello Joe!\"") ); } }
所以, 终于, 我们可以解析点属性了.
At Last, Parsing Attributes
我们现在可以解析空格、标识符、= 符号和带引号的字符串。 最后,这就是我们解析属性所需的全部内容。
首先,让我们为一个属性对编写一个解析器。 我们将把它们存储为 Vec<(String, String)>,你可能还记得,所以我们需要一个解析器来处理 (String, String) 元组,来提供给我们值得信赖的 zero_or_more 组合子。 让我们看看我们是否可以写出一个。
#![allow(unused)] fn main() { fn attribute_pair<'a>() -> impl Parser<'a, (String, String)> { pair(identifier, right(match_literal("="), quoted_string())) } }
易如反掌! 总结一下:我们已经有一个方便的组合子来解析一个值的元组,pair,所以我们将它与 identifier 解析器一起使用,产生一个 String 和一个带有 = 符号的 right, 它包括了我们不想保留的值,以及我们新的 quoted_string 解析器,它给了我们另一个 String。
现在,让我们将其与 zero_or_more 结合起来构建该 vector - 但不要忘记它们之间的空白。
#![allow(unused)] fn main() { fn attributes<'a>() -> impl Parser<'a, Vec<(String, String)>> { zero_or_more(right(space1(), attribute_pair())) } }
零次或多次出现以下内容:一个或多个空白字符,然后是一个属性对。 我们使用right来丢弃空格并保留属性对。
让我们测试一下。
#![allow(unused)] fn main() { #[test] fn attribute_parser() { assert_eq!( Ok(( "", vec![ ("one".to_string(), "1".to_string()), ("two".to_string(), "2".to_string()) ] )), attributes().parse(" one=\"1\" two=\"2\"") ); } }
测试通过! 起飞!
实际上,并没有,在叙述者点上, 我的 rustc 抱怨我的类型变得非常复杂,我需要增加最大允许的类型大小才能继续。你也可能遇到这种情况,如果发生了, 你需要知道如何处理它。 幸好,在这些情况下,rustc 通常会给出很好的建议,所以当它告诉你将 #![type_length_limit = "...some big number..."] 添加到文件顶部时,就按照它说的去做。 实际上,只需将其设为 #![type_length_limit = "16777216"],这将使我们进一步深入复杂类型的平流层。 全力以赴,我们现在是宇航员!
So Close Now
这个时候,事情似乎即将开始合为一体,这让人松了一口气,因为我们的类型正在快速接近 NP 完整性。 我们只需要处理两个版本的元素标签:单个元素和带有子元素的父元素,但是我们非常有信心,一旦我们有了这些,解析子元素将只是 zero_or_more 的问题, 对吧?
所以让我们先从单一元素开始,把孩子的问题推迟一点。 或者,更好的是,让我们首先为两者的所有共同点编写一个解析器:开头的 <、元素名称和属性。 让我们看看我们是否可以从几个组合子中得到 (String, Vec<(String, String)>)类型。
#![allow(unused)] fn main() { fn element_start<'a>() -> impl Parser<'a, (String, Vec<(String, String)>)> { right(match_literal("<"), pair(identifier, attributes())) } }
有了它,我们可以快速地给它打上标签,为单个元素创建一个解析器。
#![allow(unused)] fn main() { fn single_element<'a>() -> impl Parser<'a, Element> { map( left(element_start(), match_literal("/>")), |(name, attributes)| Element { name, attributes, children: vec![], }, ) } }
万岁,感觉我们的目标已经触手可及了——我们现在实际上正在构建一个 Element!
让我们来测试一下这个现代科技的奇迹吧。
#![allow(unused)] fn main() { #[test] fn single_element_parser() { assert_eq!( Ok(( "", Element { name: "div".to_string(), attributes: vec![("class".to_string(), "float".to_string())], children: vec![] } )), single_element().parse("<div class=\"float\"/>") ); } }
...我想我们才刚刚突破大气层。
single_element 的返回类型非常复杂,编译器会花费很长时间,直到遇到我们之前给它的非常大的类型大小限制 (#![type_length_limit = ""]),要求更大的类型。 很明显我们不能再忽视这个问题,因为它是一个相当简单的解析器和(应该只需要)几分钟的编译时间——对于成品来说甚至可能是几个小时——似乎有点不合理。
在继续之前,你最好在我们修复问题时注释掉这两个函数和测试......
To Infinity And Beyond
如果你曾经尝试过在 Rust 中编写递归类型,你可能已经知道我们的小问题的解决方案。
递归类型的一个非常简单的例子是单向链表。 原则上,可以将其表示为这样的枚举:
#![allow(unused)] fn main() { enum List<A> { Cons(A, List<A>), Nil, } }
rustc 会非常明智地反对你的递归类型 List<A> ,因为它具有无限大小,因为在每个 List::<A>::Cons 内部是另一个 List<A>,这意味着它也是一个 List<A>......直到无穷大。就 rustc 而言,我们要求一个无限列表,我们要求它能够分配一个无限列表。
在许多语言中,无限列表原则上对于类型系统来说不是问题,实际上对于 Rust 也不是问题。问题是在 Rust 中,如前所述,我们需要能够分配它,或者更确切地说,我们需要能够在我们构造它时预先确定类型的 大小,以及当类型是无限的,这意味着大小也必须是无限的。
解决方案是使用一点间接性。我们的List::Cons 不是A 的一个元素和A 的另一个list,而是我们使它成为A 的一个元素和一个指向A 列表的指针。我们知道指针的大小,不管它指向什么都是一样的,所以我们的 List::Cons 现在有一个固定的和可预测的大小,无论列表的大小如何。在 Rust 中,将一个拥有的东西变成指向堆上拥有的东西的指针的方法是用 box 包裹它。
#![allow(unused)] fn main() { enum List<A> { Cons(A, Box<List<A>>), Nil, } }
Box 的另一个有趣的特性是它里面的类型可以是抽象的。 这意味着我们可以让类型检查器处理一个非常简洁的 Box<dyn Parser<'a, A>>,而不是我们现在非常复杂的解析器函数类型。
听起来不错。 有什么缺点? 好吧,我们可能会因为必须遵循该指针而失去一两个指令周期,也可能是编译器失去了一些优化解析器的机会。 但回想一下 Knuth 关于过早优化(1)的告诫:它会没事的。 你完全可以负担得起这些周期。 来这里是为了解 解析器组合子,而不是了解手写的超专业化 SIMD 解析器(尽管它们本身就很令人兴奋)。 因此,除了迄今为止我们一直在使用的裸函数之外,让我们继续为 boxed 解析器函数实现 Parser。
译者注: 1: 过早优化是万恶之源
#![allow(unused)] fn main() { struct BoxedParser<'a, Output> { parser: Box<dyn Parser<'a, Output> + 'a>, } impl<'a, Output> BoxedParser<'a, Output> { fn new<P>(parser: P) -> Self where P: Parser<'a, Output> + 'a, { BoxedParser { parser: Box::new(parser), } } } impl<'a, Output> Parser<'a, Output> for BoxedParser<'a, Output> { fn parse(&self, input: &'a str) -> ParseResult<'a, Output> { self.parser.parse(input) } } }
出于礼节,我们创建了一个新类型 BoxedParser来保存我们的 box。 要从任何其他类型的解析器(包括另一个BoxedParser,即使那毫无意义)创建一个新的BoxedParser,我们提供了一个函数BoxedParser::new(parser),它只会将该解析器放入 我们的新类型中的一个 Box。 最后,我们为它实现了 Parser,这样它就可以作为解析器互换使用。
这使我们能够将解析器函数放入 Box,并且 BoxedParser 将与函数一样用作 Parser。 现在,正如前面提到的,这意味着将解析器移动到堆中,并且必须取消引用一个指针才能找到它,这可能会花费我们几个宝贵的纳秒,所以我们实际上可能想要推迟使用 box。 将一些更常用的组合子放到 box 就足够了。
An Opportunity Presents Itself
但是,稍等片刻,这为我们提供了解决另一个变得麻烦的问题的机会。
还记得我们写的最后几个解析器吗? 因为我们的组合子是独立的函数,当我们嵌套大量的组合子时,我们的代码开始变得有点不可读。 回想一下我们的 quoted_string 解析器:
#![allow(unused)] fn main() { fn quoted_string<'a>() -> impl Parser<'a, String> { map( right( match_literal("\""), left( zero_or_more(pred(any_char, |c| *c != '"')), match_literal("\""), ), ), |chars| chars.into_iter().collect(), ) } }
如果我们可以在解析器上使用这些组合子方法而不是独立函数,它会有更好的可读性。 如果我们可以将组合子声明为 Parser trait 上的方法会怎样?
问题是,如果我们这样做,我们就失去了依赖 impl Trait 作为返回类型的能力,因为 impl Trait 不允许出现在 trait 声明中。
……但现在我们有了BoxedParser。 我们不能声明一个返回 impl Parser<'a, A> 的 trait ,但我们肯定可以声明一个返回 BoxedParser<'a, A> 的 trait 。
最好的部分是我们甚至可以使用默认实现声明这些,这样我们就不必为实现 Parser 的每个类型重新实现每个组合子。
让我们用 map 来试试,通过扩展我们的 Parser trait 如下:
#![allow(unused)] fn main() { trait Parser<'a, Output> { fn parse(&self, input: &'a str) -> ParseResult<'a, Output>; fn map<F, NewOutput>(self, map_fn: F) -> BoxedParser<'a, NewOutput> where Self: Sized + 'a, Output: 'a, NewOutput: 'a, F: Fn(Output) -> NewOutput + 'a, { BoxedParser::new(map(self, map_fn)) } } }
啊这,好多'a',唉,它们都是必要的。 幸运的是,我们仍然可以不变地重用旧的组合子函数——而且,我们还得到一个额外的好处,不仅可以获得更好的语法来应用它们,我们还通过自动 box 来摆脱爆炸性的 impl Trait 类型。 现在我们可以稍微改进我们的 quoted_string 解析器:
#![allow(unused)] fn main() { fn quoted_string<'a>() -> impl Parser<'a, String> { right( match_literal("\""), left( zero_or_more(pred(any_char, |c| *c != '"')), match_literal("\""), ), ) .map(|chars| chars.into_iter().collect()) } }
乍一看现在更明显,正在对 right() 的结果调用 .map()。
我们也可以给 pair、left 和 right 相同的处理,但是对于这三个,我认为当它们是函数时读起来更容易,因为它们反映了 pair 的输出结构 类型。 如果你不同意,完全可以像我们对 map 所做的那样将它们添加到 trait 中,并且非常欢迎你继续尝试将其作为练习。
不过,另一个主要候选人是 pred。 让我们将它的定义添加到 Parser trait 中:
#![allow(unused)] fn main() { fn pred<F>(self, pred_fn: F) -> BoxedParser<'a, Output> where Self: Sized + 'a, Output: 'a, F: Fn(&Output) -> bool + 'a, { BoxedParser::new(pred(self, pred_fn)) } }
这下我们就可以用 pred 重写 quoted_string:
#![allow(unused)] fn main() { zero_or_more(any_char.pred(|c| *c != '"')), }
我认为这读起来更好一些,我认为我们也会保留 zero_or_more 原样 - 它读起来就像应用了以下谓词的零个或多个 any_char,这对我来说听起来很半。 当然,如果你愿意这么写,你也可以继续将 zero_or_more 和 one_or_more 移到 trait 中。
除了重写quoted_string,我们还要修正single_element中的map:
#![allow(unused)] fn main() { fn single_element<'a>() -> impl Parser<'a, Element> { left(element_start(), match_literal("/>")).map(|(name, attributes)| Element { name, attributes, children: vec![], }) } }
让我们试着取消对 element_start 和我们之前注释掉的测试的注释,看看情况是否变得更好。 开始编译并尝试运行测试......
……而且,是的,现在编译时间恢复正常了。 甚至可以继续删除文件顶部的字体大小设置。
这只是通过 box 两个 map 和一个 pred - 而且我们从中得到了更好的语法!
Having Children
现在让我们为父元素的开始标记编写解析器。 它几乎与single_element 相同,只是它以> 结尾而不是/>。 后面还有零个或多个子元素和一个结束标记,但首先我们需要解析实际的开始标记,所以让我们完成这个函数。
#![allow(unused)] fn main() { fn open_element<'a>() -> impl Parser<'a, Element> { left(element_start(), match_literal(">")).map(|(name, attributes)| Element { name, attributes, children: vec![], }) } }
现在,我们如何得到这些子元素? 它们将是单个元素或父元素本身,并且它们有零个或多个,所以我们有我们可信赖的 zero_or_more 组合子,但是我们提供什么? 我们还没有编写过的一件事是多重解析器:解析或者单个元素或父元素的东西。
为了完成这个特性,我们需要一个组合子,它按顺序尝试两个解析器:如果第一个解析器成功,我们就完成了,我们返回它的结果,就是这样。 如果失败,我们不会返回错误,而是在相同的输入上尝试第二个解析器。 如果成功,很好,如果没有,我们也会返回错误,因为这意味着我们的两个解析器都失败了,这是一个整体性失败。
#![allow(unused)] fn main() { fn either<'a, P1, P2, A>(parser1: P1, parser2: P2) -> impl Parser<'a, A> where P1: Parser<'a, A>, P2: Parser<'a, A>, { move |input| match parser1.parse(input) { ok @ Ok(_) => ok, Err(_) => parser2.parse(input), } } }
这使得我们可以声明一个解析器element,它匹配单个元素或父元素(现在,我们只使用open_element 来表示它,一旦我们有了element,我们将处理 element)。
#![allow(unused)] fn main() { fn element<'a>() -> impl Parser<'a, Element> { either(single_element(), open_element()) } }
现在让我们为结束标记添加一个解析器。 它具有必须匹配开始标签的特性,这意味着解析器必须知道开始标签的名称是什么。 但这就是函数参数的用途,对吧?
#![allow(unused)] fn main() { fn close_element<'a>(expected_name: String) -> impl Parser<'a, String> { right(match_literal("</"), left(identifier, match_literal(">"))) .pred(move |name| name == &expected_name) } }
事实证明,那个 pred 组合子真的很有用,不是吗?
现在,让我们为完整的父元素解析器、子元素和所有元素组合起来:
#![allow(unused)] fn main() { fn parent_element<'a>() -> impl Parser<'a, Element> { pair( open_element(), left(zero_or_more(element()), close_element(…oops)), ) } }
通过使用 and_then,我们现在可以通过使用该函数构建正确版本的 close_element 来获得正确的结果。
#![allow(unused)] fn main() { fn parent_element<'a>() -> impl Parser<'a, Element> { open_element().and_then(|el| { left(zero_or_more(element()), close_element(el.name.clone())).map(move |children| { let mut el = el.clone(); el.children = children; el }) }) } }
现在看起来有点复杂,因为 and_then 必须在 open_element() 中进行,在那里我们找到进入 close_element 的地方。这意味着 open_element 之后的解析器的其余部分都必须在 and_then 闭包内构造。此外,因为该闭包现在是来自 open_element 的 Element 结果的唯一接收者,我们返回的解析器也必须向前传递该信息。
我们在生成的解析器上 map的内部闭包具有对外部闭包中的 Element(el)的引用。我们必须使用 clone() ,因为一个 Fn 中,只有对它的引用。我们获取内部解析器的结果(我们的 Vec<Element> 子元素)并将其添加到我们克隆的 Element 中,然后将其作为最终结果返回。
我们现在需要做的就是返回到我们的 element 解析器并确保我们将 open_element 更改为 parent_element,这样它就会解析整个元素结构,而不是只是它的开头,我相信我们已经完成了!
Word Or Do I Have To?
还记得我们讨论过 map 模式如何在 Planet Haskell 上被称为“函子”吗?
and_then 模式是你在 Rust 中经常看到的另一种模式,通常与 map 位于相同的位置。它在 Iterator 上被称为 flat_map,但它的模式与其他模式相同。
它的花名是monad。如果你有一个东西 Thing<A>,并且你有一个可用的 and_then 函数,它可以将一个函数从 A 传递给 Thing<B>,这样现在你就有了一个新的 Thing<B> 来替代原来的,这就是一个 monad。
该函数可能会立即被调用,比如当你有一个 Option<A> 时,我们已经知道它是一个 Some(A) 还是一个 None,我们直接应用该函数,如果它是一个 Some(A),那么就会给我们一个Some(B)。
它也可能被称为 惰性 (lazy)。例如,如果有一个仍在等待解析的 Future<A>,它不会立即调用该函数来创建一个 Future<B>,而是创建一个新的 Future<B>它包含 Future<A> 和函数,然后等待 Future<A> 完成。当它这样做时,它会使用 Future<A> 的结果调用函数,这样就搞定了 1(He isn't really your uncle.),得到你的 Future< B> 。换句话说,在Future 的情况下,可以将传递给and_then 的函数视为回调函数,因为它会在完成时使用原始 future 的结果进行调用。它还比这更有趣,因为它返回一个 new Future,它可能已经或可能没有被解决,所以它是一种将 future 连在一起的方法。
然而,与函子一样,Rust 的类型系统目前不能表达 monad,所以让我们只需注意这种模式被称为 monad,而且令人失望的是,这和网上的搜到的意思并不一样,它与墨西哥卷饼毫无关系。
Whitespace, Redux
只有最后一件事。
我们现在应该有一个能够解析一些 XML 的解析器,但是他并不能很好的接受空格。 标签之间应该允许任意空格,这样我们就可以自由地在标签之间插入换行符等(原则上,标识符和文字之间应该允许空格,比如< div />,但这里跳过它)。 在这一点上,我们应该能够毫不费力地为此组合一个快速组合子。
#![allow(unused)] fn main() { fn whitespace_wrap<'a, P, A>(parser: P) -> impl Parser<'a, A> where P: Parser<'a, A>, { right(space0(), left(parser, space0())) } }
如果我们将 element 包裹在里面,它将忽略 element 周围的所有前面和后面空格,这意味着我们可以随意使用尽可能多的换行符和尽可能多的缩进。
#![allow(unused)] fn main() { fn element<'a>() -> impl Parser<'a, Element> { whitespace_wrap(either(single_element(), parent_element())) } }
We're Finally There!
我想我们终于做到了! 让我们写个测试庆祝一下!
#[test]
fn xml_parser() {
let doc = r#"
<top label="Top">
<semi-bottom label="Bottom"/>
<middle>
<bottom label="Another bottom"/>
</middle>
</top>"#;
let parsed_doc = Element {
name: "top".to_string(),
attributes: vec![("label".to_string(), "Top".to_string())],
children: vec![
Element {
name: "semi-bottom".to_string(),
attributes: vec![("label".to_string(), "Bottom".to_string())],
children: vec![],
},
Element {
name: "middle".to_string(),
attributes: vec![],
children: vec![Element {
name: "bottom".to_string(),
attributes: vec![("label".to_string(), "Another bottom".to_string())],
children: vec![],
}],
},
],
};
assert_eq!(Ok(("", parsed_doc)), element().parse(doc));
}
下面这个测试会因为有未闭合 tag 而解析失败:
#![allow(unused)] fn main() { #[test] fn mismatched_closing_tag() { let doc = r#" <top> <bottom/> </middle>"#; assert_eq!(Err("</middle>"), element().parse(doc)); } }
好消息是它返回不匹配的结束标记作为错误。 坏消息是它实际上并没有说问题是不匹配的结束标签,只是错误在哪里。 总比没有好,但是,老实说,随着错误消息的出现,它仍然很糟糕。 但是想让它能成功的找到错至少得再写一篇同样长的文章。
让我们关注好消息:我们使用解析器组合子从头开始编写了一个解析器! 我们知道解析器既构成函子又构成单子,因此你现在可以在令人生畏的范畴论知识聚会上给人们留下深刻印象了2。(Please don't be that person at parties. 别真的这么干)
最重要的是,我们现在知道解析器组合子是如何从头开始工作的。 现在没有人能阻止我们!
Victory Puppies

Further Resources
首先,我对用严格的 rust术语 向你解释 monad 感到内疚,而且我知道如果我不向你指出 他的开创性论文,Phil Wadler 会对我非常不满。 其中详细介绍了更多令人兴奋的细节——包括它们与解析器组合子的关系。
本文中的想法与 pom 解析器组合子库背后的想法极为相似,如果这让你想在同一个解析器组合子中使用风格,我强烈推荐它。
Rust 解析器组合子的最新技术仍然是 nom,以至于前面提到的 pom 显然是派生的名称(而且没有比这更好的称赞了),但它采用了与我们今天在这里构建的方法截然不同的方法。
另一个流行的 Rust 解析器组合库是 combine,它可能也值得一看。
Haskell 的开创性解析器组合库是 Parsec。
最后,我对解析器组合子的第一次认识归功于 Graham Hutton 所著的 Programming in Haskell,这是一本很棒的书,不仅容易读而且还会教给你 Haskell 的积极副作用。
Licence
This work by Bodil Stokke is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License.
本文由 Bodil Stokke 撰写,基于署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0)协议。
用Rust编写LLVM的玩具编译器
原文
我目前的副业是用Rust编写一个可以将代码转换成LLVM IR的编译器。LLVM的API对于新手(noobs)来说有点令人生畏(daunting),而且没有很多有关的教程(有限的教程大多数还是基于C++的,如何使用Rust做同样的事并不总是那么明确)。我希望当我准备做一件事情时,有人可以手把手的教我,这也是我要写这篇文章的原因。
对于Rust,与LLVM的接口交互的最佳选择是使用llvm-sys。互联网上的一些热心朋友在这里托管了一些关于llvm-sys的文档。当然,你还应该去查看LLVM的官方指南,因为它可以帮助你理解LLVM是如何“思考”的。这篇文章基本上是LLVM官方指南的Rust翻译。
你可以从这里获取最终的代码。
搭建开发环境
对于新手,使用LLVM开发有一个可以复用的方式:
# `curl` is just so we can next install Rust
sudo apt-get -y install clang curl llvm-3.8-dev
curl https://sh.rustup.rs -sSf | sh
# The `llvm-sys` crate expects something called `llvm-config` on your PATH.
sudo ln -s /usr/bin/llvm-config-3.8 /usr/bin/llvm-config
如果你是在Ubuntu上执行上面的语句(你可能需要执行apt-get update),你就可以继续了。如果不是,你需要使用下面的Vagrantfile文件在Vagrant Box中运行上述语句。
Vagrant.configure("2") do |config|
config.vm.box = "bento/ubuntu-16.04"
end
你可以从执行cargo init llvm-example --bin开始,并将下面(从llvm-sys中拷贝)的代码写入src/main.rs中:
//! Construct a function that does nothing in LLVM IR. extern crate llvm_sys as llvm; use std::ptr; fn main() { unsafe { // Set up a context, module and builder in that context. let context = llvm::core::LLVMContextCreate(); let module = llvm::core::LLVMModuleCreateWithName(b"nop\0".as_ptr() as *const _); let builder = llvm::core::LLVMCreateBuilderInContext(context); // Get the type signature for void nop(void); // Then create it in our module. let void = llvm::core::LLVMVoidTypeInContext(context); let function_type = llvm::core::LLVMFunctionType(void, ptr::null_mut(), 0, 0); let function = llvm::core::LLVMAddFunction(module, b"nop\0".as_ptr() as *const _, function_type); // Create a basic block in the function and set our builder to generate // code in it. let bb = llvm::core::LLVMAppendBasicBlockInContext(context, function,b"entry\0".as_ptr() as *const _); llvm::core::LLVMPositionBuilderAtEnd(builder, bb); // Emit a `ret void` into the function llvm::core::LLVMBuildRetVoid(builder); // Dump the module as IR to stdout. llvm::core::LLVMDumpModule(module); // Clean up. Values created in the context mostly get cleaned up there. llvm::core::LLVMDisposeBuilder(builder); llvm::core::LLVMDisposeModule(module); llvm::core::LLVMContextDispose(context); } }
并在你的Cargo.toml文件中:
[package]
name = "llvm-example"
version = "0.1.0"
authors = ["Ulysse Carion <ulysse@ulysse.io>"]
[[bin]]
name = "main"
[dependencies]
llvm-sys = "0.2"
你可以获得:
vagrant@vagrant:/vagrant cargo run
Compiling llvm-example v0.1.0 (file:///vagrant)
Running `target/debug/main`
; ModuleID = 'nop'
define void @nop() {
entry:
ret void
}
完美!现在我们可以开始编写自己的东西了。
一个不太平凡的程序
首先,让我们编译一个程序,该程序通过从main函数中返回一个整数来简单的设置一个返回码。
下面是我使用的方式(我们有时候需要使用一个解析器,所以我先添加了peg库):
#![feature(plugin)] #![plugin(peg_syntax_ext)] extern crate llvm_sys as llvm; use std::ffi::CString; use std::fs::File; use std::io::Read; use std::ptr; fn main() { let mut input = String::new(); let mut f = File::open("in.ex").unwrap(); f.read_to_string(&mut input).unwrap(); let parsed_input = parser::program(&input).unwrap(); unsafe { codegen(parsed_input); } } peg! parser(r#" #[pub] program -> String = i:int_literal "\n" { i } int_literal -> String = [0-9]+ { match_str.to_owned() } "#); unsafe fn codegen(input: String) { let context = llvm::core::LLVMContextCreate(); let module = llvm::core::LLVMModuleCreateWithName(b"example_module\0".as_ptr() as *const _); let builder = llvm::core::LLVMCreateBuilderInContext(context); // In LLVM, you get your types from functions. let int_type = llvm::core::LLVMInt64TypeInContext(context); let function_type = llvm::core::LLVMFunctionType(int_type, ptr::null_mut(), 0, 0); let function = llvm::core::LLVMAddFunction(module, b"main\0".as_ptr() as *const _, function_type); let entry_name = CString::new("entry").unwrap(); let bb = llvm::core::LLVMAppendBasicBlockInContext(context, function, entry_name.as_ptr()); llvm::core::LLVMPositionBuilderAtEnd(builder, bb); // The juicy part: construct a `LLVMValue` from a Rust value: let int_value: u64 = input.parse().unwrap(); let int_value = llvm::core::LLVMConstInt(int_type, int_value, 0); llvm::core::LLVMBuildRet(builder, int_value); // Instead of dumping to stdout, let's write out the IR to `out.ll` let out_file = CString::new("out.ll").unwrap(); llvm::core::LLVMPrintModuleToFile(module, out_file.as_ptr(), ptr::null_mut()); llvm::core::LLVMDisposeBuilder(builder); llvm::core::LLVMDisposeModule(module); llvm::core::LLVMContextDispose(context); }
它起作用了!测试一下:
vagrant@vagrant:/vagrant cat in.ex
42
vagrant@vagrant:/vagrant<span class="katex"><span class="katex-html" aria-hidden="true"><span class="base"><span class="strut" style="height:1em;vertical-align:-0.25em;"></span><span class="mord mathnormal">c</span><span class="mord mathnormal">a</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal" style="margin-right:0.03588em;">g</span><span class="mord mathnormal" style="margin-right:0.02778em;">or</span><span class="mord mathnormal">u</span><span class="mord mathnormal">n</span><span class="mord mathnormal" style="margin-right:0.00773em;">R</span><span class="mord mathnormal">u</span><span class="mord mathnormal">nnin</span><span class="mord mathnormal" style="margin-right:0.03588em;">g</span><span class="mord">‘</span><span class="mord mathnormal">t</span><span class="mord mathnormal">a</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal" style="margin-right:0.03588em;">g</span><span class="mord mathnormal">e</span><span class="mord mathnormal">t</span><span class="mord">/</span><span class="mord mathnormal">d</span><span class="mord mathnormal">e</span><span class="mord mathnormal">b</span><span class="mord mathnormal" style="margin-right:0.03588em;">ug</span><span class="mord">/</span><span class="mord mathnormal">main</span><span class="mord">‘</span><span class="mord mathnormal" style="margin-right:0.03588em;">v</span><span class="mord mathnormal">a</span><span class="mord mathnormal" style="margin-right:0.03588em;">g</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal">an</span><span class="mord mathnormal">t</span><span class="mord">@</span><span class="mord mathnormal" style="margin-right:0.03588em;">v</span><span class="mord mathnormal">a</span><span class="mord mathnormal" style="margin-right:0.03588em;">g</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal">an</span><span class="mord mathnormal">t</span><span class="mspace" style="margin-right:0.2777777777777778em;"></span><span class="mrel">:</span><span class="mspace" style="margin-right:0.2777777777777778em;"></span></span><span class="base"><span class="strut" style="height:1em;vertical-align:-0.25em;"></span><span class="mord">/</span><span class="mord mathnormal" style="margin-right:0.03588em;">v</span><span class="mord mathnormal">a</span><span class="mord mathnormal" style="margin-right:0.03588em;">g</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal">an</span><span class="mord mathnormal">t</span></span></span></span> lli-3.8 out.ll ; echo ?
42
有点酷哦!顺便提一下,下面是out.ll文件的内容:
; ModuleID = 'example_module'
define i64 @main() {
entry:
ret i64 42
}
算术
让我们添加对数字的加减乘除操作的支持。为了实现这个,我们需要扩展我们的语法。我们引入一个枚举来代表AST(抽象语法树)。
#![allow(unused)] fn main() { pub enum Expr { Add(Box<Expr>, Box<Expr>), Sub(Box<Expr>, Box<Expr>), Mul(Box<Expr>, Box<Expr>), Div(Box<Expr>, Box<Expr>), Literal(String), } }
并扩展语法:
#![allow(unused)] fn main() { // `product` and `sum` are that way to get operator precedence peg! parser(r#" use super::Expr; #[pub] program -> Expr = e:expression "\n" { e } expression -> Expr = sum sum -> Expr = a:product _ "+" _ b:sum { Expr::Add(Box::new(a), Box::new(b)) } / a:product _ "-" _ b:sum { Expr::Sub(Box::new(a), Box::new(b)) } / product product -> Expr = a:int_literal _ "*" _ b:product { Expr::Mul(Box::new(a), Box::new(b)) } / a:int_literal _ "/" _ b:product { Expr::Div(Box::new(a), Box::new(b)) } / int_literal int_literal -> Expr = [0-9]+ { Expr::Literal(match_str.to_owned()) } _ = " "* "#); }
接下来,可以提交代码。你可以指定诸如“addtmp”的字符串,这些字符串将被用作IR中对应“寄存器”名称的一部分。
#![allow(unused)] fn main() { // When you write out instructions in LLVM, you get back `LLVMValueRef`s. You // can then use these references in other instructions. unsafe fn codegen_expr(context: LLVMContextRef, builder: LLVMBuilderRef, expr: Expr) -> LLVMValueRef { match expr { Expr::Literal(int_literal) => { let int_type = llvm::core::LLVMInt64TypeInContext(context); llvm::core::LLVMConstInt(int_type, int_literal.parse().unwrap(), 0) }, Expr::Add(lhs, rhs) => { let lhs = codegen_expr(context, builder, *lhs); let rhs = codegen_expr(context, builder, *rhs); let name = CString::new("addtmp").unwrap(); llvm::core::LLVMBuildAdd(builder, lhs, rhs, name.as_ptr()) }, Expr::Sub(lhs, rhs) => { let lhs = codegen_expr(context, builder, *lhs); let rhs = codegen_expr(context, builder, *rhs); let name = CString::new("subtmp").unwrap(); llvm::core::LLVMBuildSub(builder, lhs, rhs, name.as_ptr()) }, Expr::Mul(lhs, rhs) => { let lhs = codegen_expr(context, builder, *lhs); let rhs = codegen_expr(context, builder, *rhs); let name = CString::new("multmp").unwrap(); llvm::core::LLVMBuildMul(builder, lhs, rhs, name.as_ptr()) }, Expr::Div(lhs, rhs) => { let lhs = codegen_expr(context, builder, *lhs); let rhs = codegen_expr(context, builder, *rhs); let name = CString::new("divtmp").unwrap(); llvm::core::LLVMBuildUDiv(builder, lhs, rhs, name.as_ptr()) }, } } }
现在,你可以执行10 * 4 + 20/2 - 8之类的程序!如果你问我,那可真是太酷了。
变量
我们将采用简单的方式并假设程序不会执行任何烦人的操作,如引用未定义的变量等。我们只将变量存储在寄存器中,并将它们存在HashMap<String, LLVMValueRef>中,之所以有用是因为运行该程序只有这一种方式。
我们扩展语言和解析器:
#![allow(unused)] fn main() { pub enum Expr { Literal(String), Ref(String), Assign(String, Box<Expr>), Add(Box<Expr>, Box<Expr>), Sub(Box<Expr>, Box<Expr>), Mul(Box<Expr>, Box<Expr>), Div(Box<Expr>, Box<Expr>), } peg! parser(r#" use super::Expr; #[pub] program -> Vec<Expr> = e:(expression ** "\n") "\n" { e } expression -> Expr = i:identifier _ "=" _ s:sum { Expr::Assign(i, Box::new(s)) } / sum sum -> Expr = a:product _ "+" _ b:sum { Expr::Add(Box::new(a), Box::new(b)) } / a:product _ "-" _ b:sum { Expr::Sub(Box::new(a), Box::new(b)) } / product product -> Expr = a:ref_or_literal _ "*" _ b:product { Expr::Mul(Box::new(a), Box::new(b)) } / a:ref_or_literal _ "/" _ b:product { Expr::Div(Box::new(a), Box::new(b)) } / ref_or_literal ref_or_literal -> Expr = i:identifier { Expr::Ref(i) } / int_literal identifier -> String = [a-zA-Z]+ { match_str.to_owned() } int_literal -> Expr = [0-9]+ { Expr::Literal(match_str.to_owned()) } _ = " "* "#); }
然后为这两个新的表达式添加支持:
#![allow(unused)] fn main() { unsafe fn codegen_expr(context: LLVMContextRef, builder: LLVMBuilderRef, names: &mut HashMap<String, LLVMValueRef>, expr: Expr) -> LLVMValueRef { match expr { // ... Expr::Ref(name) => { *names.get(&name).unwrap() }, Expr::Assign(name, expr) => { let new_value = codegen_expr(context, builder, names, *expr); names.insert(name, new_value); new_value }, } } }
并迅速的在codegen函数中更新:
#![allow(unused)] fn main() { let zero = llvm::core::LLVMConstInt(int_type, 0, 0); let mut names = HashMap::new(); let mut return_value = zero; // return value on empty program for expr in input { return_value = codegen_expr(context, builder, &mut names, expr); } llvm::core::LLVMBuildRet(builder, return_value); }
现在让我们来一探究竟:
#![allow(unused)] fn main() { vagrant@vagrant:/vagrant cat in.ex a = 3 b = 76 a + b vagrant@vagrant:/vagrant<span class="katex"><span class="katex-html" aria-hidden="true"><span class="base"><span class="strut" style="height:1em;vertical-align:-0.25em;"></span><span class="mord mathnormal">c</span><span class="mord mathnormal">a</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal" style="margin-right:0.03588em;">g</span><span class="mord mathnormal" style="margin-right:0.02778em;">or</span><span class="mord mathnormal">u</span><span class="mord mathnormal">n</span><span class="mord mathnormal" style="margin-right:0.00773em;">R</span><span class="mord mathnormal">u</span><span class="mord mathnormal">nnin</span><span class="mord mathnormal" style="margin-right:0.03588em;">g</span><span class="mord">‘</span><span class="mord mathnormal">t</span><span class="mord mathnormal">a</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal" style="margin-right:0.03588em;">g</span><span class="mord mathnormal">e</span><span class="mord mathnormal">t</span><span class="mord">/</span><span class="mord mathnormal">d</span><span class="mord mathnormal">e</span><span class="mord mathnormal">b</span><span class="mord mathnormal" style="margin-right:0.03588em;">ug</span><span class="mord">/</span><span class="mord mathnormal">main</span><span class="mord">‘</span><span class="mord mathnormal" style="margin-right:0.03588em;">v</span><span class="mord mathnormal">a</span><span class="mord mathnormal" style="margin-right:0.03588em;">g</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal">an</span><span class="mord mathnormal">t</span><span class="mord">@</span><span class="mord mathnormal" style="margin-right:0.03588em;">v</span><span class="mord mathnormal">a</span><span class="mord mathnormal" style="margin-right:0.03588em;">g</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal">an</span><span class="mord mathnormal">t</span><span class="mspace" style="margin-right:0.2777777777777778em;"></span><span class="mrel">:</span><span class="mspace" style="margin-right:0.2777777777777778em;"></span></span><span class="base"><span class="strut" style="height:1em;vertical-align:-0.25em;"></span><span class="mord">/</span><span class="mord mathnormal" style="margin-right:0.03588em;">v</span><span class="mord mathnormal">a</span><span class="mord mathnormal" style="margin-right:0.03588em;">g</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal">an</span><span class="mord mathnormal">t</span></span></span></span> cat out.ll ; ModuleID = 'example_module' define i64 @main() { entry: ret i64 79 } }
If
在使用if关键字的时候遇到一些麻烦。让if起作用的最简单的方式就是将所有的变量存储在堆栈上。并让LLVM做一些优化。在LLVM中,你可以通过alloca指令创建一个栈变量,并使用load/store进行读写。
为了实现这个,我们通过添加新的解析规则再一次扩展了语言和语法。
#![allow(unused)] fn main() { expression -> Expr = if_expression / i:identifier _ "=" _ s:expression { Expr::Assign(i, Box::new(s)) } / sum if_expression -> Expr = "if" _ e:expression _ "{\n" _ then_body:statements _ "}" _ "else" _ "{\n" _ else_body:statements _ "}" { Expr::If(Box::new(e), then_body, else_body) } }
并在AST节点上添加了一个新的类型:
#![allow(unused)] fn main() { pub enum Expr { Literal(String), Ref(String), Assign(String, Box<Expr>), Add(Box<Expr>, Box<Expr>), Sub(Box<Expr>, Box<Expr>), Mul(Box<Expr>, Box<Expr>), Div(Box<Expr>, Box<Expr>), If(Box<Expr>, Vec<Expr>, Vec<Expr>), } }
最后,完成关于if表达式的代码:
#![allow(unused)] fn main() { unsafe fn codegen_expr(context: LLVMContextRef, builder: LLVMBuilderRef, func: LLVMValueRef, names: &mut HashMap<String, LLVMValueRef>, expr: Expr) -> LLVMValueRef { match expr { // ... Expr::If(condition, then_body, else_body) => { let condition_value = codegen_expr(context, builder, func, names, *condition); let int_type = llvm::core::LLVMInt64TypeInContext(context); let zero = llvm::core::LLVMConstInt(int_type, 0, 0); // `is_nonzero` is a 1-bit integer let name = CString::new("is_nonzero").unwrap(); let is_nonzero = llvm::core::LLVMBuildICmp(builder, llvm::LLVMIntPredicate::LLVMIntNE, condition_value, zero, name.as_ptr()); // It's fine to create blocks first, and then fill them in later. let entry_name = CString::new("entry").unwrap(); let then_block = llvm::core::LLVMAppendBasicBlockInContext(context, func, entry_name.as_ptr()); let else_block = llvm::core::LLVMAppendBasicBlockInContext(context, func, entry_name.as_ptr()); let merge_block = llvm::core::LLVMAppendBasicBlockInContext(context, func, entry_name.as_ptr()); llvm::core::LLVMBuildCondBr(builder, is_nonzero, then_block, else_block); llvm::core::LLVMPositionBuilderAtEnd(builder, then_block); let mut then_return = zero; for expr in then_body { then_return = codegen_expr(context, builder, func, names, expr); } llvm::core::LLVMBuildBr(builder, merge_block); llvm::core::LLVMPositionBuilderAtEnd(builder, else_block); let mut else_return = zero; for expr in else_body { else_return = codegen_expr(context, builder, func, names, expr); } llvm::core::LLVMBuildBr(builder, merge_block); // Position the builder so that it's ready to work on the next // expression. llvm::core::LLVMPositionBuilderAtEnd(builder, merge_block); zero } } } }
代码有点多,但是完成了你所期待的事情。现在,你可以像这样来运行程序:
a = 1
if a {
a = 42
} else {
a = 13
}
a
上述代码对应的IR如下所示:
; ModuleID = 'example_module'
define i64 @main() {
entry:
%a = alloca i64
store i64 1, i64* %a
%a1 = load i64, i64* %a
%is_nonzero = icmp ne i64 %a1, 0
br i1 %is_nonzero, label %entry2, label %entry3
entry2: ; preds = %entry
store i64 42, i64* %a
br label %entry4
entry3: ; preds = %entry
store i64 13, i64* %a
br label %entry4
entry4: ; preds = %entry3, %entry2
%a5 = load i64, i64* %a
ret i64 %a5
}
然而,我们还没有结束。目前,我们的“if”表达式的返回结果始终为zero(见上述codegen_expr函数中If分支的返回值)。而我们想要的正好与其相反,如果我们执行了“then”路径,则if的求值结果应该为then_return,否则返回else_return。
你如何使用LLVM跟踪它执行了哪个分支?通过使用“Phi”节点。你给phi指令一个(block, value)对,该phi节点将会返回与先前执行的块相对应的值。
我们可以这样结束if。注意,我们必须更新then_block和else_block,因为这是我们在“then/else”分支中需要的最后一个块,并且前面的then_block是“then/else”的第一个块。
#![allow(unused)] fn main() { // This is mostly the same code as before, just note the new calls to // `LLVMGetInsertBlock`. llvm::core::LLVMPositionBuilderAtEnd(builder, then_block); let mut then_return = zero; for expr in then_body { then_return = codegen_expr(context, builder, func, names, expr); } llvm::core::LLVMBuildBr(builder, merge_block); let then_block = llvm::core::LLVMGetInsertBlock(builder); llvm::core::LLVMPositionBuilderAtEnd(builder, else_block); let mut else_return = zero; for expr in else_body { else_return = codegen_expr(context, builder, func, names, expr); } llvm::core::LLVMBuildBr(builder, merge_block); let else_block = llvm::core::LLVMGetInsertBlock(builder); // Insert the phi node llvm::core::LLVMPositionBuilderAtEnd(builder, merge_block); let phi_name = CString::new("iftmp").unwrap(); let phi = llvm::core::LLVMBuildPhi(builder, int_type, phi_name.as_ptr()); let mut values = vec![then_return, else_return]; let mut blocks = vec![then_block, else_block]; llvm::core::LLVMAddIncoming(phi, values.as_mut_ptr(), blocks.as_mut_ptr(), 2); phi }
然后,你就得到了一个令人惊叹的编译器:
vagrant@vagrant:/vagrant<span class="katex"><span class="katex-html" aria-hidden="true"><span class="base"><span class="strut" style="height:0.65952em;vertical-align:0em;"></span><span class="mord mathnormal">c</span><span class="mord mathnormal">a</span><span class="mord mathnormal">t</span><span class="mord mathnormal">in</span><span class="mord">.</span><span class="mord mathnormal">e</span><span class="mord mathnormal">x</span><span class="mord mathnormal">a</span><span class="mspace" style="margin-right:0.2777777777777778em;"></span><span class="mrel">=</span><span class="mspace" style="margin-right:0.2777777777777778em;"></span></span><span class="base"><span class="strut" style="height:0.69444em;vertical-align:0em;"></span><span class="mord">1</span><span class="mord mathnormal">b</span><span class="mspace" style="margin-right:0.2777777777777778em;"></span><span class="mrel">=</span><span class="mspace" style="margin-right:0.2777777777777778em;"></span></span><span class="base"><span class="strut" style="height:0.64444em;vertical-align:0em;"></span><span class="mord">0</span><span class="mord mathnormal">c</span><span class="mspace" style="margin-right:0.2777777777777778em;"></span><span class="mrel">=</span><span class="mspace" style="margin-right:0.2777777777777778em;"></span></span><span class="base"><span class="strut" style="height:0.8888799999999999em;vertical-align:-0.19444em;"></span><span class="mord mathnormal">i</span><span class="mord mathnormal" style="margin-right:0.10764em;">f</span><span class="mord mathnormal">a</span><span class="mord"><span class="mord mathnormal">i</span><span class="mord mathnormal" style="margin-right:0.10764em;">f</span><span class="mord mathnormal">b</span><span class="mord"><span class="mord">11</span></span><span class="mord mathnormal">e</span><span class="mord mathnormal" style="margin-right:0.01968em;">l</span><span class="mord mathnormal">se</span><span class="mord"><span class="mord">40</span></span></span><span class="mord mathnormal">e</span><span class="mord mathnormal" style="margin-right:0.01968em;">l</span><span class="mord mathnormal">se</span><span class="mord"><span class="mord mathnormal">i</span><span class="mord mathnormal" style="margin-right:0.10764em;">f</span><span class="mord mathnormal">b</span><span class="mord"><span class="mord">10</span></span><span class="mord mathnormal">e</span><span class="mord mathnormal" style="margin-right:0.01968em;">l</span><span class="mord mathnormal">se</span><span class="mord"><span class="mord">20</span></span></span><span class="mord mathnormal">c</span><span class="mspace" style="margin-right:0.2222222222222222em;"></span><span class="mbin">+</span><span class="mspace" style="margin-right:0.2222222222222222em;"></span></span><span class="base"><span class="strut" style="height:0.8888799999999999em;vertical-align:-0.19444em;"></span><span class="mord">2</span><span class="mord mathnormal" style="margin-right:0.03588em;">v</span><span class="mord mathnormal">a</span><span class="mord mathnormal" style="margin-right:0.03588em;">g</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal">an</span><span class="mord mathnormal">t</span><span class="mord">@</span><span class="mord mathnormal" style="margin-right:0.03588em;">v</span><span class="mord mathnormal">a</span><span class="mord mathnormal" style="margin-right:0.03588em;">g</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal">an</span><span class="mord mathnormal">t</span><span class="mspace" style="margin-right:0.2777777777777778em;"></span><span class="mrel">:</span><span class="mspace" style="margin-right:0.2777777777777778em;"></span></span><span class="base"><span class="strut" style="height:1em;vertical-align:-0.25em;"></span><span class="mord">/</span><span class="mord mathnormal" style="margin-right:0.03588em;">v</span><span class="mord mathnormal">a</span><span class="mord mathnormal" style="margin-right:0.03588em;">g</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal">an</span><span class="mord mathnormal">t</span></span></span></span> cargo run
Running `target/debug/main`
vagrant@vagrant:/vagrant<span class="katex"><span class="katex-html" aria-hidden="true"><span class="base"><span class="strut" style="height:0.77777em;vertical-align:-0.08333em;"></span><span class="mord mathnormal" style="margin-right:0.01968em;">ll</span><span class="mord mathnormal">i</span><span class="mspace" style="margin-right:0.2222222222222222em;"></span><span class="mbin">−</span><span class="mspace" style="margin-right:0.2222222222222222em;"></span></span><span class="base"><span class="strut" style="height:0.8888799999999999em;vertical-align:-0.19444em;"></span><span class="mord">3.8</span><span class="mord mathnormal">o</span><span class="mord mathnormal">u</span><span class="mord mathnormal">t</span><span class="mord">.</span><span class="mord mathnormal" style="margin-right:0.01968em;">ll</span><span class="mpunct">;</span><span class="mspace" style="margin-right:0.16666666666666666em;"></span><span class="mord mathnormal">ec</span><span class="mord mathnormal">h</span><span class="mord mathnormal">o</span></span></span></span>?
42
太酷了!下面是我们提供的示例输入程序的IR:
; ModuleID = 'example_module'
define i64 @main() {
entry:
%a = alloca i64
%b = alloca i64
%c = alloca i64
store i64 1, i64* %a
store i64 0, i64* %b
%a1 = load i64, i64* %a
%is_nonzero = icmp ne i64 %a1, 0
br i1 %is_nonzero, label %entry2, label %entry3
entry2: ; preds = %entry
%b5 = load i64, i64* %b
%is_nonzero6 = icmp ne i64 %b5, 0
br i1 %is_nonzero6, label %entry7, label %entry8
entry3: ; preds = %entry
%b10 = load i64, i64* %b
%is_nonzero11 = icmp ne i64 %b10, 0
br i1 %is_nonzero11, label %entry12, label %entry13
entry4: ; preds = %entry14, %entry9
%iftmp16 = phi i64 [ %iftmp, %entry9 ], [ %iftmp15, %entry14 ]
store i64 %iftmp16, i64* %c
%c17 = load i64, i64* %c
%addtmp = add i64 %c17, 2
ret i64 %addtmp
entry7: ; preds = %entry2
br label %entry9
entry8: ; preds = %entry2
br label %entry9
entry9: ; preds = %entry8, %entry7
%iftmp = phi i64 [ 11, %entry7 ], [ 40, %entry8 ]
br label %entry4
entry12: ; preds = %entry3
br label %entry14
entry13: ; preds = %entry3
br label %entry14
entry14: ; preds = %entry13, %entry12
%iftmp15 = phi i64 [ 10, %entry12 ], [ 20, %entry13 ]
br label %entry4
}
请注意:这些块具有以下的模式:不包含第一个条目,它们三个为一组,第一个是“then”分支,然后是“else”分支,最后是“merge”块(带有可识别的phi指令)。每一次我们遇到“if”表达式时都会在main后面附加三个新块。因为要在AST中递归查询三元组,所以块的三元组是有序的。
这就是我想要分享的全部内容!希望在这一点上你可以有足够的实力来决定你的命运。
使用 nom 解析 url
原文

在本教程中,我们将演示如何使用 nom 解析器组合器库在 Rust 中编写一个非常基础的 URL 解析器。我们将包含以下内容
- 什么是解析器组合器?
- nom是如何工作的
- 设置nom
- 数据类型
- nom中的错误处理
- 使用Rust写一个解析器
- 解析待授权的URL
- Rust解析:主机,IP和端口
- 使用Rust解析路径
- 查询和片段
- 在Rust中使用nom解析:最终的测试
什么是解析器组合器?
解析器组合器是高阶函数,可以接受多个解析器作为输入,并返回一个新的解析器作为输出。
这种方式让你可以为简单的任务(如:解析某个字符串或数字)构建解析器,并使用组合器函数将它们组合成一个递归下降(recursive descent)的解析器。
组合解析的好处包括可测试性,可维护性和可读性。每个部件都非常小且具有自我隔离性,从而使整个解析器由模块化组件构成。
如果你对这个概念不熟悉,我强烈推荐你阅读 Bodil Stokke 的用 Rust 学习解析器组合器。
nom是如何工作的
nom 是使用 Rust 编写的解析器组合器库,它可以让你创建安全的解析器,而不会占用内存或影响性能。它依靠 Rust 强大的类型系统和内存安全来生成既正确又高效的解析器,并使用函数,宏和特征来抽象出容易出错的管道。
为了演示 nom 是如何工作的,我们将创建一个基础的 URL 解析器。我们不会完整的实现 URL 规范;这将远远超出此代码示例的范围。相反,我们将采用一些捷径。
最终的目标是能够将合法的 URL (如:https://www.zupzup.org/about/?someVal=5&anotherVal=hello#anchor 和 http://user:pw@127.0.0.1:8080) 解析成相关的结构,并在解析过程中为非法的 URL 返回一个有用的错误。
而且,由于可测试性被认为是解析器组合器的一大优势,我们将对大多数组件进行测试,以了解其具体的优势。
让我们开始吧!
设置nom
为了进行下面的一系列操作,你需要安装最新的 Rust 版本 (1.44+)。
首先,创建一个新的 Rust 项目:
cargo new --lib rust-nom-example
cd rust-nom-example
然后,编辑Cargo.toml文件并添加你需要的依赖:
[dependencies]
nom = "6.0"
是的,我们需要的是最新版本的nom库(在撰写本文时是 6.0)。
数据类型
编写解析器时,通常先定义输出结构以了解你需要哪些部分是很有意义的。
在这里,我们正在解析一个 URL,因此,让我们给它定义一个结构:
#![allow(unused)] fn main() { #[derive(Debug, PartialEq, Eq)] pub struct URI<'a> { scheme: Scheme, authority: Option<Authority<'a>>, host: Host, port: Option<u16>, path: Option<Vec<&'a str>>, query: Option<QueryParams<'a>>, fragment: Option<&'a str>, } #[derive(Debug, PartialEq, Eq)] pub enum Scheme { HTTP, HTTPS, } pub type Authority<'a> = (&'a str, Option<&'a str>); #[derive(Debug, PartialEq, Eq)] pub enum Host { HOST(String), IP([u8; 4]), } pub type QueryParam<'a> = (&'a str, &'a str); pub type QueryParams<'a> = Vec<QueryParam<'a>>; }
让我们逐行进行说明。
这些字段是根据它们在常规 URI 中出现的顺序进行排列的。首先,我们有 scheme。在这里,我们将 URI 的前缀限制为http://和https://,但是请注意,这里还有很多其它可选的 scheme。
接下来是authority部分,它由用户名和可选密码组成,通常是完全可选的。
host 可以是 IP,(在我们的示例中仅为 IPv4),也可以是主机字符串,如:example.org,后面跟一个可选的port,port 仅是个数字:如:localhost:8080。
在端口之后是 path。它是由/分割的字符串序列,如:/some/important/path。query 和 fragment 部分是可选的,它们表示 URL 的?query=some-value&another=5和#anchor部分。query 是字符串元组的可选列表,而 fragment 只是可选字符串(完整的 URL 示例是https://some/important/?query=some-value&another=5#anchor)。
如果你对这些类型中的生命周期('a)感到困惑,请不用感到沮丧;它不会真的影响到我们写代码的方式。本质上,我们可以使用指向输入字符串各部分的指针,而不是为 URL 的每一部分分配新的字符串,只要输入的生命周期和我们 URI 结构一样长就可以了。
在开始解析之前,让我们实现From特征将合法的 scheme 转换成Scheme枚举:
#![allow(unused)] fn main() { impl From<&str> for Scheme { fn from(i: &str) -> Self { match i.to_lowercase().as_str() { "http://" => Scheme::HTTP, "https://" => Scheme::HTTPS, _ => unimplemented!("no other schemes supported"), } } } }
顺便说一句,让我们从顶部开始,开始解析 scheme。
nom中的错误处理
在我们开始之前,先讨论一下 nom 中的错误处理。虽然我们不会面面俱到,但是至少会让调用者大致了解在解析的哪一步出了什么问题。
为了达到我们的目的,我们将使用nom中的context组合器。在nom中,一个解析器通常会返回如下类型:
#![allow(unused)] fn main() { type IResult<I, O, E = (I, ErrorKind)> = Result<(I, O), Err<E>>; }
在本例中,我们将返回一个输入值(&str - 输入字符串)的元组类型。它包含仍需要解析的字符串,以及输出的值。当解析失败时,它也会返回一个错误。
标准的IResult只允许我们使用 nom 内置的错误类型,如果我们想要创建自定义的错误类型以及在这些错误中添加一些上下文呢?
ParserError 特征和 VerboseError 类型让我们可以构建自己的错误类型,并可以在已有的错误中添加上下文。在这个简单的例子中,我们将会在我们的解析错误类型中添加上下文。为了方便起见,让我们定义一个自己的结果类型。
#![allow(unused)] fn main() { type Res<T, U> = IResult<T, U, VerboseError<T>>; }
除了它带有VerboseError之外,本质上是相同的。这意味着我们可以使用 nom 的上下文组合器,它允许我们在任何解析器中隐式地添加错误上下文。
nom 的官方文档包含这些选项,但是错误处理并不是最直观的方法。
为了看到它的实际效果,让我们为该 scheme 创建第一个解析器。
使用Rust写一个解析器
为了解析 URL 的scheme,我们想要匹配http://和https://,除此之外没有别的了。由于我们使用的是功能强大的解析器组合器库,因此我们不需要手动编写底层的解析器。nom 已经帮我们覆盖了。
解析器组合器宏清单讲述了在某些用例中如何使用 nom 中的解析器组合器。
我们将会使用tag_no_case解析器和alt组合器来做基础的说明:“每个小写(输入)应该是http://或https://” 。在本教程中,我们将只使用常规函数,但请注意,nom 中的许多解析器和组合器也可以作为宏使用。
在 Rust 中使用 nom 如下所示:
#![allow(unused)] fn main() { fn scheme(input: &str) -> Res<&str, Scheme> { context( "scheme", alt((tag_no_case("HTTP://"), tag_no_case("HTTPS://"))), )(input) .map(|(next_input, res)| (next_input, res.into())) } }
如你所示:我们使用context组合器封装了实际的解析器并在其中添加了scheme上下文,因此,此处触发的任何错误都将在结果中标记为scheme。
一旦将解析器和组合器组装成了整个解析器,便使用输入字符串来调用它,这是我们唯一的输入参数。然后我们对结果进行map - 如上所述,它由剩余的输入和解析的输出组成,并通过实现前面提到的.into()特征将我们解析后的 scheme 转换成Scheme枚举。
#![allow(unused)] fn main() { #[cfg(test)] mod tests { use super::*; use nom::{ error::{ErrorKind, VerboseError, VerboseErrorKind}, Err as NomErr, }; #[test] fn test_scheme() { assert_eq!(scheme("https://yay"), Ok(("yay", Scheme::HTTPS))); assert_eq!(scheme("http://yay"), Ok(("yay", Scheme::HTTP))); assert_eq!( scheme("bla://yay"), Err(NomErr::Error(VerboseError { errors: vec![ ("bla://yay", VerboseErrorKind::Nom(ErrorKind::Tag)), ("bla://yay", VerboseErrorKind::Nom(ErrorKind::Alt)), ("bla://yay", VerboseErrorKind::Context("scheme")), ] })) ); } } }
如你所见,在成功的情况下,我们取回已解析Scheme枚举和剩余待解析的字符串(yay)。另外,如果有错误,我们将列举出已触发的错误以及定义的上下文列表(scheme)。
在本例中,两次tag调用都失败了,因此,alt组合器也失败了,因为它无法产生单个值。
那不是很难。在上面我们基本上只是解析了一个常量的字符串,让我们通过解析authority部分来尝试更高级的内容。
解析待授权的URL
如果我们还记得我们在之前的 URI 的结构,尤其是 authority 部分,我们会看到我们正在寻找一个完全可选的结构。如果它存在,则需要一个用户名和一个可选的密码。
这是我们使用的类型别名:
#![allow(unused)] fn main() { pub type Authority<'a> = (&'a str, Option<&'a str>); }
我们该怎么办呢?在 URL 中,它看起来像:
https://username:password@example.org
:password是可选的,但是在任何情况下,它都会以@作为结尾,所以我们可以通过使用terminated解析器开始。这给了我们一个字符串,该字符串是通过终止另一个字符串得到的。
在authority部分中,我们看到:作为一个分隔符。根据文档,我们可以使用separated_pair组合器,它通过分割一个字符串给我们提供了两个值。但是我们如何处理实际的文本呢?这里有几种选项,一种是使用alphanumeric1解析器。它生成了一个至少包含一个字符的字母数字字符串。
为了简单起见,我们不必担心可以在 URL 的不同部分使用哪些字符。这与编写和构造解析器无关,只会使所有的内容变得更长且更不方便。出于我们的目的,我们假设 URL 的大部分都可以由字母数字组成,有时候还包含连字符和点 - 根据 URL 标准,这当然是错误的。
让我们来看看组合后的authority解析器:
#![allow(unused)] fn main() { fn authority(input: &str) -> Res<&str, (&str, Option<&str>)> { context( "authority", terminated( separated_pair(alphanumeric1, opt(tag(":")), opt(alphanumeric1)), tag("@"), ), )(input) } }
我们通过运行一些测试用例来检验它是否工作:
#![allow(unused)] fn main() { #[test] fn test_authority() { assert_eq!( authority("username:password@zupzup.org"), Ok(("zupzup.org", ("username", Some("password")))) ); assert_eq!( authority("username@zupzup.org"), Ok(("zupzup.org", ("username", None))) ); assert_eq!( authority("zupzup.org"), Err(NomErr::Error(VerboseError { errors: vec![ (".org", VerboseErrorKind::Nom(ErrorKind::Tag)), ("zupzup.org", VerboseErrorKind::Context("authority")), ] })) ); assert_eq!( authority(":zupzup.org"), Err(NomErr::Error(VerboseError { errors: vec![ ( ":zupzup.org", VerboseErrorKind::Nom(ErrorKind::AlphaNumeric) ), (":zupzup.org", VerboseErrorKind::Context("authority")), ] })) ); assert_eq!( authority("username:passwordzupzup.org"), Err(NomErr::Error(VerboseError { errors: vec![ (".org", VerboseErrorKind::Nom(ErrorKind::Tag)), ( "username:passwordzupzup.org", VerboseErrorKind::Context("authority") ), ] })) ); assert_eq!( authority("@zupzup.org"), Err(NomErr::Error(VerboseError { errors: vec![ ( "@zupzup.org", VerboseErrorKind::Nom(ErrorKind::AlphaNumeric) ), ("@zupzup.org", VerboseErrorKind::Context("authority")), ] })) ) } }
看起来很不错!对于各种情况,我们都有与之对应的测试用例,缺少密码,缺少@以及其他几种错误的情况。
让我们继续来到 host 部分。
Rust解析:主机,IP和端口
因为 host 部分可以包含 主机字符串或者 IP,这一步将会有点复杂。更糟的是,在结尾还有一个可选的:port。
为了尽可能保持简单,我们只支持 IPv4 的 IP。我们将从 host 开始。让我们看一下它的实现并逐行进行说明。
#![allow(unused)] fn main() { fn host(input: &str) -> Res<&str, Host> { context( "host", alt(( tuple((many1(terminated(alphanumerichyphen1, tag("."))), alpha1)), tuple((many_m_n(1, 1, alphanumerichyphen1), take(0 as usize))), )), )(input) .map(|(next_input, mut res)| { if !res.1.is_empty() { res.0.push(res.1); } (next_input, Host::HOST(res.0.join("."))) }) } }
首先你注意到这里有两个选项(alt)。在这两种情况下,都有一个元组,并包含了一个解析器链。
在第一种情况下,我们想要一个或多个(many1)字母数字字符串,包含一个连字符,被一个.终结并以顶级域名 (alpha1) 结尾。
alphanumerichyphen1解析器如下所示:
#![allow(unused)] fn main() { fn alphanumerichyphen1<T>(i: T) -> Res<T, T> where T: InputTakeAtPosition, <T as InputTakeAtPosition>::Item: AsChar, { i.split_at_position1_complete( |item| { let char_item = item.as_char(); !(char_item == '-') && !char_item.is_alphanum() }, ErrorKind::AlphaNumeric, ) } }
这有点复杂,但基本上是 nom 中alphanumeric1解析器带有-的复制版本。我不知道它是否是最好的方式,但是它确实有用。
在任何情况下,主机部分都有第二个选项,它是一个字符串,如:localhost。
为什么我们要用将1和1传给many_m_n解析器这种看起来很无用的方式来表示呢?这里的问题是,在alt组合器中,所有的选项都必须返回相同的类型 - 在这里,它是一个字符串向量和另一个字符串的元组。
我们也在map函数中看到,如果元组的第二部分不为空(顶级域名),则将其添加到元组的第一部分。最后,我们构建了一个 HOST 枚举,将字符串部分用一个.相连,并创建了一个原始的主机字符串。
让我们来看一些测试用例:
#![allow(unused)] fn main() { #[test] fn test_host() { assert_eq!( host("localhost:8080"), Ok((":8080", Host::HOST("localhost".to_string()))) ); assert_eq!( host("example.org:8080"), Ok((":8080", Host::HOST("example.org".to_string()))) ); assert_eq!( host("some-subsite.example.org:8080"), Ok((":8080", Host::HOST("some-subsite.example.org".to_string()))) ); assert_eq!( host("example.123"), Ok((".123", Host::HOST("example".to_string()))) ); assert_eq!( host(".com"), Err(NomErr::Error(VerboseError { errors: vec![ (".com", VerboseErrorKind::Nom(ErrorKind::AlphaNumeric)), ("<span class="katex"><span class="katex-html" aria-hidden="true"><span class="base"><span class="strut" style="height:0.8888799999999999em;vertical-align:-0.19444em;"></span><span class="mord">.</span><span class="mord mathnormal">co</span><span class="mord mathnormal">m</span><span class="mord">"</span><span class="mpunct">,</span><span class="mspace" style="margin-right:0.16666666666666666em;"></span><span class="mord mathnormal" style="margin-right:0.22222em;">V</span><span class="mord mathnormal" style="margin-right:0.02778em;">er</span><span class="mord mathnormal">b</span><span class="mord mathnormal">ose</span><span class="mord mathnormal" style="margin-right:0.05764em;">E</span><span class="mord mathnormal" style="margin-right:0.07153em;">rrorK</span><span class="mord mathnormal">in</span><span class="mord mathnormal">d</span><span class="mspace" style="margin-right:0.2777777777777778em;"></span><span class="mrel">::</span><span class="mspace" style="margin-right:0.2777777777777778em;"></span></span><span class="base"><span class="strut" style="height:1em;vertical-align:-0.25em;"></span><span class="mord mathnormal" style="margin-right:0.10903em;">N</span><span class="mord mathnormal">o</span><span class="mord mathnormal">m</span><span class="mopen">(</span><span class="mord mathnormal" style="margin-right:0.05764em;">E</span><span class="mord mathnormal" style="margin-right:0.07153em;">rrorK</span><span class="mord mathnormal">in</span><span class="mord mathnormal">d</span><span class="mspace" style="margin-right:0.2777777777777778em;"></span><span class="mrel">::</span><span class="mspace" style="margin-right:0.2777777777777778em;"></span></span><span class="base"><span class="strut" style="height:1em;vertical-align:-0.25em;"></span><span class="mord mathnormal" style="margin-right:0.10903em;">M</span><span class="mord mathnormal">an</span><span class="mord mathnormal" style="margin-right:0.03588em;">y</span><span class="mord mathnormal" style="margin-right:0.10903em;">MN</span><span class="mclose">))</span><span class="mpunct">,</span><span class="mspace" style="margin-right:0.16666666666666666em;"></span><span class="mopen">(</span><span class="mord">"</span></span></span></span>.com", VerboseErrorKind::Nom(ErrorKind::Alt)), (".com", VerboseErrorKind::Context("host")), ] })) ); assert_eq!( host(".com"), Err(NomErr::Error(VerboseError { errors: vec![ (".com", VerboseErrorKind::Nom(ErrorKind::AlphaNumeric)), (".com", VerboseErrorKind::Nom(ErrorKind::ManyMN)), (".com", VerboseErrorKind::Nom(ErrorKind::Alt)), (".com", VerboseErrorKind::Context("host")), ] })) ); } }
让我们来到 主机是 IP 的情况。首先,我们需要能够解析 IPv4 的 IP 中每一个的部分(如:127.0.0.1):
#![allow(unused)] fn main() { fn ip_num(input: &str) -> Res<&str, u8> { context("ip number", n_to_m_digits(1, 3))(input).and_then(|(next_input, result)| { match result.parse::<u8>() { Ok(n) => Ok((next_input, n)), Err(_) => Err(NomErr::Error(VerboseError { errors: vec![] })), } }) } fn n_to_m_digits<'a>(n: usize, m: usize) -> impl FnMut(&'a str) -> Res<&str, String> { move |input| { many_m_n(n, m, one_of("0123456789"))(input) .map(|(next_input, result)| (next_input, result.into_iter().collect())) } } }
为了获取每一个数字,我们尝试使用n_to_m_digits解析器来寻找一到三个连续的数字并将他们转换成 u8。
通过这种方式,我们可以查看如何将完整的 IP 解析成u8数组:
#![allow(unused)] fn main() { fn ip(input: &str) -> Res<&str, Host> { context( "ip", tuple((count(terminated(ip_num, tag(".")), 3), ip_num)), )(input) .map(|(next_input, res)| { let mut result: [u8; 4] = [0, 0, 0, 0]; res.0 .into_iter() .enumerate() .for_each(|(i, v)| result[i] = v); result[3] = res.1; (next_input, Host::IP(result)) }) } }
在这里,我们要查找的查好是3个后面跟.的ip_num,然后是另一个ip_num。在映射函数中,我们将这些独立的结果拼接,从而将u8数组转换成Host::IP枚举。
再一次,我们将写一些测试用例来确保它是正常工作的:
#![allow(unused)] fn main() { #[test] fn test_ipv4() { assert_eq!( ip("192.168.0.1:8080"), Ok((":8080", Host::IP([192, 168, 0, 1]))) ); assert_eq!(ip("0.0.0.0:8080"), Ok((":8080", Host::IP([0, 0, 0, 0])))); assert_eq!( ip("1924.168.0.1:8080"), Err(NomErr::Error(VerboseError { errors: vec![ ("4.168.0.1:8080", VerboseErrorKind::Nom(ErrorKind::Tag)), ("1924.168.0.1:8080", VerboseErrorKind::Nom(ErrorKind::Count)), ("1924.168.0.1:8080", VerboseErrorKind::Context("ip")), ] })) ); assert_eq!( ip("192.168.0000.144:8080"), Err(NomErr::Error(VerboseError { errors: vec![ ("0.144:8080", VerboseErrorKind::Nom(ErrorKind::Tag)), ( "192.168.0000.144:8080", VerboseErrorKind::Nom(ErrorKind::Count) ), ("192.168.0000.144:8080", VerboseErrorKind::Context("ip")), ] })) ); assert_eq!( ip("192.168.0.1444:8080"), Ok(("4:8080", Host::IP([192, 168, 0, 144]))) ); assert_eq!( ip("192.168.0:8080"), Err(NomErr::Error(VerboseError { errors: vec![ (":8080", VerboseErrorKind::Nom(ErrorKind::Tag)), ("192.168.0:8080", VerboseErrorKind::Nom(ErrorKind::Count)), ("192.168.0:8080", VerboseErrorKind::Context("ip")), ] })) ); assert_eq!( ip("999.168.0.0:8080"), Err(NomErr::Error(VerboseError { errors: vec![ ("999.168.0.0:8080", VerboseErrorKind::Nom(ErrorKind::Count)), ("999.168.0.0:8080", VerboseErrorKind::Context("ip")), ] })) ); } }
将它们放置在一起,我们需要另一个可以同时解析 IP 和 host 的解析器,并返回一个Host:
#![allow(unused)] fn main() { fn ip_or_host(input: &str) -> Res<&str, Host> { context("ip or host", alt((ip, host)))(input) } }
最后,让我们来解析端口(原文遗漏):
#![allow(unused)] fn main() { fn port(input: &str) -> Res<&str, u16> { context( "port", tuple(( tag(":"), n_to_m_digits(1, 5) )), )(input) .and_then(|(next_input, result)| { let port = result.1.parse::<u16>(); match port { Ok(port) => Ok((next_input, port)), Err(e) => Err(NomErr::Error(VerboseError { errors: vec![ (input, VerboseErrorKind::Nom(ErrorKind::Digit))] })) } }) } }
并使用一些测试用例保证它是可以正常工作的:
#![allow(unused)] fn main() { #[test] fn test_port() { assert_eq!(port(":0"), Ok(("", 0u16))); assert_eq!(port(":65535"), Ok(("", 65535u16))); assert_eq!( port(":65536"), Err(NomErr::Error(VerboseError { errors: vec![ (":65536", VerboseErrorKind::Nom(ErrorKind::Digit)) ] }))); assert_eq!( port(":a"), Err(NomErr::Error(VerboseError { errors: vec![ ("a", VerboseErrorKind::Nom(ErrorKind::OneOf)), ("a", VerboseErrorKind::Nom(ErrorKind::ManyMN)), (":a", VerboseErrorKind::Context("port")) ] }))); } }
还不错,一切正常!
使用Rust解析路径
下一步是解决路径问题。在此,我们再次假设该路径中的字符串只能包含带有连字符和点的字母数字字符串,并使用以下帮助程序进行解析:
#![allow(unused)] fn main() { fn url_code_points<T>(i: T) -> Res<T, T> where T: InputTakeAtPosition, <T as InputTakeAtPosition>::Item: AsChar, { i.split_at_position1_complete( |item| { let char_item = item.as_char(); !(char_item == '-') && !char_item.is_alphanum() && !(char_item == '.') // ... actual ascii code points and url encoding...: https://infra.spec.whatwg.org/#ascii-code-point }, ErrorKind::AlphaNumeric, ) } }
为了解析path,我们希望可以将由/分隔的字符串解析成字符串向量:
#![allow(unused)] fn main() { fn path(input: &str) -> Res<&str, Vec<&str>> { context( "path", tuple(( tag("/"), many0(terminated(url_code_points, tag("/"))), opt(url_code_points), )), )(input) .map(|(next_input, res)| { let mut path: Vec<&str> = res.1.iter().map(|p| p.to_owned()).collect(); if let Some(last) = res.2 { path.push(last); } (next_input, path) }) } }
我们总是由/开始。这已经是一个合法的路径了,但是我们仍然可以有0个或更多个(many0)由/分隔的字符串,后面跟一个最终的可选的字符串(如:index.php)。
在映射中,我们检查元组的第三部分(最后一部分)是否存在,如果存在,则将其添加到路径向量中。
让我们为路径也写一点测试用例:
#![allow(unused)] fn main() { #[test] fn test_path() { assert_eq!(path("/a/b/c?d"), Ok(("?d", vec!["a", "b", "c"]))); assert_eq!(path("/a/b/c/?d"), Ok(("?d", vec!["a", "b", "c"]))); assert_eq!(path("/a/b-c-d/c/?d"), Ok(("?d", vec!["a", "b-c-d", "c"]))); assert_eq!(path("/a/1234/c/?d"), Ok(("?d", vec!["a", "1234", "c"]))); assert_eq!( path("/a/1234/c.txt?d"), Ok(("?d", vec!["a", "1234", "c.txt"])) ); } }
看起来不错!我们获取到了路径中的不同部分以及剩余的字符串,并且它们都被添加到了字符串向量中了。
让我们通过解析 query 和 URL 部分的 fragment 来增强功能。
查询和片段
查询主要是由键值对组成:第一个键前面跟一个?,其余的查询由&进行分隔。再一次,我们将自己限制为有限的url_code_points。
#![allow(unused)] fn main() { fn query_params(input: &str) -> Res<&str, QueryParams> { context( "query params", tuple(( tag("?"), url_code_points, tag("="), url_code_points, many0(tuple(( tag("&"), url_code_points, tag("="), url_code_points, ))), )), )(input) .map(|(next_input, res)| { let mut qps = Vec::new(); qps.push((res.1, res.3)); for qp in res.4 { qps.push((qp.1, qp.3)); } (next_input, qps) }) } }
实际上这相当不错,因为解析器是非常直观(intuitive)且可读性的。我们解析?后面的第一个键值对的元组,使用=分隔,然后同样的操作执行0或多次,它们是以&而不是?开头。
然后,在映射中,我们简单的将所有的键值对放在向量中,然后就有了我们在文章的开头定义的结构。
#![allow(unused)] fn main() { pub type QueryParam<'a> = (&'a str, &'a str); pub type QueryParams<'a> = Vec<QueryParam<'a>>; }
这里有一组基础的测试用例:
#![allow(unused)] fn main() { #[test] fn test_query_params() { assert_eq!( query_params("?bla=5&blub=val#yay"), Ok(("#yay", vec![("bla", "5"), ("blub", "val")])) ); assert_eq!( query_params("?bla-blub=arr-arr#yay"), Ok(("#yay", vec![("bla-blub", "arr-arr"),])) ); } }
最后一部分是 fragment,它其实就是一个#后面跟一个字符串:
#![allow(unused)] fn main() { fn fragment(input: &str) -> Res<&str, &str> { context("fragment", tuple((tag("#"), url_code_points)))(input) .map(|(next_input, res)| (next_input, res.1)) } }
在介绍了所有这些复杂的解析器之后,为了达到良好的效果,让我们编写一些完整性检查测试:
#![allow(unused)] fn main() { #[test] fn test_fragment() { assert_eq!(fragment("#bla"), Ok(("", "bla"))); assert_eq!(fragment("#bla-blub"), Ok(("", "bla-blub"))); } }
在Rust中使用nom解析:最终的测试
让我们将它们都放在最顶层的 URI 解析器函数中:
#![allow(unused)] fn main() { pub fn uri(input: &str) -> Res<&str, URI> { context( "uri", tuple(( scheme, opt(authority), ip_or_host, opt(port), opt(path), opt(query_params), opt(fragment), )), )(input) .map(|(next_input, res)| { let (scheme, authority, host, port, path, query, fragment) = res; ( next_input, URI { scheme, authority, host, port, path, query, fragment, }, ) }) } }
我们有一个强制的(mandatory)scheme,后面跟一个可选的authority,然后再跟一个强制的ip 或 host。最后后面跟可选的port,path,query 参数,和一个fragment。
在映射中,剩下的唯一一件事就是将解析后的元素构成成我们的URI结构。
在这一点上,你可以看到整个结构的美观性和模块化。如果 uri 函数是你的起点,那么你可以从头到尾查看每个单独的解析器,以了解整个过程在做什么。
当然,我们也需要对uri解析器进行一些测试:
#![allow(unused)] fn main() { #[test] fn test_uri() { assert_eq!( uri("https://www.zupzup.org/about/"), Ok(( "", URI { scheme: Scheme::HTTPS, authority: None, host: Host::HOST("www.zupzup.org".to_string()), port: None, path: Some(vec!["about"]), query: None, fragment: None } )) ); assert_eq!( uri("http://localhost"), Ok(( "", URI { scheme: Scheme::HTTP, authority: None, host: Host::HOST("localhost".to_string()), port: None, path: None, query: None, fragment: None } )) ); assert_eq!( uri("https://www.zupzup.org:443/about/?someVal=5#anchor"), Ok(( "", URI { scheme: Scheme::HTTPS, authority: None, host: Host::HOST("www.zupzup.org".to_string()), port: Some(443), path: Some(vec!["about"]), query: Some(vec![("someVal", "5")]), fragment: Some("anchor") } )) ); assert_eq!( uri("http://user:pw@127.0.0.1:8080"), Ok(( "", URI { scheme: Scheme::HTTP, authority: Some(("user", Some("pw"))), host: Host::IP([127, 0, 0, 1]), port: Some(8080), path: None, query: None, fragment: None } )) ); } }
它没问题!你可以在 Github找到完整的代码。
结论
真是太好了!我希望本文能够使你对 Rust 中的解析器特别是解析器组合器感到兴奋。
nom库解析速度特别快,是很多生产级别的库和系统的基础。除此之外,它还提供了出色的 API 和文档。
Rust 生态系统还提供了更多的解析选项,如:combine 和 pest。
Rust 中异步编程实用介绍
在本文中,我们将探讨一个使用 Tokio 运行时在 Rust 中进行异步编程的简短示例,展示了不同的执行场景。这篇文章主要是针对异步编程的初学者的。
这个示例的代码可以在 Github 中获取,也可以使用基于async-std运行时的分支(由 @BartMassey 贡献)。
什么是异步编程
异步编程可以让你在等待 I/O 操作(通常是网络请求或响应)结果的同时,即使在单个 OS 线程中,也可以继续执行计算。
这是通过使用异步运行时来实现的,该运行时将异步任务(即:绿色线程)分配给实际的 OS 线程。
与 OS 线程不同,创建绿色线程并不昂贵,因此我们不必担心是否达到了硬件限制。而 OS 线程需要维护自己的堆栈,因此在处理多个线程时会占用大量内存。在 Linux 中你可以使用cat /proc/sys/kernel/threads-max命令来查看每个进程的线程数限制,我的是 127162。
例如,如果我们需要一个单独的 OS 线程来处理 Web 服务器上的每个请求,这将是一个重大的问题,这是 C10k 问题的根源 - 如何处理 Web 服务器上的 10000 个连接。
早期的 Web 服务器确实为每个请求分配了独立的 OS 线程,以便并行处理每个请求。但是这会造成这些线程花费了大量的时间来等待网络响应,而不是做其他的计算。
Async 和 await
Rust 已经采用 async/await 语法定义异步代码块和函数。
async关键字定义了异步代码块和函数。它被指定返回了一个Future - 一个需要在其他地方.await以触发任务执行(注意延迟执行),并等待可用的返回的值。
.await关键字(必须被用于async代码块/函数中)用于异步等待异步任务的完成并获取返回值。请注意,虽然在Future准备好之前任务本身无法进行,但是实际的 OS 线程却可以在运行时分配其他的任务,因此 (OS 线程)可以继续工作。
高效的任务正在通知运行时,这时它可能会导致执行另一个任务(最终,另一个任务也将等待某个事件,如果此任务中的Future准备就绪,则该任务可以继续执行) - 这是多任务协作的实现。
这种语法非常优雅,它使我们可以编写异步程序,该程序的结构类似于简单的同步程序。
我们应该什么时候使用异步?
当线程原本只是在等待 I/O 操作(例如:发出网络请求或响应,对磁盘的读写以及等待用户的输入)时,异步编程将会很有用。
如果你始终都在计算并且没有等待 I/O 操作,异步编程其实用处不大,即使这些计算可以并行运行(如在光线跟踪器中),它对你的帮助也十分有限。在这种情况下,最好直接在 OS 线程上并行执行计算(利用 CPU 中的多个内核),如在rayon库中使用并行迭代器(如果你想要进行线程级别的控制,则可以使用crossbeam和threadpool库)。然而,请记住 Amdahl 定律,即算法优化改进可能会比专注于并行化产生更好的回报。
如果在等待 I/O 操作的同时没有其他任务可做,那它也没有用。例如,在上一篇博客中,当我们向 AWS Secrets Manager 请求数据库连接凭证时,Rusoto实际上返回的是一个RusotoFuture对象,但是在这种情况下,我们对 Lambda 函数的一次调用对应于一次请求 - 等待数据库凭证到达起见无需完成任何工作。因此我们可以仅使用同步编程(幸运的是,RusotoFuture提供了.sync()函数来做到这一点)。
示例
在此示例中,我们将模拟三个非常慢的网络请求,包括三个阶段:
- 连接 - 2秒的异步延迟
- 等待响应 - 8秒的异步延迟(延迟在服务端)
- 计算 - 4秒的同步延迟(如:它必须阻塞当前的 OS 线程去做计算)。
我们将使用 Tokio 作为本例中的异步运行时,因为它是目前 Rust 中最流行的异步框架。其他的异步框架如async-std运行时 - 基于async-std的本示例代码可以在 Github仓库的 async-std 分支上获取(由 @BartMassey贡献)。
请注意,两者都使用futures库,因此你可以在切换异步运行时的同时(whilst)保留大部分相同的 API。
Server
本示例的 server 代码改编自 tokio教程。它在延迟 8 秒后,打印接收到的字节。
完整的改编代码如下:
use futures::stream::StreamExt; use tokio::net::TcpListener; #[tokio::main] async fn main() { let addr = "127.0.0.1:6142"; let mut listener = TcpListener::bind(addr).await.unwrap(); let server = { async move { let mut incoming = listener.incoming(); while let Some(conn) = incoming.next().await { match conn { Err(e) => eprintln!("accept failed = {:?}", e), Ok(mut sock) => { tokio::spawn(async move { let (mut reader, mut writer) = sock.split(); tokio::time::delay_for(tokio::time::Duration::from_secs(8)).await; match tokio::io::copy(&mut reader, &mut writer).await { Ok(amt) => { println!("wrote {} bytes", amt); } Err(err) => { eprintln!("IO error {:?}", err); } } }); } } } } }; println!("Server running on localhost:6142"); server.await; }
同步请求
在同步的情况下,我们只需依次运行每个请求即可。因此我们预测完成 3 个任务的总执行时间为3 * ( 2 + 8 + 4) = 42秒。
我们可以用一张图对这种情况进行可视化:

我们实现这个仅需使用标准库:
use std::io::prelude::*; use std::net::TcpStream; use std::thread::sleep; use std::time::Instant; fn main() -> Result<(), Box<dyn std::error::Error>> { let now = Instant::now(); task("task1", now.clone())?; task("task2", now.clone())?; task("task3", now.clone())?; Ok(()) } fn task(label: &str, now: std::time::Instant) -> Result<(), Box<dyn std::error::Error>> { // Simulate network delay using thread sleep for 2 seconds println!( "OS Thread {:?} - {} started: {:?}", std::thread::current().id(), label, now.elapsed(), ); sleep(std::time::Duration::from_secs(2)); // Write to server - server will echo this back to us with 8 second delay let mut stream = TcpStream::connect("127.0.0.1:6142")?; stream.write_all(label.as_bytes())?; println!( "OS Thread {:?} - {} written: {:?}", std::thread::current().id(), label, now.elapsed() ); // Read 5 chars we expect (to avoid dealing with EOF, etc.) let mut buffer = [0; 5]; stream.read_exact(&mut buffer)?; stream.shutdown(std::net::Shutdown::Both)?; println!( "OS Thread {:?} - {} read: {:?}", std::thread::current().id(), label, now.elapsed() ); // Simulate computation work by sleeping actual thread for 4 seconds sleep(std::time::Duration::from_secs(4)); println!( "OS Thread {:?} - {} finished: {:?}", std::thread::current().id(), std::str::from_utf8(&buffer)?, now.elapsed() ); Ok(()) }
运行这段代码:
<span class="katex"><span class="katex-html" aria-hidden="true"><span class="base"><span class="strut" style="height:0.7777700000000001em;vertical-align:-0.19444em;"></span><span class="mord mathnormal">c</span><span class="mord mathnormal">a</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal" style="margin-right:0.03588em;">g</span><span class="mord mathnormal" style="margin-right:0.02778em;">or</span><span class="mord mathnormal">u</span><span class="mord mathnormal">n</span><span class="mspace" style="margin-right:0.2222222222222222em;"></span><span class="mbin">−</span><span class="mspace" style="margin-right:0.2222222222222222em;"></span></span><span class="base"><span class="strut" style="height:0.77777em;vertical-align:-0.08333em;"></span><span class="mord">−</span><span class="mord mathnormal">re</span><span class="mord mathnormal" style="margin-right:0.01968em;">l</span><span class="mord mathnormal">e</span><span class="mord mathnormal">a</span><span class="mord mathnormal">se</span><span class="mspace" style="margin-right:0.2222222222222222em;"></span><span class="mbin">−</span><span class="mspace" style="margin-right:0.2222222222222222em;"></span></span><span class="base"><span class="strut" style="height:0.77777em;vertical-align:-0.08333em;"></span><span class="mord">−</span><span class="mord mathnormal">bin</span><span class="mord mathnormal" style="margin-right:0.02778em;">ser</span><span class="mord mathnormal" style="margin-right:0.03588em;">v</span><span class="mord mathnormal" style="margin-right:0.02778em;">er</span></span></span></span> cargo run --release --bin client_synchronous
OS Thread ThreadId(1) - task1 started: 578ns
OS Thread ThreadId(1) - task1 written: 2.000346788s
OS Thread ThreadId(1) - task1 read: 10.002177173s
OS Thread ThreadId(1) - task1 finished: 14.002328699s
OS Thread ThreadId(1) - task2 started: 14.002387112s
OS Thread ThreadId(1) - task2 written: 16.002673602s
OS Thread ThreadId(1) - task2 read: 24.006071003s
OS Thread ThreadId(1) - task2 finished: 28.006204147s
OS Thread ThreadId(1) - task3 started: 28.006263855s
OS Thread ThreadId(1) - task3 written: 30.00652763s
OS Thread ThreadId(1) - task3 read: 38.008234993s
OS Thread ThreadId(1) - task3 finished: 42.008389223s
准确给出了我们上面计算的 42 秒总执行时间。
同步请求 (Tokio)
请注意,在使用 Tokio 时(有时是无意间),可以从异步函数中获取同步行为。用 Tokio 实现上述功能:
use futures::stream::StreamExt; use std::error::Error; use std::thread::sleep; use std::time::Instant; use tokio::join; use tokio::net::TcpStream; use tokio::prelude::*; #[tokio::main] async fn main() -> Result<(), Box<dyn Error + Send + Sync>> { let now = Instant::now(); // Synchronous task("task1", now.clone()).await?; task("task2", now.clone()).await?; task("task3", now.clone()).await?; Ok(()) } async fn task(label: &str, now: std::time::Instant) -> Result<(), Box<dyn Error + Send + Sync>> { // Simulate network delay using Tokio async delay for 2 seconds println!( "OS Thread {:?} - {} started: {:?}", std::thread::current().id(), label, now.elapsed(), ); tokio::time::delay_for(tokio::time::Duration::from_secs(2)).await; // Write to server - server will echo this back to us with 8 second delay let mut stream = TcpStream::connect("127.0.0.1:6142").await?; stream.write_all(label.as_bytes()).await?; println!( "OS Thread {:?} - {} written: {:?}", std::thread::current().id(), label, now.elapsed() ); // Read 5 chars we expect (to avoid dealing with EOF, etc.) let mut buffer = [0; 5]; stream.read_exact(&mut buffer).await?; stream.shutdown(std::net::Shutdown::Both)?; println!( "OS Thread {:?} - {} read: {:?}", std::thread::current().id(), label, now.elapsed() ); // Simulate computation work by sleeping actual thread for 4 seconds sleep(std::time::Duration::from_secs(4)); println!( "OS Thread {:?} - {} finished: {:?}", std::thread::current().id(), std::str::from_utf8(&buffer)?, now.elapsed() ); Ok(()) }
运行这段代码,产生的输出和之前一样:
cargo run --release --bin client_async
OS Thread ThreadId(1) - task1 started: 333ns
OS Thread ThreadId(1) - task1 written: 2.001476012s
OS Thread ThreadId(1) - task1 read: 10.003284491s
OS Thread ThreadId(1) - task1 finished: 14.003404307s
OS Thread ThreadId(1) - task2 started: 14.003476979s
OS Thread ThreadId(1) - task2 written: 16.005013941s
OS Thread ThreadId(1) - task2 read: 24.005471439s
OS Thread ThreadId(1) - task2 finished: 28.005575307s
OS Thread ThreadId(1) - task3 started: 28.005615372s
OS Thread ThreadId(1) - task3 written: 30.007082377s
OS Thread ThreadId(1) - task3 read: 38.009223127s
OS Thread ThreadId(1) - task3 finished: 42.009349576s
这是因为串行任务的等待(.await)造成了同步。主函数是异步的,但是使用.await会使它在继续之前等待Future的结果。在这方面,主函数与其他异步函数之间没有什么区别。当时没有任何其他的任务可以产生执行结果,因此任务的执行实际上还是同步的。
请注意,在上面的实现中是不需要Send + Sync的(因为它运行在单个 OS 线程中),但是在下一个示例中,我们将会需要它们。这也是为什么我们会 clone now 而不是在task()中对其进行借用(我们也可以将其封装在Arc中)。
在下面的示例中,我们将使用同样的async fn task()定义,在此将其忽略。
异步请求(一个 OS 线程)
在异步中单个 OS 线程的场景下,我们同时开始等待步骤(连接并获取服务端的响应)。然而,最终的计算步骤仍然需要在每个任务中依次执行完成。因此我们预期总执行时间是8 + 2 + (3 * 4) = 22秒。
对应的图表如下所示:

像之前一样使用相同的async fn task()定义:
use futures::stream::futures_unordered::FuturesUnordered; use futures::stream::StreamExt; use std::error::Error; use std::thread::sleep; use std::time::Instant; use tokio::net::TcpStream; use tokio::prelude::*; #[tokio::main] async fn main() -> Result<(), Box<dyn Error + Send + Sync>> { let now = Instant::now(); // Asynchronous single-thread let mut futs = FuturesUnordered::new(); futs.push(task("task1", now.clone())); futs.push(task("task2", now.clone())); futs.push(task("task3", now.clone())); while let Some(_handled) = futs.next().await {} Ok(()) }
运行这段代码,总执行时间是 22 秒:
OS Thread ThreadId(1) - task1 started: 3.994µs
OS Thread ThreadId(1) - task2 started: 21.174µs
OS Thread ThreadId(1) - task3 started: 25.511µs
OS Thread ThreadId(1) - task3 written: 2.002221984s
OS Thread ThreadId(1) - task2 written: 2.002406898s
OS Thread ThreadId(1) - task1 written: 2.002483563s
OS Thread ThreadId(1) - task3 read: 10.003326999s
OS Thread ThreadId(1) - task3 finished: 14.003478669s
OS Thread ThreadId(1) - task2 read: 14.00365763s
OS Thread ThreadId(1) - task2 finished: 18.00379238s
OS Thread ThreadId(1) - task1 read: 18.003951713s
OS Thread ThreadId(1) - task1 finished: 22.004094444s
在本示例中,我们使用FuturesUnordered集合以便我们可以重复等待不同的 Future。然而,我们不会使用tokio::spawn()因此它只能运行在单个 OS 线程中(因为我们不允许创建更多的 OS 线程)。
请注意,在这里我们可以使用join!宏而不必分配一个FuturesUnordered,我们将在之后的示例中这么做。然而,它仅对数量很少的 Future 具有实用性。
我们也可以通过设置主函数上的属性参数来强制 Tokio 只能使用一个线程。
#[tokio::main(core_threads = 1, max_threads = 1)] async fn main() -> Result<(), Box<dyn Error + Send + Sync>> { ... }
异步请求(多个 OS 线程)
在跨多个 OS 线程的异步请求中,我们可以同时进行每一步(并在 OS 线程可以在任务等待的时候去完成其他的任务)。这就意味着我们可以在不同的 OS 线程中并行的进行最终的计算。

因此我们预测 3 次请求的总执行时间为2 + 8 + 4 = 14秒。这是我们能够实现的最好的方案 - 与完成单个请求的用时一样。
请注意,这需要我们跨进程发送的类型是线程安全的,也就是说需要实现Send或Sync - 就像我们直接使用 OS 线程一样。
它的实现和之前的示例很像,但是不是直接等待 Future 的返回,我们对任务进行tokio::spawn并等待它们的处理。这允许 tokio 可以在不同的的 OS 线程中执行它们。
#[tokio::main] async fn main() -> Result<(), Box<dyn Error + Send + Sync>> { let now = Instant::now(); let mut futs = FuturesUnordered::new(); futs.push(tokio::spawn(task("task1", now.clone()))); futs.push(tokio::spawn(task("task2", now.clone()))); futs.push(tokio::spawn(task("task3", now.clone()))); while let Some(_handled) = futs.next().await {} Ok(()) }
然后我们会观察到 14 秒的执行时间(请注意我们并不关心执行顺序):
OS Thread ThreadId(2) - task1 started: 17.055µs
OS Thread ThreadId(3) - task2 started: 30.227µs
OS Thread ThreadId(2) - task3 started: 32.513µs
OS Thread ThreadId(2) - task3 written: 2.001499145s
OS Thread ThreadId(3) - task1 written: 2.00153689s
OS Thread ThreadId(5) - task2 written: 2.001721878s
OS Thread ThreadId(3) - task3 read: 10.003403756s
OS Thread ThreadId(2) - task1 read: 10.003501s
OS Thread ThreadId(5) - task2 read: 10.003417328s
OS Thread ThreadId(3) - task3 finished: 14.003584085s
OS Thread ThreadId(2) - task1 finished: 14.003664981s
OS Thread ThreadId(5) - task2 finished: 14.003698375s
不同的 OS 线程 ID 证明了任务确实是在 OS 中不同的线程中执行的。
为了本文内容更加完整,这里有一个使用join!宏的相同实现,而不是分配一个FuturesUnordered:
#[tokio::main] async fn main() -> Result<(), Box<dyn Error + Send + Sync>> { let now = Instant::now(); // Asynchronous multi-threaded match join!( tokio::spawn(task("task1", now.clone())), tokio::spawn(task("task2", now.clone())), tokio::spawn(task("task3", now.clone())) ) { (x, y, z) => { (x.ok(), y.ok(), z.ok()) } }; Ok(()) }
这样可以节省FuturesUnordered的分配,但是处理返回的结果元组(尤其是对于很多的Future来说),可能会很笨拙。
它和 OS 线程并行有什么区别呢?
在一些同步的场景中,你可以直接使用 OS 线程来实现相同的事情,例如之前提到的rayon库。
然而,这种情况下每个请求都会需要一个自己的 OS 线程,如果我们必须处理 10000 个并行请求,很可能会达到系统的线程限制。
也就是说,执行图如下所示:

请注意,OS 线程可能会花费大量的时间来等待 I/O 操作,而无法启动其他任务。
我们可以使用 rayon 修改我们在上面的第一个同步示例:
use rayon::prelude::*; fn main() -> Result<(), Box<dyn std::error::Error + Send + Sync>> { let now = Instant::now(); ["task1", "task2", "task3"] .par_iter() .map(|x| task(x, now.clone())) .collect::<Result<Vec<_>, _>>()?; Ok(()) }
而且它在预期的 14 秒内结束了(请注意这里每个任务都单独分配了一个 OS 线程)。
OS Thread ThreadId(3) - task1 started: 280.871µs
OS Thread ThreadId(6) - task2 started: 281.03µs
OS Thread ThreadId(7) - task3 started: 283.838µs
OS Thread ThreadId(6) - task2 written: 2.000605562s
OS Thread ThreadId(7) - task3 written: 2.000619598s
OS Thread ThreadId(3) - task1 written: 2.000679853s
OS Thread ThreadId(3) - task1 read: 10.002321036s
OS Thread ThreadId(6) - task2 read: 10.00233185s
OS Thread ThreadId(7) - task3 read: 10.002384653s
OS Thread ThreadId(3) - task1 finished: 14.002447762s
OS Thread ThreadId(6) - task2 finished: 14.002540969s
OS Thread ThreadId(7) - task3 finished: 14.002589621s
然而,由于一个任务对应了一个 OS 线程,当处理大量的任务时可能会无法充分利用资源。
而在异步的情况下,我们在(同步的)计算步骤中只需要额外的线程即可。这意味着我们可以使用固定大小的 OS 线程池,并仍然可以在计算步骤的并行化中受益,同时还可以保证系统资源的充分利用(即我们可以限制 OS 线程的最大数量,但是依然可以处理新的请求)。
结论
我希望这篇文章可以帮助你更好的理解在 Rust 中何时以及如何去使用异步编程。
优雅的async/await语法允许进行简单明了的异步编程。但是,如果你之前没有接触过异步编程,可能需要花一点时间来适应这种方式。
上述的示例也展示了并发和并行之间的区别。在异步单个 OS 线程中,我们并发的处理任务,但是这不是并行执行的(因为我们只有一个 OS 线程)。
当前的限制
请注意,现在你还不能在 trait 中使用异步函数,并且你也不能创建异步的解构。如果你希望结构在销毁时发出网络请求,但是不希望这么做的同时阻塞 OS 线程,这时就会出现问题 - 你无法使用.await因为drop()(来自 From) 不是异步的。
Tokio 内幕:自底向上的理解 Rust 的异步 I/O 框架
tokio 是用于开发异步 I/O 应用程序的 Rust 框架 - 它基于事件驱动的方式,与传统的同步 I/O 相比,它通常可以实现更好的伸缩性,性能与资源使用。不幸的是,tokio 由于其复杂的 (sophisticated) 抽象而难以学习。即使在阅读了教程之后,我仍然觉得自己没有内部化抽象来推理出实际发生的事情。
我以前在异步 I/O 编程方面的经验甚至可能成为我学习 tokio 的阻碍。我习惯于使用操作系统的 selection 工具(如 Linux 的 epoll) 作为起点,然后继续学习调度,状态机等内容。从 tokio 的抽象开始,对底层的 epoll_wait 发生的位置和方式没有清晰的了解,我发现很难将所有的点连接起来。tokio 及其 future 驱动的方式感觉就像个黑匣子。
我没有继续采用自上而下的方式来学习 tokio,而是决定采用自下而上的方式,通过研究源代码来确切地了解当前在Future::poll()中的具体实现如何驱动 epoll 事件向 I/O 消耗的进展。我不会详细介绍 tokio 和 futures 的高级用法,因为有其他的教程对其进行了更深入的说明。除了做一些简短的总结之外,我也不会讨论异步 I/O 的一般问题,因为讨论该主题可能需要写一本书。我的目标仅仅是让人们对 futures 和 tokio 轮询的工作方式有足够的了解。
首先,先做一些重要的免责声明。请注意,tokio 正在积极的开发中,因此此处的某些结论可能很快就会过时。为了这次研究的目的,我使用tokio-core: 0.1.10,futures: 0.1.17以及mio: 0.6.10。因为我想了解 tokio 的最底层,所以我没有考虑使用诸如tokio-proto和tokio-service这种更高层次的 crate。tokio-core 的事件系统拥有很多的组件,为了尽可能简洁,本文将不会对其进行讨论。我是在 Linux 系统中学习 tokio 的,因此一些讨论必然涉及平台相关的实现细节,如:epoll。最后,这里提到的所有内容都是我作为 tokio 新手对其做出的解释,因此可能存在错误或误解。
异步 I/O 简述
同步 I/O 编程涉及执行 同步的 I/O 操作,该操作会一直阻塞线程直到完成。读操作会一直阻塞直到接收到数据,写操作会一直阻塞直到输出的字节发送到内核为止。这种依次执行的操作十分适合传统的命令式编程方式。举个例子,一个 HTTP 服务器为每一个连接都创建了一个线程。在线程中,它需要一直读取字节流直到接收到整个请求(在接收到所有的字节之前线程是阻塞的),然后处理请求,再将响应写入连接通道(在所有的字节写入之前,线程是阻塞的)。这是一种非常直接的方式。缺点(downside)是由于阻塞,每个连接都需要一个不同的线程,每个线程都有自己的堆栈。在多数情况下这都没有问题,同步 I/O 是一种正确的方式。然而,线程开销阻碍了服务器处理大量连接的伸缩性(参阅:C10k问题),并且在处理少量连接的低配置系统中也可能过载。
如果我们的 HTTP 服务器是使用异步 I/O 编写的,它可能会在一个线程中处理所有的 I/O 操作。所有的活跃连接以及监听套接字都将被配置成非阻塞的,在事件循环 (event loop) 中监听其读/写的准备情况,并在事件发生时将执行操作分发给处理程序。每个连接需要维护其状态和缓冲区。如果一个处理程序只能读取 200 字节请求的其中100个字节,它将无法等待剩余字节的到达,因为这样做会阻止其他准备处理的连接。它必须将部分读取存储在缓冲区中,将状态设置为“读请求”,然后返回事件循环。下次此连接调用处理程序时,它可以读取请求的剩余部分并切换为“写入响应”的状态。借助复杂的状态机和易于出错的资源管理,实现这样的系统非常麻烦。
一个理想的异步 I/O 框架将提供一种依次编写此类 I/O 处理步骤的方式,就好像它们在阻塞一样,但是在后台会生成事件循环和状态机。在大多数语言中这都是一个艰巨的任务,但是 Tokio 给我们提供了一种更接近这种方式的异步调用。
Tokio 技术栈

Tokio 技术栈包含以下几个组件:
-
System Selector: 每个操作系统都提供了一个接收 I/O 事件的工具,如:epoll (Linux),kqueue (FreeBSD/Mac OS)以及 IOCP (Windows)。
-
Mio - Metal I/O:Mio 是一个 Rust 库,它通过内部处理每个操作系统的细节来提供一套用于底层 I/O 的通用 API。
-
Futures:Futures 为尚未发生的事件提供了一个强大的抽象。它用一种有效的方式将这些事件组合在一起,以创建可以描述复杂事件序列的组合 Futures。这种抽象足够通用,可以用于 I/O 之外的许多其他的方面,在 Tokio 中,我们将异步 I/O 的状态机作为 futures。
-
Tokio:tokio-core 提供了中央事件循环,该循环与 Mio 集成以响应 I/O 事件,并驱动完成 futures。
-
你的程序:使用 Tokio 框架的程序可以将异步 I/O 系统构造为 futures,并为其提供 Tokio 事件循环以待执行。
Mio:Metal I/O
Mio 提供了一套底层 I/O 的 API,它允许调用者接收诸如读写套接字准备情况变更的事件,以下为其中的重点:
-
Poll 和 Evented:Mio 提供了一个 Evented 特征来表示任何可能成为事件源的东西。在你的事件循环中,你可以通过 mio::Poll 对象来注册大量的
Evented,然后调用 mio::Poll::poll() 进行阻塞直到事件发生在一个或多个Evented对象中(或超过了指定的超时时间)。 -
System Selector:Mio 对 System selector 提供了跨平台的访问方式,因此 Linux 的 epoll,Windows 的 IOCP,FreeBSD/Mac OS 的 kqueue 以及其他选择都可以使用相同的 API。system selector 适配 Mio API 的开销有所不同。因为 Mio 提供了一种类似于 epoll 基于就绪的 API,因此在 Linux 中使用 Mio 时,API 的许多部分可以一对一的进行映射(例如:
mio::Events本质上是一个结构为epoll_event的数组)。相反,由于 Windows 的 IOCP 是基于完成而不是基于就绪,因此需要更多的适配来桥接这两个范式。Mio 提供了自己的std::net结构,如:TcpListener,TcpStream以及UdpSocket。它们封装了std::net,但是默认为非阻塞形式,并提供了Evented实现,这些实现将套接字添加到 System selector 中。 -
非系统事件:除了提供了 I/O 源的就绪状态之外,Mio 还可以指示在用户空间中生成就绪事件。举个例子,如果工作线程完成了一个工作单元,则它可以向事件循环线程发出完成信号。你的程序调用 Registration::new2() 以获取一个(
Registration,SetReadiness)元组。Registration对象是一个Evented,可以在事件循环中向 Mio 注册。当需要指示就绪情况时,可以在SetReadiness对象上调用set_readiness()。在 Linux 中,非系统事件通知是使用管道实现的。当调用SetReadiness::set_readiness()时,0x01字节就被写入管道中。mio::Poll的基础 epoll 配置为监控管道读取的末端,因此epoll_wait()将解除阻塞并且 Mio 可以将事件传递给调用方。实例化轮询时仅创建一个管道,而不管后来注册了多少个(如果有)非系统事件。
每一个Evented的注册都与调用者提供的作为mio::Token的usize类型的值相关联,并且此值与事件一起返回以指示相应的注册。在 Linux 系统中,这可以很好的映射到 System selector 中,因为 token 可以放置在 64 位 epoll_data 联合体中,该联合体以相同的方式起作用。
为了提供 Mio 操作的具体示例,这是当我们使用 Mio 监视 Linux 系统上的 UDP 套接字时在内部发生的事情:
- 创建套接字
#![allow(unused)] fn main() { let socket = mio::net::UdpSocket::bind( &SocketAddr::new( std::net::IpAddr::V4(std::net::Ipv4Addr::new(127,0,0,1)), 2000 ) ).unwrap(); }
这里创建了一个 Linux 中封装在std::net::UdpSocket的 UDP 套接字,这个套接字也封装在mio::net::UdpSocket中。这个套接字被设置为非阻塞的。
- 创建 poll
#![allow(unused)] fn main() { let poll = mio::Poll::new().unwrap(); }
Mio 初始化 System selector,就绪队列(用于非系统事件)和并发保护。就绪队列初始化会创建一个管道,以便可以从用户空间发出准备就绪的信号,并将管道读取的文件描述符添加到epoll中。创建 poll对象时,将从递增计数器中为其分配唯一的selector_id。
- 使用 poll 注册套接字
#![allow(unused)] fn main() { poll.register( &socket, mio::Token(0), mio::Ready::readable(), mio::PollOpt::level() ).unwrap(); }
UdpSocket的Evented.register()函数被调用时,会将代理指向一个被封装的EventedFd,这个EventedFd会将套接字的文件描述符添加到 poll selector 中(最终会调用epoll_ctl(fepd, EPOLL_CTL_ADD, fd, &epoll_event),并将epoll_event.data设置为提供的token值)。当一个UdpSocket被注册后,它的selector_id会被设置为Poll的selector_id,从而与 selector 产生关联。
- 在事件循环中调用 poll()
#![allow(unused)] fn main() { loop { poll.poll(&mut events, None).unwrap(); for event in &events { handle_event(event); } } }
system selector (epoll_wait())和就绪队列将会轮询是否有新事件(epoll_wait()会阻塞,但是由于非系统事件除了推送到就绪队列之外,还通过管道触发了epoll,因此仍需要及时处理它们。)。这一系列事件的组合可供调用端处理。
Futures 和 任务
Futures 是从函数式编程中借用的技术,因此尚未发生的计算可以表示为一个 “future“,并且这些独立的 future 可以被组合起来以构建一个复杂的系统。这对于异步 I/O 很有用,因为执行事物的基本步骤可以建模成此类组合的 futures。在 HTTP 服务器的示例中,一个 future 可以通过读取字节来读取一个请求,直到到达请求的末端为止,此时将产生请求对象。另一个 future 可能会处理请求并产生响应。再另一个 future 可能会写入响应。
在 Rust 中,futures 库 实现了 futures,你可以通过实现 Future 特征来定义一个 future,它需要实现一个poll() 方法,该方法在需要时会被调用,并允许 future 开始执行。此方法会返回一个错误或表示 future 仍在等待中,因此应稍后再调用poll(),或者当 future 已经完成时将产生一个值。Future 特征还提供了大量的组合器作为默认方法。
想要理解 futures,先要理解三个重要的概念:任务,执行器,通知 - 以及它们是如何在正确的时间调用 futures 的poll()方法的。每一个 future 都会在一个 任务上下文中执行。一个任务直接与一个 future 相关联,但是这个 future 可能是个组合 future,它驱动着很多被包含的 future(举个例子,许多 future 通过join_all() 组合器组合到一个future 中,或者两个 future 通过 and_then() 组合器依次执行)。
任务和他们的 future 需要一个执行器来运行。一个执行器需要在正确的时间轮询任务/ future - 通常是当获得通知可以做一些进展时。当其他一些代码调用实现了 futures::executor::Notify 特征所提供 notify() 方法的对象时,就会产生这样的通知。futures 库中提供的一个及其简单的执行程序就是一个例子,当在 future 上调用 wait() 方法时,该执行程序将被调用。查看源代码):
#![allow(unused)] fn main() { /// Waits for the internal future to complete, blocking this thread's /// execution until it does. /// /// This function will call `poll_future` in a loop, waiting for the future /// to complete. When a future cannot make progress it will use /// `thread::park` to block the current thread. pub fn wait_future(&mut self) -> Result<F::Item, F::Error> { ThreadNotify::with_current(|notify| { loop { match self.poll_future_notify(notify, 0)? { Async::NotReady => notify.park(), Async::Ready(e) => return Ok(e), } } }) } }
给定一个预先创建的 futures::executor::Spawn 对象来融合任务与 future,这个执行器在循环中调用 poll_future_notify()。Notify对象变成任务上下文的一部分,future 也在被轮询。如果一个 future 的poll()返回Async::NotReady表明 future 仍在等待中,需要在 future 中再次安排轮询。Notify对象可以通过 futures::task::current() 获取一个任务的句柄,并在 future 有进展后调用 notify() 方法(当一个 future 正在被轮询时,与其关联的任务信息被存储在 thread-local 中,可以通过current()访问到)。在上述示例中,如果轮询返回了Async::NotReady,执行器将会一直阻塞直到接收到通知。也许 future 会在另一个线程中开始一些工作,并在完成时调用notify(),也许poll()在返回Async::NotReady之前直接自己调用notify()(后者不是很常见,因为从理论上来说,poll()应该在返回之前继续取得进展)。
Tokio 事件循环更像是一种复杂的 (sophisticated) 执行器,与Mio 事件集成以驱动 future 完成。在这种情况下,指示套接字准备就绪的 Mio 事件将发送一个通知使得对应的 future 进行轮询。
处理 future 时,任务是最基础的执行单元,且基本上就是提供了某种多任务协作的绿色线程,允许一个操作系统线程中有多个执行上下文。如果一个任务无法取得进展,会让处理器处理其他可执行的任务。理解通知发生在任务级别而非 future 级别是十分中重要的。当一个任务接收到通知,它将会轮询它的顶级 future,可能会导致其中某些或全部的子 future 都被轮询。举个例子,如果一个任务的顶级 future 是由其他 10 个 future join_all()的,其中一个 future 安排的任务被通知到,全部的 10 个任务都将被轮询。
Tokio 与 Mio 的接口
Tokio 通过上面描述的 Mio “非系统事件”的特性将任务通知转换成为 Mio 的事件。当任务获取到 Mio 的(Registration, SetReadiness) 元组后,它使用 Mio 的轮询将Registration(它是一个Evented)进行注册,并在MySetReadiness中封装实现了Notify特征的mio::SetReadiness对象,查看源码:
#![allow(unused)] fn main() { struct MySetReadiness(mio::SetReadiness); impl Notify for MySetReadiness { fn notify(&self, _id: usize) { self.0.set_readiness(mio::Ready::readable()) .expect("failed to set readiness"); } } }
在这种方式中,任务通知被转换成为 Mio 事件,且可以在 Tokio 事件处理与分派机制中与其他类型的 Mio 事件一起进行处理。
就像 Mio 封装了std::net结构(如:UdpSocket,TcpListener,TcpStream)以自定义功能一样,Tokio 也使用组合和装饰来提供这些类型的 Tokio的 感知版本。例如:Tokio 的UdpSocket看起来像这样:

Tokio 版本的这些 I/O 源类型提供的构造函数都需要一个指向事件循环的句柄(tokio_core::reactor::Handle)。在初始化的时候,这些类型将会将它们的套接字注册到事件循环的 Mio 轮询中,以接收edge-triggered(一种 epoll 事件的触发方式)事件及其新分配的偶数数字的 token(下面会提及)。当底层 I/O 操作回传WouldBlock时,这些类型可以很方便地通知当前的任务来接收读/写就绪状态。
Tokio 在 Mio 上注册了很多 Evented 的类型,键入特定的 token:
-
Token 0 (
TOKEN_MESSAGES) 被用于 tokio 内部的消息队列,它提供了移除 I/O 来源,接收读写就绪通知的定时任务,配置超时时间,在事件循环的上下文中运行任意(arbitrary)闭包。这可以安全地与其他线程的事件循环进行通信。举个例子:Remote::spawn() 通过消息系统将 future 传入事件循环中。消息系统被实现为 futures::sync::mpsc 流。作为一个 futures::stream::Stream (与 future 很像,但是它产生一系列的值而不是单个值),使用上面提到的
MySetReadiness方案执行此消息队列的处理,其中Registration是以TOKEN_MESSAGES令牌进行注册的。当接收到TOKEN_MESSAGES事件,他们会被分发给consume_queue()方法来进行处理(源码:enum Message,consume_queue())。 -
Token 1 (
TOKEN_FUTURE) 被用来通知主任务需要被轮询。这发生在主任务关联的通知被发布的时候(换句话说就是 future 或者其中的子 future 被传递给Core::run(),而不是通过spawn()运行在不同任务上的 future)。它同样使用一个MySetReadiness方案将 future 的通知转换成了 Mio 的事件。在一个 future 运行在主任务之前返回Async::NotReady,并以其所选的方式在稍后发布通知。当接收到TOKEN_FUTURE事件后,Tokio 事件循环将会重新轮询主任务。 -
大于 1 的偶数 Token (TOKEN_START + key * 2) 被用来表明 I/O 来源上的就绪状态的变更。key 是指与
Core::inner::io_dispatch Slab<ScheduledIo>相关联的Slabkey。当对应的 Tokio 源类型初始化时,Mio I/O 源类型(UdpSocket,TcpListener,TcpStream)使用此 token 自动进行注册。 -
大于 1 的奇数 Token (TOKEN_START + key * 2 + 1) 被用来表明一个已创建的任务(以及相关的 future)需要被轮询。key 是与
Core::inner::task_dispatch Slab<ScheduledTask>相关联的Slabkey。和TOKEN_MESSAGES与TOKEN_FUTURE事件相同,这里也使用了MySetReadiness方案。
Tokio 事件循环
Tokio,尤其是tokio_core::reactor::Core,提供了一个管理 future 和任务的事件循环,来驱动 future 的完成,它同样还提供了与 Mio 的接口,因此 I/O 事件将会导致正确的任务被通知到。使用事件循环设置使用 Core::new() 初始化 Core 以及 使用单个 future 调用Core::run()。事件循环将会在返回之前驱动提供的 future 完成。对于服务端应用,这个 future 更像是长期存活。它确实可能是这样,举个例子:使用一个TcpListener来一直接收新的连接,每个连接都会被自己的 future 进行处理,这些 future 运行在由Handle.spawn()创建的独立任务中。
下面的流程图概述了 Tokio 事件循环的基本步骤:

当数据抵达套接字时发生了什么?
了解 Tokio 的一个有用的练习是检查当数据到达套接字时在事件循环中发生的步骤。我惊讶的发现这个过程最终分为两个部分,分别在事件循环内的各自迭代中,进行独立的 epoll 事务。第一部分负责当套接字读就绪(即 Mio 事件带着比 1 大的偶数 token 或者主任务的TOKEN_FUTURE)时,通过发送通知给对套接字感兴趣的任务。第二部分通过轮询任务及与其关联的 future 来处理通知(即 Mio 事件带着比 1 大的奇数 token)。我们来考虑以下情景:一个创建的 future 通过上层的 Tokio 事件循环 从 Linux 系统中的UdpSocket上读取数据,假设之前对 future 的轮询导致recv_from()返回了一个WouldBlock错误。

Tokio 事件轮询调用mio::Poll::poll(),该方法转而(在 Linux上 )调用epoll_wait(),进而阻塞某个监控中的文件修饰符发生了就绪状态变更的事件。当这些发生时,epoll_wait()返回一个epoll_event结构的数组,用来描述发生了什么事,这些结构通过 Mio 转换成mio::Events并返回给 Tokio(在 Linux 中,这个转换是零开销的,因为mio::Events只是epoll_event数组的一个元组结构)。在我们的例子中,假定数组中只有一个事件表明套接字已经读就绪。因为事件的 token 是大于 1 的偶数,因此 Tokio 将其解释为一个 I/O 事件,并在Slab<ScheduledIo>的相关元素中查找详细信息,该元素包含有关对这个套接字的读写就绪感兴趣的任务信息。然后,Tokio 通知读任务通过MySetReadiness调用 Mio 的set_readiness()。Mio 通过将事件详细信息添加到就绪队列,并将单个 0x01 字节写入就绪管道来处理这个非系统事件。

在 Tokio 的事件轮询来到下一个迭代后,它再一次轮询 Mio,Mio 则调用epoll_wait(),这时,该函数将会返回一个发生在 Mio 就绪管道上的读就绪事件。Mio 读取之前写入管道的 0x01 字节,并从就绪队列中取出最先的非系统事件的详细信息,并将该事件返回给 Tokio。因为事件的 Token 是大于 1 的奇数,Tokio 将其解释为任务通知事件,并在Slab<ScheduledIo>的相关元素中查找详细信息,该元素包含从spawn()返回的任务最初的Spawn对象。Tokio 通过 poll_future_notify() 轮询任务及其相关的 future。future 可能会在之后读取套接字上的数据知道它收到一个WouldBlock错误。
与其他异步 I/O 事件相比,这两种设计管道读写的迭代方式可能会增加一点开销。在单线程程序中,使用strace查看线程通过管道和它自己交流是很奇怪的:
pipe2([4, 5], O_NONBLOCK|O_CLOEXEC) = 0
...
epoll_wait(3, [{EPOLLIN|EPOLLOUT, {u32=14, u64=14}}], 1024, -1) = 1
write(5, "\1", 1) = 1
epoll_wait(3, [{EPOLLIN, {u32=4294967295, u64=18446744073709551615}}], 1024, 0) = 1
read(4, "\1", 128) = 1
read(4, 0x7ffce1140f58, 128) = -1 EAGAIN (Resource temporarily unavailable)
recvfrom(12, "hello\n", 1024, 0, {sa_family=AF_INET, sin_port=htons(43106), sin_addr=inet_addr("127.0.0.1")}, [16]) = 6
recvfrom(12, 0x7f576621c800, 1024, 0, 0x7ffce1140070, 0x7ffce114011c) = -1 EAGAIN (Resource temporarily unavailable)
epoll_wait(3, [], 1024, 0) = 0
epoll_wait(3, 0x7f5765b24000, 1024, -1) = -1 EINTR (Interrupted system call)
Mio 使用这种管道的方式来支持可能从其他线程调用set_readiness()的一般情况,也许在强制事件的公平调度以及维护 future 与 I/O 之间的间接层方面也会有一些好处。
收获:组合 future 和 衍生 future
当我第一次学习 Tokio 时,我写了一个小程序监听来自不同 UDP 套接字上的数据。我创建了 10 个 读取套接字的 future 实例,它们每一个都监听不同的端口。我天真的使用join_all() 将它们组合成一个 future,并将其传入Core::run(),然后惊讶的发现当单个数据包抵达时,每个 future 都在被轮询。同样让人惊讶的是tokio_core::net::UdpSocket::recv_from()已足够聪明,在先前的 Mio 轮询中,可以避免在未标记已就绪的套接字上实际调用操作系统的recv_from()。以下的strace反应出在 future 的poll()中的调试println!(),大致如下:
epoll_wait(3, [{EPOLLIN|EPOLLOUT, {u32=14, u64=14}}], 1024, -1) = 1
write(5, "\1", 1) = 1
epoll_wait(3, [{EPOLLIN, {u32=4294967295, u64=18446744073709551615}}], 1024, 0) = 1
read(4, "\1", 128) = 1
read(4, 0x7ffc183129d8, 128) = -1 EAGAIN (Resource temporarily unavailable)
write(1, "UdpServer::poll()...\n", 21) = 21
write(1, "UdpServer::poll()...\n", 21) = 21
write(1, "UdpServer::poll()...\n", 21) = 21
write(1, "UdpServer::poll()...\n", 21) = 21
write(1, "UdpServer::poll()...\n", 21) = 21
write(1, "UdpServer::poll()...\n", 21) = 21
write(1, "UdpServer::poll()...\n", 21) = 21
recvfrom(12, "hello\n", 1024, 0, {sa_family=AF_INET, sin_port=htons(43106), sin_addr=inet_addr("127.0.0.1")}, [16]) = 6
getsockname(12, {sa_family=AF_INET, sin_port=htons(2006), sin_addr=inet_addr("127.0.0.1")}, [16]) = 0
write(1, "recv 6 bytes from 127.0.0.1:43106 at 127.0.0.1:2006\n", 52) = 52
recvfrom(12, 0x7f2a11c1c400, 1024, 0, 0x7ffc18312ba0, 0x7ffc18312c4c) = -1 EAGAIN (Resource temporarily unavailable)
write(1, "UdpServer::poll()...\n", 21) = 21
write(1, "UdpServer::poll()...\n", 21) = 21
write(1, "UdpServer::poll()...\n", 21) = 21
epoll_wait(3, [], 1024, 0) = 0
epoll_wait(3, 0x7f2a11c36000, 1024, -1) = ...
因为 Tokio 和 futures 的内部机制对我来说有些模糊 (opaque),我想我希望后台发生一些魔法规则只会轮询需要的 future。当然,在对 Tokio 有了更好的了解之后,很明显我的程序正在使用这样的 future。

这实际上可以正常工作,但不是最佳选择 - 特别是在你有很多套接字的情况下。因为通知是在任务级别发生的,因此在上面任何绿色框中排列的任何通知都将导致通知主要任务。它将轮询它的 FromAll future,使得所有的子 future 都将接受轮询。我真正需要的是一个主 future,它可以使用Handle::spawn()来启动封装在各自任务中的 future,这样的安排大致如下所示:

当任何 future 安排通知时,只有 future 特定的任务会被通知到,并且只有该 future 会被轮询(回想一下,当tokio_core::net::UdpSocket::recv_from()从它的底层mio::net::UdpSocket::recv_from()调用中接收到WouldBlock时,“安排通知”会自动发生)。future 的组合器是用来描述协议流的强大工具,否则将在手动状态机中实现该协议流,但是了解你的设计可能需要在何处支持独立且并行执行的任务,这一点很重要。
最后的思考
学习 Tokio的源码,Mio 以及 futures 确实有助于巩固我对 Tokio 的理解,并通过理解具体的实现来验证我的抽象策略。这种方法在仅学习抽象层的狭隘使用案例时非常危险,我们必须意识到具体的示例仅是助于理解的一般用例,在阅读了源码之后再学习 Tokio 的教程,我有一些马后炮的意见:Tokio 非常合理,应该很容易理解与上手。
我仍有一些问题待日后研究:
-
Tokio 是否能够处理边缘触发的饥饿问题?我想将来可以通过限制单个
poll()中的读写次数来处理它。当达到极限时, future 可以在明确通知当前任务后提前返回,而不是依赖于 Tokio 的 I/O 源类型的隐式“定时WouldBlock”的行为,从而使其他任务及 future 有机会取得进展。 -
Tokio 是否支持以任何方式在多线程中运行事件循环,而不是依靠寻找机会将工作分担给工作线程以最大程度地利用处理器内核。
2017-12-19 更新:这里有 Reddit thread on r/rust 在讨论本文。Mio 的作者 Carl Lerche 在这里和这里 贴了些信息量很大的留言。除了回应上述问题,他也指出 FuturesUnordered 提供了一种组合 future 的方式,以便对相关的子 future 进行轮询,从而避免了像join_all()那样对每个 future 进行轮询,且需要权衡其他分配。同样,Tokio 的未来版本将从mio::Registration方案迁移到通知任务,这可以简化前面描述的某些步骤。
2017-12-21更新:看起来 Hacker News 也在讨论这篇文章。
2018-01-26更新:我为 Tokio 的示例代码创建了一个Github仓库。
「转」 Rust 中的 Arenas
Rust 中的 Arenas 内存池
最近有一些关于 Rust 中 Arenas 的讨论,我想我应该写一篇关于这个的文章。
在 Rust 中,Arenas 并不是那种 "典型的" 问题,所以很少有人了解它们。只会在各种用例的应用程序中有看到它们。一般来说,你只需要调包就行了,没必要为它使用 unsafe 。因此无需专门去了解它,但这些知识也不是无用的,尤其是对使用 Arenas 的人来说更是如此 。
此外,我在实现自引用的 Arenas 时会涉及到一系列非常酷的 lifetime操作 ,我以前完全没写过。
我主要是为了一些很酷的生命周期效应而写的,但是我认为有必要写一篇针对所有 Rustaceans 的介绍。如果你已经知道什么是 Arenas,并且想看到一些很炫酷的 lifetime 技巧,则可以直接跳到这里阅读。
什么是 arena ?
Arenas 本质上是一种将生命周期相同的内存进行分组的模式。比如说有时需要在某个生命周期内分配一堆对象,之后这些对象将被全部销毁。每次都调用系统分配器效率低下,更可取的是为对象预分配一堆内存,并在完成处理后立即将其全部清理干净。
译者注: 没错就是 cache
从广义上讲,使用 Arenas 有以下两个原因:
首先,如上所述,使用它的主要目标是减轻内存消耗。例如,在游戏或应用程序中,可能存在大量对象需要逐帧分配,使用完立即销毁的情况。特别是在游戏开发中,这非常普遍,而内存压力是游戏开发人员比较关心的事情。使用 Arenas,可以轻松地分配一个 Arena,在每个帧中将其填满,并在帧结束后将其清空。缓存局部性还能其他好处:可以确保大多数每帧对象在帧期间(可能比其他对象使用得更多)位于缓存中,因为它们是相邻分配的。
另一个原因可能是用于编写自引用的数据,例如带有环的复杂图,使用此方法可以一次性清除全部数据。例如,在编写编译器时,类型信息可能将需要引用其他类型或者其他数据,从而导致复杂的类型有环图。一旦推导出类型,就不需要专门销毁它了,因此可以使用一个 Arenas 来存储所有计算出的类型信息,当类型信息无关紧要时,就可以直接将他们一次性清除。使用这种模式可以让代码不必担心自引用位是否会 “提前” 释放,它可以保证,如果存在一个 Ty ,则它的寿命与其他所有 Ty 一样长,并且可以直接引用它们。
译者注: 不会导致空引用
这两个目标不一定是相互联系的:可以使用一个 Arenas 来同时实现两个目标。但是,也可以拥有一个禁止使用自我引用类型的 Arenas(有得有失,你能得到一些好处)。在本文的稍后部分,我将实现一个允许自我引用类型但对减轻内存分配压力影响不大的 Arenas,主要是为了易于实现。通常,如果你正在为自引用类型编写 Arenas,可以使其同时减少分配器压力,但可能会有所取舍。
在 Rust 中如何使用 arena ?
一般来说,要使用 arena ,只需要调包。 我简单的搜索一下现有的 Arenas 实现,在这里。下面我会介绍两个我已经了解的库,但我只是挂 "二" 漏万。
要指出的是,如果只需要环结构,则不必使用 arenas ,出色的 petgraph 通常就足够了。 slotmap 也很不错; 它是类似地图的数据结构,可用于基于分代索引的自引用数据。
Bumpalo
Bumpalo 是一种快速的 bump allocator[1],它允许异构的内容,并且仅在不关心析构函数运行的情况下才允许循环。
参见: 1
#![allow(unused)] fn main() { use bumpalo::Bump; // (example slightly modified from `bumpalo` docs) // Create a new arena to bump allocate into. let bump = Bump::new(); // Allocate values into the arena. let scooter = bump.alloc(Doggo { cuteness: u64::max_value(), age: 8, scritches_required: true, }); // Happy birthday, Scooter! scooter.age += 1; }
每次对 Bump::alloc() 的调用都会返回对已分配对象的可变引用。 这可以分配不同的对象,它们甚至可以相互引用 (不用环的话,借用检查就会强制这样做) 。 默认情况下,它不会在其内容上调用析构函数。 但是,可以使用 bumpalo::boxed(或Nightly上的自定义分配器)来实现这个效果。 可以类似地使用 bumpalo::collections来获取 bumpalo 支持的向量和字符串。 bumpalo::boxed 将不允许自引用。
typed-arena
typed-arena是一个 areana 分配器,它只能存储单一类型的对象,但是可以循环引用:
#![allow(unused)] fn main() { // Example from typed-arena docs use std::cell::Cell; use typed_arena::Arena; struct CycleParticipant<'a> { other: Cell<Option<&'a CycleParticipant<'a>>>, } let arena = Arena::new(); let a = arena.alloc(CycleParticipant { other: Cell::new(None) }); let b = arena.alloc(CycleParticipant { other: Cell::new(None) }); // mutate them after the fact to set up a cycle a.other.set(Some(b)); b.other.set(Some(a)); }
和 bumpalo 不同的是,typed-arena 当 arena 本身超出范围时,就会使用析构函数。
你或许想知道,析构函数在引用数据上的安全性–毕竟,无论哪一个变量被第二次销毁,析构函数都会读到悬挂的引用。我们将在文章的后面对此进行介绍,但这与
drop检查有关,特别是如果尝试自引用时,则 arena 元素本身允许的唯一显式析构函数将是带有适当标记类型的析构函数。
实现一个支持自引用的 arena
写自引用代码是很有趣的,因为 Rust 非常警惕自我参照数据。 但是 areana 可以让你清楚地将“我不在乎此对象”和“可以删除此对象”阶段分开,以允许自引用和循环类型出现。
人们很少需要实现自己的 arena,Bumpalo 和 Typedarena 涵盖了大多数使用场景,实在没办法的话不妨先在 crates.io 上 找一下。 但是,如果你的确需要直接实现的话,或者对具体的生命周期细节感兴趣,那么本节适合你。
实现带有 Entry 类型的 Arena 的关键是以下几种规则:
Arena和Entry都应具有生命周期参数:Arena<'arena>和Entry<'arena>Arena方法都应将Arena<'arena>作为&'arena self,即self的类型为&'arena Arena<'arena>Entry几乎应该始终以&'arena Entry<'arena>的形式传递(为此创建别名非常有用)- 使用内部可变性;
Arena上的&mut self将使所有代码停止编译。如果使用unsafe的可变性,请确保RefCell<Entry<'arena>>具有 PhantomData 。
从生命周期的角度来看基本上就是这样,剩下的全部就是确定所需的 API。掌握了以上规则,只要确保定义区域与所需的保证一起使用,就不必了解底层生命周期的状况。
让我们看一个实现,然后剖析其工作原理。
实现
我的库 elsa 在其中一个示例中使用 100% safe 的代码实现了一个 arena 。由于 elsa :: FrozenVec 要求其内容位于间接引用之后,因此该 arena 无法节省分配,并且它不是通用的,但这是一种合理的方式来说明生命周期的工作方式,而无需陷入 使用 unsafe 带来的麻烦之中。
该示例实现了 Person<'arena> 类型的 Arena ,Arena<'arena> 。目标是实现某种可能有环的有向社交图。
#![allow(unused)] fn main() { use elsa::FrozenVec; struct Arena<'arena> { people: FrozenVec<Box<Person<'arena>>>, } }
elsa::FrozenVec 是类似于 Vec 的仅支持追加内容的抽象,可让你调用push 而不需要传入可变的引用,这是只使用 safe 的一个实现。
每个 Person <'arena> 都有一个他们关注的人的列表,但也跟踪他们关注的人:
#![allow(unused)] fn main() { struct Person<'arena> { pub follows: FrozenVec<PersonRef<'arena>>, pub reverse_follows: FrozenVec<PersonRef<'arena>>, pub name: &'static str, } // following the rule above about references to entry types type PersonRef<'arena> = &'arena Person<'arena>; }
这个生命周期 arena 其实是 “arena本身的生命周期”。 从这开始事情就变得奇怪起来了:通常,如果一个有生命周期参数,则调用者可以选择其中的内容。 不必只是说“这是对象本身的生命周期”,调用者通常可以根据需要实例化 arena<'static> 或为某个 'a 实例化 Arena <'a> 。 但是在这里,我们声明 “'arena 是 arena 自身的生命周期”;很明显,一定有东西不太对。
这是我们实际实现的地方:
#![allow(unused)] fn main() { impl<'arena> Arena<'arena> { fn new() -> Arena<'arena> { Arena { people: FrozenVec::new(), } } fn add_person(&'arena self, name: &'static str, follows: Vec<PersonRef<'arena>>) -> PersonRef<'arena> { let idx = self.people.len(); self.people.push(Box::new(Person { name, follows: follows.into(), reverse_follows: Default::default(), })); let me = &self.people[idx]; for friend in &me.follows { // We're mutating existing arena entries to add references, // potentially creating cycles! // 把每一个元素都加上了 引用 , 很有可能导致循环引用 friend.reverse_follows.push(me) } me } fn dump(&'arena self) { // code to print out every Person, their followers, and the people who follow them // 打印出 `Person` ,他们的关注者 ,和关注的人 } } }
注意 add_person 中的 &'arena self。
此处的很好的实现了,“如果A 关注了 B,然后B又关注A” 这种通常需要分开处理的情况,但这仅是示例。
最后,我们可以像这样使用 arena :
fn main() { let arena = Arena::new(); let lonely = arena.add_person("lonely", vec![]); let best_friend = arena.add_person("best friend", vec![lonely]); let threes_a_crowd = arena.add_person("threes a crowd", vec![lonely, best_friend]); let rando = arena.add_person("rando", vec![]); let _everyone = arena.add_person("follows everyone", vec![rando, threes_a_crowd, lonely, best_friend]); arena.dump(); }
在这种情况下,所有 “可变性” 都发生在 arena 本身的实现中,但是此代码可能会将元素直接添加到 follows/reverse_follows 列表中,或者 Person 可能具有用于其他类型链接的 RefCells 。
生命周期是如何工作的
那么这是如何工作的呢? 如前所述,在 Rust 中使用这样的抽象,调用者通常可以自由地根据其处理方式来设置生存期。 例如,如果 HashMap<K,&'a str>,则 'a 将根据你尝试插入的内容的生存期进行调整。
当构造 Arena 时,其生命周期确实仍然不受限制,我们可以通过检查以下强制约束生命周期的代码来进行测试(依然是能过编译的)。
#![allow(unused)] fn main() { let arena: Arena<'static> = Arena::new(); }
当你想做点什么的时候,就会停止工作:
#![allow(unused)] fn main() { let arena: Arena<'static> = Arena::new(); let lonely = arena.add_person("lonely", vec![]); }
error[E0597]: `arena` does not live long enough
--> examples/mutable_arena.rs:5:18
|
4 | let arena: Arena<'static> = Arena::new();
| -------------- type annotation requires that `arena` is borrowed for `'static`
5 | let lonely = arena.add_person("lonely", vec![]);
| ^^^^^ borrowed value does not live long enough
...
11 | }
| - `arena` dropped here while still borrowed
add_person 方法以某种方式强制将 Arena 的 arena 参数设置为自己的生命周期,从而对其进行约束(并且无法用类型注释将其强制约束为其他任何值)。 这是与 add_person 的&'arena 自签名(即 self 是 &'arena Arena<'self> )的巧妙互动,以及'Arena in Arena<'arena> 是不变的生命周期。
通常,在 Rust 程序中,生命周期具有"伸缩性"。 以下代码可以通过编译:
#![allow(unused)] fn main() { // ask for two strings *with the same lifetime* // 要求具有相同 生命周期的 string fn take_strings<'a>(x: &'a str, y: &'a str) {} // string literal with lifetime 'static // 要求具有 `'static' 生命周期的 ` string literal` let lives_forever = "foo"; // owned string with shorter, local lifetime // 要求具有 `local` 生命周期 let short_lived = String::from("bar"); // still works! // 能跑通 take_strings(lives_forever, &*short_lived); }
在这段代码中,Rust 很高兴地注意到,虽然 live_forever 和 &* short_lived 具有不同的生命周期,但假装 life_forever 在 take_strings 函数的有效期内具有较短的生命周期是完全可以接受的。这只是引用,使用生命周期长的引用也适用于生命周期短的情况。
事实是,这种伸缩性并非对所用的生命周期都一样!nomicon chapter on subtyping and variance 一章详细说明了为什么会这样,但一般的经验法则是,大多数生命周期都是“紧缩的” (更专业的说法是 协变的 ),就像上面的&a str 中的一样,但是如果涉及某种形式的可变性,它们是不可变的,也称为“不变式”。如果使用的是函数类型,则具有 弹性的 生命周期 (即抗变的),但是这种情况很少见。
我们的 Arena<'arena> 使用内部可变性(通过 FrozenVec)使' arena不变。 让我们再次看一下两行代码。当编译器看到下面代码的第一行时,便会构建 arena,我们将其生命周期称为“ a”。此时 Arena 类型是 Arena<'?> ,其中的'?由表示形式表示,但生命周期不受限制。
#![allow(unused)] fn main() { let arena = Arena::new(); let lonely = arena.add_person("lonely", vec![]); }
让我们把生命周期写清楚一点:
#![allow(unused)] fn main() { let arena = Arena::new(); // type Arena<'?>, lives for 'a // explicitly write the `self` that gets constructed when you call add_person // 显式写出 在调用 add_person 时的构建函数 let ref_to_arena = &arena; // type &'a Arena<'?> let lonely = Arena::add_person(ref_to_arena, "lonely", vec![]); }
还记得我之前列出的第二条规则吗?
- Arena方法都应将Arena <'arena>接收为&'arena自身,即其自身类型为&'arena Arena <'arena> 我们遵循这条规则;
add_person 的签名是 fn add_person(&'arena self)。这意味着 ref_to_arena 的生存期必须与 &'arena Arena<'arena> 模式匹配。目前,它的生命周期是&'a Arena<'?>,表示'?强制与'a相同,即 arena 变量本身的生存期。如果生命周期是可变的,则编译器可以压缩其他生存期来适配它,但它是不变的,并且不受限制的生存期被强制转变成一个确切的生命周期。
通过这个巧妙的技巧,我们可以强制编译器将 Arena<'arena> 的生存期参数设置为其实例的生存期。
在此之后,其余的工作就非常简单了。 Arena<'arena> 拥有类型为 Person<'arena>的元素,也就是说:“Person 被允许引用具有 'arena 生命周期的元素, 例如 Arena“。
type PersonRef<'arena> = &'arena Person<'arena>是引用在 Arena 中并允许从其中引用对象 Person 的引用的便捷缩写。
析构器如何工作
到目前为止,我还没有讨论存在析构函数的情况下如何保证安全。 如果 Arena 具 有循环引用,并且编写了一个析构函数读取去这些循环引用,那么在销毁的过程中就会导致悬垂引用。
这是 rust 十分模糊的地方。 除了“明确析构器巧妙地改变借用检查行为”,你没有什么需要必须去了解的。 但是了解这里的机制对建立一个更好的心智模型更有帮助。
如果将以下代码添加到 arena 示例中:
#![allow(unused)] fn main() { impl<'arena> Drop for Person<'arena> { fn drop(&mut self) { println!("goodbye {:?}", self.name); for friend in &self.reverse_follows { // potentially dangling! println!("\t\t{}", friend.name); } } } }
报错:
error[E0597]: `arena` does not live long enough
--> examples/mutable_arena.rs:5:18
|
5 | let lonely = arena.add_person("lonely", vec![]);
| ^^^^^ borrowed value does not live long enough
...
11 | }
| -
| |
| `arena` dropped here while still borrowed
| borrow might be used here, when `arena` is dropped and runs the destructor for type `Arena<'_>`
析构函数的存在在自引用数据的生命周期内巧妙地更改了借用检查器的行为。准确的规则是十分 tricky的,并在 nomicon中进行了解释,但实际上发生的是,在Person <'arena>上存在自定义析构函数后,'person arena(因为是Arena)的'arena变成了一个“在销毁时观测到的的生命周期"。然后在借用检查期间将其考虑在内---知道作用域末尾隐式调用drop()能够读取'arena的数据,Rust 做出了适当的结论,由于销毁本身是可变的操作,在销毁之后,调用drop() 读取内容是可行的。
当然,需要问的一个合理问题是,如果析构函数不允许用 'arena “包装”数据,应该如何在 arena 中存储例如 Box 或者 FrozenVec之类的东西呢?
原因是 Rust 知道 Box::Drop由于不清楚 Person 是什么,也不会去试图知道,而无法检查 Person.follows的内容。
当然凡事都有例外,由于析构器可以调用指定的 trait 方法(或者特化的方法)来告诉如何读取Person的内容,如果有一个随机的泛型类型提供了这种方法,就可以再次巧妙地更改借用检查器的行为。stdlib 类型和其他自定义数据结构通过转义填充#[may_dangle](也称为“ eyepatch” 毕竟析构器 "看不到" 生命周期)来实现这种目的,声明不会从生命周期或通用参数中读取自定义析构函数。
这也适用于诸如 typed-arena 之类的库;如果需要创建循环引用,则将无法在为放置在 arena 上的类型上编写自定义析构函数。但是只要避免创建循环引用就可以使用 typed-arena 编写自定义析构函数了;因此将无法使用内部可变性来使一个 arena 指向另一个 arena。
感谢 Mark Cohen 和 Nika Layzell 审阅了这篇文章的草稿。
「转」Rust 异步 I/O:从 mio 到 coroutine
目录
引言
2018 年接近尾声,rust 团队勉强立住了异步 IO 的 flag,async 成为了关键字,Pin, Future, Poll 和 await! 也进入了标准库。不过一直以来实际项目中用不到这套东西,所以也没有主动去了解过。
最近心血来潮想用 rust 写点东西,但并找不到比较能看的文档(可能是因为 rust 发展太快了,很多都过时了),最后参考这篇文章和 "new tokio"( romio ) 写了几个 demo,并基于 mio 在 coroutine 中实现了简陋的异步 IO。
最终实现的 file-server 如下:
// examples/async-echo.rs #![feature(async_await)] #![feature(await_macro)] #![feature(futures_api)] #[macro_use] extern crate log; use asyncio::executor::{block_on, spawn, TcpListener, TcpStream}; use asyncio::fs_future::{read_to_string}; use failure::Error; fn main() -> Result<(), Error> { env_logger::init(); block_on(new_server())? } const CRLF: &[char] = &['\r', '\n']; async fn new_server() -> Result<(), Error> { let mut listener = TcpListener::bind(&"127.0.0.1:7878".parse()?)?; info!("Listening on 127.0.0.1:7878"); while let Ok((stream, addr)) = await!(listener.accept()) { info!("connection from {}", addr); spawn(handle_stream(stream))?; } Ok(()) } async fn handle_stream(mut stream: TcpStream) -> Result<(), Error> { await!(stream.write_str("Please enter filename: "))?; let file_name_vec = await!(stream.read())?; let file_name = String::from_utf8(file_name_vec)?.trim_matches(CRLF).to_owned(); let file_contents = await!(read_to_string(file_name))?; await!(stream.write_str(&file_contents))?; stream.close(); Ok(()) }
写这篇文章的主要目的是梳理和总结,同时也希望能给对这方面有兴趣的 Rustacean 作为参考。本文代码以易于理解为主要编码原则,某些地方并没有太考虑性能,还请见谅;但如果文章和代码中有明显错误,欢迎指正。
本文代码仓库在 Github (部分代码较长,建议 clone 下来用编辑器看),所有 examples 在 nightly-x86_64-apple-darwin 2018 Edition 上均能正常运行。运行 example/async-echo 时设置 RUST_LOG 为 info 可以在 terminal 看到基本的运行信息,debug 则可见事件循环中的事件触发顺序。
异步 IO 的基石 - mio
mio 是一个极简的底层异步 IO 库,如今 rust 生态中几乎所有的异步 IO 程序都基于它。
随着 channel, timer 等 sub module 在 0.6.5 版本被标为 deprecated,如今的 mio 提供的唯二两个核心功能分别是:
- 对操作系统异步网络
IO的封装 - 用户自定义事件队列
第一个核心功能对应到不同操作系统分别是
Linux(Android) => epollWindows => iocpMacOS(iOS), FreeBSD => kqueueFuchsia => <unknown>
mio 把这些不同平台上的 API 封装出了一套 epoll like 的异步网络 API,支持 udp 和 tcp。
除此之外还封装了一些不同平台的拓展 API,比如
uds,本文不对这些 API 做介绍。
异步网络 IO
下面是一个 tcp 的 demo
// examples/tcp.rs use mio::*; use mio::net::{TcpListener, TcpStream}; use std::io::{Read, Write, self}; use failure::Error; use std::time::{Duration, Instant}; const SERVER_ACCEPT: Token = Token(0); const SERVER: Token = Token(1); const CLIENT: Token = Token(2); const SERVER_HELLO: &[u8] = b"PING"; const CLIENT_HELLO: &[u8] = b"PONG"; fn main() -> Result<(), Error> { let addr = "127.0.0.1:13265".parse()?; // Setup the server socket let server = TcpListener::bind(&addr)?; // Create a poll instance let poll = Poll::new()?; // Start listening for incoming connections poll.register(&server, SERVER_ACCEPT, Ready::readable(), PollOpt::edge())?; // Setup the client socket let mut client = TcpStream::connect(&addr)?; let mut server_handler = None; // Register the client poll.register(&client, CLIENT, Ready::readable() | Ready::writable(), PollOpt::edge())?; // Create storage for events let mut events = Events::with_capacity(1024); let start = Instant::now(); let timeout = Duration::from_millis(10); 'top: loop { poll.poll(&mut events, None)?; for event in events.iter() { if start.elapsed() >= timeout { break 'top } match event.token() { SERVER_ACCEPT => { let (handler, addr) = server.accept()?; println!("accept from addr: {}", &addr); poll.register(&handler, SERVER, Ready::readable() | Ready::writable(), PollOpt::edge())?; server_handler = Some(handler); } SERVER => { if event.readiness().is_writable() { if let Some(ref mut handler) = &mut server_handler { match handler.write(SERVER_HELLO) { Ok(_) => { println!("server wrote"); } Err(ref err) if err.kind() == io::ErrorKind::WouldBlock => continue, err => { err?; } } } } if event.readiness().is_readable() { let mut hello = [0; 4]; if let Some(ref mut handler) = &mut server_handler { match handler.read_exact(&mut hello) { Ok(_) => { assert_eq!(CLIENT_HELLO, &hello); println!("server received"); } Err(ref err) if err.kind() == io::ErrorKind::WouldBlock => continue, err => { err?; } } } } } CLIENT => { if event.readiness().is_writable() { match client.write(CLIENT_HELLO) { Ok(_) => { println!("client wrote"); } Err(ref err) if err.kind() == io::ErrorKind::WouldBlock => continue, err => { err?; } } } if event.readiness().is_readable() { let mut hello = [0; 4]; match client.read_exact(&mut hello) { Ok(_) => { assert_eq!(SERVER_HELLO, &hello); println!("client received"); } Err(ref err) if err.kind() == io::ErrorKind::WouldBlock => continue, err => { err?; } } } } _ => unreachable!(), } } }; Ok(()) }
这个 demo 稍微有点长,接下来我们把它一步步分解。
直接看主循环
fn main() { // ... loop { poll.poll(&mut events, None).unwrap(); // ... } }
每次循环都得执行 poll.poll,第一个参数是用来存 events 的 Events, 容量是 1024;
#![allow(unused)] fn main() { let mut events = Events::with_capacity(1024); }
第二个参数是 timeout,即一个 Option<Duration>,超时会直接返回。返回类型是 io::Result<usize>。
其中的
usize代表events的数量,这个返回值是deprecated并且会在之后的版本移除,仅供参考
这里我们设置了 timeout = None,所以当这个函数返回时,必然是某些事件被触发了。让我们遍历 events:
#![allow(unused)] fn main() { match event.token() { SERVER_ACCEPT => { let (handler, addr) = server.accept()?; println!("accept from addr: {}", &addr); poll.register(&handler, SERVER, Ready::readable() | Ready::writable(), PollOpt::edge())?; server_handler = Some(handler); } SERVER => { if event.readiness().is_writable() { if let Some(ref mut handler) = &mut server_handler { match handler.write(SERVER_HELLO) { Ok(_) => { println!("server wrote"); } Err(ref err) if err.kind() == io::ErrorKind::WouldBlock => continue, err => { err?; } } } } if event.readiness().is_readable() { let mut hello = [0; 4]; if let Some(ref mut handler) = &mut server_handler { match handler.read_exact(&mut hello) { Ok(_) => { assert_eq!(CLIENT_HELLO, &hello); println!("server received"); } Err(ref err) if err.kind() == io::ErrorKind::WouldBlock => continue, err => { err?; } } } } } CLIENT => { if event.readiness().is_writable() { match client.write(CLIENT_HELLO) { Ok(_) => { println!("client wrote"); } Err(ref err) if err.kind() == io::ErrorKind::WouldBlock => continue, err => { err?; } } } if event.readiness().is_readable() { let mut hello = [0; 4]; match client.read_exact(&mut hello) { Ok(_) => { assert_eq!(SERVER_HELLO, &hello); println!("client received"); } Err(ref err) if err.kind() == io::ErrorKind::WouldBlock => continue, err => { err?; } } } } _ => unreachable!(), } }
我们匹配每一个 event 的 token,这里的 token 就是我用来注册的那些 token。比如我在上面注册了 server
#![allow(unused)] fn main() { // Start listening for incoming connections poll.register(&server, SERVER_ACCEPT, Ready::readable(), PollOpt::edge()).unwrap(); }
第二个参数就是 token
#![allow(unused)] fn main() { const SERVER_ACCEPT: Token = Token(0); }
这样当 event.token() == SERVER_ACCEPT 时,就说明这个事件跟我们注册的 server 有关,于是我们试图 accept 一个新的连接并把它注册进 poll,使用的 token 是 SERVER。
#![allow(unused)] fn main() { let (handler, addr) = server.accept()?; println!("accept from addr: {}", &addr); poll.register(&handler, SERVER, Ready::readable() | Ready::writable(), PollOpt::edge())?; server_handler = Some(handler); }
这样我们之后如果发现 event.token() == SERVER,我们就认为它和注册的 handler 有关:
#![allow(unused)] fn main() { if event.readiness().is_writable() { if let Some(ref mut handler) = &mut server_handler { match handler.write(SERVER_HELLO) { Ok(_) => { println!("server wrote"); } Err(ref err) if err.kind() == io::ErrorKind::WouldBlock => continue, err => { err?; } } } } if event.readiness().is_readable() { let mut hello = [0; 4]; if let Some(ref mut handler) = &mut server_handler { match handler.read_exact(&mut hello) { Ok(_) => { assert_eq!(CLIENT_HELLO, &hello); println!("server received"); } Err(ref err) if err.kind() == io::ErrorKind::WouldBlock => continue, err => { err?; } } } } }
这时候我们还需要判断 event.readiness(),这就是 register 函数的第三个参数,叫做 interest,顾名思义,就是“感兴趣的事”。它的类型是 Ready,一共四种,readable, writable, error 和 hup,可进行并运算。
在上面我们给 handler 注册了 Ready::readable() | Ready::writable(),所以 event 可能是 readable 也可能是 writable,所以我们要经过判断来执行相应的逻辑。注意这里的判断是
#![allow(unused)] fn main() { if ... { ... } if ... { ... } }
而非
#![allow(unused)] fn main() { if ... { ... } else if ... { ... } }
因为一个事件可能同时是 readable 和 writable。
容错性原则
大概逻辑先讲到这儿,这里先讲一下 mio 的“容错性原则”,即不能完全相信 event。
可以看到我上面有一段代码是这么写的
#![allow(unused)] fn main() { match event.token() { SERVER_ACCEPT => { let (handler, addr) = server.accept()?; println!("accept from addr: {}", &addr); poll.register(&handler, SERVER, Ready::readable() | Ready::writable(), PollOpt::edge())?; server_handler = Some(handler); } }
server.accept() 返回的是 io::Result<(TcpStream, SocketAddr)>。如果我们选择完全相信 event 的话,在这里 unwrap() 并没有太大问题 —— 如果真的有一个新的连接就绪,accept() 产生的 io::Result 是我们无法预料且无法处理的,我们应该抛给调用者或者直接 panic。
但问题就是,我们可以认为 event 的伪消息是可预料的,可能并没有一个新的连接准备就绪,这时候我们 accept() 会引发 WouldBlock Error。但我们不应该认为 WouldBlock 是一种错误 —— 这是一种友善的提醒。server 告诉我们:“并没有新的连接,请下次再来吧。”,所以在这里我们应该忽略(可以打个 log)它并重新进入循环。
像我后面写的那样:
#![allow(unused)] fn main() { match client.write(CLIENT_HELLO) { Ok(_) => { println!("client wrote"); } Err(ref err) if err.kind() == io::ErrorKind::WouldBlock => continue, err => { err?; } } }
Poll Option
好了,现在我们可以运行:
[async-io-demo] cargo run --example tcp
terminal 里打印出了
client wrote
accept from addr: 127.0.0.1:53205
client wrote
server wrote
server received
...
我们可以发现,在短短的 10 millis 内(let timeout = Duration::from_millis(10);),server 和 client 分别进行了数十次的读写!
如果我们不想进行这么多次读写呢?比如,我们只想让 server 写一次。在网络比较通畅的情况下,client 和 server 几乎一直是可写的,所以 Poll::poll 在数微秒内就返回了。
这时候就要看 register 的第四个参数了。
#![allow(unused)] fn main() { poll.register(&server, SERVER_ACCEPT, Ready::readable(), PollOpt::edge()).unwrap(); }
PollOpt::edge() 的类型是 PollOpt,一共有 level, edge, oneshot 三种,他们有什么区别呢?
比如在我上面的代码里,
#![allow(unused)] fn main() { if event.readiness().is_readable() { let mut hello = [0; 4]; match client.read_exact(&mut hello) { Ok(_) => { assert_eq!(SERVER_HELLO, &hello); println!("client received"); } Err(ref err) if err.kind() == io::ErrorKind::WouldBlock => continue, err => { err?; } } } }
我在收到一个 readable readiness 时,只读了四个字节。如果这时候缓冲区里有八字节的数据,那么:
- 如果我注册时使用
PollOpt::level(),我在下次poll时 一定 还能收到一次readable readiness event(只要我没有主动执行set_readiness(Read::empty())); - 如果我注册时使用
PollOpt::edge(),我在下次poll时 不一定 还能收到一次readable readiness event;
所以,使用 PollOpt::edge() 时有一个“排尽原则(Draining readiness)”,即每次触发 event 时一定要操作到资源耗尽返回 WouldBlock,即上面的代码要改成:
#![allow(unused)] fn main() { if event.readiness().is_readable() { let mut hello = [0; 4]; loop { match client.read_exact(&mut hello) { Ok(_) => { assert_eq!(SERVER_HELLO, &hello); println!("client received"); } Err(ref err) if err.kind() == io::ErrorKind::WouldBlock => break, err => { err?; } } } } }
那么,oneshot 又是怎样的行为呢?让我们回到上面的问题,如果我们只想让 handler 写一次,怎么办 —— 注册时使用 PollOpt::oneshot(),即
#![allow(unused)] fn main() { let (handler, addr) = server.accept()?; println!("accept from addr: {}", &addr); poll.register(&handler, SERVER, Ready::readable() | Ready::writable(), PollOpt::oneshot())?; server_handler = Some(handler); }
这样的话,你只能收到一次 SERVER 事件,除非你使用 Poll::reregister 重新注册 handler。
Poll::reregister可以更改PollOpt和interest
Still Block
其实上面这个 demo 还存在一个问题,即我们在回调代码块中使用了同步的 IO 操作 println!。我们要尽可能避免在回调的代码块里使用耗时的 IO 操作。
考虑到文件 IO (包括 Stdin, Stdout, Stderr) 速度很慢,我们只需要把所有的文件 IO 交给一个线程进行即可。
#![allow(unused)] fn main() { use std::sync::mpsc::{Sender, Receiver, channel, SendError}; #[derive(Clone)] pub struct Fs { task_sender: Sender<Task>, } impl Fs { pub fn new() -> Self { let (sender, receiver) = channel(); std::thread::spawn(move || { loop { match receiver.recv() { Ok(task) => { match task { Task::Println(ref string) => println!("{}", string), Task::Exit => return } }, Err(_) => { return; } } } }); Fs { task_sender: sender } } pub fn println(&self, string: String) { self.task_sender.send(Task::Println(string)).unwrap() } } pub enum Task { Exit, Println(String), } }
之后,可以使用 Fs::println 替换所有的 println!。
自定义事件
上面我们实现异步 println 比较简单,这是因为 println 并没有返回值,不需要进行后续操作。设想一下,如果要我们实现 open 和 ready_to_string,先异步地 open 一个文件,然后异步地 read_to_string,最后再异步地 println, 我们要怎么做?
最简单的写法是回调,像这样:
#![allow(unused)] fn main() { // src/fs.rs use crossbeam_channel::{unbounded, Sender}; use std::fs::File; use std::io::Read; use std::boxed::FnBox; use std::thread; use failure::Error; #[derive(Clone)] pub struct Fs { task_sender: Sender<Task>, } pub struct FsHandler { io_worker: thread::JoinHandle<Result<(), Error>>, executor: thread::JoinHandle<Result<(), Error>>, } pub fn fs_async() -> (Fs, FsHandler) { let (task_sender, task_receiver) = unbounded(); let (result_sender, result_receiver) = unbounded(); let io_worker = std::thread::spawn(move || { loop { match task_receiver.recv() { Ok(task) => { match task { Task::Println(ref string) => println!("{}", string), Task::Open(path, callback, fs) => { result_sender .send(TaskResult::Open(File::open(path)?, callback, fs))? } Task::ReadToString(mut file, callback, fs) => { let mut value = String::new(); file.read_to_string(&mut value)?; result_sender .send(TaskResult::ReadToString(value, callback, fs))? } Task::Exit => { result_sender .send(TaskResult::Exit)?; break; } } } Err(_) => { break; } } } Ok(()) }); let executor = std::thread::spawn(move || { loop { let result = result_receiver.recv()?; match result { TaskResult::ReadToString(value, callback, fs) => callback.call_box((value, fs))?, TaskResult::Open(file, callback, fs) => callback.call_box((file, fs))?, TaskResult::Exit => break }; }; Ok(()) }); (Fs { task_sender }, FsHandler { io_worker, executor }) } impl Fs { pub fn println(&self, string: String) -> Result<(), Error> { Ok(self.task_sender.send(Task::Println(string))?) } pub fn open<F>(&self, path: &str, callback: F) -> Result<(), Error> where F: FnOnce(File, Fs) -> Result<(), Error> + Sync + Send + 'static { Ok(self.task_sender.send(Task::Open(path.to_string(), Box::new(callback), self.clone()))?) } pub fn read_to_string<F>(&self, file: File, callback: F) -> Result<(), Error> where F: FnOnce(String, Fs) -> Result<(), Error> + Sync + Send + 'static { Ok(self.task_sender.send(Task::ReadToString(file, Box::new(callback), self.clone()))?) } pub fn close(&self) -> Result<(), Error> { Ok(self.task_sender.send(Task::Exit)?) } } impl FsHandler { pub fn join(self) -> Result<(), Error> { self.io_worker.join().unwrap()?; self.executor.join().unwrap() } } type FileCallback = Box<FnBox(File, Fs) -> Result<(), Error> + Sync + Send>; type StringCallback = Box<FnBox(String, Fs) -> Result<(), Error> + Sync + Send>; pub enum Task { Exit, Println(String), Open(String, FileCallback, Fs), ReadToString(File, StringCallback, Fs), } pub enum TaskResult { Exit, Open(File, FileCallback, Fs), ReadToString(String, StringCallback, Fs), } }
// examples/fs.rs use asyncio::fs::fs_async; use failure::Error; const TEST_FILE_VALUE: &str = "Hello, World!"; fn main() -> Result<(), Error> { let (fs, fs_handler) = fs_async(); fs.open("./examples/test.txt", |file, fs| { fs.read_to_string(file, |value, fs| { assert_eq!(TEST_FILE_VALUE, &value); fs.println(value)?; fs.close() }) })?; fs_handler.join()?; Ok(()) }
测试
[async-io-demo] cargo run --example fs
这样写在逻辑上的确是对的,但是负责跑 callback 的 executor 线程其实被负责 io 的线程阻塞住了(result_receiver.recv())。那我们能不能在 executor 线程里跑一个事件循环,以达到不被 io 线程阻塞的目的呢?(即确定 result_receiver 中有 result 时,executor 才会进行 result_receiver.recv()).
这就到了体现 mio 强大可拓展性的时候:注册用户态的事件队列。
把上面的代码稍加修改,就成了这样:
#![allow(unused)] fn main() { // src/fs_mio.rs use crossbeam_channel::{unbounded, Sender, TryRecvError}; use std::fs::File; use std::io::{Read}; use std::boxed::FnBox; use std::thread; use failure::Error; use std::time::Duration; use mio::*; #[derive(Clone)] pub struct Fs { task_sender: Sender<Task>, } pub struct FsHandler { io_worker: thread::JoinHandle<Result<(), Error>>, executor: thread::JoinHandle<Result<(), Error>>, } const FS_TOKEN: Token = Token(0); pub fn fs_async() -> (Fs, FsHandler) { let (task_sender, task_receiver) = unbounded(); let (result_sender, result_receiver) = unbounded(); let poll = Poll::new().unwrap(); let (registration, set_readiness) = Registration::new2(); poll.register(®istration, FS_TOKEN, Ready::readable(), PollOpt::oneshot()).unwrap(); let io_worker = std::thread::spawn(move || { loop { match task_receiver.recv() { Ok(task) => { match task { Task::Println(ref string) => println!("{}", string), Task::Open(path, callback, fs) => { result_sender .send(TaskResult::Open(File::open(path)?, callback, fs))?; set_readiness.set_readiness(Ready::readable())?; } Task::ReadToString(mut file, callback, fs) => { let mut value = String::new(); file.read_to_string(&mut value)?; result_sender .send(TaskResult::ReadToString(value, callback, fs))?; set_readiness.set_readiness(Ready::readable())?; } Task::Exit => { result_sender .send(TaskResult::Exit)?; set_readiness.set_readiness(Ready::readable())?; break; } } } Err(_) => { break; } } } Ok(()) }); let executor = thread::spawn(move || { let mut events = Events::with_capacity(1024); 'outer: loop { poll.poll(&mut events, Some(Duration::from_secs(1)))?; for event in events.iter() { match event.token() { FS_TOKEN => { loop { match result_receiver.try_recv() { Ok(result) => { match result { TaskResult::ReadToString(value, callback, fs) => callback.call_box((value, fs))?, TaskResult::Open(file, callback, fs) => callback.call_box((file, fs))?, TaskResult::Exit => break 'outer } } Err(e) => { match e { TryRecvError::Empty => break, TryRecvError::Disconnected => Err(e)? } } } } poll.reregister(®istration, FS_TOKEN, Ready::readable(), PollOpt::oneshot())?; } _ => unreachable!() } } }; Ok(()) }); (Fs { task_sender }, FsHandler { io_worker, executor }) } impl Fs { pub fn println(&self, string: String) -> Result<(), Error> { Ok(self.task_sender.send(Task::Println(string))?) } pub fn open<F>(&self, path: &str, callback: F) -> Result<(), Error> where F: FnOnce(File, Fs) -> Result<(), Error> + Sync + Send + 'static { Ok(self.task_sender.send(Task::Open(path.to_string(), Box::new(callback), self.clone()))?) } pub fn read_to_string<F>(&self, file: File, callback: F) -> Result<(), Error> where F: FnOnce(String, Fs) -> Result<(), Error> + Sync + Send + 'static { Ok(self.task_sender.send(Task::ReadToString(file, Box::new(callback), self.clone()))?) } pub fn close(&self) -> Result<(), Error> { Ok(self.task_sender.send(Task::Exit)?) } } impl FsHandler { pub fn join(self) -> Result<(), Error> { self.io_worker.join().unwrap()?; self.executor.join().unwrap() } } type FileCallback = Box<FnBox(File, Fs) -> Result<(), Error> + Sync + Send>; type StringCallback = Box<FnBox(String, Fs) -> Result<(), Error> + Sync + Send>; pub enum Task { Exit, Println(String), Open(String, FileCallback, Fs), ReadToString(File, StringCallback, Fs), } pub enum TaskResult { Exit, Open(File, FileCallback, Fs), ReadToString(String, StringCallback, Fs), } }
// examples/fs-mio.rs use asyncio::fs_mio::fs_async; use failure::Error; const TEST_FILE_VALUE: &str = "Hello, World!"; fn main() -> Result<(), Error> { let (fs, fs_handler) = fs_async(); fs.open("./examples/test.txt", |file, fs| { fs.read_to_string(file, |value, fs| { assert_eq!(TEST_FILE_VALUE, &value); fs.println(value)?; fs.close() }) })?; fs_handler.join()?; Ok(()) }
可以注意到,上面的代码发生的改变就是,executor 不再被 result_receiver.recv 阻塞,而变成了注册事件(registration)后等待 Poll::poll 返回事件;只有等到了新的事件,才会进行 result_receiver.try_recv。同时,io_worker 线程在 send result 之后会执行 set_readiness.set_readiness(Ready::readable())?;,以通知 executor 线程对相应结果做处理。
这样的话,executor 就不会被 io worker 阻塞了,因为我们可以把所有的事件都注册到 executor 上,mio::Poll 会同时监听多个事件(比如把 fs 和 tcp 结合起来)。
测试
[async-io-demo] cargo run --example fs-mio
Callback is evil
既然文件 IO 的 executor 不再会被 io worker 线程阻塞了,那我们来试试让 fs 和 tcp 共用一个 poll 然后建立一个简单的文件服务器吧。
但可以先等等,因为我已经开始觉得写 callback 有点难受了 —— 如果我们还想处理错误的话,会觉得更难受,像这样
use asyncio::fs_mio::fs_async; use failure::Error; const TEST_FILE_VALUE: &str = "Hello, World!"; fn main() -> Result<(), Error> { let (fs, fs_handler) = fs_async(); fs.open("./examples/test.txt", |file, fs| { fs.read_to_string(file, |value, fs| { assert_eq!(TEST_FILE_VALUE, &value); fs.println(value, |err| { ... } ); fs.close() }, |err| { ... } ) }, |err| { ... } )?; fs_handler.join()?; Ok(()) }
而且对 rust 来说,更加艰难的是闭包中的生命周期问题(闭包几乎不能通过捕获来借用环境变量)。这就意味着,如果我要借用环境中的某个变量,我要么 clone 它(如果它实现了 Clone 的话),要么把它作为闭包参数传入(意味着你要根据需要改每一层回调函数的签名,这太屎了)。
考虑到各种原因,rust 最终选择用 coroutine 作为异步 IO 的 API 抽象。
coroutine
这里所说的 coroutine 是指基于 rust generator 的 stackless coroutine 而非早期被 rust 抛弃的 green thread(stackful coroutine)。
generator
rust 大概在今年五月份引入了 generator,但到现在还是 unstable 的 —— 虽说也没多少人用 stable(误
一个典型的斐波那契 generator 如下
// examples/fab.rs #![feature(generators, generator_trait)] use std::ops::{Generator, GeneratorState}; fn main() { let mut gen = fab(5); loop { match unsafe { gen.resume() } { GeneratorState::Yielded(value) => println!("yield {}", value), GeneratorState::Complete(ret) => { println!("return {}", ret); break; } } } } fn fab(mut n: u64) -> impl Generator<Yield=u64, Return=u64> { move || { let mut last = 0u64; let mut current = 1; yield last; while n > 0 { yield current; let tmp = last; last = current; current = tmp + last; n -= 1; } return last; } }
由于 generator 的“中断特性”,我们很自然的可以想到,如果用 generator 搭配 mio,给每个 generator 分配一个 token,然后 poll mio 的事件循环,收到一个唤醒事件就 resume 相应的 generator;每个 generator 在要阻塞的时候拿自己的 token 注册一个唤醒事件然后 yield,不就实现了“同步代码”的异步 IO 吗?
这样看来原理上来说已经稳了,但 rust 异步 IO 的天空依旧漂浮着两朵乌云。
自引用
第一朵乌云和 rust 自身的内存管理机制有关。
如果你写出这样的 generator
#![allow(unused)] fn main() { fn self_ref_generator() -> impl Generator<Yield=u64, Return=()> { || { let x: u64 = 1; let ref_x: &u64 = &x; yield 0; yield *ref_x; } } }
rust 一定会给你抛个错然后告诉你 "borrow may still be in use when generator yields"。编译器没有教你怎么修正可能会让你有些恐慌,去不存在的搜索引擎上查了查,你发现这和 generator 的实现有关。
前文中提到,rust generator 是 stackless 的,即它并不会保留一个完整的栈,而是根据不同的状态保留需要的变量。如果你把上面的代码改成
#![allow(unused)] fn main() { fn no_ref_generator() -> impl Generator<Yield=u64, Return=()> { || { let x: u64 = 1; let ref_x: &u64 = &x; yield *ref_x; yield 0; } } }
在第一次 yield 结束之后,编译器会发现 generator 唯一需要保留的是字面量 0,所以这段代码可以顺利编译通过。但是,对于前面的 generator,第一次 yield 过后,编译器发现你需要同时保留 x 和它的引用 ref_x,这样的话 generator 就会变成类似这样的结构(仅供参考):
#![allow(unused)] fn main() { enum SomeGenerator<'a> { ... SomeState { _yield: u64, x: u64 ref_x: &'a u64 } ... } }
这就是 rust 中“臭名昭著” 的自引用,下面这段代码会发生什么呢
#![allow(unused)] fn main() { struct A<'a> { b: u64, ref_b: Option<&'a u64> } impl<'a> A<'a> { fn new() -> Self { let mut a = A{b: 1, ref_b: None}; a.ref_b = Some(&a.b); a } } }
你会发现它编译不过,当然这是很合理的,栈上的 a 变量拷贝出去之后其成员 b 的引用会失效,rust的生命周期机制帮你规避了这个问题。但即使你改成这样
#![allow(unused)] fn main() { use std::borrow::{BorrowMut}; struct A<'a> { b: u64, ref_b: Option<&'a u64> } impl<'a> A<'a> { fn boxed() -> Box<Self> { let mut a = Box::new(A{b: 1, ref_b: None}); let mut_ref: &mut A = a.borrow_mut(); mut_ref.ref_b = Some(&mut_ref.b); a } } }
这样按道理来说是没问题的,因为 a 的实体已经在堆上了,即使你拷贝它在栈上的引用,也不会改变其成员 b 的地址,引用一直是有效的 —— 但问题是,你没法跟编译器解释这事,编译器认为函数里面的 &mut_ref.b只能活到函数结束,这样含有这个引用的 a 自然也不能 move 出来。
那你可能会想,那我就在外面再取引用就好了
struct A<'a> { b: u64, ref_b: Option<&'a u64> } impl<'a> A<'a> { fn new() -> Self { A{b: 1, ref_b: None} } } fn main() { let mut a = A::new(); a.ref_b = Some(&a.b); }
这样的确没啥毛病,但是,你会发现自引用不仅阻止了 move,还阻止了你对 A 可变引用。。比如这样就编译不过
struct A<'a> { b: u64, ref_b: Option<&'a u64> } impl<'a> A<'a> { fn new() -> Self { A{b: 1, ref_b: None} } fn mute(&mut self) { } } fn main() { let mut a = A::new(); a.ref_b = Some(&a.b); a.mute(); }
但远古的 Future::poll 签名就长这样
#![allow(unused)] fn main() { fn poll(&mut self) -> Poll<Self::Item, Self::Error>; }
而直到现在 Generator::resume 的签名还是这样
#![allow(unused)] fn main() { unsafe fn resume(&mut self) -> GeneratorState<Self::Yield, Self::Return>; }
这样的话自引用会导致 generator 无法实现 Generator 和 Future
在这种情况下,我们可以使用 NonNull来避过编译器的检查
use std::ptr::NonNull; struct A { b: u64, ref_b: NonNull<u64> } impl A { fn new() -> Self { A{b: 1, ref_b: NonNull::dangling()} } } fn main() { let mut a = A::new(); a.ref_b = NonNull::from(&a.b); }
这样的确没有了烦人的生命周期约束,但也意味着你要自己保证内存安全 —— 绝对不能 move,也不能对其可变引用使用 mem::replace 或 mem::swap ,这样非常不妙。
Pin
那有没有办法通过其它方式来保证能保证它不能被 move 或者取可变引用呢?这就是 pin的应用场景了。pin具体的内容可以看这篇 RFC,本文只是简要说明一下。
rust 默认给大部分类型实现了 trait std::marker::Unpin,这只是一个标记,表示这个类型 move 是安全的,这时候,Pin<'a, T> 跟 &'a mut T 没有区别,你也可以安全地通过 Pin::new(&mut T) 和 Pin::as_mut(self: &mut Pin<T>)相互转换。
但对于不能安全 move 的类型,比如上面的 A,我们得先把它标记为 !Unpin,安全的标记方法是给它一个 !Unpin的成员,比如 Pinned。
#![feature(pin)] use std::marker::{Pinned}; use std::ptr::NonNull; struct A { b: u64, ref_b: NonNull<u64>, _pin: Pinned, } impl A { fn new() -> Self { A { b: 1, ref_b: NonNull::dangling(), _pin: Pinned, } } } fn main() { let mut a = A::new(); let mut pinned = unsafe { Pin::new_unchecked(&mut a) }; let ref_b = NonNull::from(&pinned.b); let mut_ref: Pin<&mut A> = pinned.as_mut(); unsafe {Pin::get_mut_unchecked(mut_ref).ref_b = ref_b}; let unmoved = pinned; assert_eq!(unmoved.ref_b, NonNull::from(&unmoved.b)); }
从 !Unpin 的类型构建 Pin 总是 unsafe 的,它们通过 Pin::new_unchecked 和 Pin::get_mut_unchecked 相互转换。当然,我们在构建时是可以保证它是 safe ,我们只要完成这两个 unsafe的操作,就可以保证:
- 永远不能
safe地获得可变引用:Pin::get_mut_unchecked是unsafe的 - 永远不能
safe地 move:因为Pin只拥有可变引用,且由于Pin::get_mut_unchecked是unsafe的,你不能safe地对其可变引用使用mem::replace或mem::swap
当然,如果你不想在构建时使用 unsafe或者想获得 a 的所有权以便在函数间传递,你可以使用 Box::pinned从而把它分配在堆上
struct A { b: u64, ref_b: NonNull<u64>, _pin: Pinned, } impl A { fn boxed() -> Pin<Box<Self>> { let mut boxed = Box::pinned(A { b: 1, ref_b: NonNull::dangling(), _pin: Pinned, }); let ref_b = NonNull::from(&boxed.b); let mut_ref: Pin<&mut A> = boxed.as_mut(); unsafe { Pin::get_mut_unchecked(mut_ref).ref_b = ref_b }; boxed } } fn main() { let boxed = A::boxed(); let unmoved = boxed; assert_eq!(unmoved.ref_b, NonNull::from(&unmoved.b)); }
有了 Pin 之后,新版 Future 的定义就是这样的了
#![allow(unused)] fn main() { pub trait Future { type Output; fn poll(self: Pin<&mut Self>, lw: &LocalWaker) -> Poll<Self::Output>; } }
合理的抽象
既然已经打算钦定了 coroutine 作为异步 IO 的 API 抽象,那应该把哪些东西加入标准库、哪些东西加入语法支持、哪些东西交给第三方实现呢?让开发者手动调用 unsafe 的 Generator::resume 终归不是很妙,也不好把 mio 作为唯一的底层异步 IO 实现(如果这样的话不如把 mio 也并入标准库)。
现在的 rust 提供了 async 的语法支持(以前是用过程宏的实现的)、await!的标准库宏支持,标准库 std::future 的 trait Future 和 struct GenFuture , 标准库 std::task 的 enum Poll<T>, struct LocalWaker, struct Waker 和 trait UnsafeWaker。
你需要给你的 MyWaker 实现 trait UnsafeWaker,用 mio 的话就用 SetReadiness,unsafe fn wake(&self) 用 SetReadiness::set_readiness 实现。然后把 MyWaker 包在 Waker, LocalWaker 里面。
Poll<T>
Poll<T> 的定义为
#![allow(unused)] fn main() { pub enum Poll<T> { Ready(T), Pending, } }
await!
await! 宏只能在 async 函数或者块里面用,传入一个 Future
await!(future)会被展开成
#![allow(unused)] fn main() { loop { if let Poll::Ready(x) = ::future::poll_with_tls(unsafe{ Pin::new_unchecked(&mut future) }) { break x; } yield } }
::future::poll_with_tls 即 thread-local waker,就是你传给这个 GenFuture::poll 的 LocalWaker,
async
async则会把 Generator 包装成 Future(GenFuture) 。
GenFuture 的相关定义如下
#![allow(unused)] fn main() { struct GenFuture<T: Generator<Yield = ()>>(T); impl<T: Generator<Yield = ()>> !Unpin for GenFuture<T> {} impl<T: Generator<Yield = ()>> Future for GenFuture<T> { type Output = T::Return; fn poll(self: Pin<&mut Self>, lw: &LocalWaker) -> Poll<Self::Output> { set_task_waker(lw, || match unsafe { Pin::get_mut_unchecked(self).0.resume() } { GeneratorState::Yielded(()) => Poll::Pending, GeneratorState::Complete(x) => Poll::Ready(x), }) } } pub fn from_generator<T: Generator<Yield = ()>>(x: T) -> impl Future<Output = T::Return> { GenFuture(x) } }
这里可以看到,GenFuture 在每次调用 self.0.resume 之前会 set_task_waker,通过一个 thread_local 的变量中转,从而 generator 里面的 future::poll 能通过 poll_with_tls 拿到这个 LocalWaker。
所以,下面的代码
#![allow(unused)] fn main() { async fn async_recv(string_channel: Receiver<String>) -> String { await!(string_channel.recv_future()) } }
会被类似地展开为这样
#![allow(unused)] fn main() { fn async_recv(string_channel: Receiver<String>) -> impl Future<Output = T::Return> { from_generator(move || { let recv_future = string_channel.recv_future(); loop { if let Poll::Ready(x) = ::future::poll_with_tls(unsafe{ Pin::new_unchecked(&mut recv_future) }) { break x; } yield } }) } }
non-blocking coroutine
掌握了上文的基础知识后,我们就可以开始实践了。
coroutine 本身并不意味着“非阻塞”,你完全可以在两次 yield 之间调用阻塞 IO 的 API 从而导致阻塞。 非阻塞的关键在于,在将要阻塞的时候(比如某个 API 返回了 io::ErrorKind::WouldBlock),在 GenFuture::poll 中用底层异步接口注册一个事件和唤醒回调(waker)然后自身休眠(yield),底层异步调度在特定事件发生的时候回调唤醒这个 Future。
下面我参照 romio 的异步调度实现了 Executor block_on, spawn, TcpListener 和 TcpStream,代码较长,建议 clone 后用编辑器看。(请注意区分 Poll(mio::Poll) 与 task::Poll 以及 net::{TcpListener, TcpStream}(mio::net::{TcpListener, TcpStream}) 与 TcpListener, TcpStream)
Executor
Executor 中包含 mio::Poll,main task waker 及用来管理 task 和 source 的 Slab 各一个。其本身并没有实现什么特别的方法,主要是初始化为 thread_local 的 EXECUTOR 供其它函数借用。
block_on
block_on 函数会阻塞当前线程,传入参数是一个 future: Future<Output=T>,被称为 main task;返回值类型是 T。该函数一般在最外层被调用。
block_on 会引用 thread_local EXECUTOR,主要逻辑是调用 mio::Poll::poll 来响应事件。block_on 把 0 - MAX_RESOURCE_NUM(1 << 31) 个 Token 分为三类。
-
main task token收到
Token为MAIN_TASK_TOKEN的事件即表示需要唤醒main task,执行main_task.poll,返回task::Poll::Ready(T)则block_on函数返回。 -
task token奇数
token表示由spawn函数分发的其它任务需要被唤醒,执行相应的task.poll,token和该事件在EXECUTOR.tasks中的index一一映射。 -
source token偶数
token表示由register_source函数注册的source需要被分发,执行相应source的waker()以唤醒分发它们的task。
spawn
分发任务
TcpListener
包装了 mio::net::TcpListener,accept 方法返回一个 Future。
TcpStream
包装了 mio::net::TcpStream, read和 write 方法均返回 Future。
echo-server
实现了 executor 之后,我们可以就写一个简单的 echo-server 了
// examples/async-echo #![feature(async_await)] #![feature(await_macro)] #[macro_use] extern crate log; use asyncio::executor::{block_on, spawn, TcpListener}; use failure::Error; fn main() -> Result<(), Error> { env_logger::init(); block_on( async { let mut listener = TcpListener::bind(&"127.0.0.1:7878".parse()?)?; info!("Listening on 127.0.0.1:7878"); while let Ok((mut stream, addr)) = await!(listener.accept()) { info!("connection from {}", addr); spawn( async move { let client_hello = await!(stream.read())?; let read_length = client_hello.len(); let write_length = await!(stream.write(client_hello))?; assert_eq!(read_length, write_length); stream.close(); Ok(()) }, )?; }; Ok(()) }, )? }
RUST_LOG=info cargo run --example async-echo
可以用 telnet 连上试试看。
后记
当然最后还留了一个 demo,就是把文件 IO 也封装为 coroutine 的非阻塞 IO,实现在 src/fs_future.rs 中,这时可以运行本文开头给的 example 了。
RUST_LOG=info cargo run --example file-server
用 telnet 测试
[~] telnet 127.0.0.1 7878
Trying 127.0.0.1...
Connected to localhost.
Escape character is '^]'.
Please enter filename: examples/test.txt
Hello, World!
Connection closed by foreign host.
读者有兴趣的话可以看一下 src/fs_future.rs 中的实现,这里就不细说,接下来我们再谈谈现在 coroutine API 的不足。
我目前发现的主要问题就是不能在 Future::poll 中使用 try,导致出现 Result 的地方只能 match,希望之后会有比较好的解决方案(比如给 task::Poll<Result<R, E>> 实现 Try)。
第二个问题是 Waker 最里面装的是 UnsafeWaker的 NonNull 指针,当然我能理解 rust 团队有性能等其它方面的考虑,但如果用 mio 的 set_readiness 封装出 MyWaker 的话,clone 完全不需要 NonNull,而且我在实际编码时因为这个出过空指针错误。。希望以后能提供一个更安全的选择。
「转」图解 Rust 所有权与生命周期
1.引言
所有权与生命周期是 Rust 语言非常核心的内容。其实不仅仅是 Rust 有这两个概念,在C/C++ 中也一样是存在的。而几乎所有的内存安全问题也源于对所有权和生命周期的错误使用。只要是不采用垃圾回收来管理内存的程序语言,都会有这个问题。只是 Rust 在语言级明确了这两个概念,并提供了相关的语言特性让用户可以显式控制所有权的转移与生命周期的声明。同时编译器会对各种错误使用进行检查,提高了程序的内存安全性。
所有权和生命周期其涉及的语言概念很多,本文主要是对梳理出与“所有权与生命周期”相关的概念,并使用 UML 的类图表达概念间的关系,帮助更好的理解和掌握。
图例说明
本文附图都是 UML 类图,UML 类图可以用来表示对概念的分析。表达概念之间的依赖、继承、聚合、组成等关系。图中的每一个矩形框都是一个语义概念,有的是抽象的语言概念,有的是 Rust 库中的结构和 Trait。
所有图中使用的符号也只有最基础的几个。图 1 对符号体系做简单说明,主要解释一下表达概念之间的关系的符号语言。
依赖关系:
依赖是 UML 中最基础的关系语义。 以带箭头的虚线表示,A 依赖与 B 表达如下图。直观理解可以是 A “看的见” B,而 B 可以对 A 一无所知。比如在代码中 结构体 A 中有 结构体 B 的成员变量,或者 A 的实现代码中有 B 的局部变量。这样如果找不到 B,A 是无法编译通过的。
关联关系:
一条实线连接表示两个类型直接有关联,有箭头表示单向"可见",无箭头表示相互之间可见。关联关系也是一种依赖,但是更具体。有时候两个类型之间的关联关系太复杂,需要用一个类型来表达,叫做关联类型,如例图中的 H.
聚合与组成:
聚合与组成都是表示的是整体和部分的关系。差别在于“聚合”的整体与部分可以分开,部分可以在多个整体之间共享。而“组成”关系中整体对部分有更强的独占性,部分不能被拆开,部分与整体有相同的生命周期。
继承与接口实现:
继承与接口实现都是一种泛化关系,C 继承自 A,表示 A 是更泛化的概念。UML 中各种关系语义也可以用 UML 自身来表达,如图 2:“关联”和“继承”都是“依赖”的具体体现方式。
总图
图 3 是本文的总图,后续各节分局部介绍。
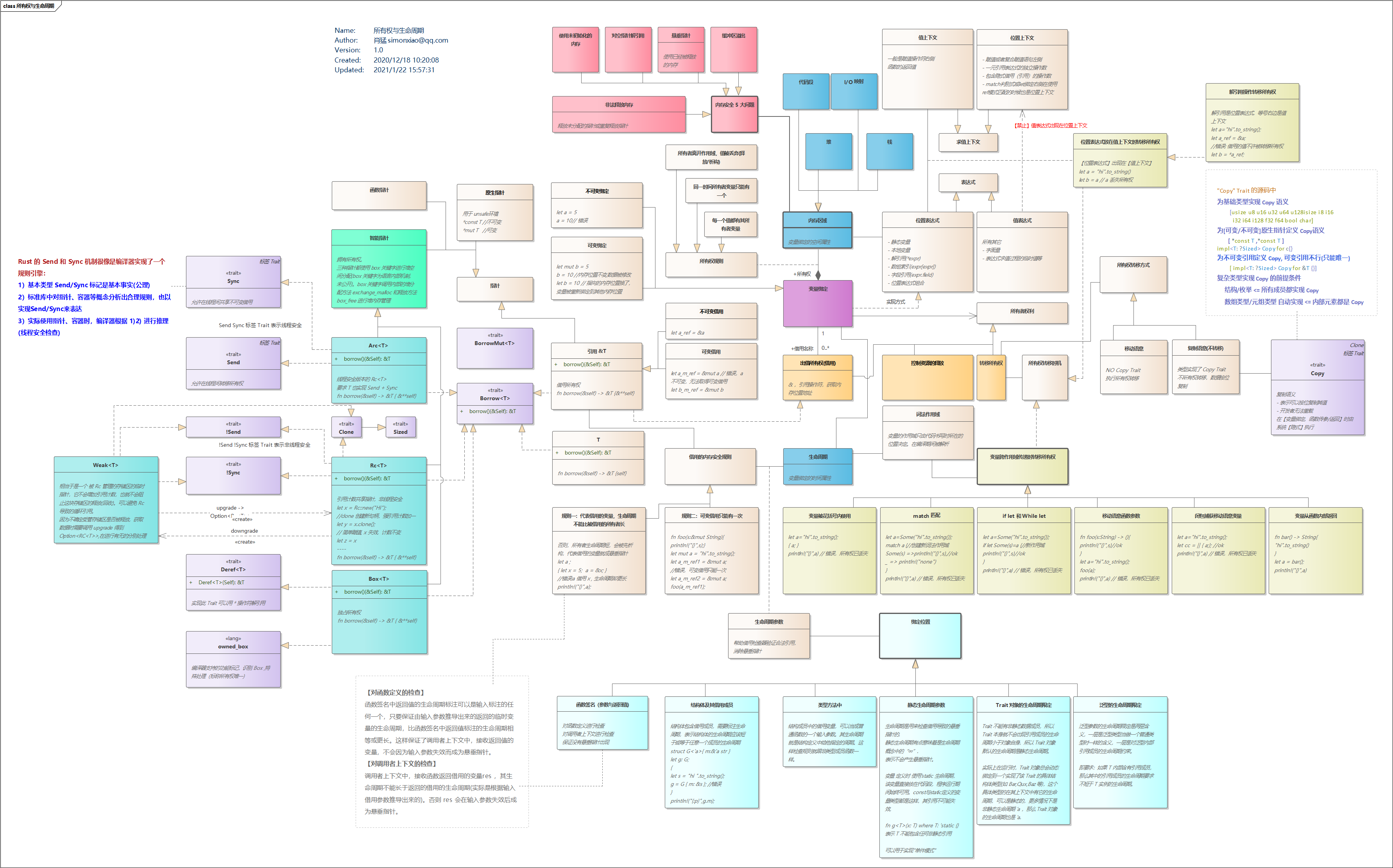
2.所有权与生命周期期望解决的问题
我们从图中间部分开始看起,所谓“所有权”是指对一个变量拥有了一块“内存区域”。这个内存区域,可以在堆上,可以在栈上,也可以在代码段,还有些内存地址是直接用于 I/O 地址映射的。这些都是内存区域可能存在的位置。
在高级语言中,这个内存位置要在程序中要能被访问,必然就会与一个或多个变量建立关联关系(低级语言如汇编语言,可以直接访问内存地址)。也就是说,通过这一个或多个变量,就能访问这个内存地址。
这就引出三个问题:
- 内存的不正确访问引发的内存安全问题
- 由于多个变量指向同一块内存区域导致的数据一致性问题
- 由于变量在多个线程中传递,导致的数据竞争的问题
由第一个问题引发的内存安全问题一般有 5 个典型情况:
- 使用未初始化的内存
- 对空指针解引用
- 悬垂指针(使用已经被释放的内存)
- 缓冲区溢出
- 非法释放内存(释放未分配的指针或重复释放指针)
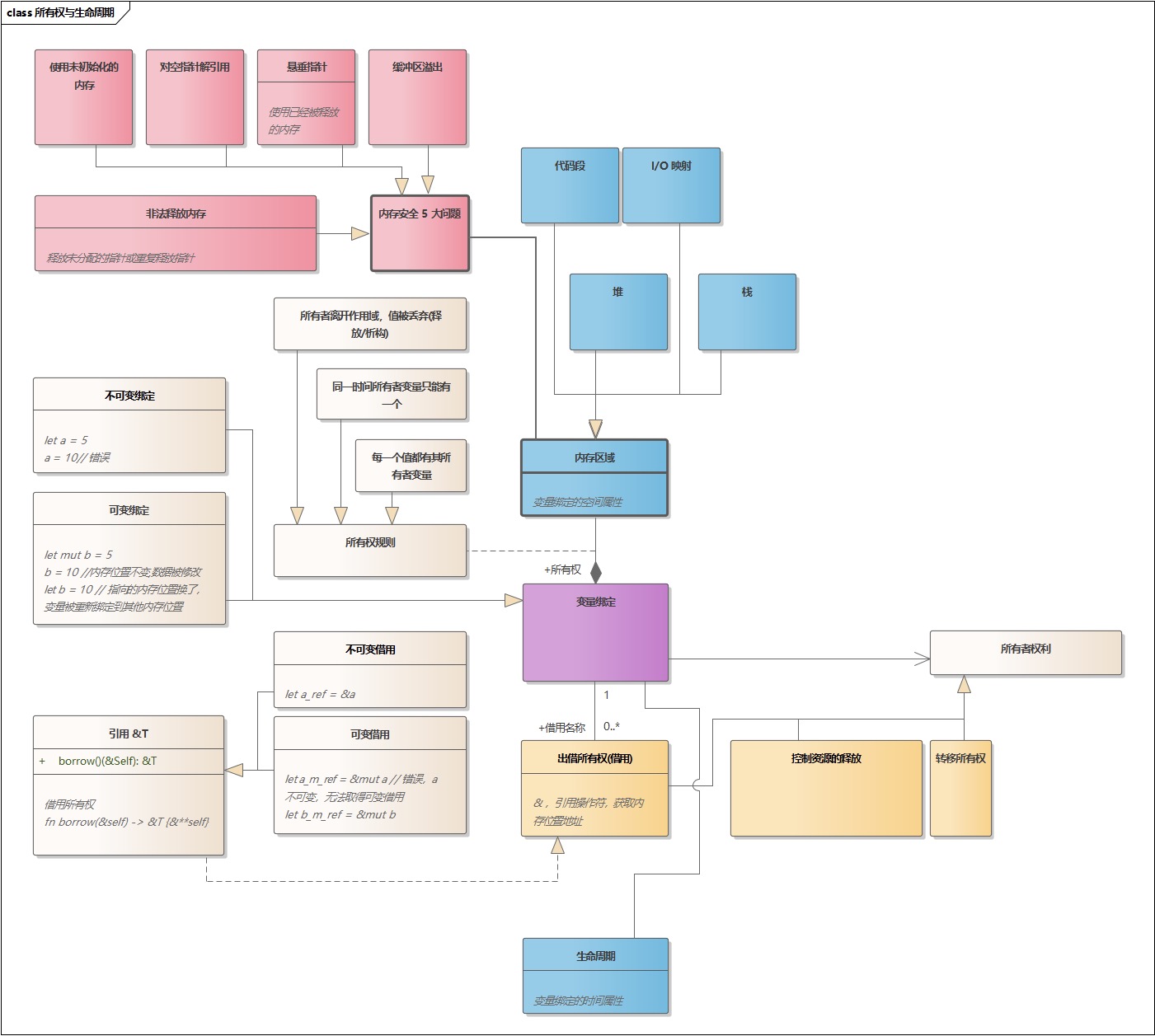
这些问题在 C/C++ 中是需要开发者非常小心的自己处理。 比如我们可以写一段 C++ 代码,把这五个内存安全错误全部犯一遍。
#include <iostream>
struct Point {
int x;
int y;
};
Point* newPoint(int x,int y) {
Point p { .x=x,.y=y };
return &p; //悬垂指针
}
int main() {
int values[3]= { 1,2,3 };
std::cout<<values[0]<<","<<values[3]<<std::endl; //缓冲区溢出
Point *p1 = (Point*)malloc(sizeof(Point));
std::cout<<p1->x<<","<<p1->y<<std::endl; //使用未初始化内存
Point *p2 = newPoint(10,10); //悬垂指针
delete p2; //非法释放内存
p1 = NULL;
std::cout<<p1->x<<std::endl; //对空指针解引用
return 0;
}
这段代码是可以编译通过的,当然,编译器还是会给出警告信息。这段代码也是可以运行的,也会输出信息,直到执行到最后一个错误处“对空指针解引用时”才会发生段错误退出。
Rust 的语言特性为上述问题提供了解决方案,如下表所示:
| 问题 | 解决方案 |
|---|---|
使用未初始化的内存 | 编译器禁止变量读取未赋值变量 |
对空指针解引用 | 使用 Option |
悬垂指针 | 生命周期标识与编译器检查 |
缓冲区溢出 | 编译器检查,拒绝超越缓冲区边界的数据访问 |
非法释放内存 | 语言级的 RAII 机制,只有唯一的所有者才有权释放内存 |
多个变量修改同一块内存区域 | 允许多个变量借用所有权,但是同一时间只允许一个可变借用 |
变量在多个线程中传递时的安全问题 | 对基本数据类型用 Sync 和 Send 两个 Trait 标识其线程安全特性,即能否转移所有权或传递可变借用,把这作为基本事实。再利用泛型限定语法和 Trait impl 语法描述出类型线程安全的规则。编译期间使用类似规则引擎的机制,基于基本事实和预定义规则为用户代码中的跨线程数据传递做推理检查。 |
3.变量绑定与所有权的赋予
Rust 中为什么叫“变量绑定”而不叫“变量赋值"。我们先来看一段 C++ 代码,以及对应的 Rust 代码。
C++:
#include <iostream>
int main()
{
int a = 1;
std::cout << &a << std::endl; /* 输出 0x62fe1c */
a = 2;
std::cout << &a << std::endl; /* 输出 0x62fe1c */
}
Rust:
fn main() {
let a = 1;
println!("a:{}",a); // 输出1
println!("&a:{:p}",&a); // 输出0x9cf974
//a=2; // 编译错误,不可变绑定不能修改绑定的值
let a = 2; // 重新绑定
println!("&a:{:p}",&a); // 输出0x9cfa14地址发生了变化
let mut b = 1; // 创建可变绑定
println!("b:{}",b); // 输出1
println!("&b:{:p}",&b); // 输出0x9cfa6c
b = 2;
println!("b:{}",b); // 输出2
println!("&b:{:p}",&b); // 输出0x9cfa6c地址没有变化
let b = 2; // 重新绑定新值
println!("&b:{:p}",&b); // 输出0x9cfba4地址发生了变化
}
我们可以看到,在 C++ 代码中,变量 a 先赋值为 1,后赋值为 2,但其地址没有发生变化。Rust 代码中,a 是一个不可变绑定,执行a=2动作被编译器拒绝。但是可以使用 let 重新绑定,但这时 a 的地址跟之前发生了变化,说明 a 被绑定到了另一个内存地址。b 是一个可变绑定,可以使用b = 2重新给它指向的内存赋值,b 的地址不变。但使用 let 重新绑定后,b 指向了新的内存区域。
可以看出,"赋值" 是将值写入变量关联的内存区域,"绑定" 是建立变量与内存区域的关联关系,Rust 里,还会把这个内存区域的所有权赋予这个变量。
不可变绑定的含义是:将变量绑定到一个内存地址,并赋予所有权,通过该变量只能读取该地址的数据,不能修改该地址的数据。对应的,可变绑定就可以通过变量修改关联内存区域的数据。从语法上看,有 let 关键字是绑定, 没有就是赋值。
这里我们能看出 Rust 与 C++ 的一个不同之处。C++ 里是没有“绑定”概念的。Rust 的变量绑定概念是一个很关键的概念,它是所有权的起点。有了明确的绑定才有了所有权的归属,同时解绑定的时机也确定了资源释放的时机。
所有权规则:
- 每一个值都有其所有者变量
- 同一时间所有者变量只能有一个
- 所有者离开作用域,值被丢弃(释放/析构)
作为所有者,它有如下权利:
- 控制资源的释放
- 出借所有权
- 转移所有权
4.所有权的转移
所有者的重要权利之一就是“转移所有权”。这引申出三个问题:
- 为什么要转移?
- 什么时候转移?
- 什么方式转移?
相关的语言概念如下图。
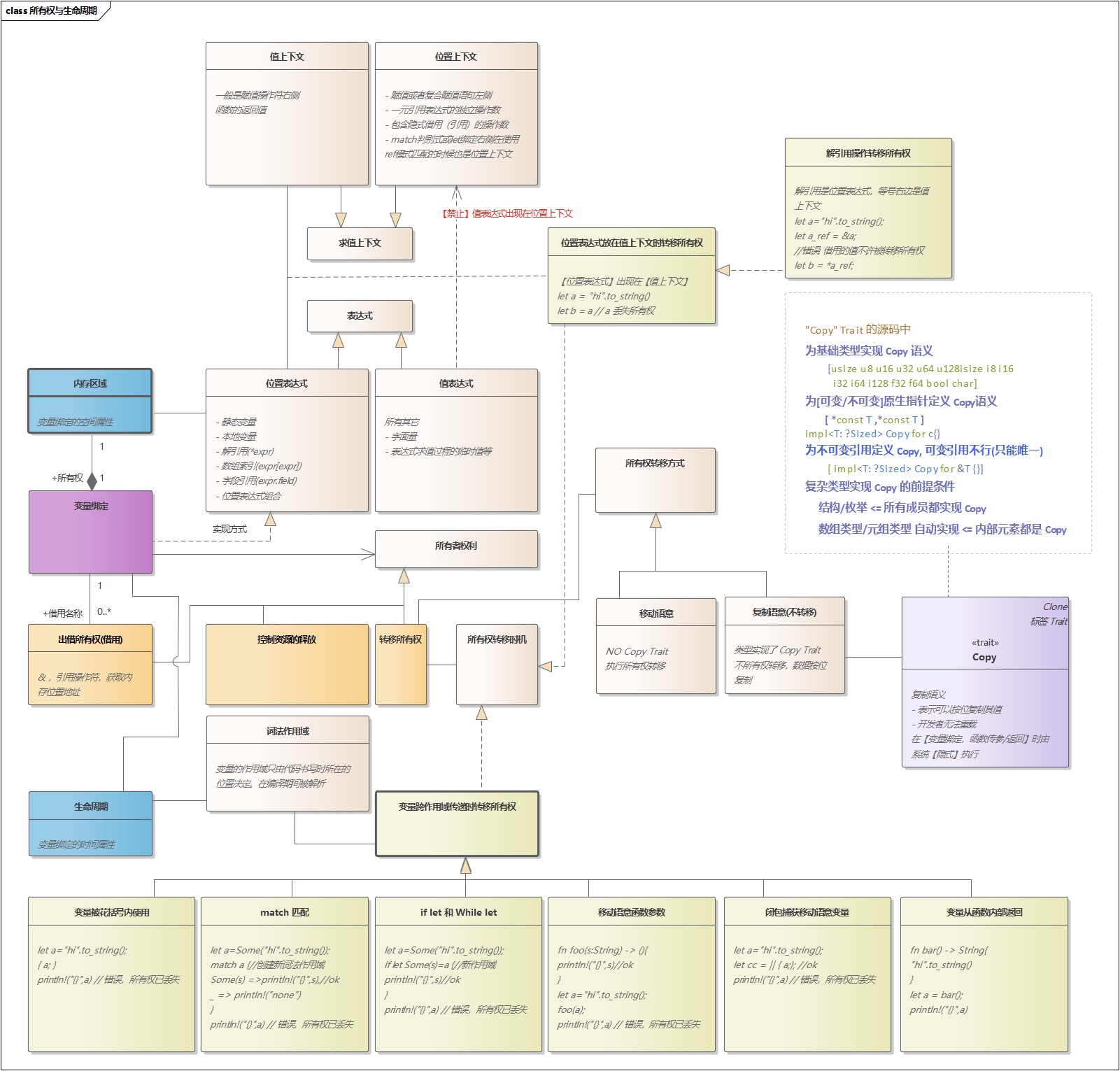
为什么要转移所有权? 我们知道,C/C++/Rust 的变量关联了某个内存区域,但变量总会在表达式中进行操作再赋值给另一个变量,或者在函数间传递。实际上期望被传递的是变量绑定的内存区域的内容,如果这块内存区域比较大,复制内存数据到给新的变量就是开销很大的操作。所以需要把所有权转移给新的变量,同时当前变量放弃所有权。所以归根结底,转移所有权还是为了性能。
所有权转移的时机总结下来有以下两种情况:
- 位置表达式出现在值上下文时转移所有权
- 变量跨作用域传递时转移所有权
第一条规则是一个精确的学术表达,涉及到位置表达式,值表达式,位置上下文,值上下文等语言概念。它的简单理解就是各种各样的赋值行为。能明确指向某一个内存区域位置的表达式是位置表达式,其它的都是值表达式。各种带有赋值语义的操作的左侧是位置上下文,右侧是值上下文。
当位置表达式出现在值上下文时,其程序语义就是要把这边位置表达式所指向的数据赋给新的变量,所有权发生转移。
第二条规则是“变量跨作用域时转移所有权”。
图上列举出了几种常见的跨作用域行为,能涵盖大多数情况,也有简单的示例代码
- 变量被花括号内使用
- match 匹配
- if let 和 While let
- 移动语义函数参数传递
- 闭包捕获移动语义变量
- 变量从函数内部返回
为什么变量跨作用域要转移所有权?在 C/C++ 代码中,是否转移所有权是程序员自己隐式或显式指定的。
试想,在 C/C++ 代码中,函数 Fun1 在栈上创建一个 类型 A 的实例 a, 把它的指针 &a 传递给函数 void fun2(A* param) 我们不会希望 fun2 释放这个内存,因为 fun1 返回时,栈上的空间会自动被释放。
如果 fun1 在堆上创建 A 的实例 a, 把它的指针 &a 传递给函数 fun2(A* param),那么关于 a 的内存空间的释放,fun1 和 fun2 之间需要有个商量,由谁来释放。fun1 可能期望由 fun2 来释放,如果由 fun2 释放,则 fun2 并不能判断这个指针是在堆上还是栈上。归根结底,还是谁拥有 a 指向内存区的所有权问题。 C/C++ 在语言层面上并没有强制约束。fun2 函数设计的时候,需要对其被调用的上下文做假定,在文档中对对谁释放这个变量的内存做约定。这样编译器实际上很难对错误的使用方式给出警告。
Rust 要求变量在跨越作用域时明确转移所有权,编译器可以很清楚作用域边界内外哪个变量拥有所有权,能对变量的非法使用作出明确无误的检查,增加的代码的安全性。
所有权转移的方式有两种:
- 移动语义-执行所有权转移
- 复制语义-不执行转移,只按位复制变量
这里我把 ”复制语义“定义为所有权转移的方式之一,也就是说“不转移”也是一种转移方式。看起来很奇怪。实际上逻辑是一致的,因为触发复制执行的时机跟触发转移的时机是一致的。只是这个数据类型被打上了 Copy 标签 trait, 在应该执行转移动作的时候,编译器改为执行按位复制。
Rust 的标准库中为所有基础类型实现的 Copy Trait。
这里要注意,标准库中的
impl<T: ?Sized> Copy for &T {}
为所有引用类型实现了 Copy, 这意味着我们使用引用参数调用某个函数时,引用变量本身是按位复制的。标准库没有为可变借用 &mut T 实现“Copy” Trait , 因为可变借用只能有一个。后文讲闭包捕获变量的所有权时我们可以看到例子。
5.所有权的借用
变量拥有一个内存区域所有权,其所有者权利之一就是“出借所有权”。
与出借所有权相关的概念关系如图 6
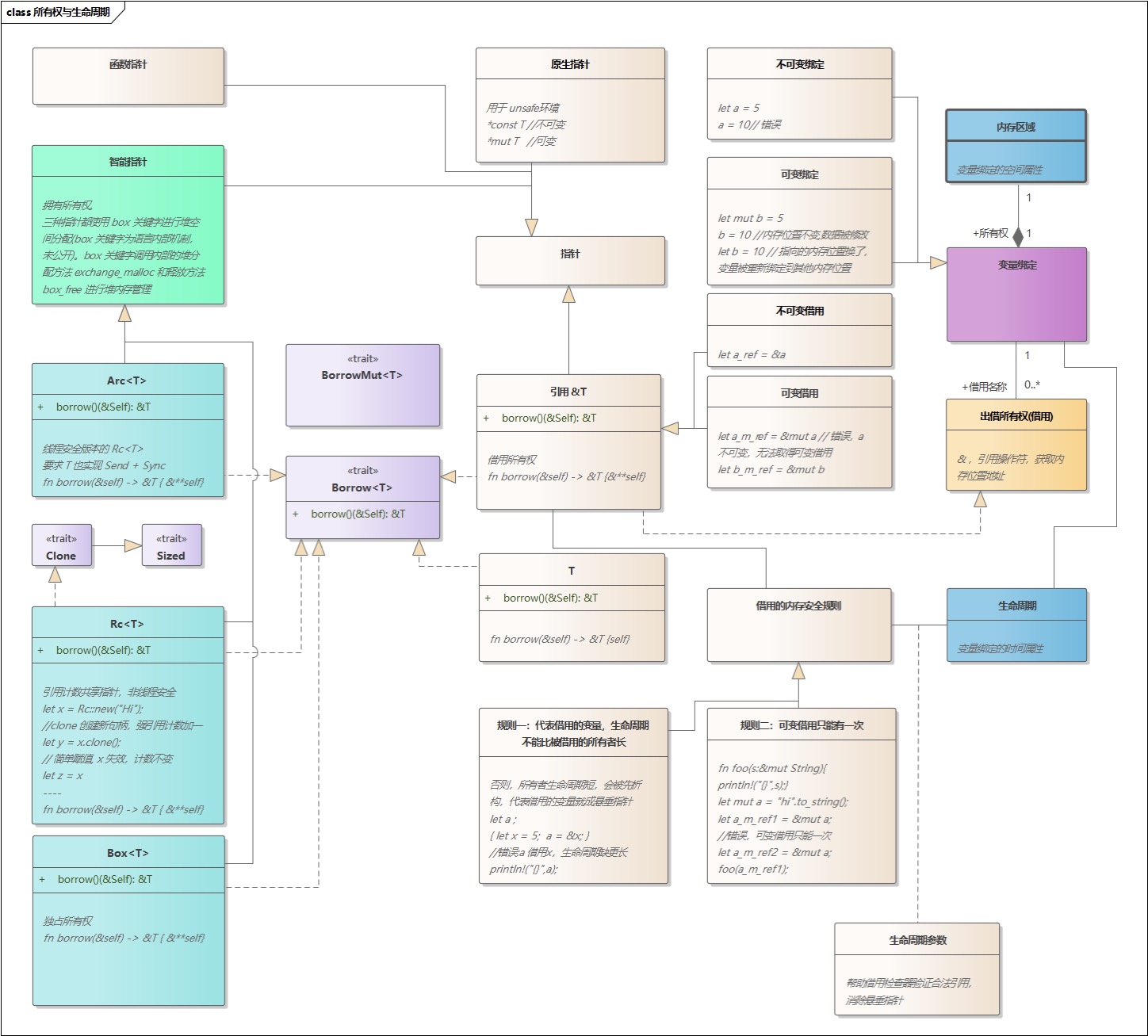
拥有所有权的变量借出其所有权有“引用”和“智能指针”两种方式:
-
引用(包含可变借用和不可变借用)
-
智能指针
- 独占式智能指针
Box<T> - 非线程安全的引用计数智能指针
Rc<T> - 线程安全的引用计数智能指针
Arc<T> - 弱指针
Weak<T>
- 独占式智能指针
引用实际上也是指针,指向的是实际的内存位置。
借用有两个重要的安全规则:
- 代表借用的变量,其生命周期不能比被借用的变量(所有者)的生命周期长
- 同一个变量的可变借用只能有一个
第一条规则就是确保不出现“悬垂指针”的内存安全问题。如果这条规则被违反,例如:变量 a 拥有存储区域的所有权,变量 b 是 a 的某种借用形式,如果 b 的生命周期比 a 长,那么 a 被析构后存储空间被释放,而 b 仍然可以使用,则 b 就成为了悬垂指针。
第二条是不允许有两个可变借用,避免出现数据一致性问题。
Struct Foo{v:i32}
fn main(){
let mut f = Foo{v:10};
let im_ref = &f; // 获取不可变引用
let mut_ref = & mut f; // 获取可变引用
//println!("{}",f.v);
//println!("{}",im_ref.v);
//println!("{}",mut_ref.v);
}
变量 f 拥有值的所有权,im_ref 是其不可变借用,mut_ref 是其可变借用。以上代码是可以编译过去的,但是这几个变量都没有被使用,这种情况下编译器并不禁止你同时拥有可变借用和不可变借用。最后的三行被注释掉的代码(6,7,8)使用了这些变量。打开一行或多行这些注释的代码,编译器会报告不同形式的错误:
| 开放注释行 | 编译器报告 |
|---|---|
| 6 | 正确 |
| 7 | 第 5 行错误:不能获得 f 的可变借用,因为已经存在不可变借用 |
| 8 | 正确 |
| 6, 7 | 第 5 行错误:不能获得 f 的可变借用,因为已经存在不可变借用 |
| 6,8 | 第 6 行错误:不能获得 f 的不可变借用,因为已经存在可变借用 |
对"借用" 的抽象表达
Rust 的核心包中有两个泛型 trait ,core::borrow::Borrow 与 core::borrow::BorrowMut,可以用来表达"借用"的抽象含义,分别代表可变借用和不可变借用。
前面提到,“借用”有多种表达形式 (&T,Box<T>,Rc<T> 等等),在不同的使用场景中会选择合适的借用表达方式。它们的抽象形式就可以用 core::borrow::Borrow 来代表. 从类型关系上, Borrow 是"借用" 概念的抽象形式。从实际应用上,某些场合我们希望获得某个类型的“借用”,同时希望能支持所有可能的“借用”形式,Borrow Trait 就有用武之地。
Borrow 的定义如下:
pub trait Borrow<Borrowed: ?Sized> {
fn borrow(&self) -> &Borrowed;
}
它只有一个方法,要求返回指定类型的引用。
Borrow 的文档中有提供例子
use std::borrow::Borrow;
fn check<T: Borrow<str>>(s: T) {
assert_eq!("Hello", s.borrow());
}
fn main(){
let s: String = "Hello".to_string();
check(s);
lets: &str = "Hello";
check(s);
}
check 函数的参数表示它希望接收一个 “str”类型的任何形式的“借用”,然后取出其中的值与 “Hello”进行比较。
标准库中为 String 类型实现了 Borrow<str>,代码如下
impl Borrow<str> for String{
#[inline]
fn borrow(&self) -> &str{
&self[..]
}
}
所以 String 类型可以作为 check 函数的参数。
从图上可以看出,标准库为所有类型 T 实现了 Borrow Trait, 也为 &T 实现了 Borrow Trait。
代码如下 ,这如何理解。
impl<T: ?Sized> Borrow<T> for T {
fn borrow(&self) -> &T { // 是 fn borrow(self: &Self)的缩写,所以 self 的类型就是 &T
self
}
}
impl<T: ?Sized> Borrow<T> for &T {
fn borrow(&self) -> &T {
&**self
}
}
这正是 Rust 语言很有意思的地方,非常巧妙的体现了语言的一致性。既然 Borrow<T> 的方法是为了能获取 T 的引用,那么类型 T 和 &T 当然也可以做到这一点。在 Borrow for T 的实现中,
fn borrow(&self)->&T 是 fn borrow(self: &Self)->&T 的缩写,所以 self 的类型就是 &T,可以直接被返回。在 Borrow for &T 的实现中,fn borrow(&self)->&T 是 fn borrow(self: &Self)->&T 的缩写,所以 self 的类型就是 &&T, 需要被两次解引用得到 T, 再返回其引用。
智能指针 Box<T>,Rc<T>,Arc<T>,都实现了 Borrow<T> ,其获取 &T 实例的方式都是两次解引用在取引用。Weak<T> 没有实现 Borrow<T>, 它需要升级成 Rc<T> 才能获取数据。
6.生命周期参数
变量的生命周期主要跟变量的作用域有关,在大部分程序语言中都是隐式定义的。Rust 中能显式声明变量的生命周期参数,这是非常独特的设计,其语法特性在其他语言也是不太可能见到的。以下是生命周期概念相关的图示。
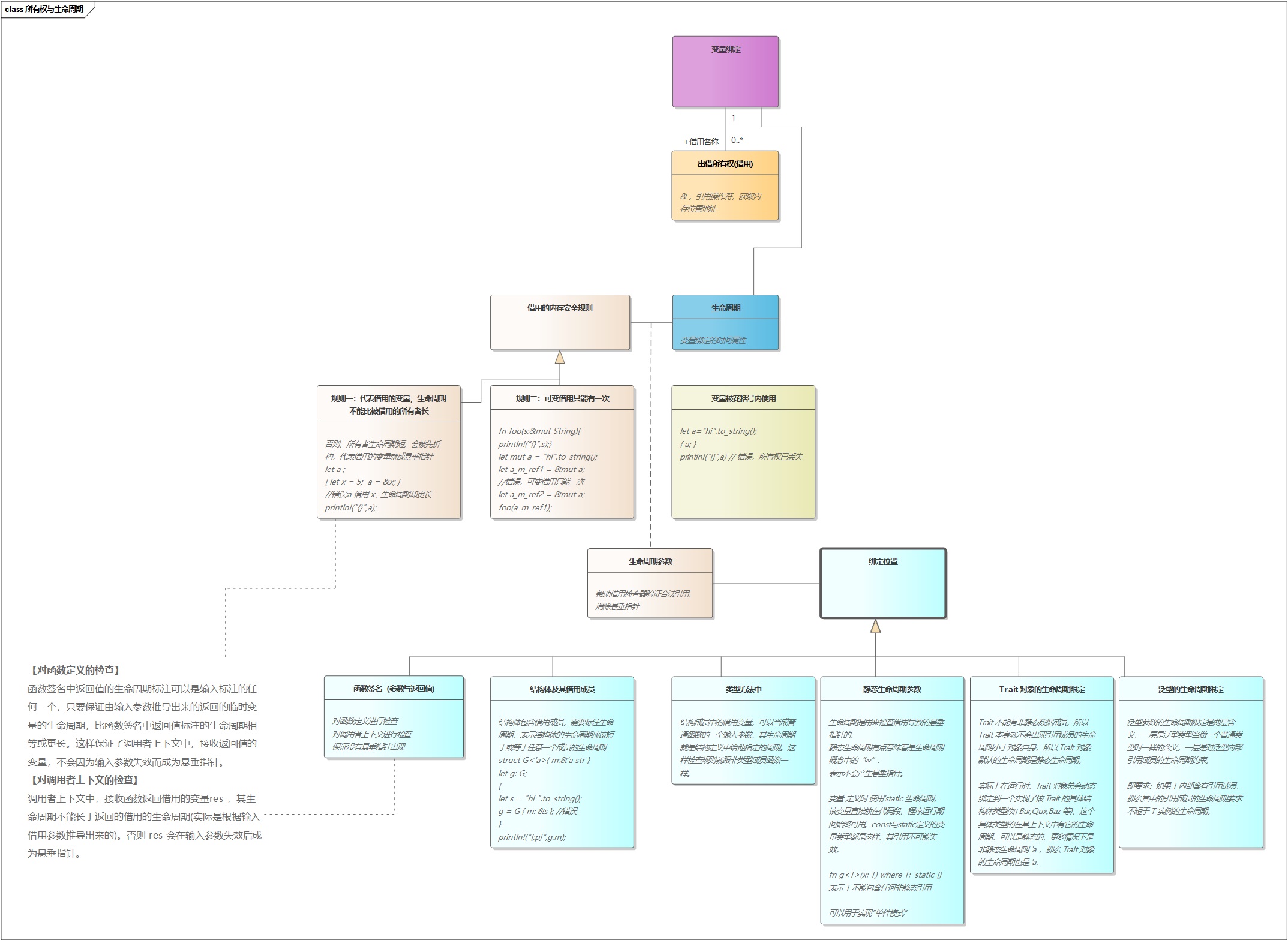
生命周期参数的作用
生命周期参数的核心作用就是解决悬垂指针问题。就是让编译器帮助检查变量的生命周期,防止出现变量指向的内存区域被释放后,变量仍然可以使用的问题。那么什么情况下会让编译器无法判断生命周期,而必须引入一个特定语法来对生命周期进行标识?
我们来看看最常见的悬垂指针问题,函数以引用方式返回函数内部的局部变量:
struct V{v:i32}
fn bad_fn() -> &V{ //编译错误:期望一个命名的生命周期参数
let a = V{v:10};
&a
}
let res = bad_fn();
这个代码是一个典型的悬垂指针错误,a 是函数内的局部变量,函数返回后 a 就被销毁,把 a 的引用赋值给 res ,如果能执行成功,res 绑定的就是未定义的值。
但编译器并不是报告悬垂指针错误,而是说返回类型 &V 没有指定生命周期参数。C++ 的类似代码编译器会给出悬垂指针的警告(警告内容:局部变量的地址被返回了)。
那我们指定一个生命周期参数看看:
fn bad_fn<'a>() -> &'a V{
let a = V{v:10};
let ref_a = &a;
ref_a //编译错误:不能返回局部变量的引用
}
这次编译器报告的是悬垂指针错误了。那么编译器的分析逻辑是什么?
首先我们明确一下 'a 在这里的精确语义到底是什么?
函数将要返回的引用会代表一个内存数据,这个数据有其生命周期范围,'a 参数是对这个生命周期范围提出的要求。就像 &V 是对返回值类型提的要求类似,'a 是对返回值生命周期提的要求。编译器需要检查的就是实际返回的数据,其生命是否符合要求。
那么 'a 参数对返回值的生命周期到底提出了什么要求?
我们先区分一下"函数上下文"和“调用者上下文”,函数上下文是指函数体内部的作用域范围,调用者上下文是指该函数被调用的位置。上述的悬垂指针错误其实并不会影响函数上下文范围的程序执行,出问题的地方是调用者上下文拿到一个无效引用并使用时,会出现不可预测的错误。
函数返回的引用会在“调用者上下文”中赋予某个变量,如:
let res = bod_fn();
res 获得了返回的引用, 函数内的 ref_a 引用会按位复制给变量 res (标准库中 impl<T: ?Sized> Copy for &T {} 指定了此规则)res 会指向 函数内 res_a 同样的数据。为了保证将来在调用者上下文不出悬垂指针,编译器真正要确保的是 res 所指向的数据的生命周期,不短于 res 变量自己的生命周期。否则如果数据的生命周期短,先被释放,res 就成为悬垂指针。
可以把这里的 'a 参数理解为调用者上下文中接收函数返回值的变量 res 的生命周期,那么 'a 对函数体内部返回引用的要求是:返回引用所指代数据的生命周期不短于 'a ,也就是不短于调用者上下文接收返回值的变量的生命周期。
上述例子中函数内 ref_a 指代的数据生命周期就是函数作用域,函数返回前,数据被销毁,生命周期小于调用者上下文的 res, 编译器根据 返回值的生命周期要求与实际返回值做比较,发现了错误。
实际上,返回的引用或者是静态生命周期,或者是根据函数输入的引用参数通过运算变换得来的,否则都是这个结果,因为都是对局部数据的引用。
静态生命周期
看函数
fn get_str<'a>() -> &'a str {
let s = "hello";
s
}
这个函数可以编译通过,返回的引用虽然不是从输入参数推导,不过是静态生命周期,可以通过检查。
因为静态生命周期可以理解为“无穷大”的语义,实际是跟进程的生命周期一致,也就是在程序运行期间始终有效。
Rust 的字符串字面量是存储在程序代码中,程序加载后在代码空间,始终有效。可以通过一个简单试验验证这一点:
let s1="Hello";
println!("&s1:{:p}", &s1);//&s1:0x9cf918
let s2="Hello";
println!("&s2:{:p}",&s2);//&s2:0x9cf978
//s1,s2是一样的值但是地址不一样,是两个不同的引用变量
let ptr1: *const u8 = s1.as_ptr();
println!("ptr1:{:p}", ptr1);//ptr1:0x4ca0a0
let ptr2: *const u8 = s2.as_ptr();
println!("ptr2:{:p}", ptr2);//ptr2:0x4ca0a0
s1,s2 的原始指针都指向同一个地址,说明编译器为 "Hello" 字面量只保存了一份拷贝,所有引用都指向它。
get_str 函数中静态生命周期长于返回值要求的'a,所以是合法的。
如果把 get_str 改成
fn get_str<'a>() -> &'static str
即把对返回值生命周期的要求改为无穷大,那就只能返回静态字符串引用了。
函数参数的生命周期
前面的例子为了简单起见,没有输入参数,这并不是一个典型的情况。大多数情况下,函数返回的引用是根据输入的引用参数通过运算变换而来。比如下面的例子:
fn remove_prefix<'a>(content:&'a str,prefix:&str) -> &'a str{
if content.starts_with(prefix){
let start:usize = prefix.len();
let end:usize = content.len();
let sub = content.get(start..end).unwrap();
sub
}else{
content
}
}
let s = "reload";
let sub = remove_prefix(&s0,"re");
println!("{}",sub); // 输出: load
remove_prefix 函数从输入的 content 字符串中判断是否有 prefix 代表的前缀。 如果有就返回 content 不包含前缀的切片,没有就返回 content 本身。
无论如何这个函数都不会返回前缀 prefix ,所以 prefix 变量不需要指定生命周期。
函数两个分支返回的都是通过 content 变量变换出来的,并作为函数的返回值。所以 content 必须标注生命周期参数,编译器要根据 content 的生命周期参数与返回值的要求进行比较,判断是否符合要求。即:实际返回数据的生命周期,大于或等于返回参数要求的生命周期。
前面说到,我们把返回参数中指定的生命周期参数 'a 看做调用者上下文中接收返回值的变量的生命周期,在这个例子中就是字符串引用 sub,那么输入参数中的 'a 代表什么意思 ?
这在 Rust 语法设计上是一个很让人困惑的地方,输入参数和输出参数的生命周期都标志为 'a ,似乎是要求两者的生命周期要求一致,但实际上并不是这样。
我们先看看如果输入参数的生命周期跟输出参数期待的不一样是什么情况,例如下面两个例子:
fn echo<'a, 'b>(content: &'b str) -> &'a str {
content //编译错误:引用变量本身的生命周期超过了它的借用目标
}
fn longer<'a, 'b>(s1: &'a str, s2: &'b str) -> &'a str {
if s1.len() > s2.len()
{ s1 }
else
{ s2 }//编译错误:生命周期不匹配
}
echo 函数输入参数生命周期标注为 'b , 返回值期待的是 'a .编译器报错信息是典型的“悬垂指针”错误。不过内容似乎并不明确。编译器指出查阅详细信息 --explain E0312 ,这里的解释是"借用内容的生命周期与期待的不一致"。这个错误描述就与实际的错误情况是相符合的了。
longer 函数两个参数分别具有生命周期 'a 和 'b , 返回值期待 'a ,当返回 s2 时,编译器报告生命周期不匹配。把 longer 函数中的生命周期 'b 标识为比 'a 长,就可以正确编译了。
fn longer<'a, 'b: 'a>(s1: &'a str, s2: &'b str) -> &'a str {
if s1.len() > s2.len()
{ s1 }
else
{ s2 }//编译通过
}
回到我们前面的问题,那么输入参数中的 'a 代表什么意思 ?
我们知道编译器在函数定义上下文中所做的生命周期检查就是要确保”实际返回数据的生命周期,大于或等于返参数要求的生命周期“。当输入参数给出与返回值一样的生命周期参数 'a 时,实际上是人为地向编译器保证:在调用者上下文中,实际给出的函数输入参数的生命周期,不小于将来用于接收返回值的变量的生命周期。
当有两个生命周期参数 'a 'b , 而 'b 大于 'a,当然 也保证了在调用者上下文 'b 代表的输入参数生命周期也足够长。
在函数定义中,编译器并不知道将来实际调用这个函数的上下文是怎么样的。生命周期参数相当是函数上下文与调用者上下文之间关于参数生命周期的协议。
就像函数签名中的类型声明一样,类型声明约定了与调用者之间输入输出参数的类型,编译器编译函数时,会检查函数体返回的数据类型与声明的返回值是否一致。同样对与参数与返回值的生命周期,函数也会检查函数体中返回的变量生命周期与声明的是否一致。
前面说的是编译器在“函数定义上下文的生命周期检查”机制,这只是生命周期检查的一部分,还有另一部分就是“调用者上下文对生命周期的检查”机制。两者检查的规则如下:
函数定义上下文的生命周期检查:
函数签名中返回值的生命周期标注可以是输入标注的任何一个,只要保证由输入参数推导出来的返回的临时变量的生命周期,比函数签名中返回值标注的生命周期相等或更长。这样保证了调用者上下文中,接收返回值的变量,不会因为输入参数失效而成为悬垂指针。
调用者上下文对生命周期的检查:
调用者上下文中,接收函数返回借用的变量 res ,其生命周期不能长于返回的借用的生命周期(实际是根据输入借用参数推导出来的)。否则 res 会在输入参数失效后成为悬垂指针。
前面 remove_prefix 函数编译器已经校验合格,那么我们在调用者上下文中构建如下例子
let res: &str;
{
let s = String::from("reload");
res = remove_prefix(&s, "re") //编译错误:s 的生命周期不够长
}
println!("{}", res);
这个例子中 remove_prefix 被调用这一行,编译器会报错 “s 的生命周期不够长”。代码中的 大括号创建了一个新的词法作用域,导致 res 的生命周期比大括号内部的 s 更长。这不符合函数签名中对生命周期的要求。函数签名要求输入参数的生命周期不短于返回值要求的生命周期。
结构体定义中的生命周期
结构体中有引用成员时,就会有潜在的悬垂指针问题,需要标识生命周期参数来让编译器帮助检查。
struct G<'a>{ m:&'a str}
fn get_g() -> () {
let g: G;
{
let s0 = "Hi".to_string();
let s1 = s0.as_str(); //编译错误:借用值存活时间不够长
g = G{ m: s1 };
}
println!("{}", g.m);
}
上面的例子中,结构体 G 包含了引用成员,不指定生命周期参数是无法编译的。函数 get_g 演示了在使用者上下文中如何出现生命周期不匹配的情况。
结构体的生命周期定义就是要保证在一个结构体实例中,其引用成员的生命周期不短于结构体实例自身的生命周期。否则如果结构体实例存活期间,其引用成员的数据先被销毁,那么访问这个引用成员时就构成了对悬垂指针的访问。
实际上结构体的生命周期参数可以和函数生命周期参数做类比,成员的生命周期相当函数的输入参数的生命周期,结构体整体的生命周期相当函数返回值的生命周期。这样所有之前对函数生命周期参数的分析一样可以适用。
如果结构体有方法成员会返回引用参数,方法同样需要填写生命周期参数。返回的引用来源可以是方法的输入引用参数,也可以是结构体的引用成员。在做生命周期分析的时候,可以把“方法的输入引用参数”和“结构体的引用成员”都看做普通函数的输入参数,这样前面对普通函数参数和返回值的生命周期分析方法可以继续套用。
泛型的生命周期限定
前文说过生命周期参数跟类型限定很像,比如在代码
fn longer<'a>(s1:&'a str, s2:&'a str) -> &'a str
struct G<'a>{ m:&'a str }
中,'a 出现的位置参数类型旁边,一个对参数的静态类型做限定,一个对参数的动态时间做限定。'a 使用前需要先声明,声明的位置与模板参数的位置一样,在 <> 括号内,也是用来放泛型的类型参数的地方。
那么,把类型换成泛型可以吗,语义是什么?使用场景是什么?
我们看看代码例子:
use std::cmp::Ordering;
#[derive(Eq, PartialEq, PartialOrd, Ord)]
struct G<'a, T:Ord>{ m: &'a T }
#[derive(Eq, PartialEq, PartialOrd, Ord)]
struct Value{ v: i32 }
fn longer<'a, T:Ord>(s1: &'a T, s2: &'a T) -> &'a T {
if s1 > s2 { s1 } else { s2 }
}
fn main(){
let v0 = Value{ v:12 };
let v1 = Value{ v:15 };
let res_v = longer(&v0, &v1);
println!("{}", res_v.v);//15
let g0 = G{ m: &v0 };
let g1 = G{ m: &v1 };
let res_g = longer(&g0, &g1);//15
println!("{}", res_g.m.v);
}
这个例子扩展了 longer 函数,可以对任何实现了 Ord trait 的类型进行操作。 Ord 是核心包中的一个用于实现比较操作的内置 trait. 这里不细说明。longer 函数跟前一个版本比较,只是把 str 类型换成了泛型参数 T, 并给 T 增加了类型限定 T:Ord.
结构体 G 也扩展成可以容纳泛型 T,但要求 T 实现了 Ord trait.
从代码及执行结果看,跟 把 T 当成普通类型一样,没有什么特别,生命周期参数依然是他原来的语义。
但实际上 "&'a T" 还隐含另一层语义:如果 T 内部含有引用成员,那么其中的引用成员的生命周期要求不短于 T 实例的生命周期。
老规矩,我们来构造一个反例。结构体 G 内部包含一个泛型的引用成员,我们将 G 用于 longer 函数,但是让 G 内部的引用成员生命周期短于 G。代码如下:
fn main(){
let v0 = Value{ v:12 };
let v1_ref: &Value; // 将 v1 的引用定义在下面大括号之外,有意延长变量的生命周期范围
let res_g: &G<Value>;
{
let v1 = Value{ v:15 };
v1_ref = &v1; //编译错误:v1的生命周期不够长。
let res_v = longer(&v0,v1_ref);
println!("{}",res_v.v);
}
let g0 = G{ m:&v0 };
let g1 = G{ m:v1_ref }; // 这时候 v1_ref 已经是悬垂指针
res_g = longer(&g0, &g1);
println!("{}", res_g.m.v);
}
变量 g1 自身的生命周期是满足 longer 函数要求的,但是其内部的引用成员,生命周期过短。
这个范例是在“调用者上下文”检查时触发的,对泛型参数的生命周期限定比较难设计出在“函数定义或结构体定义上下文”触发的范例。毕竟 T 只是类型指代,定义时还没有具体类型。
实际上要把在 “struct G<'a,T>{m:&'a T}中,T 的所有引用成员的生命周期不短于'a ”这个语义准确表达,应该写成:
struct G<'a,T:'a>{m:&'a T}
因为 T:'a 才是这个语义的明确表述。但是第一种表达方式也是足够的(我用反证法证明了这一点)。所以编译器也接受第一种比较简化的表达形式。
总而言之,泛型参数的生命周期限定是两层含义,一层是泛型类型当做一个普通类型时一样的含义,一层是对泛型内部引用成员的生命周期约束。
Trait 对象的生命周期
看如下代码
trait Foo{}
struct Bar{v:i32}
struct Qux<'a>{m:&'a i32}
struct Baz<'a,T>{v:&'a T}
impl Foo for Bar{}
impl<'a> Foo for Qux<'a>{}
impl<'a,T> Foo for Baz<'a,T>{}
结构体 Bar,Qux,Baz 都实现了 trait Foo, 那么 &Foo 类型可以接受这三个结构体的任何一个的引用类型。
我们把 &Foo 称为 Trait 对象。
Trait 对象可以理解为类似其它面向对象语言中,指向接口或基类的指针或引用。其它OO语言指向基类的指针在运行时确定其实际类型。Rust 没有类继承,指向 trait 的指针或引用起到类似的效果,运行时被确定具体类型。所以编译期间不知道大小。
Rust 的 Trait 不能有非静态数据成员,所以 Trait 本身就不会出现引用成员的生命周期小于对象自身,所以 Trait 对象默认的生命周期是静态生命周期。我们看下面三个函数:
fn check0() -> &'static Foo { // 如果不指定 'static , 编译器会报错,要求指定生命周期命参数, 并建议 'static
const b:Bar = Bar{v:0};
&b
}
fn check1<'a>() -> &'a Foo { //如果不指定 'a , 编译器会报错
const b:Bar = Bar{v:0};
&b
}
fn check2(foo:&Foo) -> &Foo {//生命周期参数被省略,不要求静态生命周期
foo
}
fn check3(foo:&'static Foo) -> &'static Foo {
foo
}
fn main(){
let bar= Bar{v:0};
check2(&bar); //能编译通过,说明 chenk2 的输入输出参数都不是静态生命周期
//check3(&bar); //编译错误:bar的生命周期不够长
const bar_c:Bar =Bar{v:0};
check3(&bar_c); // check3 只能接收静态参数
}
check0 和 check1 说明将 Trait 对象的引用作为 函数参数返回时,跟返回其他引用类型一样,都需要指定生命周期参数。函数 check2 的生命周期参数只是被省略了(编译器可以推断),但这个函数里的 Trait 对象并不是静态生命周期,这可以从 main 函数内能成功执行 check2(bar) 分析出来,因为 bar 不是静态生命周期.
实际上在运行时,Trait 对象总会动态绑定到一个实现了该 Trait 的具体结构体类型(如 Bar,Qux,Baz 等),这个具体类型的在其上下文中有它的生命周期,可以是静态的,更多情况下是非静态生命周期 'a ,那么 Trait 对象的生命周期也是 'a.
| 结构体或成员生命周期 | Trait 对象生命周期 | |
|---|---|---|
| Foo | 无 | 'static |
| Bar | 'a | 'a |
| Qux<'a>{m:&'a str} | 'a | 'a |
| Baz<'a,T>{v:&'a T} | 'a | 'a |
fn qux_update<'a>(qux: &'a mut Qux<'a>, new_value: &'a i32)->&'a Foo {
qux.v = new_value;
qux
}
let value = 100;
let mut qux = Qux{v: &value};
let new_value = 101;
let muted: &dyn Foo = qux_update(& mut qux, &new_value);
qux_update 函数的智能指针版本如下:
fn qux_box<'a>(new_value: &'a i32) -> Box<Foo +'a> {
Box::new(Qux{v:new_value})
}
let new_value = 101;
let boxed_qux:Box<dyn Foo> = qux_box(&new_value);
返回的智能指针中,Box 装箱的类型包含了引用成员,也需要给被装箱的数据指定生命周期,语法形式是在被装箱的类型位置增加生命周期参数,用 "+" 号连接。
这两个版本的代码其实都说明一个问题,就是 Trait 虽然默认是静态生命周期,但实际上,其生命周期是由具体实现这个 Trait 的结构体的生命周期决定,推断方式跟之前叙述的函数参数生命周期并无太大区别。
7.智能指针的所有权与生命周期
如图 6,在 Rust 中引用和智能指针都算是“指针”的一种形态,所以他们都可以实现 std::borrow::Borrow Trait。一般情况下,我们对栈中的变量获取引用,栈中的变量存续时间一般比较短,当前的作用域退出时,作用域范围内的栈变量就会被回收。如果我们希望变量的生命周期能跨越当前的作用域,甚至在线程之间传递,最好是把变量绑定的数据区域创建在堆上。
栈上的变量其作用域在编译期间就是明确的,所以编译器能够确定栈上的变量何时会被释放,结合生命周期参数生命,编译器能找到绝大部分对栈上变量的错误引用。
堆上变量其的内存管理比栈变量要复杂很多。在堆上分配一块内存之后,编译器无法根据作用域来判断这块内存的存活时间,必须由使用者显式指定。C 语言中就是对于每一块通过 malloc 分配到的内存,需要显式的使用 free 进行释放。C++中是 new / delete。但是什么时候调用 free 或 delete 就是一个难题。尤其当代码复杂,分配内存的代码和释放内存的代码不在同一个代码文件,甚至不在同一个线程的时候,仅仅靠人工跟踪代码的逻辑关系来维护分配与释放就难免出错。
智能指针的核心思想是让系统自动帮我们决定回收内存的时机。其主要手段就是“将内存分配在堆上,但指向该内存的指针变量本身是在栈上,这样编译器就可以捕捉指针变量离开作用域的时机。在这时决定内存回收动作,如果该指针变量拥有内存区的所有权就释放内存,如果是一个引用计数指针就减少计数值,计数为 0 就回收内存”。
Rust 的 Box<T> 为独占所有权指针,Rc<T>为引用计数指针,但其计数过程不是线程安全的,Arc<T>提供了线程安全的引用计数动作,可以跨线程使用。
我们看 Box<T> 的定义
pub struct Box<T: ?Sized>(Unique<T>);
pub struct Unique<T: ?Sized>{
pointer: *const T,
_marker: PhantomData<T>,
}
Box 本身是一个元组结构体,包装了一个 Unique<T>, Unique<T>内部有一个原生指针。
(注:Rust 最新版本的 Box
Box 没有实现 Copy Trait,它在所有权转移时会执行移动语意。
示例代码:
Struct Foo {v:i32}
fn inc(v:& mut Foo) -> &Foo {//省略了生命周期参数
v.v = v.v + 1;
v
}
//返回Box指针不需要生命周期参数,因为Box指针拥有了所有权,不会成为悬垂指针
fn inc_ptr(mut foo_ptr:Box<Foo>) -> Box<Foo> {//输入参数和返回参数各经历一次所有权转移
foo_ptr.v = foo_ptr.v + 1;
println!("ininc_ptr:{:p}-{:p}", &foo_ptr, &*foo_ptr);
foo_ptr
}
fn main() {
let foo_ptr1 = Box::new(Foo{v:10});
println!("foo_ptr1:{:p}-{:p}", &foo_ptr1, &*foo_ptr1);
let mut foo_ptr2 = inc_ptr(foo_ptr1);
//println!("{}",foo_ptr1.v);//编译错误,f0_ptr所有权已经丢失
println!("foo_ptr2:{:p}-{:p}", &foo_ptr2, &*foo_ptr2);
inc(foo_ptr2.borrow_mut());//获得指针内数据的引用,调用引用版本的inc函数
println!("{}",foo_ptr2.v);
}
inc 为引用版本,inc_ptr 是指针版本。改代码的输出为:
foo_ptr1:0x8dfad0-0x93a5e0
in inc_ptr:0x8df960-0x93a5e0
foo_ptr2:0x8dfb60-0x93a5e0
12
可以看到 foo_ptr1 进入函数 inc_ptr 时,执行了一次所有权转移,函数返回时又执行了一次。所以三个 Box<Foo> 的变量地址都不一样,但是它们内部的数据地址都是一样的,指向同一个内存区。
Box 类型自身是没有引用成员的,但是如果 T 包含引用成员,那么其相关的生命周期问题会是怎样的?
我们把 Foo 的成员改成引用成员试试,代码如下:
use std::borrow::BorrowMut;
struct Foo<'a>{v:&'a mut i32}
fn inc<'a>(foo:&'a mut Foo<'a>) ->&'a Foo<'a> {//生命周期不能省略
*foo.v=*foo.v + 1; // 解引用后执行加法操作
foo
}
fn inc_ptr(mut foo_ptr:Box<Foo>) -> Box<Foo> {//输入参数和返回参数各经历一次所有权转移
*foo_ptr.v = *foo_ptr.v + 1; / 解引用后执行加法操作
println!("ininc_ptr:{:p}-{:p}", &foo_ptr, &*foo_ptr);
foo_ptr
}
fn main(){
let mut value = 10;
let foo_ptr1 = Box::new(Foo{v:& mut value});
println!("foo_ptr1:{:p}-{:p}", &foo_ptr1, &*foo_ptr1);
let mut foo_ptr2 = inc_ptr(foo_ptr1);
//println!("{}",foo_ptr1.v);//编译错误,f0_ptr所有权已经丢失
println!("foo_ptr2:{:p}-{:p}", &foo_ptr2, &*foo_ptr2);
let foo_ref = inc(foo_ptr2.borrow_mut());//获得指针内数据的引用,调用引用版本的inc函数
//println!("{}",foo_ptr2.v);//编译错误,无法获取foo_ptr2.v的不可变借用,因为已经存在可变借用
println!("{}", foo_ref.v);
}
引用版本的 inc 函数生命周期不能再省略了。因为返回 Foo 的引用时,有两个生命周期值,一个是Foo 实例的生命周期,一个是 Foo 中引用成员的生命周期,编译器无法做推断,需要指定。但是智能指针版本 inc_ptr 函数的生命周期依然不用指定。Foo 的实例被智能指针包装,生命周期由 Box 负责管理。
如果 Foo 是一个 Trait ,而实现它的结构体有引用成员,那么 Box<Foo> 的生命周期会有什么情况。示例代码如下:
trait Foo{
fn inc(&mut self);
fn value(&self)->i32;
}
struct Bar<'a>{v:&'a mut i32}
impl<'a> Foo for Bar<'a> {
fn inc(&mut self){
*(self.v)=*(self.v)+1
}
fn value(&self)->i32{
*self.v
}
}
fn inc(foo:& mut dyn Foo)->& dyn Foo {//生命周期参数被省略
foo.inc();
foo
}
fn inc_ptr(mut foo_ptr:Box<dyn Foo>) -> Box< dyn Foo> {//输入参数和返回参数各经历一次所有权转移
foo_ptr.inc();
foo_ptr
}
fn main() {
}
引用版本和智能指针版本都没生命周期参数,可以编译通过。不过 main 函数里是空的,也就是没有使用这些函数,只是定义编译通过了。我先试试使用引用版本:
fn main(){
let mut value = 10;
let mut foo1= Bar{v:& mut value};
let foo2 =inc(&mut foo1);
println!("{}", foo2.value()); // 输出 11
}
可以编译通过并正常输出。再试智能指针版本:
fn main(){
let mut value = 10;
let foo_ptr1 = Box::new(Bar{v:&mut value}); //编译错误:value生命周期太短
let mut foo_ptr2 = inc_ptr(foo_ptr1); //编译器提示:类型转换需要value为静态生命周期
}
编译失败。提示的错误信息是 value 的生命周期太短,需要为 'static 。因为 Trait 对象( Box< dyn Foo>)默认是静态生命周期,编译器推断出返回数据的生命周期太短。去掉最后一行 inc_ptr 是可以正常编译的。
如果将 inc_ptr 的定义加上生命周期参数上述代码就可以编译通过。修改后的 inc_ptr 如下:
fn inc_ptr<'a>(mut foo_ptr:Box<dyn Foo+'a>) -> Box<dyn Foo+'a> {
foo_ptr.inc();
foo_ptr
}
为什么指针版本不加生命周期参数会出错,而引用版没有生命周期参数却没有问题?
因为引用版是省略了生命周期参数,完整写法是:
fn inc<'a>(foo:&'a mut dyn Foo)->&'a dyn Foo {
foo.inc();
foo
}
8. 闭包与所有权
这里不介绍闭包的使用,只说与所有权相关的内容。闭包与普通函数相比,除了输入参数,还可以捕获上线文中的变量。闭包还支持一个 move 关键字,来强制转移捕获变量的所有权。
我们先来看 move 对输入参数有没有影响:
//结构 Value 没有实现Copy Trait
struct Value{x:i32}
//没有作为引用传递参数,所有权被转移
let mut v = Value{x:0};
let fun = |p:Value| println!("in closure:{}", p.x);
fun(v);
//println!("callafterclosure:{}",point.x);//编译错误:所有权已经丢失
//作为闭包的可变借用入参,闭包定义没有move,所有权没有转移
let mut v = Value{x:0};
let fun = |p:&mut Value| println!("in closure:{}", p.x);
fun(& mut v);
println!("call after closure:{}", v.x);
//可变借用作为闭包的输入参数,闭包定义增加move,所有权没有转移
let mut v = Value{x:0};
let fun = move |p:& mut Value| println!("in closure:{}", p.x);
fun(& mut v);
println!("call after closure:{}", v.x);
可以看出,变量作为输入参数传递给闭包时,所有权转移规则跟普通函数是一样的,move 关键字对闭包输入参数的引用形式不起作用,输入参数的所有权没有转移。
对于闭包捕获的上下文变量,所有权是否转移就稍微复杂一些。
下表列出了 10 多个例子,每个例子跟它前后的例子都略有不同,分析这些差别,我们能得到更清晰的结论。
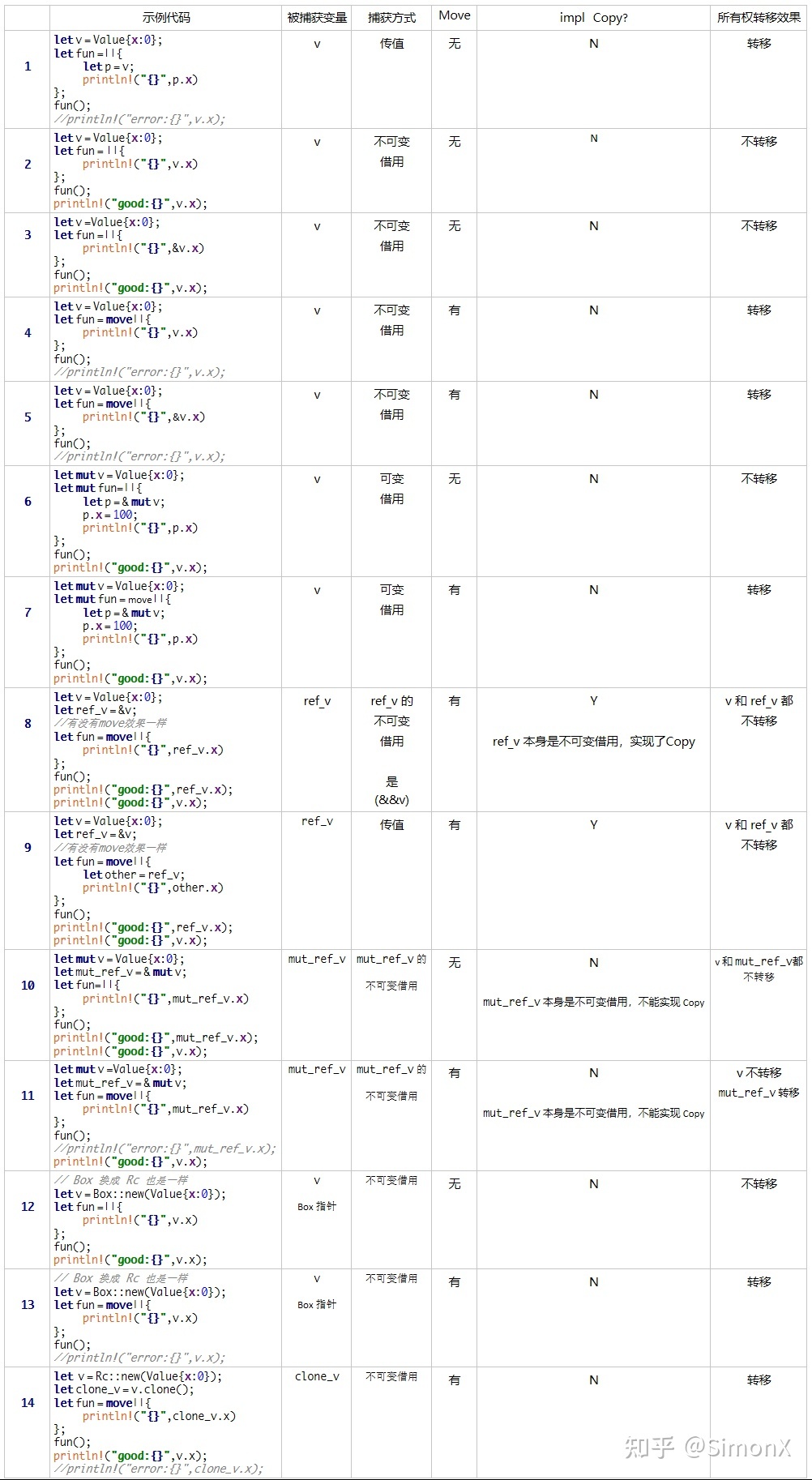
首先要明确被捕获的变量是哪个,这很重要。比如例 8 中,ref_v 是 v 的不可变借用,闭包捕获的是 ref_v ,那么所有权转移的事情跟 v 没有关系,v 不会发生与闭包相关的所有权转移事件。
明确了被捕获的变量后,是否转移所有权受三个因素联合影响:
- 变量被捕获的方式(值,不可变借用,可变借用)
- 闭包是否有 move 限定
- 被捕获变量的类型是否实现了 "Copy" Trait
是用伪代码描述是否转移所有权的规则如下:
if 捕获方式 == 值传递 {
if 被捕获变量的类型实现了 "Copy"
不转移所有权 // 例 :9
else
转移所有权 // 例 :1
}
}
else { // 捕获方式是借用
if 闭包没有 move 限定
不转移所有权 // 例:2,3,6,10,12
else { // 有 move
if 被捕获变量的类型实现了 "Copy"
不转移所有权 // 例: 8
else
转移所有权 // 例: 4,5,7,11,13,14
}
}
先判断捕获方式,如果是值传递,相当于变量跨域了作用域,触发转移所有权的时机。move 是对借用捕获起作用,要求对借用捕获也触发所有权转移。是否实现 "Copy" 是最后一步判断。 前文提到,我们可以把 Copy Trait 限定的位拷贝语义当成一种转移执行的方式。Copy Trait 不参与转移时机的判定,只在最后转移执行的时候起作用。
- 例 1 和(例 2、例 3) 的区别在于捕获方式不同。
- (例 2、例 3) 和例 4 的区别在于 move 关键字。
- 例 6 和例 7 的区别 演示了 move 关键字对借用方式捕获的影响。
- 例 8 说明了捕获不可变借用变量,无论如何都不会转移,因为不可变借用实现了 Copy.
- 例 8 和例 11 的区别就在于例 11 捕获的 "不可变借用"没有实现 "Copy" Trait 。
- 例 10 和例 11 是以“不可变借用的方式”捕获了一个“可变借用变量”
- 例 12,13,14 演示了对智能指针的效果,判断逻辑也是一致的。
C++11 的闭包需要在闭包声明中显式指定是按值还是按引用捕获,Rust 不一样。Rust 闭包如何捕获上下文变量,不取决与闭包的声明,取决于闭包内部如何使用被捕获的变量。实际上编译器会尽可能以借用的方式去捕获变量(例,除非实在不行,如例 1.)
这里刻意没有提及闭包背后的实现机制,即 Fn,FnMut,FnOnce 三个 Trait。因为我们只用闭包语法时是看不到编译器对闭包的具体实现的。所以我们仅从闭包语法本身去判断所有权转移的规则。
9.多线程环境下的所有权问题
我们把前面的例 1 再改一下,上下文与闭包的实现都没有变化,但是闭包在另一个线程中执行。
let v = Value{x:1};
let child = thread::spawn(||{ // 编译器报错,要求添加 move 关键字
let p = v;
println!("inclosure:{}",p.x)
});
child.join();
这时,编译器报错,要求给闭包增加 move 关键字。也就是说,闭包作为线程的入口函数时,强制要求对被捕获的上下文变量执行移动语义。下面我们看看多线程环境下的所有权系统。
前面的讨论都不涉及变量在跨线程间的共享,一旦多个线程可以访问同一个变量时,情况又复杂了一些。这里有两个问题,一个仍然是内存安全问题,即“悬垂指针”等 5 个典型的内存安全问题,另一个是线程的执行顺序导致执行结果不可预测的问题。这里我们只关注内存安全问题。
首先,多个线程如何共享变量?前面的例子演示了启动新线程时,通过闭包捕获上下文中的变量来实现多个线程共享变量。这是一个典型的形式,我们以这个形式为基础来阐述多线程环境下的所有权问题。
我们来看例子代码:
//结构 Value 没有实现Copy Trait
struct Value{x:i32}
let v = Value{x:1};
let child = thread::spawn(move||{
let p = v;
println!("in closure:{}",p.x)
});
child.join();
//println!("{}",v.x);//编译错误:所有权已经丢失
这是前面例子的正确实现,变量 v 被传递到另一个线程(闭包内),执行了所有权转移
//闭包捕获的是一个引用变量,无论如何也拿不到所有权。那么多线程环境下所有引用都可以这么传递吗?
let v = Value{x:0};
let ref_v = &v;
let fun = move ||{
let p = ref_v;
println!("inclosure:{}",p.x)
};
fun();
println!("callafterclosure:{}",v.x);//编译执行成功
这个例子中,闭包捕获的是一个变量的引用,Rust 的引用都是实现了 Copy Trait,会被按位拷贝到闭包内的变量 p.p 只是不可变借用,没有获得所有权,但是变量 v 的不可变借用在闭包内外进行了传递。那么把它改成多线程方式会如何呢?这是多线程下的实现和编译器给出的错误提示:
let v:Value = Value{x:1};
let ref_v = &v; // 编译错误:被借用的值 v0 生命周期不够长
let child = thread::spawn(move||{
let p = ref_v;
println!("in closure:{}",p.x)
}); // 编译器提示:参数要求 v0 被借用时为 'static 生命周期
child.join();
编译器的核心意思就是 v 的生命周期不够长。当 v 的不可变借用被传递到闭包中,并在另一个线程中使用时,主线程继续执行, v 随时可能超出作用域范围被回收,那么子线程中的引用变量就变成了悬垂指针。 如果 v 为静态生命周期,这段代码就可以正常编译执行。即把第一行改为:
const v:Value = Value{x:1};
当然只能传递静态生命周期的引用实际用途有限,多数情况下我们还是希望能把非静态的数据传递给另一个线程。可以采用 Arc<T>来包装数据。 Arc<T> 是引用计数的智能指针,指针计数的增减操作是线程安全的原子操作,保证计数的变化是线程安全的。
//线程安全的引用计数智能指针Arc可以在线程间传递
let v1 = Arc::new(Value{x:1});
let arc_v = v1.clone();
let child = thread::spawn(move||{
let p = arc_v;
println!("Arc<Value>in closure:{}",p.x)
});
child.join();
//println!("Arc<Value>inclosure:{}",arc_v.x);//编译错误,指针变量的所有权丢失
如果把上面的 Arc<T> 换成 Rc<T> ,编译器会报告错误,说"Rc<T> 不能在线程间安全的传递"。
通过上面的例子我们可以总结出来一点,因为闭包定义中的 move 关键字,以闭包启动新线程时,被闭包捕获的变量本身的所有权必然会发生转移。无论捕获的变量是 "值变量"还是引用变量或智能指针(上述例子中 v,ref_v,arc_v 本身的所有权被转移)。但是对于引用或指针,它们所指代的数据的所有权并不一定被转移。
那么对于上面的类型 struct Value{x:i32}, 它的值可以在多个线程间传递(转移所有权),它的多个不可变借用可以在多个线程间同时存在。同时 &Value 和 Arc<Value> 可以在多个线程间传递(转移引用变量或指针变量自身的所有权),但是 Rc<T> 不行。
要知道,Rc<T> 和 Arc<T> 只是 Rust 标准库(std)实现的,甚至不在核心库(core)里。也就是说,它们并不是 Rust 语言机制的一部分。那么,编译器是如何来判断 Arc
Rust 核心库 的 marker.rs 文件中定义了两个标签 Trait:
pub unsafe auto trait Sync{}
pub unsafe auto trait Send{}
标签 Trait 的实现是空的,但编译器会分析某个类型是否实现了这个标签 Trait.
- 如果一个类型
T实现了“Sync”,其含义是T可以安全的通过引用可以在多个线程间被共享。 - 如果一个类型
T实现了“Send”,其含义是T可以安全的跨线程边界被传递。
那么上面的例子中的类型,Value ,&Value,Arc<Value> 类型一定都实现了“Send”Trait. 我们看看如何实现的。
marker.rs 文件还定义了两条规则:
unsafe impl<T:Sync + ?Sized> Send for &T{}
unsafe impl<T:Send + ?Sized> Send for & mut T{}
其含义分别是:
- 如果类型 T 实现了“Sync”,则自动为类型
&T实现“Send”. - 如果类型 T 实现了“Send”,则自动为类型
&mut T实现“Send”.
这两条规则都可以直观的理解。比如:对第一条规则 T 实现了 “Sync”, 意味则可以在很多个线程中出现同一个 T 实例的 &T 类型实例。如果线程 A 中先有 &T 实例,线程 B 中怎么得到 &T 的实例呢?必须要有在线程 A 中通过某种方式 send 过来,比如闭包的捕获上下文变量。而且 &T 实现了 "Copy" Trait, 不会有所有权风险,数据是只读的不会有数据竞争风险,非常安全。逻辑上也是正确的。那为什么还会别标记为 unsafe ? 我们先把这个问题暂时搁置,来看看为智能指针设计的另外几条规则。
impl <T:?Sized>!marker::Send for Rc<T>{}
impl <T:?Sized>!marker::Sync for Rc<T>{}
impl<T:?Sized>!marker::Send for Weak<T>{}
impl<T:?Sized>!marker::Sync for Weak<T>{}
unsafe impl<T:?Sized+Sync+Send>Send for Arc<T>{}
unsafe impl<T:?Sized+Sync+Send>Sync for Arc<T>{}
这几条规则明确指定 Rc<T> 和 Weak<T> 不能实现 “Sync”和 “Send”。
同时规定如果类型 T 实现了 “Sync”和 “Send”,则自动为 Arc<T> 实现 “Sync”和 “Send”。Arc<T> 对引用计数增减是原子操作,所以它的克隆体可以在多个线程中使用(即可以为 Arc<T> 实现”Sync”和“Send”),但为什么其前提条件是要求 T 也要实现"Sync”和 “Send”呢。
我们知道,Arc<T>实现了 std::borrow,可以通过 Arc<T>获取 &T 的实例,多个线程中的 Arc<T> 实例当然也可以获取到多个线程中的 &T 实例,这就要求 T 必须实现“Sync”。Arc<T> 是引用计数的智能指针,任何一个线程中的 Arc<T>的克隆体都有可能成为最后一个克隆体,要负责内存的释放,必须获得被 Arc<T>指针包装的 T 实例的所有权,这就要求 T 必须能跨线程传递,必须实现 “Send”。
Rust 编译器并没有为 Rc<T>或 Arc<T> 做特殊处理,甚至在语言级并不知道它们的存在,编译器本身只是根据类型是否实现了 “Sync”和 “Send”标签来进行推理。实际上可以认为编译器实现了一个检查变量跨线程传递安全性的规则引擎,编译器为基本类型直接实现 “Sync”和 “Send”,这作为“公理”存在,然后在标准库代码中增加一些“定理”,也就是上面列举的那些规则。用户自己实现的类型可以自己指定是否实现 “Sync”和 “Send”,多数情况下编译器会根据情况默认选择是否实现。代码编译时编译器就可以根据这些公理和规则进行推理。这就是 Rust 编译器支持跨线程所有权安全的秘密。
对于规则引擎而言,"公理"和"定理"是不言而喻无需证明的,由设计者自己声明,设计者自己保证其安全性,编译器只保证只要定理和公理没错误,它的推理也没错误。所以的"公理"和"定理"都标注为 unsafe,提醒声明着检查其安全性,用户也可以定义自己的"定理",有自己保证安全。反而否定类规则 (实现 !Send 或 !Sync)不用标注为 unsafe , 因为它们直接拒绝了变量跨线程传递,没有安全问题。
当编译器确定 “Sync”和 “Send”适合某个类型时,会自动为其实现此。
比如编译器默认为以下类型实现了 Sync :
- [u8] 和 [f64] 这样的基本类型都是 [Sync],
- 包含它们的简单聚合类型(如元组、结构和名号)也是[Sync] 。
- "不可变" 类型(如 &T)
- 具有简单继承可变性的类型,如 Box
、Vec - 大多数其他集合类型(如果泛型参数是 [Sync],其容器就是 [Sync]。
用户也可以手动使用 unsafe 的方式直接指定。
下图是与跨线程所有权相关的概念和类型的 UML 图。
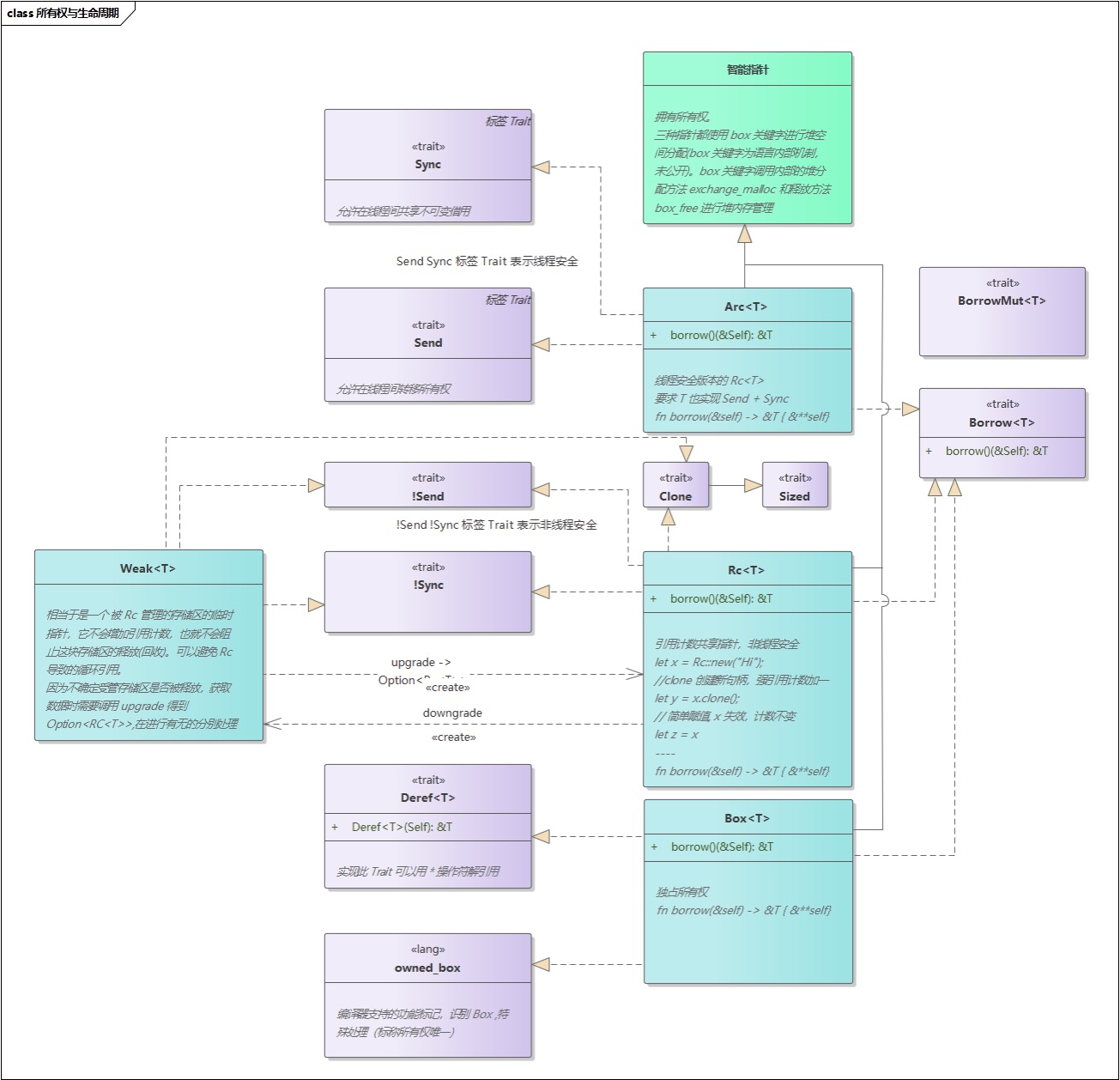
Rust 异步执行器
作为从事大量并发工作(尤其是在 Fanout 的网络工作)的老牌 C/C++ 程序员,Rust 编程语言及其最近的异步功能引起了我的兴趣 (intrigued)。
像 C/C++ 一样,Rust 没有运行时。有趣的是,即使引入了异步也同样如此。使用async和await关键字可以并发的运行代码。你需要使用自己的运行时(如:Tokio 或 async-std) 与语言的核心元素进行交互。
但是,你也可以实现自己的运行时!在过去的几个月中,我一直在学习所有的实现细节。在本文中,我将描述如何仅使用标准库来执行 Rust 的异步函数。
关于 异步以及 future 其他文章已经写了很多,因此本文主要关注于如何构建执行程序。
语言 vs 运行时
Rust 提供了一下几种基本特性:
- Future 特征:允许逐步执行某项操作。
async关键字:重写你的代码以实现Future。await关键字:允许在生成的异步代码中使用其他的Future实例。
就是这样。值得注意的是,Rust 在你使用async关键字生成Future之外并没有提供Future的具体实现。
为了使用 Rust 的异步特性做一些有用的事情,你将需要一些Future实现(仅使用生成的Future是没有意义的),以及一种执行Future实例的方法。
我个人认为这是一个出色的设计。Rust 能够提供相当不错的异步语法,而不用提交给特定的运行时。
请注意,尽管听起来好像语言本身没有提供太多的功能,但是其内置的异步代码生成却是一个具有挑战性的问题。
实现一个 Future
下面是对Future特征的定义:
#![allow(unused)] fn main() { pub trait Future { type Output; fn poll(self: Pin<&mut Self>, cx: &mut Context) -> Poll<Self::Output>; } }
你可以手动实现一个Future。举个例子:下面这个 Future 可以产生一个整数:
#![allow(unused)] fn main() { use std::future::Future; use std::task::{Context, Poll}; struct IntFuture { x: i32, } impl Future for IntFuture { type Output = i32; fn poll(self: Pin<&mut Self>, cx: &mut Context) -> Poll<i32> { Poll::Ready(self.x) } } }
或者你可以通过async关键字来构建具有同样功能的代码:
#![allow(unused)] fn main() { async fn int_future(x: i32) -> i32 { x } }
在以上两种情况下,我们最终都具有满足Future<Output = i32>的类型:
fn eat<F: Future<Output = i32>>(_: F) {} fn main() { eat(IntFuture { x: 42 }); eat(int_future(42)); }
嵌入的 future
如果你有一个异步函数的调用链,举个例子:一个 HTTP 请求的异步函数调用 TCP I/O 的异步函数,它将被编译为单个封装的Future。对这个 future 进行轮询将导致对其内部的 future 进行轮询。进行轮询的任何操作都不会对内部 future 有任何感知。
举个例子:
#![allow(unused)] fn main() { async fn get_audience() -> &'static str { "world" } async fn make_greeting() -> String { let audience = get_audience().await; format!("hello {}", audience) } }
在上面的代码中,如果调用make_greeting()来获取一个 future,轮询这个 future 将会依次轮询由get_audience()生成的 future,但这可以视为make_greeting()的实现细节。
所有这一切都说明:在执行 future 时,我们实际上只需要考虑最顶层的 future 即可。
调用 poll
创建一个Future有点简单。轮询 future,也没有太多内容。我们再来看一下poll()的签名:
#![allow(unused)] fn main() { fn poll(self: Pin<&mut Self>, cx: &mut Context) -> Poll<Self::Output>; }
我们需要一个Pin和一个Context。你可能要问,这些到底是什么?
Pin
Pin是一种表示某些内存不会被移动的方式。通常,可以将结构从一个内存位置移动到另一个内存位置,而不会出现任何问题。这是因为 Rust 禁止在safe代码中进行自引用。举个例子,一个结构可以存储在栈上,然后被移动到堆上的Box中,并且 Rust 可以通过简单的复制字节来执行移动操作。然而,Rust 异步最伟大的成就之一就是可以在 await 点之间进行借用,这需要稍微调整规则。异步生成的 future 需要具有在使用 await 时保留对其内部内存引用的能力,因此需要确保其内存不会在poll()调用之间移动。
这里使用Pin的方式有点不直观。poll()函数消耗Pin。这意味着为了轮询一个 future,每次轮询的时候你都需要实例化一个新的Pin。看起来像这样:
#![allow(unused)] fn main() { let mut f = IntFuture { x: 42 }; let mut cx = ... // we'll talk about this later let p = unsafe { Pin::new_unchecked(&mut f) }; match p.poll(&mut cx) { Poll::Ready(x) => println!("got int: {}", x), Poll::Pending => println!("future not ready"), } }
(请注意:有趣的是Pin可以被用作self类型。看起来 Rust 虽然将self限制为T,&T以及&mut T,还允许使用固定列表中的其他类型)。
一旦通过poll()方法消耗并消毁了Pin,你是否就不打算保留固定的内存了?没有!对文档的质疑,“这个值一旦固定,就必须永远固定”。事实上,这就是为什么构建Pin是 unsafe 的原因。unsafe 的部分是你最终会丢失Pin,但是尽管没有Pin保护你了,你仍然需要坚持固定 (pinning) 合约。
Context 和 Waker
当前,Context唯一要做的就是提供对Waker的访问。Waker用于指示如果poll()返回了Poll::Pending,则应在何时再次轮询 future。poll()采用Context而不是简单的Waker是为了实现扩展。在更高版本的 Rust 中,其他内容可能会添加到Context上。
构建Context需要一些努力。它唯一 (sole) 的构造函数Context::from_waker 需要一个Waker。Waker 唯一的构造函数 Waker::from_raw 需要一个RawWaker。并且RawWaker唯一的构造函数 RawWaker::new 需要一个RawWakerVTable。
让我们实现一个迷你版,不带任何操作的RawWakerVTable:
#![allow(unused)] fn main() { use std::task::{RawWaker, RawWakerVTable}; unsafe fn vt_clone(data: *const ()) -> RawWaker { RawWaker::new(data, &VTABLE) } unsafe fn vt_wake(_data: *const ()) { } unsafe fn vt_wake_by_ref(_data: *const ()) { } unsafe fn vt_drop(_data: *const ()) { } static VTABLE: RawWakerVTable = RawWakerVTable::new( vt_clone, vt_wake, vt_wake_by_ref, vt_drop ); }
然后我们可以像这样构建一个Waker:
#![allow(unused)] fn main() { let rw = RawWaker::new(&(), &VTABLE); let w = unsafe { Waker::from_raw(rw) }; }
所有的这些 vtable 都是为了允许我们提供自己的唤醒行为。RawWaker 只是一个数据指针和一个 vtable。Waker对此进行了封装,并实现了熟悉的 Rust 特征,如Clone和Drop。Waker构造函数是 unsafe 的,因此 vtable 函数可能需要对原始指针进行解引用。
你可能想知道为什么 Rust 使用此自定义的 vtable 而不是使Waker成为特征。我相信这样做是为了使Waker可以被拥有,同时避免了堆分配。使用特征可能需要在某处添加Box。
最后,我们可以构建一个Context:
#![allow(unused)] fn main() { let mut cx = Context::from_waker(&w); }
当然,在真实的应用中我们需要Waker做些什么。我们将在后面讨论这个问题。
这次是真的调用 poll() 了
既然我们知道如何构建一个Pin和一个Context,我们可以调用poll()了。以下是轮询一个 future 程序的完整源代码:
use std::future::Future; use std::pin::Pin; use std::task::{Poll, Context, Waker, RawWaker, RawWakerVTable}; unsafe fn vt_clone(data: *const ()) -> RawWaker { RawWaker::new(data, &VTABLE) } unsafe fn vt_wake(_data: *const ()) { } unsafe fn vt_wake_by_ref(_data: *const ()) { } unsafe fn vt_drop(_data: *const ()) { } static VTABLE: RawWakerVTable = RawWakerVTable::new( vt_clone, vt_wake, vt_wake_by_ref, vt_drop ); async fn get_greeting() -> &'static str { "hello world" } fn main() { let mut f = get_greeting(); let rw = RawWaker::new(&(), &VTABLE); let w = unsafe { Waker::from_raw(rw) }; let mut cx = Context::from_waker(&w); let p = unsafe { Pin::new_unchecked(&mut f) }; assert_eq!(p.poll(&mut cx), Poll::Ready("hello world")); }
触发 Waker
让我们来创建一个知道如何唤醒自己的 future。
以下是计时器的实现。可以以期望的持续时间构建它。第一次轮询时,它会产生一个线程并返回Poll::Pending。下次轮询时,它将返回Poll::Ready。线程休眠然后调用wake()。
#![allow(unused)] fn main() { use std::time; use std::thread; use std::future::Future; use std::pin::Pin; use std::task::{Context, Poll}; struct TimerFuture { duration: time::Duration, handle: Option<thread::JoinHandle<()>>, } impl TimerFuture { fn new(duration: time::Duration) -> Self { Self { duration, handle: None, } } } impl Future for TimerFuture { type Output = (); fn poll(mut self: Pin<&mut Self>, cx: &mut Context) -> Poll<()> { match &self.handle { None => { let duration = self.duration; let waker = cx.waker().clone(); self.handle = Some(thread::spawn(move || { thread::sleep(duration); waker.wake(); })); Poll::Pending }, Some(_) => { let handle = self.handle.take().unwrap(); handle.join().unwrap(); Poll::Ready(()) }, } } } // convenience wrapper for use in async functions fn sleep(duration: time::Duration) -> TimerFuture { TimerFuture::new(duration) } }
Waker已被克隆,因此我们可以在poll()返回后继续使用它。事实上,我们还可以将其移动到另一个线程。
请注意,在实际的应用程序中,你不希望为每个计时器都生成一个线程。取而代之的是,计时器可能会在某些事件反应堆 (evented reactor) 中注册。不过在此示例中,我们将使其保持简单。
管理不同类型的 future
在我们接触执行器之前,我们需要解决最后一个挑战:改变 future 的类型。
不同的 future 可以有不同的Output类型(如:Future<Output = i32>和Future<Output = String>),因此,poll()也会有不同的返回值。这意味着如果我们要构建一个执行器,我们不能简单的通过将 future 放入类似Vec<Box<dyn Future>>的结构中,即使有可能,我们也无法使用相同的代码对其进行处理。
据我所知,解决方案是为执行器跟踪所有 future 选择一个共同的返回类型(即:顶级 future)。举个例子,你可以决定所有的顶级 future 都没有返回值类型,因此你可以将它们包含在Vec<Box<dyn Future<Output = ()>>>中。请注意,嵌套的 future 仍然可以具有任意的 (arbitrary) 返回值类型。一个不带返回值的异步函数可以等待一个返回String的 future。之所以可行是因为所有的嵌套 future 都隐藏在外部的 future 中,而执行者只关心外部的 future。
我们的类型问题还不止于此。poll()函数需要其具体类型的固定引用。回忆一下前面大写的Self签名。
#![allow(unused)] fn main() { fn poll(self: Pin<&mut Self>, cx: &mut Context) -> Poll<Self::Output>; }
这意味着即使两个不同的 future 实现都具有相同的Output类型并因此具有相同的特征,我们仍然无法使用非通用的代码来处理它们!
可能需要具体的类型,因此Pin可以保护一块已知大小的区域。无论如何,dyn Future都是没有用的。
解决此问题的一种方式是将细节隐藏在闭包中。我们可以使用单态化 (monomorphization) 为每个具体的 future 实现生成不同的代码,但是让闭包共享相同的函数签名。在下面,我们创建符合特征dyn FnMut(&mut Context) -> Poll<()>(对于带有Output = ()的 future) 的闭包,并将其装箱:
#![allow(unused)] fn main() { type PollFn = dyn FnMut(&mut Context) -> Poll<()>; struct WrappedFuture { poll_fn: Box<PollFn>, } impl WrappedFuture { pub fn new<F>(mut f: F) -> Self where F: Future<Output = ()> + 'static { let c = move |cx: &mut Context| { let p: Pin<&mut F> = unsafe { Pin::new_unchecked(&mut f) }; match p.poll(cx) { Poll::Ready(_) => Poll::Ready(()), Poll::Pending => Poll::Pending, } }; Self { poll_fn: Box::new(c), } } pub fn poll(&mut self, cx: &mut Context) -> Poll<()> { (self.poll_fn)(cx) } } }
使用WrappedFuture,我们可以对所有 future 一视同仁:
// generates Future<Output = ()> async fn print_hello() { println!("hello"); } // generates Future<Output = ()> async fn print_goodbye() { println!("goodbye"); } fn main() { let mut futures: Vec<WrappedFuture> = Vec::new(); futures.push(WrappedFuture::new(print_hello())); futures.push(WrappedFuture::new(print_goodbye())); for f in futures.iter_mut() { let mut cx = ... // context assert_eq!(f.poll(&mut cx), Poll::Ready(())); } }
一个简单的执行器
为了执行我们的 future,我们需要做以下三件事:
- 在某处跟踪 future
- 当创建 future 时,对其进行轮询
- 实现
Waker以便我们可以知道何时再次轮询 future
下面是一个基础的执行器。它使用两个向量(need_poll和sleeping)对 future 进行跟踪。调用spawn将一个 future 添加到need_poll中。
与其直接使用WrappedFuture,不如使用Arc/Mutex对其进行封装,以便可以在线程之间共享 future。我们声明一个别名(SharedFuture),以减少噪音。
#![allow(unused)] fn main() { type SharedFuture = Arc<Mutex<WrappedFuture>>; struct ExecutorData { need_poll: Vec<SharedFuture>, sleeping: Vec<SharedFuture>, } struct Executor { data: Arc<(Mutex<ExecutorData>, Condvar)>, } impl Executor { pub fn new() -> Self { let data = ExecutorData { need_poll: Vec::new(), sleeping: Vec::new(), }; Self { data: Arc::new((Mutex::new(data), Condvar::new())), } } pub fn spawn<F>(&self, f: F) where F: Future<Output = ()> + 'static { let (lock, _) = &*self.data; let mut data = lock.lock().unwrap(); data.need_poll.push(Arc::new(Mutex::new(WrappedFuture::new(f)))); } pub fn wake( data: &mut Arc<(Mutex<ExecutorData>, Condvar)>, wf: &SharedFuture ) { let (lock, cond) = &**data; let mut data = lock.lock().unwrap(); let mut pos = None; for (i, f) in data.sleeping.iter().enumerate() { if Arc::ptr_eq(f, wf) { pos = Some(i); break; } } if pos.is_none() { // unknown future return } let pos = pos.unwrap(); let f = data.sleeping.remove(pos); data.need_poll.push(f); cond.notify_one(); } pub fn exec(&self) { loop { let (lock, cond) = &*self.data; let mut data = lock.lock().unwrap(); if data.need_poll.is_empty() { if data.sleeping.is_empty() { // no tasks, we're done break; } data = cond.wait(data).unwrap(); } let need_poll = mem::replace( &mut data.need_poll, Vec::new() ); mem::drop(data); let mut need_sleep = Vec::new(); for f in need_poll { let w = MyWaker { data: Arc::clone(&self.data), f: Arc::new(Mutex::new(Some(Arc::clone(&f)))), }.into_task_waker(); let mut cx = Context::from_waker(&w); let result = { f.lock().unwrap().poll(&mut cx) }; match result { Poll::Ready(_) => {}, Poll::Pending => { need_sleep.push(f); }, } } let mut data = lock.lock().unwrap(); data.sleeping.append(&mut need_sleep); } } } }
exec函数循环并轮询 future。首先,它检查是否有 future 需要被轮询。如果没有,它将会等待一个休眠的 future 被唤醒。一旦有要轮询的 future,便对其进行轮询。如果轮询返回了Ready,表示 future 已经完成,我们可以将其释放。如果轮询返回了Pending,我们将 future 移动到sleeping向量中。如果没有剩余的 future,则循环退出。
为了唤醒一个执行器,需要调用Executor::wake。这是一个关联函数,旨在由MyWaker从另一个线程中调用。
MyWaker代码如下所示:
#![allow(unused)] fn main() { #[derive(Clone)] struct MyWaker { data: Arc<(Mutex<ExecutorData>, Condvar)>, f: Arc<Mutex<Option<SharedFuture>>>, } impl MyWaker { ... fn wake(mut self) { self.wake_by_ref(); } fn wake_by_ref(&mut self) { let f: &mut Option<SharedFuture> = &mut self.f.lock().unwrap(); if f.is_some() { let f: SharedFuture = f.take().unwrap(); Executor::wake(&mut self.data, &f); } } } }
唤醒器的实现旨在一次性使用,但是必须是可克隆的。这就是为什么内部SharedFuture由Option以及Arc/Mutex封装的原因。特定 future 的唤醒器集合可以安全共享单个Option<SharedFuture>的访问权限。在集合中的任何一个唤醒器上调用wake()时,都会唤醒 future,并将选项设置为None。
为了让我们的唤醒器实现可用,我们需要将其集成到 vtable 中,以便可以由Waker对其进行控制:
#![allow(unused)] fn main() { impl MyWaker { ... fn into_task_waker(self) -> Waker { let w = Box::new(self); let rw = RawWaker::new(Box::into_raw(w) as *mut (), &VTABLE); unsafe { Waker::from_raw(rw) } } ... } unsafe fn vt_clone(data: *const ()) -> RawWaker { let w = (data as *const MyWaker).as_ref().unwrap(); let new_w = Box::new(w.clone()); RawWaker::new(Box::into_raw(new_w) as *mut (), &VTABLE) } unsafe fn vt_wake(data: *const ()) { let w = Box::from_raw(data as *mut MyWaker); w.wake(); } unsafe fn vt_wake_by_ref(data: *const ()) { let w = (data as *mut MyWaker).as_mut().unwrap(); w.wake_by_ref(); } unsafe fn vt_drop(data: *const ()) { Box::from_raw(data as *mut MyWaker); } }
基本上,以上 unsafe 代码将 vtable 函数连接到MyWaker的常规 Rust 方法,以处理克隆 (clone) 和销毁 (drop) 操作。
很明显,这不是最复杂的 (sophisticated) 执行器,但它足以作为示例。
使用执行器
让我们来试试看!sleep函数是我们之前定义的TimerFuture的封装。
fn main() { let e = Executor::new(); e.spawn(async { println!("a"); sleep(time::Duration::from_millis(200)).await; println!("c"); }); e.spawn(async { sleep(time::Duration::from_millis(100)).await; println!("b"); sleep(time::Duration::from_millis(200)).await; println!("d"); }); e.exec(); }
以下输出如预期的一样:
#![allow(unused)] fn main() { a b c d }
完整的代码见这里。
Rust 标准库特征指南
原文 / 译者:skanfd
目录
- 引入 Intro
- 特性的基础知识 Trait Basics
- 可自动实现的特性 Auto Traits
- 常用特性 General Traits
- 文本格式化特性 Formatting Traits
- 算符重载特性 Operator Traits
- 转换特性 Conversion Traits
- 错误处理 Error Handling
- 转换特性深入 Conversion Traits Continued
- 迭代特性 Iteration Traits
- 输入输出特性 I/O Traits
- 结语 Conclusion
- 讨论 Discuss
- 通告 Notifications
- 更多资料 Further Reading
- 翻译 Translation
引入 Intro
你是否曾对以下特性的区别感到困惑:
Deref<Target = T>,AsRef<T>和Borrow<T>?Clone,Copy和ToOwned?From<T>和Into<T>?TryFrom<&str>和FromStr?FnOnce,FnMut,Fn和fn?
或者有这样的疑问:
- “我应该在特性中使用关联类型还是泛型类型?”
- "什么是通用泛型实现?"
- "子特性与超特性是如何工作的?"
- "为什么某个特性没有实现任何方法?"
本文正是为你解答以上困惑而撰写!而且本文绝不仅仅只回答了以上问题。下面,我们将一起对 Rust 标准库中所有最流行、最常用的特性做一个走马观花般的概览!
你可以按顺序阅读本文,也可以直接跳读至你最感兴趣的特性。每节都会提供预备知识列表,它会帮助你获得相应的背景知识,不必担心跳读带来的理解困难。
特性的基础知识
本章覆盖了特性的基础知识,相应内容在以后的章节中不再赘述。
特性的记号
特性的记号指的是,在特性的声明中可使用的记号。
Self
Self 永远引用正被实现的类型。
#![allow(unused)] fn main() { trait Trait { // always returns i32 // 总是返回 i32 fn returns_num() -> i32; // returns implementing type // 总是返回正被实现的类型 fn returns_self() -> Self; } struct SomeType; struct OtherType; impl Trait for SomeType { fn returns_num() -> i32 { 5 } // Self == SomeType fn returns_self() -> Self { SomeType } } impl Trait for OtherType { fn returns_num() -> i32 { 6 } // Self == OtherType fn returns_self() -> Self { OtherType } } }
函数
特性的函数指的是,任何不以 self 关键字作为首参数的函数。
#![allow(unused)] fn main() { trait Default { // function // 函数 fn default() -> Self; } }
特性的函数同时声明在特性本身以及具体实现类型的命名空间中。
fn main() { let zero: i32 = Default::default(); let zero = i32::default(); }
方法
特性的方法指的是,任何以 self 关键字作为首参数的函数,其类型是 Self , &Self 或 &mut Self。前者的类型也可以包裹在 Box , Rc , Arc 或 Pin 中。
#![allow(unused)] fn main() { trait Trait { // methods // 方法 fn takes_self(self); fn takes_immut_self(&self); fn takes_mut_self(&mut self); // above methods desugared // 以上代码等价于 fn takes_self(self: Self); fn takes_immut_self(self: &Self); fn takes_mut_self(self: &mut Self); } // example from standard library // 来自于标准库的示例 trait ToString { fn to_string(&self) -> String; } }
可以使用点算符在具体实现类型上调用方法:
fn main() { let five = 5.to_string(); }
并且,与函数相似地,方法也声明在特性本身以及具体实现类型的命名空间中。
fn main() { let five = ToString::to_string(&5); let five = i32::to_string(&5); }
关联类型
特性内部可以声明关联类型。当我们希望在特性函数的签名中使用某种 Self 以外的类型,又不希望硬编码这种类型,而是希望后来的实现该特性的程序员来选择该类型具体是什么的时候,关联类型会很有用。
trait Trait { type AssociatedType; fn func(arg: Self::AssociatedType); } struct SomeType; struct OtherType; // any type implementing Trait can // choose the type of AssociatedType // 我们可以在实现 Trait 特性的时候 // 再决定 AssociatedType 的具体类型 // 而不必是在声明 Trait 特性的时候 impl Trait for SomeType { type AssociatedType = i8; // chooses i8 fn func(arg: Self::AssociatedType) {} } impl Trait for OtherType { type AssociatedType = u8; // chooses u8 fn func(arg: Self::AssociatedType) {} } fn main() { SomeType::func(-1_i8); // can only call func with i8 on SomeType OtherType::func(1_u8); // can only call func with u8 on OtherType // 同一特性实现在不同类型上时,可以具有不同的函数签名 }
泛型参数
“泛型参数” 是泛型类型参数、泛型寿命参数以及泛型常量参数的统称。由于这些术语过于佶屈聱牙,我们通常将他们缩略为“泛型类型”,“泛型寿命”和“泛型常量”。鉴于标准库中的特性无一采用泛型常量,本文也略过不讲。
我们可以使用以下参数来声明特性:
#![allow(unused)] fn main() { // trait declaration generalized with lifetime & type parameters // 使用泛型寿命与泛型类型声明特性 trait Trait<'a, T> { // signature uses generic type // 在签名中使用泛型类型 fn func1(arg: T); // signature uses lifetime // 在签名中使用泛型寿命 fn func2(arg: &'a i32); // signature uses generic type & lifetime // 在签名中同时使用泛型类型与泛型寿命 fn func3(arg: &'a T); } struct SomeType; impl<'a> Trait<'a, i8> for SomeType { fn func1(arg: i8) {} fn func2(arg: &'a i32) {} fn func3(arg: &'a i8) {} } impl<'b> Trait<'b, u8> for SomeType { fn func1(arg: u8) {} fn func2(arg: &'b i32) {} fn func3(arg: &'b u8) {} } }
可以为泛型类型指定默认值,最常用的默认值是 Self ,此外任何其它类型都是可以的。
#![allow(unused)] fn main() { // make T = Self by default // T 的默认值是 Self trait Trait<T = Self> { fn func(t: T) {} } // any type can be used as the default // 任何其它类型都可用作默认值 trait Trait2<T = i32> { fn func2(t: T) {} } struct SomeType; // omitting the generic type will // cause the impl to use the default // value, which is Self here // 省略泛型类型时, impl 块使用默认值,在这里是 Self impl Trait for SomeType { fn func(t: SomeType) {} } // default value here is i32 // 这里的默认值是 i32 impl Trait2 for SomeType { fn func2(t: i32) {} } // the default is overridable as we'd expect // 默认值可以被重写,正如我们希望的那样 impl Trait<String> for SomeType { fn func(t: String) {} } // overridable here too // 这里也可以重写 impl Trait2<String> for SomeType { fn func2(t: String) {} } }
不仅可以为特性提供泛型,也可以独立地为函数或方法提供泛型。
#![allow(unused)] fn main() { trait Trait { fn func<'a, T>(t: &'a T); } }
泛型类型与关联类型
通过使用泛型类型与关联类型,我们都可以将具体类型的选择问题抛给后来实现该特性的程序员来决定,这一节将解释我们如何在相似的两者之间做出选择。
按照惯常的经验:
- 对于某一特性,每个类型仅应当有单一实现时,使用关联类型。
- 对于某一特性,每个类型可以有多个实现时,使用泛型类型。
例如,我们声明一个 Add 特性,它允许将各值加总在一起。这是仅使用关联类型的初始设计:
trait Add { type Rhs; type Output; fn add(self, rhs: Self::Rhs) -> Self::Output; } struct Point { x: i32, y: i32, } impl Add for Point { type Rhs = Point; type Output = Point; fn add(self, rhs: Point) -> Point { Point { x: self.x + rhs.x, y: self.y + rhs.y, } } } fn main() { let p1 = Point { x: 1, y: 1 }; let p2 = Point { x: 2, y: 2 }; let p3 = p1.add(p2); assert_eq!(p3.x, 3); assert_eq!(p3.y, 3); }
例如,我们希望程序允许将 i32 类型的值与 Point 类型的值相加,其规则是该 i32 类型的值分别加到成员 x 与成员 y 。
trait Add { type Rhs; type Output; fn add(self, rhs: Self::Rhs) -> Self::Output; } struct Point { x: i32, y: i32, } impl Add for Point { type Rhs = Point; type Output = Point; fn add(self, rhs: Point) -> Point { Point { x: self.x + rhs.x, y: self.y + rhs.y, } } } impl Add for Point { // ❌ type Rhs = i32; type Output = Point; fn add(self, rhs: i32) -> Point { Point { x: self.x + rhs, y: self.y + rhs, } } } fn main() { let p1 = Point { x: 1, y: 1 }; let p2 = Point { x: 2, y: 2 }; let p3 = p1.add(p2); assert_eq!(p3.x, 3); assert_eq!(p3.y, 3); let p1 = Point { x: 1, y: 1 }; let int2 = 2; let p3 = p1.add(int2); // ❌ assert_eq!(p3.x, 3); assert_eq!(p3.y, 3); }
编译出错:
error[E0119]: conflicting implementations of trait `Add` for type `Point`:
--> src/main.rs:23:1
|
12 | impl Add for Point {
| ------------------ first implementation here
...
23 | impl Add for Point {
| ^^^^^^^^^^^^^^^^^^ conflicting implementation for `Point`
由于 Add 特性未提供泛型类型,因而每个类型只能具有该特性的单一实现,这即是说一旦我们指定了 Rhs 和 Output 的类型后就不可再更改了!为了 Point 类型的值能同时接受 i32 类型和 Point 类型的值作为被加数,我们应当重构之以将 Rhs 从关联类型改为泛型类型,这将允许我们为 Rhs 指定不同的类型并为同一类型多次实现某一特性。
trait Add<Rhs> { type Output; fn add(self, rhs: Rhs) -> Self::Output; } struct Point { x: i32, y: i32, } impl Add<Point> for Point { type Output = Self; fn add(self, rhs: Point) -> Self::Output { Point { x: self.x + rhs.x, y: self.y + rhs.y, } } } impl Add<i32> for Point { // ✅ type Output = Self; fn add(self, rhs: i32) -> Self::Output { Point { x: self.x + rhs, y: self.y + rhs, } } } fn main() { let p1 = Point { x: 1, y: 1 }; let p2 = Point { x: 2, y: 2 }; let p3 = p1.add(p2); assert_eq!(p3.x, 3); assert_eq!(p3.y, 3); let p1 = Point { x: 1, y: 1 }; let int2 = 2; let p3 = p1.add(int2); // ✅ assert_eq!(p3.x, 3); assert_eq!(p3.y, 3); }
例如,我们现在声明一个包含两个 Point 类型的新类型 Line ,要求当两个 Point 类型相加时返回 Line 而不是 Point 。在当前 Add 特性的设计中 Output 是关联类型,不能满足这一要求,重构之以将关联类型改为泛型类型:
trait Add<Rhs, Output> { fn add(self, rhs: Rhs) -> Output; } struct Point { x: i32, y: i32, } impl Add<Point, Point> for Point { fn add(self, rhs: Point) -> Point { Point { x: self.x + rhs.x, y: self.y + rhs.y, } } } impl Add<i32, Point> for Point { fn add(self, rhs: i32) -> Point { Point { x: self.x + rhs, y: self.y + rhs, } } } struct Line { start: Point, end: Point, } impl Add<Point, Line> for Point { // ✅ fn add(self, rhs: Point) -> Line { Line { start: self, end: rhs, } } } fn main() { let p1 = Point { x: 1, y: 1 }; let p2 = Point { x: 2, y: 2 }; let p3: Point = p1.add(p2); assert!(p3.x == 3 && p3.y == 3); let p1 = Point { x: 1, y: 1 }; let int2 = 2; let p3 = p1.add(int2); assert!(p3.x == 3 && p3.y == 3); let p1 = Point { x: 1, y: 1 }; let p2 = Point { x: 2, y: 2 }; let l: Line = p1.add(p2); // ✅ assert!(l.start.x == 1 && l.start.y == 1 && l.end.x == 2 && l.end.y == 2) }
所以说,哪一种 Add 特性最好?答案是具体问题具体分析!不管白猫黑猫,会捉老鼠就是好猫。
作用域
特性仅当被引入当前作用域时才可以使用。绝大多数的初学者要在编写 I/O 程序时经历一番痛苦挣扎后,才能领悟到这一点,原因是 Read 和 Write 两个特性并未包含在标准库的 prelude 模块中。
use std::fs::File; use std::io; fn main() -> Result<(), io::Error> { let mut file = File::open("Cargo.toml")?; let mut buffer = String::new(); file.read_to_string(&mut buffer)?; // ❌ read_to_string not found in File // ❌ 当前文件中找不到 read_to_string Ok(()) }
read_to_string(buf: &mut String) 声明于 std::io::Read 特性,并实现于 std::fs::File 类型,若要调用该函数还须得 std::io::Read 特性处于当前作用域中:
use std::fs::File; use std::io; use std::io::Read; // ✅ fn main() -> Result<(), io::Error> { let mut file = File::open("Cargo.toml")?; let mut buffer = String::new(); file.read_to_string(&mut buffer)?; // ✅ Ok(()) }
诸如 std::prelude::v1 ,prelude 是标准库的一类模块,其特点是该模块命名空间下的成员将被自动导入到任何其它模块的顶部,其作用等效于 use std::prelude::v1::* 。因此,以下 prelude 模块中的特性无需我们显式导入,它们永远存在于当前作用域:
- AsMut
- AsRef
- Clone
- Copy
- Default
- Drop
- Eq
- Fn
- FnMut
- FnOnce
- From
- Into
- ToOwned
- IntoIterator
- Iterator
- PartialEq
- PartialOrd
- Send
- Sized
- Sync
- ToString
- Ord
衍生宏
标准库导出了一系列实用的衍生宏,我们可以利用它们方便快捷地为特定类型实现某种特性,前提是该类型的成员亦实现了相应的特性。衍生宏与它们各自所实现的特性同名:
用例:
#![allow(unused)] fn main() { // macro derives Copy & Clone impl for SomeType // 利用宏的方式为特定类型衍生出 Copy 与 Clone 特性的具体实现 #[derive(Copy, Clone)] struct SomeType; }
注意:衍生宏仅是一种机械的过程,宏展开之后发生的事情并无一定之规。并没有绝对的规定要求衍生宏展开之后必须要为类型实现某种特性,又或者它们必须要求该类型的所有成员都必须实现某种特性才能为当前类型实现该特性,这仅仅是在标准库衍生宏的编纂过程中逐渐约定俗成的规则。
默认实现
特性可为函数与方法提供默认的实现。
trait Trait { fn method(&self) { println!("default impl"); } } struct SomeType; struct OtherType; // use default impl for Trait::method // 省略时使用默认实现 impl Trait for SomeType {} impl Trait for OtherType { // use our own impl for Trait::method // 重写时覆盖默认实现 fn method(&self) { println!("OtherType impl"); } } fn main() { SomeType.method(); // prints "default impl" OtherType.method(); // prints "OtherType impl" }
这对于实现特性中某些仅依赖于其它方法的方法来说极其方便。
trait Greet { fn greet(&self, name: &str) -> String; fn greet_loudly(&self, name: &str) -> String { self.greet(name) + "!" } } struct Hello; struct Hola; impl Greet for Hello { fn greet(&self, name: &str) -> String { format!("Hello {}", name) } // use default impl for greet_loudly // 省略时使用 greet_loudly 的默认实现 } impl Greet for Hola { fn greet(&self, name: &str) -> String { format!("Hola {}", name) } // override default impl // 重写时覆盖 greet_loudly 的默认实现 fn greet_loudly(&self, name: &str) -> String { let mut greeting = self.greet(name); greeting.insert_str(0, "¡"); greeting + "!" } } fn main() { println!("{}", Hello.greet("John")); // prints "Hello John" println!("{}", Hello.greet_loudly("John")); // prints "Hello John!" println!("{}", Hola.greet("John")); // prints "Hola John" println!("{}", Hola.greet_loudly("John")); // prints "¡Hola John!" }
标准库中的许多特性都为它们的方法提供默认实现。
通用泛型实现
通用泛型实现是对泛型类型的实现,与之对应的是对特定类型的实现。我们将以 is_even 方法为例说明如何对数字类型实现通用泛型实现。
#![allow(unused)] fn main() { trait Even { fn is_even(self) -> bool; } impl Even for i8 { fn is_even(self) -> bool { self % 2_i8 == 0_i8 } } impl Even for u8 { fn is_even(self) -> bool { self % 2_u8 == 0_u8 } } impl Even for i16 { fn is_even(self) -> bool { self % 2_i16 == 0_i16 } } // etc #[test] // ✅ fn test_is_even() { assert!(2_i8.is_even()); assert!(4_u8.is_even()); assert!(6_i16.is_even()); // etc } }
显而易见地,我们重复实现了近乎相同的逻辑,这非常的繁琐。进一步来讲,如果 Rust 在将来决定增加更多的数字类型(小概率事件并非绝不可能),那么我们将不得不重新回到这里对新增的数字类型编写代码。通用泛型实现恰可以解决这些问题:
#![allow(unused)] fn main() { use std::fmt::Debug; use std::convert::TryInto; use std::ops::Rem; trait Even { fn is_even(self) -> bool; } // generic blanket impl // 通用泛型实现 impl<T> Even for T where T: Rem<Output = T> + PartialEq<T> + Sized, u8: TryInto<T>, <u8 as TryInto<T>>::Error: Debug, { fn is_even(self) -> bool { // these unwraps will never panic // 以下 unwrap 永远不会 panic self % 2.try_into().unwrap() == 0.try_into().unwrap() } } #[test] // ✅ fn test_is_even() { assert!(2_i8.is_even()); assert!(4_u8.is_even()); assert!(6_i16.is_even()); // etc } }
默认实现可以重写,而通用泛型实现不可重写。
#![allow(unused)] fn main() { use std::fmt::Debug; use std::convert::TryInto; use std::ops::Rem; trait Even { fn is_even(self) -> bool; } impl<T> Even for T where T: Rem<Output = T> + PartialEq<T> + Sized, u8: TryInto<T>, <u8 as TryInto<T>>::Error: Debug, { fn is_even(self) -> bool { self % 2.try_into().unwrap() == 0.try_into().unwrap() } } impl Even for u8 { // ❌ fn is_even(self) -> bool { self % 2_u8 == 0_u8 } } }
编译出错:
error[E0119]: conflicting implementations of trait `Even` for type `u8`:
--> src/lib.rs:22:1
|
10 | / impl<T> Even for T
11 | | where
12 | | T: Rem<Output = T> + PartialEq<T> + Sized,
13 | | u8: TryInto<T>,
... |
19 | | }
20 | | }
| |_- first implementation here
21 |
22 | impl Even for u8 {
| ^^^^^^^^^^^^^^^^ conflicting implementation for `u8`
重叠的实现产生了冲突,于是 Rust 拒绝了该代码以确保特性一致性。特性一致性指的是,对任意给定类型,仅能对某一特性具有单一实现。Rust 强制实现特性一致性,而这一规则的潜在影响与变通方法超出了本文的讨论范围。
子特性与超特性
子特性的“子”即为子集,超特性的“超”即为超集。若有下列特性声明:
#![allow(unused)] fn main() { trait Subtrait: Supertrait {} }
所有实现了子特性的类型都是实现了超特性的类型的子集,也可以说,所有实现了超特性的类型都是实现了子特性的类型的超集。
以上代码等价于:
#![allow(unused)] fn main() { trait Subtrait where Self: Supertrait {} }
这是一种易于忽略但又至关重要的区别 —— 约束是 Self 的约束,而不是 Subtrait 的约束。后者没有任何意义,因为特性约束只能应用于具体类型。不能用一种特性去实现其它特性:
trait Supertrait { fn method(&self) { println!("in supertrait"); } } trait Subtrait: Supertrait { // this looks like it might impl or // override Supertrait::method but it // does not // 这可能会令你产生超特性的方法被覆盖的错觉(实际不会) fn method(&self) { println!("in subtrait") } } struct SomeType; // adds Supertrait::method to SomeType impl Supertrait for SomeType {} // adds Subtrait::method to SomeType impl Subtrait for SomeType {} // both methods exist on SomeType simultaneously // neither overriding or shadowing the other // 两个同名方法同时存在于同一类型时,既不重写也不影射 fn main() { SomeType.method(); // ❌ ambiguous method call // ❌ 不允许语义模糊的函数调用 // must disambiguate using fully-qualified syntax // 必须使用完全限定的记号来明确你要使用的函数 <SomeType as Supertrait>::method(&st); // ✅ prints "in supertrait" <SomeType as Subtrait>::method(&st); // ✅ prints "in subtrait" }
此外,对于特定类型如何同时实现子特性与超特性并没有规定。子、超特性之间的方法也可以相互调用。
trait Supertrait { fn super_method(&mut self); } trait Subtrait: Supertrait { fn sub_method(&mut self); } struct CallSuperFromSub; impl Supertrait for CallSuperFromSub { fn super_method(&mut self) { println!("in super"); } } impl Subtrait for CallSuperFromSub { fn sub_method(&mut self) { println!("in sub"); self.super_method(); } } struct CallSubFromSuper; impl Supertrait for CallSubFromSuper { fn super_method(&mut self) { println!("in super"); self.sub_method(); } } impl Subtrait for CallSubFromSuper { fn sub_method(&mut self) { println!("in sub"); } } struct CallEachOther(bool); impl Supertrait for CallEachOther { fn super_method(&mut self) { println!("in super"); if self.0 { self.0 = false; self.sub_method(); } } } impl Subtrait for CallEachOther { fn sub_method(&mut self) { println!("in sub"); if self.0 { self.0 = false; self.super_method(); } } } fn main() { CallSuperFromSub.super_method(); // prints "in super" CallSuperFromSub.sub_method(); // prints "in sub", "in super" CallSubFromSuper.super_method(); // prints "in super", "in sub" CallSubFromSuper.sub_method(); // prints "in sub" CallEachOther(true).super_method(); // prints "in super", "in sub" CallEachOther(true).sub_method(); // prints "in sub", "in super" }
通过以上示例,希望读者能够领会到,子特性与超特性之间的关系并未被一刀切的限制住。接下来我们将学习一种将所有这些复杂性巧妙地封装在一起的心智模型,在这之前我们先来回顾一下我们用来理解泛型类型与特性约束的关系的心智模型。
#![allow(unused)] fn main() { fn function<T: Clone>(t: T) { // impl } }
即便我们不知道这个函数的具体实现,我们仍旧可以有理有据地猜测 t.clone() 将在函数的某处被调用,因为当泛型类型被特性所约束的时候,会给人一种它依赖于该特性的强烈暗示。这就是一种理解泛型类型与特性约束的关系的心智模型,它简单且可凭直觉 —— 泛型类型依赖于它们的特性约束。
现在,让我们看看 Copy 特性的声明:
#![allow(unused)] fn main() { trait Copy: Clone {} }
以上的记号和之前我们为泛型添加特性约束的记号非常相似,但是 Copy 却完全不依赖 Clone 。早前建立的心智模型现在不适用了。在我看来,理解子特性与超特性的关系的最简单和最优雅的心智模型莫过于 —— 子特性 改良 了超特性。
“改良”一词故意地预留了一些模糊的空间,它的具体含义在不同的上下文中有所不同:
- 子特性可能比超特性的方法更加特异化、运行更快或使用更少内存等等,例如
Copy: Clone - 子特性可能比超特性的方法具有额外的功能,例如
Eq: PartialEq,Ord: PartialOrd和ExactSizeIterator: Iterator - 子特性可能比超特性的方法更灵活和更易于调用,例如
FnMut: FnOnce和Fn: FnMut - 子特性可能扩展了超特性并添加了新的方法,例如
DoubleEndedIterator: Iterator和ExactSizeIterator: Iterator
特性对象
如果说泛型给了我们编译时的多态性,那么特性对象就给了我们运行时的多态性。通过特性对象,我们可以允许函数在运行时动态地返回不同的类型。
#![allow(unused)] fn main() { fn example(condition: bool, vec: Vec<i32>) -> Box<dyn Iterator<Item = i32>> { let iter = vec.into_iter(); if condition { // Has type: // Box<Map<IntoIter<i32>, Fn(i32) -> i32>> // But is cast to: // Box<dyn Iterator<Item = i32>> Box::new(iter.map(|n| n * 2)) } else { // Has type: // Box<Filter<IntoIter<i32>, Fn(&i32) -> bool>> // But is cast to: // Box<dyn Iterator<Item = i32>> Box::new(iter.filter(|&n| n >= 2)) } } // 以上代码中,两种不同的指针类型转换成相同的指针类型 }
特性对象也允许我们在集合中存储不同类型的值:
#![allow(unused)] fn main() { use std::f64::consts::PI; struct Circle { radius: f64, } struct Square { side: f64 } trait Shape { fn area(&self) -> f64; } impl Shape for Circle { fn area(&self) -> f64 { PI * self.radius * self.radius } } impl Shape for Square { fn area(&self) -> f64 { self.side * self.side } } fn get_total_area(shapes: Vec<Box<dyn Shape>>) -> f64 { shapes.into_iter().map(|s| s.area()).sum() } fn example() { let shapes: Vec<Box<dyn Shape>> = vec![ Box::new(Circle { radius: 1.0 }), // Box<Circle> cast to Box<dyn Shape> Box::new(Square { side: 1.0 }), // Box<Square> cast to Box<dyn Shape> ]; assert_eq!(PI + 1.0, get_total_area(shapes)); // ✅ } }
特性对象的结构体大小是未知的,所以必须要通过指针来引用它们。具体类型与特性对象在字面上的区别在于,特性对象必须要用 dyn 关键字来修饰前缀,了解了这一点我们可以轻松辨别二者。
#![allow(unused)] fn main() { struct Struct; trait Trait {} // regular struct // 这是一般的结构 &Struct Box<Struct> Rc<Struct> Arc<Struct> // trait objects // 这是特性对象 &dyn Trait Box<dyn Trait> Rc<dyn Trait> Arc<dyn Trait> }
并非全部的特性都可以转换为特性对象,一个 “对象安全” 的特性必须满足:
- 该特性不要求
Self: Sized - 该特性的所有方法都是 “对象安全” 的
一个特性的方法若要是 “对象安全” 的,必须满足:
- 该方法要求
Self: Sized - 该方法仅在接收参数中使用
Self类型
关于具有这些限制条件的原因超出了本文的讨论范围且与下文无关,如果你对此深感兴趣不妨阅读 Sizedness in Rust 以了解详情。
仅用于标记的特性
仅用于标记的特性,即是某种声明体为空的特性。它们存在的意义在于 “标记” 所实现的类型,且该类型具有某种类型系统所无法表达的属性。
#![allow(unused)] fn main() { // Impling PartialEq for a type promises // that equality for the type has these properties: // - symmetry: a == b implies b == a, and // - transitivity: a == b && b == c implies a == c // But DOES NOT promise this property: // - reflexivity: a == a // 为特定类型实现 PartialEq 特性确保了该类型的相等算符具有以下性质: // - 对称性: 若有 a == b , 则必有 b == a // - 传递性: 若有 a == b 和 b == c , 则必有 a == c // 但是不能确保具有以下性质: // - 自反性: a == a trait PartialEq { fn eq(&self, other: &Self) -> bool; } // Eq has no trait items! The eq method is already // declared by PartialEq, but "impling" Eq // for a type promises this additional equality property: // - reflexivity: a == a // Eq 特性的声明体是空的! 而 eq 方法已经被 PartialEq 所声明, // 但是对特定类型“实现” Eq 特性确保了额外的相等性质: // - 自反性: a == a trait Eq: PartialEq {} // f64 impls PartialEq but not Eq because NaN != NaN // i32 impls PartialEq & Eq because there's no NaNs :) // f64 实现了 PartialEq 特性但是没有实现 Eq 特性,因为 NaN != NaN // i32 同时实现了 PartialEq 特性与 Eq 特性,因为没有 NaN 来捣乱 :) }
可自动实现的特性
可自动实现的特性指的是,存在这样一种特性,若给定类型的成员都实现了该特性,那么该类型就隐式地自动实现该特性。这里所说的 “成员” 依据上下文而具有不同的含义,包括而又不限于结构体的字段、枚举的变量、数组的元素和元组的内容等等。
所有可自动实现的特性都是仅用于标记的特性,反之则不是。正是由于可自动实现的特性必须是仅用于标记的特性,所以编译器才能够自动为其提供一个默认实现,反之编译器就无能为力了。
可自动实现的特性的示例:
#![allow(unused)] fn main() { // implemented for types which are safe to send between threads // 实现 Send 特性的类型可以安全地往返于多个线程 unsafe auto trait Send {} // implemented for types whose references are safe to send between threads // 实现 Sync 特性的类型,其引用可以安全地往返于多个线程 unsafe auto trait Sync {} }
不安全的特性
以 unsafe 修饰前缀的特性,意味着该特性的实现可能需要不安全的代码。Send 特性与 Sync 特性以 unsafe 修饰前缀意味着,如果特定类型没有自动实现该特性,那么说明该类型的成员并非都实现了该特性,这提示着我们手动实现该特性一定要谨慎小心,以确保没有发生数据竞争。
#![allow(unused)] fn main() { // SomeType is not Send or Sync // SomeType 没有实现 Send 和 Sync struct SomeType { not_send_or_sync: *const (), } // but if we're confident that our impl doesn't have any data // races we can explicitly mark it as Send and Sync using unsafe // 倘若我们得以社会主义伟大成就的庇佑自信地写出没有数据竞争的代码 // 可以使用 unsafe 来修饰前缀,以显式地实现 Send 特性与 Sync 特性 unsafe impl Send for SomeType {} unsafe impl Sync for SomeType {} }
可自动实现的特性
Send & Sync
预备知识
#![allow(unused)] fn main() { unsafe auto trait Send {} unsafe auto trait Sync {} }
实现 Send 特性的类型可以安全地往返于多线程。实现 sync 特性的类型,其引用可以安全地往返于多线程。用更加准确的术语来讲,当且仅当 &T 实现 Send 特性时,T 才能实现 Sync 特性。
几乎所有类型都实现了 Send 特性和 Sync 特性。对于 Send 唯一需要注意的例外是 Rc ,对于 Sync 唯三需要注意的例外是 Rc,Cell 和 RefCell 。如果我们需要 Send 版的 Rc ,可以使用 Arc 。如果我们需要 Sync 版的 Cell 或 RefCell ,可以使用 Mutex 或 RwLock 。尽管我们可以使用 Mutex 或 RwLock 来包裹住原语类型,但通常使用标准库提供的原子原语类型会更好,诸如 AtomicBool ,AtomicI32 和 AtomicUsize 等等。
多亏了 Rust 严格的借用规则,几乎所有的类型都是 Sync 的。这对于一些人来讲可能会很惊讶,但事实胜于雄辩,甚至对于那些没有内部同步机制的类型来说也是如此。
对于同一数据,我们可以放心地将该数据的多个不可变引用传递给多个线程,因为只要当前存在一个该数据的不可变引用,那么 Rust 就会静态地确保该数据不会被改变:
use crossbeam::thread; fn main() { let mut greeting = String::from("Hello"); let greeting_ref = &greeting; thread::scope(|scoped_thread| { // spawn 3 threads // 产生三个线程 for n in 1..=3 { // greeting_ref copied into every thread // greeting_ref 被拷贝到每个线程 scoped_thread.spawn(move |_| { println!("{} {}", greeting_ref, n); // prints "Hello {n}" }); } // line below could cause UB or data races but compiler rejects it // 下面这行代码可能导致数据竞争,于是编译器拒绝了它 greeting += " world"; // ❌ cannot mutate greeting while immutable refs exist // ❌ 当不可变引用存在时,不可以修改引用的数据 }); // can mutate greeting after every thread has joined // 当所有的线程结束之后,可以修改数据 greeting += " world"; // ✅ println!("{}", greeting); // prints "Hello world" }
同样地,我们可以将某个数据的单个可变引用传递给单个线程,在此过程中不必担心出现数据竞争,因为 Rust 静态地确保了不存在其它可变引用。以下数据即仅可通过已经存在的单个可变引用而改变:
use crossbeam::thread; fn main() { let mut greeting = String::from("Hello"); let greeting_ref = &mut greeting; thread::scope(|scoped_thread| { // greeting_ref moved into thread // greeting_ref 移动到当前线程 scoped_thread.spawn(move |_| { *greeting_ref += " world"; println!("{}", greeting_ref); // prints "Hello world" }); // line below could cause UB or data races but compiler rejects it // 下面这行代码可能导致数据竞争,于是编译器拒绝了它 greeting += "!!!"; // ❌ cannot mutate greeting while mutable refs exist // ❌ 可变引用存在时不可改变数据 }); // can mutate greeting after the thread has joined // 当所有的线程结束之后,可以修改数据 greeting += "!!!"; // ✅ println!("{}", greeting); // prints "Hello world!!!" }
这就是为什么绝大多数的类型都是 Sync 的而不需要实现任何显式的同步机制。对于数据 T ,如果我们试图从多个线程同时修改的话,编译器会对我们作出警告,除非我们将数据包裹在 Arc<Mutex<T>> 或 Arc<RwLock<T>> 中。所以说,当我们真的需要显式的同步机制时,编译器会强制要求我们这样做的。
Sized
预备知识
如果一个类型实现了 Sized ,那么说明该类型具体大小的字节数在编译时可以确定,并且也就说明该类型的实例可以存放在栈上。
类型的大小以及其所带来的潜在影响,是一个易于忽略但是又十分宏大的话题,它深刻地影响着本门语言的诸多方面。鉴于它的重要性,我已经写了一整篇文章(Sizedness in Rust)来具体阐述其内容,我高度推荐对于希望深入 sizedness 的人阅读此篇文章。下面是此篇文章的要点:
- 所有的泛型类型都具有隐式的
Sized约束。
#![allow(unused)] fn main() { fn func<T>(t: &T) {} // example above desugared // 以上代码等价于 fn func<T: Sized>(t: &T) {} }
- 由于所有的泛型类型都具有隐式的
Sized约束,如果我们希望摆脱这样的隐式约束,那么我们需要使用特殊的 “宽松约束” 记号?Sized,目前这样的记号仅适用于Sized特性:
#![allow(unused)] fn main() { // now T can be unsized // 现在 T 的大小可以是未知的 fn func<T: ?Sized>(t: &T) {} }
- 所有的特性都具有隐式的
?Sized约束。
#![allow(unused)] fn main() { trait Trait {} // example above desugared // 以上代码等价于 trait Trait: ?Sized {} }
这就是为什么特性对象可以实现具体特性。再次,向您推荐关于一切真相的Sizedness in Rust。
常用特性 General traits
Default
预备知识
#![allow(unused)] fn main() { trait Default { fn default() -> Self; } }
为特定类型实现 Default 特性时,即为该类型赋予了可选的默认值。
#![allow(unused)] fn main() { struct Color { r: u8, g: u8, b: u8, } impl Default for Color { // default color is black // 默认颜色是黑色 fn default() -> Self { Color { r: 0, g: 0, b: 0, } } } }
这不仅利于快速原型设计,另外,在有时我们仅仅只是需要该类型的一个值,却完全不在意该值是什么的时候,这也非常方便。
fn main() { // just give me some color! let color = Color::default(); }
如此,我们可以明确地向该函数的用户传达出该函数某个参数的可选择性:
#![allow(unused)] fn main() { struct Canvas; enum Shape { Circle, Rectangle, } impl Canvas { // let user optionally pass a color // 用户可选地传入一个 color fn paint(&mut self, shape: Shape, color: Option<Color>) { // if no color is passed use the default color // 若用户没有传入 color ,即使用默认的 color let color = color.unwrap_or_default(); // etc } } }
在泛型编程的语境中,Default 特性也可显其威力。
#![allow(unused)] fn main() { fn guarantee_length<T: Default>(mut vec: Vec<T>, min_len: usize) -> Vec<T> { for _ in 0..min_len.saturating_sub(vec.len()) { vec.push(T::default()); } vec } }
另外,我们在使用 update 记号构造结构体时也可享受到 Default 特性带来的便利。我们以 Color 结构的 new 构造器函数为例,它接受该结构的全部成员作为参数:
#![allow(unused)] fn main() { impl Color { fn new(r: u8, g: u8, b: u8) -> Self { Color { r, g, b, } } } }
考虑以下更加便捷的构造器函数 —— 它仅接受该结构的部分成员作为参数,其它未指定的成员则回落到默认值:
#![allow(unused)] fn main() { impl Color { fn red(r: u8) -> Self { Color { r, ..Color::default() } } fn green(g: u8) -> Self { Color { g, ..Color::default() } } fn blue(b: u8) -> Self { Color { b, ..Color::default() } } } }
Default 特性也可以用衍生宏的方式来实现:
#![allow(unused)] fn main() { // default color is still black // because u8::default() == 0 // 默认颜色仍旧是黑色 // 因为 u8::default() == 0 #[derive(Default)] struct Color { r: u8, g: u8, b: u8 } }
Clone
预备知识
#![allow(unused)] fn main() { trait Clone { fn clone(&self) -> Self; // provided default impls // 提供默认实现 fn clone_from(&mut self, source: &Self); } }
对于实现了 Clone 特性的类型,我们可以将一个不可变的引用转换为自有的类型,比如 &T -> T 。Clone 特性对于这种转换的效率不做出保证,所以这样的转换速度可能很慢,代价可能很昂贵。
#![allow(unused)] fn main() { #[derive(Clone)] struct SomeType { cloneable_member1: CloneableType1, cloneable_member2: CloneableType2, // etc } // macro generates impl below // 宏展开后为 impl Clone for SomeType { fn clone(&self) -> Self { SomeType { cloneable_member1: self.cloneable_member1.clone(), cloneable_member2: self.cloneable_member2.clone(), // etc } } } }
Clone 特性也有利于在泛型编程的语境中构造类型。请看下例:
#![allow(unused)] fn main() { fn guarantee_length<T: Clone>(mut vec: Vec<T>, min_len: usize, fill_with: &T) -> Vec<T> { for _ in 0..min_len.saturating_sub(vec.len()) { vec.push(fill_with.clone()); } vec } }
克隆确是一个可以逃避借用检查器的好方法。倘若我们编写的代码无法通过借用检查,那么不妨通过克隆将这些引用转换为自有类型。
#![allow(unused)] fn main() { // oof, we gotta worry about lifetimes 😟 // 糟糕!我们真的有自信处理好 lifetime 吗? 😟 struct SomeStruct<'a> { data: &'a Vec<u8>, } // now we're on easy street 😎 // 好耶!人生苦短,我用 Clone ! 😎 struct SomeStruct { data: Vec<u8>, } }
如果性能因素微不足道,我们不必羞于使用克隆。Rust 是一门底层语言,人们可以自由地控制程序行为的方方面面,这就很容易令人陷入盲目追求优化的陷阱,而不是专注于着手解决问题。对此我给出的建议是:正确第一,优雅第二,性能第三。只有程序初具雏形后,性能瓶颈的问题才可能凸显,这时我们再解决性能问题也不迟。与其说这是一条编程建议,更不如说这是一条人生建议,万事万物大抵如此,如果你现在不信,总有一天你会的。
Copy
预备知识
#![allow(unused)] fn main() { trait Copy: Clone {} }
对于实现了 Copy 特性的类型,我们可以拷贝它,即 T -> T 。Copy 特性确保了拷贝操作是按位的拷贝,所以它更快更高效。Copy 特性不可手动实现,必须由编译器提供其实现。注意:当使用衍生宏为类型实现 Copy 特性时,必须同时使用 Clone 衍生宏,因为 Copy 是 Clone 的子特性:
#![allow(unused)] fn main() { #[derive(Copy, Clone)] struct SomeType; }
Copy 改良了 Clone 。克隆操作可能速度缓慢且代价昂贵,但是拷贝操作一定是高效低耗的,可以说拷贝就是一种物美价廉的克隆。Copy 特性的实现会令 Clone 特性的实现变得微不足道:
#![allow(unused)] fn main() { // this is what the derive macro generates // 衍生宏展开如下 impl<T: Copy> Clone for T { // the clone method becomes just a copy // 克隆实际上变成了一种拷贝 fn clone(&self) -> Self { *self } } }
实现了 Copy 特性的类型,其在移动时的行为会发生变化。默认情况下,所有的类型都具有 移动语义 ,但是一旦该类型实现了 Copy 特性,则会变为 拷贝语义。 请考虑下例中语义的不同:
#![allow(unused)] fn main() { // a "move", src: !Copy // 移动语义,src 没有实现 Copy 特性 let dest = src; // a "copy", src: Copy // 拷贝语义,src 实现 Copy 特性 let dest = src; }
事实上,这两种语义背后执行的操作是完全相同的,都是将 src 按位复制到 dest 。其不同在于,在移动语义下,借用检查器从此吊销了 src 的可用性,而在拷贝语义下,src 保持可用。
言而总之,拷贝就是移动,移动就是拷贝。它们在底层毫无二致,仅仅是借用检查器对待它们的方式不同。
对于移动行为来讲更具体的例子 —— 你可以将 src 想象为一个 Vec<i32>,它的结构体大致如下:
#![allow(unused)] fn main() { { data: *mut [i32], length: usize, capacity: usize } }
执行 desc = src 的结果如下:
#![allow(unused)] fn main() { src = { data: *mut [i32], length: usize, capacity: usize } dest = { data: *mut [i32], length: usize, capacity: usize } }
此时 src 和 dest 就都是同一数据的可变引用了,这可就糟tm的大糕了,所以借用检查器就吊销了 src 的可用性,一旦再次使用 src 就会引发编译错误。
对于拷贝行为来讲更具体的例子 —— 你可以将 src 想象为一个 Option<i32> ,它的结构体大致如下:
#![allow(unused)] fn main() { { is_valid: bool, data: i32 } }
执行 desc = src 的结果如下:
#![allow(unused)] fn main() { src = { is_valid: bool, data: i32 } dest = { is_valid: bool, data: i32 } }
此时两者同时可用!因为 Option<i32> 实现了 Copy 。
或许你已经注意到,令 Copy 特性成为可自动实现的特性在理论上是可行的。但是 Rust 语言的设计者认为,比之于在恰当时隐式地继承拷贝语义,显示地声明为拷贝语义更加的简单和安全。前者可能会导致 Rust 语言产生十分反人类的行为,也更容易出现 bug 。
Any
预备知识
#![allow(unused)] fn main() { trait Any: 'static { fn type_id(&self) -> TypeId; } }
Rust 的多态性风格本身是参数化的,但如果我们希望临时使用一种更贴近于动态语言的多态性风格,可以借用 Any 特性来模拟。我们不需要手动实现 Any 特性,因为该特性通常由通用泛型实现所实现。
#![allow(unused)] fn main() { impl<T: 'static + ?Sized> Any for T { fn type_id(&self) -> TypeId { TypeId::of::<T>() } } }
对于 dyn Any 的特性对象,我们可以使用 downcast_ref::<T>() 或 downcast_mut::<T>() 来尝试解析出 T 。
use std::any::Any; #[derive(Default)] struct Point { x: i32, y: i32, } impl Point { fn inc(&mut self) { self.x += 1; self.y += 1; } } fn map_any(mut any: Box<dyn Any>) -> Box<dyn Any> { if let Some(num) = any.downcast_mut::<i32>() { *num += 1; } else if let Some(string) = any.downcast_mut::<String>() { *string += "!"; } else if let Some(point) = any.downcast_mut::<Point>() { point.inc(); } any } fn main() { let mut vec: Vec<Box<dyn Any>> = vec![ Box::new(0), Box::new(String::from("a")), Box::new(Point::default()), ]; // vec = [0, "a", Point { x: 0, y: 0 }] vec = vec.into_iter().map(map_any).collect(); // vec = [1, "a!", Point { x: 1, y: 1 }] }
这个特性鲜少被使用,因为参数化的多态性时常要优于这样变通使用的多态性,且后者也可以使用更加类型安全和更加直接的枚举来模拟。如下例:
#[derive(Default)] struct Point { x: i32, y: i32, } impl Point { fn inc(&mut self) { self.x += 1; self.y += 1; } } enum Stuff { Integer(i32), String(String), Point(Point), } fn map_stuff(mut stuff: Stuff) -> Stuff { match &mut stuff { Stuff::Integer(num) => *num += 1, Stuff::String(string) => *string += "!", Stuff::Point(point) => point.inc(), } stuff } fn main() { let mut vec = vec![ Stuff::Integer(0), Stuff::String(String::from("a")), Stuff::Point(Point::default()), ]; // vec = [0, "a", Point { x: 0, y: 0 }] vec = vec.into_iter().map(map_stuff).collect(); // vec = [1, "a!", Point { x: 1, y: 1 }] }
尽管 Any 特性鲜少是必须要被使用的,但有时它又是一种非常便捷的用法,我们将在 错误处理 一章中领会这一点。
文本格式化特性
我们可以使用 std::fmt 中提供的文本格式化宏来序列化结构体,例如我们最熟悉的 println! 。我们可以将文本格式化的参数传入 {} 占位符,以选择具体用哪个特性来序列化该结构。
| 特性 | 占位符 | 描述 |
|---|---|---|
Display | {} | 常规序列化 |
Debug | {:?} | 调试序列化 |
Octal | {:o} | 八进制序列化 |
LowerHex | {:x} | 小写十六进制序列化 |
UpperHex | {:X} | 大写十六进制序列化 |
Pointer | {:p} | 内存地址 |
Binary | {:b} | 二进制序列化 |
LowerExp | {:e} | 小写指数序列化 |
UpperExp | {:E} | 大写十六进制序列化 |
Display & ToString
预备知识
#![allow(unused)] fn main() { trait Display { fn fmt(&self, f: &mut Formatter<'_>) -> Result; } }
实现 Display 特性的类型可以被序列化为 String 。这对于程序的用户来说非常的友好。例如:
use std::fmt; #[derive(Default)] struct Point { x: i32, y: i32, } impl fmt::Display for Point { fn fmt(&self, f: &mut fmt::Formatter<'_>) -> fmt::Result { write!(f, "({}, {})", self.x, self.y) } } fn main() { println!("origin: {}", Point::default()); // prints "origin: (0, 0)" // get Point's Display representation as a String // Point 表达为可显示的 String let stringified_point = format!("{}", Point::default()); assert_eq!("(0, 0)", stringified_point); // ✅ }
除了使用 format! 宏来序列化结构体,我们也可以使用 ToString 特性:
#![allow(unused)] fn main() { trait ToString { fn to_string(&self) -> String; } }
我们不需要自己手动实现,事实上,我们也不能,因为对于实现了 Display 的类型来说,ToString 是由通用泛型实现所自动实现的。
#![allow(unused)] fn main() { impl<T: Display + ?Sized> ToString for T; }
Using
ToStringwithPoint:
对 Point 使用 ToString 特性:
#![allow(unused)] fn main() { #[test] // ✅ fn display_point() { let origin = Point::default(); assert_eq!(format!("{}", origin), "(0, 0)"); } #[test] // ✅ fn point_to_string() { let origin = Point::default(); assert_eq!(origin.to_string(), "(0, 0)"); } #[test] // ✅ fn display_equals_to_string() { let origin = Point::default(); assert_eq!(format!("{}", origin), origin.to_string()); } }
Debug
预备知识
#![allow(unused)] fn main() { trait Debug { fn fmt(&self, f: &mut Formatter<'_>) -> Result; } }
Debug 与 Display 具有相同的签名。唯一的区别在于我们使用 {:?} 文本格式化指令来调用 Debug 特性。 Debug 特性可以使用如下方法衍生:
#![allow(unused)] fn main() { use std::fmt; #[derive(Debug)] struct Point { x: i32, y: i32, } // derive macro generates impl below // 衍生宏展开如下 impl fmt::Debug for Point { fn fmt(&self, f: &mut fmt::Formatter<'_>) -> fmt::Result { f.debug_struct("Point") .field("x", &self.x) .field("y", &self.y) .finish() } } }
为特定类型实现 Debug 特性的同时,这也使得我们可以使用 dbg! 宏来快速地调试程序,这种方式要优于 println! 。其优点在于:
dbg!输出到标准错误流而不是标准输出流,所以我们能够很容易地将调试信息提取出来。dbg!同时输出值和值的求值表达式。dbg!接管参数的属权,但不会吞掉参数,而是再抛出来,所以可以将它用在表达式中:
#![allow(unused)] fn main() { fn some_condition() -> bool { true } // no logging // 没有日志 fn example() { if some_condition() { // some code } } // println! logging // 使用 println! 打印日志 fn example_println() { // 🤦 let result = some_condition(); println!("{}", result); // just prints "true" // 仅仅打印 "true" if result { // some code } } // dbg! logging // 使用 dbg! 打印日志 fn example_dbg() { // 😍 if dbg!(some_condition()) { // prints "[src/main.rs:22] some_condition() = true" // 太棒了!打印出丰富的调试信息 // some code } } }
dbg! 宏唯一的缺点是,它不能在构建最终发布的二进制文件时自动删除,我们不得不手动删除相关代码。
算符重载特性
在 Rust 中,所有的算符都与相应的特性相关联。为特定类型实现相应特性,即为该类型实现了相应算符。
| 特性 | 类别 | 算符 | 描述 |
|---|---|---|---|
Eq, PartialEq | 比较 | == | 相等 |
Ord, PartialOrd | 比较 | <, >, <=, >= | 比较 |
Add | 算数 | + | 加 |
AddAssign | 算数 | += | 加等于 |
BitAnd | 算数 | & | 按位与 |
BitAndAssign | 算数 | &= | 按位与等于 |
BitXor | 算数 | ^ | 按位异或 |
BitXorAssign | 算数 | ^= | 按位异或等于 |
Div | 算数 | / | 除 |
DivAssign | 算数 | /= | 除等于 |
Mul | 算数 | * | 乘 |
MulAssign | 算数 | *= | 乘等于 |
Neg | 算数 | - | 一元负 |
Not | 算数 | ! | 一元逻辑非 |
Rem | 算数 | % | 求余 |
RemAssign | 算数 | %= | 求余等于 |
Shl | 算数 | << | 左移 |
ShlAssign | 算数 | <<= | 左移等于 |
Shr | 算数 | >> | 右移 |
ShrAssign | 算数 | >>= | 右移等于 |
Sub | 算数 | - | 减 |
SubAssign | 算数 | -= | 减等于 |
Fn | 闭包 | (...args) | 不可变闭包调用 |
FnMut | 闭包 | (...args) | 可变闭包调用 |
FnOnce | 闭包 | (...args) | 一次性闭包调用 |
Deref | 其它 | * | 不可变解引用 |
DerefMut | 其它 | * | 可变解引用 |
Drop | 其它 | - | 类型析构 |
Index | 其它 | [] | 不可变索引 |
IndexMut | 其它 | [] | 可变索引 |
RangeBounds | 其它 | .. | 范围迭代 |
比较特性 Comparison Traits
| 特性 | 类别 | 算符 | 描述 |
|---|---|---|---|
Eq, PartialEq | 比较 | == | 相等 |
Ord, PartialOrd | 比较 | <, >, <=, >= | 比较 |
PartialEq & Eq
预备知识
- Self
- Methods
- Generic Parameters
- Default Impls
- Generic Blanket Impls
- Marker Traits
- Subtraits & Supertraits
- Sized
#![allow(unused)] fn main() { trait PartialEq<Rhs = Self> where Rhs: ?Sized, { fn eq(&self, other: &Rhs) -> bool; // provided default impls // 提供默认实现 fn ne(&self, other: &Rhs) -> bool; } }
实现了 PartialEq<Rhs> 特性的类型可以使用 == 算符来检查与 Rhs 的相等性。
对 PartialEq<Rhs> 的实现须确保实现对称性与传递性。这意味着对于任意 a , b 和 c 有:
- 若
a == b则b == a(对称性) - 若
a == b && b == c则a == c(传递性)
默认情况下 Rhs = Self 是因为我们几乎总是在相同类型之间进行比较。这也自动地确保了我们的实现是对称的、可传递的。
#![allow(unused)] fn main() { struct Point { x: i32, y: i32 } // Rhs == Self == Point impl PartialEq for Point { // impl automatically symmetric & transitive // 该实现自动确保了对称性于传递性 fn eq(&self, other: &Point) -> bool { self.x == other.x && self.y == other.y } } }
如果特定类型的成员都实现了 PartialEq 特性,那么该类型也可衍生该特性:
#![allow(unused)] fn main() { #[derive(PartialEq)] struct Point { x: i32, y: i32 } #[derive(PartialEq)] enum Suit { Spade, Heart, Club, Diamond, } }
多亏了通用泛型实现,一旦我们为特定类型实现了 PartialEq 特性,那么直接使用该类型的引用互相比较也是可以的:
#![allow(unused)] fn main() { // this impl only gives us: Point == Point // 该衍生宏本身只允许我们在结构体之间进行比较 #[derive(PartialEq)] struct Point { x: i32, y: i32 } // all of the generic blanket impls below // are provided by the standard library // 以下的通用泛型实现由标准库提供 // this impl gives us: &Point == &Point // 这个通用泛型实现允许我们通过不可变引用之间进行比较 impl<A, B> PartialEq<&'_ B> for &'_ A where A: PartialEq<B> + ?Sized, B: ?Sized; // this impl gives us: &mut Point == &Point // 这个通用泛型实现允许我们通过可变引用与不可变引用进行比较 impl<A, B> PartialEq<&'_ B> for &'_ mut A where A: PartialEq<B> + ?Sized, B: ?Sized; // this impl gives us: &Point == &mut Point // 这个通用泛型实现允许我们通过不可变引用与可变引用进行比较 impl<A, B> PartialEq<&'_ mut B> for &'_ A where A: PartialEq<B> + ?Sized, B: ?Sized; // this impl gives us: &mut Point == &mut Point // 这个通用泛型实现允许我们通过可变引用之间进行比较 impl<A, B> PartialEq<&'_ mut B> for &'_ mut A where A: PartialEq<B> + ?Sized, B: ?Sized; }
由于该特性提供泛型,我们可以定义不同类型之间的可相等性。标准库正是利用这一点提供了不同类型字符串之间的比较功能,例如String, &str, PathBuf,&Path,OsString 和 &OsStr等等。
通常来说我们仅会实现相同类型之间的可相等性,除非两种类型虽然包含同一类数据,但又有表达形式或交互形式的差异,这时我们才会考虑实现不同类型之间的可相等性。
以下是一个有趣但糟糕的例子,它尝试为不同类型实现 PartialEq 但又违背了上述要求:
#[derive(PartialEq)] enum Suit { Spade, Club, Heart, Diamond, } #[derive(PartialEq)] enum Rank { Ace, Two, Three, Four, Five, Six, Seven, Eight, Nine, Ten, Jack, Queen, King, } #[derive(PartialEq)] struct Card { suit: Suit, rank: Rank, } // check equality of Card's suit // 检查花色的相等性 impl PartialEq<Suit> for Card { fn eq(&self, other: &Suit) -> bool { self.suit == *other } } // check equality of Card's rank // 检查牌序的相等性 impl PartialEq<Rank> for Card { fn eq(&self, other: &Rank) -> bool { self.rank == *other } } fn main() { let AceOfSpades = Card { suit: Suit::Spade, rank: Rank::Ace, }; assert!(AceOfSpades == Suit::Spade); // ✅ assert!(AceOfSpades == Rank::Ace); // ✅ }
上述代码有效且其逻辑有几分道理,黑桃 A 既是黑桃也是 A 。但如果我们真的去写一个处理扑克牌的库的话,最简单也最方便的方法莫过于独立地检查牌面的花色和牌序。而且,上述代码并不满足对称性!我们可以使用 Card == Suit 和 Card == Rank ,但却不能使用 Suit == Card 和 Rank == Card, 让我们来修复这一点:
#![allow(unused)] fn main() { // check equality of Card's suit // 检查花色的相等性 impl PartialEq<Suit> for Card { fn eq(&self, other: &Suit) -> bool { self.suit == *other } } // added for symmetry // 增加对称性 impl PartialEq<Card> for Suit { fn eq(&self, other: &Card) -> bool { *self == other.suit } } // check equality of Card's rank // 检查牌序的相等性 impl PartialEq<Rank> for Card { fn eq(&self, other: &Rank) -> bool { self.rank == *other } } // added for symmetry // 增加对称性 impl PartialEq<Card> for Rank { fn eq(&self, other: &Card) -> bool { *self == other.rank } } }
我们实现了对称性!棒!但是实现对称性却破坏了传递性!糟tm大糕!考虑以下代码:
fn main() { // Ace of Spades // ♠A let a = Card { suit: Suit::Spade, rank: Rank::Ace, }; let b = Suit::Spade; // King of Spades // ♠K let c = Card { suit: Suit::Spade, rank: Rank::King, }; assert!(a == b && b == c); // ✅ assert!(a == c); // ❌ }
关于对不同类型实现 PartialEq 特性的绝佳示例如下,本程序的功能在于处理空间上的距离,它使用不同的类型以表示不同的测量单位:
#[derive(PartialEq)] struct Foot(u32); #[derive(PartialEq)] struct Yard(u32); #[derive(PartialEq)] struct Mile(u32); impl PartialEq<Mile> for Foot { fn eq(&self, other: &Mile) -> bool { self.0 == other.0 * 5280 } } impl PartialEq<Foot> for Mile { fn eq(&self, other: &Foot) -> bool { self.0 * 5280 == other.0 } } impl PartialEq<Mile> for Yard { fn eq(&self, other: &Mile) -> bool { self.0 == other.0 * 1760 } } impl PartialEq<Yard> for Mile { fn eq(&self, other: &Yard) -> bool { self.0 * 1760 == other.0 } } impl PartialEq<Foot> for Yard { fn eq(&self, other: &Foot) -> bool { self.0 * 3 == other.0 } } impl PartialEq<Yard> for Foot { fn eq(&self, other: &Yard) -> bool { self.0 == other.0 * 3 } } fn main() { let a = Foot(5280); let b = Yard(1760); let c = Mile(1); // symmetry // 对称性 assert!(a == b && b == a); // ✅ assert!(b == c && c == b); // ✅ assert!(a == c && c == a); // ✅ // transitivity // 传递性 assert!(a == b && b == c && a == c); // ✅ assert!(c == b && b == a && c == a); // ✅ }
Eq 是仅用于标记的特性,也是 PartialEq<Self> 的子特性。
#![allow(unused)] fn main() { trait Eq: PartialEq<Self> {} }
鉴于 PartialEq 特性提供的对称性与传递性,一旦我们实现 Eq 特性,我们也就确保了该类型具有自反性,即对任意 a 有 a == a 。可以说, Eq 改良了 PartialEq ,因为它实现了一个比后者更加严格的可相等性。如果一个类型的全部成员都实现了 Eq 特性,那么该类型本身也可以衍生出该特性。
所有的浮点类型都实现了 PartialEq 但是没有实现 Eq ,因为 NaN != NaN 。几乎所有其它实现 PartialEq 的类型也都自然地实现了 Eq ,除非它们包含了浮点数。
对于实现了 PartialEq 和 Debug 的类型,我们也可以将它用于 assert_eq! 宏。并且,我们可以对实现 PartialEq 特性的类型组成的集合进行比较。
#![allow(unused)] fn main() { #[derive(PartialEq, Debug)] struct Point { x: i32, y: i32, } fn example_assert(p1: Point, p2: Point) { assert_eq!(p1, p2); } fn example_compare_collections<T: PartialEq>(vec1: Vec<T>, vec2: Vec<T>) { // if T: PartialEq this now works! if vec1 == vec2 { // some code } else { // other code } } }
Hash
预备知识
#![allow(unused)] fn main() { trait Hash { fn hash<H: Hasher>(&self, state: &mut H); // provided default impls // 提供默认实现 fn hash_slice<H: Hasher>(data: &[Self], state: &mut H); } }
本特性并未关联到任何算符,之所以在这里提及,是因为它与 PartialEq 与 Eq 密切的关系。实现 Hash 特性的类型可以通过 Hasher 作哈希运算。
#![allow(unused)] fn main() { use std::hash::Hasher; use std::hash::Hash; struct Point { x: i32, y: i32, } impl Hash for Point { fn hash<H: Hasher>(&self, hasher: &mut H) { hasher.write_i32(self.x); hasher.write_i32(self.y); } } }
以下衍生宏展开与以上代码中相同的实现:
#![allow(unused)] fn main() { #[derive(Hash)] struct Point { x: i32, y: i32, } }
如果一个类型同时实现了 Hash 和 Eq ,那么二者必须要实现步调一致,即对任意 a 与 b , 若有 a == b , 则必有 a.hash() == b.hash() 。所以,对于同时实现二者,要么都用衍生宏,要么都手动实现,不要一个用衍生宏,而另一个手动实现,否则我们将冒着步调不一致的极大风险。
实现Eq 和 Hash 特性的主要好处在于,这允许我们将该类型作为一个键存储于 HashMap 和 HashSet 中。
#![allow(unused)] fn main() { use std::collections::HashSet; // now our type can be stored // in HashSets and HashMaps! // 现在我们的类型可以存储于 HashSet 和 HashMap 中了! #[derive(PartialEq, Eq, Hash)] struct Point { x: i32, y: i32, } fn example_hashset() { let mut points = HashSet::new(); points.insert(Point { x: 0, y: 0 }); // ✅ } }
PartialOrd & Ord
预备知识
- Self
- Methods
- Generic Parameters
- Default Impls
- Subtraits & Supertraits
- Derive Macros
- Sized
- PartialEq & Eq
#![allow(unused)] fn main() { enum Ordering { Less, Equal, Greater, } trait PartialOrd<Rhs = Self>: PartialEq<Rhs> where Rhs: ?Sized, { fn partial_cmp(&self, other: &Rhs) -> Option<Ordering>; // provided default impls // 提供默认实现 fn lt(&self, other: &Rhs) -> bool; fn le(&self, other: &Rhs) -> bool; fn gt(&self, other: &Rhs) -> bool; fn ge(&self, other: &Rhs) -> bool; } }
实现 PartialOrd<Rhs> 的类型可以和 Rhs 的类型之间使用 <,<=,>,和 >= 算符。
实现 PartialOrd 时须确保比较的非对称性和传递性。这意味着对任意 a,b,c有:
- 若
a < b则!(a > b)(非对称性) - 若
a < b && b < c则a < c(传递性)
PartialOrd 是 PartialEq 的子特性,二者必须要实现步调一致。
#![allow(unused)] fn main() { fn must_always_agree<T: PartialOrd + PartialEq>(t1: T, t2: T) { assert_eq!(t1.partial_cmp(&t2) == Some(Ordering::Equal), t1 == t2); } }
PartialOrd 改良了 PartialEq ,后者仅能比较是否相等,而前者除了能比较是否相等,还能比较孰大孰小。
默认情况下 Rhs = Self ,因为我们几乎总是在相同类型的实例之间相比较,而不是不同类型之间。这一点自动保证了我们的实现的对称性和传递性。
#![allow(unused)] fn main() { use std::cmp::Ordering; #[derive(PartialEq, PartialOrd)] struct Point { x: i32, y: i32 } // Rhs == Self == Point impl PartialOrd for Point { // impl automatically symmetric & transitive // 该实现自动确保了对称性与传递性 fn partial_cmp(&self, other: &Point) -> Option<Ordering> { Some(match self.x.cmp(&other.x) { Ordering::Equal => self.y.cmp(&other.y), ordering => ordering, }) } } }
如果特定类型的全部成员都实现了 PartialOrd 特性,那么该类型也可以衍生出该特性:
#![allow(unused)] fn main() { #[derive(PartialEq, PartialOrd)] struct Point { x: i32, y: i32, } #[derive(PartialEq, PartialOrd)] enum Stoplight { Red, Yellow, Green, } }
PartialOrd 衍生宏依据 类型成员的定义顺序 对类型进行排序:
#![allow(unused)] fn main() { // generates PartialOrd impl which orders // Points based on x member first and // y member second because that's the order // they appear in the source code // 宏展开的 PartialOrd 实现排序时 // 首先考虑 x 再考虑 y // 因为这是它们在源代码中出现的顺序 #[derive(PartialOrd, PartialEq)] struct Point { x: i32, y: i32, } // generates DIFFERENT PartialOrd impl // which orders Points based on y member // first and x member second // 这里宏展开的 PartialOrd 实现排序时 // 首先考虑 y 再考虑 x #[derive(PartialOrd, PartialEq)] struct Point { y: i32, x: i32, } }
Ord 是 Eq 和 PartialOrd<Self> 的子特性:
#![allow(unused)] fn main() { trait Ord: Eq + PartialOrd<Self> { fn cmp(&self, other: &Self) -> Ordering; // provided default impls // 提供默认实现 fn max(self, other: Self) -> Self; fn min(self, other: Self) -> Self; fn clamp(self, min: Self, max: Self) -> Self; } }
鉴于 PartialOrd 提供的非对称性和传递性,对特定类型实现 Ord 特性的同时也就保证了其非对称性,即对于任意 a 与 b 有 a < b ,a == b ,a < b 。可以说, Ord 改良了 Eq 和 PartialOrd ,因为它提供了一种更加严格的比较。如果一个类型实现了 Ord ,那么 PartialOrd ,PartialEq 和 Eq 的实现也就微不足道了。
#![allow(unused)] fn main() { use std::cmp::Ordering; // of course we can use the derive macros here // 可以使用衍生宏 #[derive(Ord, PartialOrd, Eq, PartialEq)] struct Point { x: i32, y: i32, } // note: as with PartialOrd, the Ord derive macro // orders a type based on the lexicographical order // of its members // 注意:与 PatrialOrd 相同,Ord 衍生宏衍生宏依据 // 类型的成员的定义顺序 对类型进行排序 // but here's the impls if we wrote them out by hand // 以下是我们手动的实现 impl Ord for Point { fn cmp(&self, other: &Self) -> Ordering { match self.x.cmp(&other.x) { Ordering::Equal => self.y.cmp(&other.y), ordering => ordering, } } } impl PartialOrd for Point { fn partial_cmp(&self, other: &Self) -> Option<Ordering> { Some(self.cmp(other)) } } impl PartialEq for Point { fn eq(&self, other: &Self) -> bool { self.cmp(other) == Ordering::Equal } } impl Eq for Point {} }
浮点数类型实现了 PartialOrd 但是没有实现 Ord ,因为 NaN < 0 == false 与 NaN >= 0 == false 同时为真。几乎所有其它实现 PartialOrd 的类型都实现了 Ord ,除非该类型包含浮点数。
对于实现了 Ord 特性的类型,我们可以将它存储于 BTreeMap 和 BTreeSet ,并且可以通过 sort() 方法对切片,或者任何可以自动解引用为切片的类型进行排序,例如 Vec 和 VecDeque 。
#![allow(unused)] fn main() { use std::collections::BTreeSet; // now our type can be stored // in BTreeSets and BTreeMaps! // 现在我们的类型可以存储于 BTreeSet 和 BTreeMap 中了! #[derive(Ord, PartialOrd, PartialEq, Eq)] struct Point { x: i32, y: i32, } fn example_btreeset() { let mut points = BTreeSet::new(); points.insert(Point { x: 0, y: 0 }); // ✅ } // we can also .sort() Ord types in collections! // 对于实现了 Ord 特性的类型,我们可以使用 .sort() 方法来对集合进行排序! fn example_sort<T: Ord>(mut sortable: Vec<T>) -> Vec<T> { sortable.sort(); sortable } }
算术特性 Arithmetic Traits
| 特性 | 类别 | 算符 | 描述 |
|---|---|---|---|
Add | 算数 | + | 加 |
AddAssign | 算数 | += | 加等于 |
BitAnd | 算数 | & | 按位与 |
BitAndAssign | 算数 | &= | 按位与等于 |
BitXor | 算数 | ^ | 按位异或 |
BitXorAssign | 算数 | ^= | 按位异或等于 |
Div | 算数 | / | 除 |
DivAssign | 算数 | /= | 除等于 |
Mul | 算数 | * | 乘 |
MulAssign | 算数 | *= | 乘等于 |
Neg | 算数 | - | 一元负 |
Not | 算数 | ! | 一元逻辑非 |
Rem | 算数 | % | 求余 |
RemAssign | 算数 | %= | 求余等于 |
Shl | 算数 | << | 左移 |
ShlAssign | 算数 | <<= | 左移等于 |
Shr | 算数 | >> | 右移 |
ShrAssign | 算数 | >>= | 右移等于 |
Sub | 算数 | - | 减 |
SubAssign | 算数 | -= | 减等于 |
详解以上所有算术特性未免显得多余,且其大多仅用于操作数字类型。本文仅就最常见被重载的 Add 和 AddAssign 特性,亦即 + 和 += 算符,进行说明,其重载广泛用于为集合增加内容或对不同事物的连接。这样,我们多侧重于最有趣的地方,而不是无趣枯燥地重复。
Add & AddAssign
预备知识
#![allow(unused)] fn main() { trait Add<Rhs = Self> { type Output; fn add(self, rhs: Rhs) -> Self::Output; } }
实现 Add<Rhs, Output = T> 特性的类型,与 Rhs 类型相加得到 T 类型的值。
下例对 Point 类型实现了 Add<Rhs, Output = T> :
#[derive(Clone, Copy)] struct Point { x: i32, y: i32, } impl Add for Point { type Output = Point; fn add(self, rhs: Point) -> Point { Point { x: self.x + rhs.x, y: self.y + rhs.y, } } } fn main() { let p1 = Point { x: 1, y: 2 }; let p2 = Point { x: 3, y: 4 }; let p3 = p1 + p2; assert_eq!(p3.x, p1.x + p2.x); // ✅ assert_eq!(p3.y, p1.y + p2.y); // ✅ }
如果我们对 Point 的引用进行如上操作还能将他们加在一起吗?我们试试:
fn main() { let p1 = Point { x: 1, y: 2 }; let p2 = Point { x: 3, y: 4 }; let p3 = &p1 + &p2; // ❌ }
遗憾的是,并不可以。编译器出错了:
error[E0369]: cannot add `&Point` to `&Point`
--> src/main.rs:50:25
|
50 | let p3: Point = &p1 + &p2;
| --- ^ --- &Point
| |
| &Point
|
= note: an implementation of `std::ops::Add` might be missing for `&Point`
在 Rust 的类型系统中,对于特定类型 T 来讲,T ,&T ,&mut T 三者本身是具有不同类型的,这意味着我们需要对它们分别实现相应特性。下面我们对 &Point 实现 Add 特性:
impl Add for &Point { type Output = Point; fn add(self, rhs: &Point) -> Point { Point { x: self.x + rhs.x, y: self.y + rhs.y, } } } fn main() { let p1 = Point { x: 1, y: 2 }; let p2 = Point { x: 3, y: 4 }; let p3 = &p1 + &p2; // ✅ assert_eq!(p3.x, p1.x + p2.x); // ✅ assert_eq!(p3.y, p1.y + p2.y); // ✅ }
这是可行的,但是不觉得哪里怪怪的吗?我们对 Point 和 &Point 分别实现了 Add 特性,现在来看这两种实现能够保持步调一致,但是未来也能保证吗?例如,我们现在决定对两个 Point 相加要产生一个 Line 而不是 Point ,可以对 Add 特性的实现做出如下改动:
use std::ops::Add; #[derive(Copy, Clone)] struct Point { x: i32, y: i32, } #[derive(Copy, Clone)] struct Line { start: Point, end: Point, } // we updated this impl // 我们更新了这个实现 impl Add for Point { type Output = Line; fn add(self, rhs: Point) -> Line { Line { start: self, end: rhs, } } } // but forgot to update this impl, uh oh! // 但是忘记了更新这个实现,糟tm大糕! impl Add for &Point { type Output = Point; fn add(self, rhs: &Point) -> Point { Point { x: self.x + rhs.x, y: self.y + rhs.y, } } } fn main() { let p1 = Point { x: 1, y: 2 }; let p2 = Point { x: 3, y: 4 }; let line: Line = p1 + p2; // ✅ let p1 = Point { x: 1, y: 2 }; let p2 = Point { x: 3, y: 4 }; let line: Line = &p1 + &p2; // ❌ expected Line, found Point // ❌ 期待得到 Line ,但是得到 Point }
我们对 &Point 不可变引用类型的 Add 实现,给我们带来了不必要的维护困难。是否能够使得,当我们更改 Point 类型的实现时, &Point 类型的实现也能够自动发生匹配,而不需要我们手动维护呢?我们的愿望是尽可能写出 DRY (Don't Repeat Yourself) 的不重复的代码。幸运的是,我们可以如此实现这一点:
// updated, DRY impl // 使用一种更“干”的实现 impl Add for &Point { type Output = <Point as Add>::Output; fn add(self, rhs: &Point) -> Self::Output { Point::add(*self, *rhs) } } fn main() { let p1 = Point { x: 1, y: 2 }; let p2 = Point { x: 3, y: 4 }; let line: Line = p1 + p2; // ✅ let p1 = Point { x: 1, y: 2 }; let p2 = Point { x: 3, y: 4 }; let line: Line = &p1 + &p2; // ✅ }
实现 AddAssign<Rhs> 的类型,允许我们对 Rhs 的类型相加之并赋值到自身。该特性的声明为:
#![allow(unused)] fn main() { trait AddAssign<Rhs = Self> { fn add_assign(&mut self, rhs: Rhs); } }
对 Point 和 &Point 类型的实现示例:
use std::ops::AddAssign; #[derive(Copy, Clone)] struct Point { x: i32, y: i32 } impl AddAssign for Point { fn add_assign(&mut self, rhs: Point) { self.x += rhs.x; self.y += rhs.y; } } impl AddAssign<&Point> for Point { fn add_assign(&mut self, rhs: &Point) { Point::add_assign(self, *rhs); } } fn main() { let mut p1 = Point { x: 1, y: 2 }; let p2 = Point { x: 3, y: 4 }; p1 += &p2; p1 += p2; assert!(p1.x == 7 && p1.y == 10); }
闭包特性 Closure Traits
| 特性 | 类别 | 算符 | 描述 |
|---|---|---|---|
Fn | 闭包 | (...args) | 不可变闭包调用 |
FnMut | 闭包 | (...args) | 可变闭包调用 |
FnOnce | 闭包 | (...args) | 一次性闭包调用 |
FnOnce, FnMut, & Fn
预备知识
- Self
- Methods
- Associated Types
- Generic Parameters
- Generic Types vs Associated Types
- Subtraits & Supertraits
#![allow(unused)] fn main() { trait FnOnce<Args> { type Output; fn call_once(self, args: Args) -> Self::Output; } trait FnMut<Args>: FnOnce<Args> { fn call_mut(&mut self, args: Args) -> Self::Output; } trait Fn<Args>: FnMut<Args> { fn call(&self, args: Args) -> Self::Output; } }
事实上,在 stable Rust 中我们并不能对我们自己的类型实现上述特性,唯一的例外是闭包。对于闭包从环境中捕获的值的不同,该闭包会实现不同的特性:FnOnce ,FnMut ,Fn 。
对于实现 FnOnce 的闭包,仅可调用一次,因为它消耗掉了其执行中必须的值:
fn main() { let range = 0..10; let get_range_count = || range.count(); assert_eq!(get_range_count(), 10); // ✅ get_range_count(); // ❌ }
迭代器上的 .count() 方法会消耗掉整个迭代器,所以该方法仅能调用一次。所以我们的闭包也就是能调用一次了,这就是为什么当第二次调用该闭包时会出错:
error[E0382]: use of moved value: `get_range_count`
--> src/main.rs:5:5
|
4 | assert_eq!(get_range_count(), 10);
| ----------------- `get_range_count` moved due to this call
5 | get_range_count();
| ^^^^^^^^^^^^^^^ value used here after move
|
note: closure cannot be invoked more than once because it moves the variable `range` out of its environment
--> src/main.rs:3:30
|
3 | let get_range_count = || range.count();
| ^^^^^
note: this value implements `FnOnce`, which causes it to be moved when called
--> src/main.rs:4:16
|
4 | assert_eq!(get_range_count(), 10);
| ^^^^^^^^^^^^^^^
对于实现 FnMut 特性的闭包,我们可以多次调用,且其可以改变其从环境捕获的值。我们可以说实现 FnMut 的闭包的执行具有副作用,或者说它是具有状态的。下例展示了一个闭包,它通过跟踪最小值,来找到一个迭代器中所有非升序的值:
fn main() { let nums = vec![0, 4, 2, 8, 10, 7, 15, 18, 13]; let mut min = i32::MIN; let ascending = nums.into_iter().filter(|&n| { if n <= min { false } else { min = n; true } }).collect::<Vec<_>>(); assert_eq!(vec![0, 4, 8, 10, 15, 18], ascending); // ✅ }
FnMut 改良了 FnOnce ,FnOnce 需要接管参数的属权因此只能调用一次,而 FnMut 只需要参数的可变引用即可并可调用多次。FnMut 可以在所有 FnOnce 可用的地方使用。
对于实现 Fn 特性的闭包,我们可以调用多次,且其不改变任何从环境中捕获的变量。我们可以说实现 Fn 的闭包的执行不具有副作用,或者说它是不具有状态的。下例展示了一个闭包,它通过与栈上的值进行比较,过滤掉一个迭代器中所有比它小的值:
fn main() { let nums = vec![0, 4, 2, 8, 10, 7, 15, 18, 13]; let min = 9; let greater_than_9 = nums.into_iter().filter(|&n| n > min).collect::<Vec<_>>(); assert_eq!(vec![10, 15, 18, 13], greater_than_9); // ✅ }
Fn 改良了 FnMut ,尽管它们都可以多次调用,但是 FnMut 需要参数的可变引用,而 Fn 仅需要参数的不可变引用。Fn 可以在所有 FnMut 和 FnOnce 可用的地方使用。
如果一个闭包不从环境中捕获任何的值,那么从技术上讲它就不是闭包,而仅仅只是一个内联的匿名函数。并且它可以被转换为、用于或传递为一个常规函数指针,即 fn。函数指针可以用于任何 Fn ,FnMut ,FnOnce 可用的地方。
fn add_one(x: i32) -> i32 { x + 1 } fn main() { let mut fn_ptr: fn(i32) -> i32 = add_one; assert_eq!(fn_ptr(1), 2); // ✅ // capture-less closure cast to fn pointer // 不捕获环境的闭包可转换为普通函数指针 fn_ptr = |x| x + 1; // same as add_one assert_eq!(fn_ptr(1), 2); // ✅ }
以下示例中,将常规函数作为闭包而传入:
fn main() { let nums = vec![-1, 1, -2, 2, -3, 3]; let absolutes: Vec<i32> = nums.into_iter().map(i32::abs).collect(); assert_eq!(vec![1, 1, 2, 2, 3, 3], absolutes); // ✅ }
其它特性 Other Traits
| 特性 | 类别 | 算符 | 描述 |
|---|---|---|---|
Deref | 其它 | * | 不可变解引用 |
DerefMut | 其它 | * | 可变解引用 |
Drop | 其它 | - | 类型析构 |
Index | 其它 | [] | 不可变索引 |
IndexMut | 其它 | [] | 可变索引 |
RangeBounds | 其它 | .. | 范围迭代 |
Deref & DerefMut
预备知识
#![allow(unused)] fn main() { trait Deref { type Target: ?Sized; fn deref(&self) -> &Self::Target; } trait DerefMut: Deref { fn deref_mut(&mut self) -> &mut Self::Target; } }
实现 Deref<Target = T> 的类型,可以通过 * 解引用算符,解引用到 T 类型。智能指针是该特性的著名实现者,例如 Box 和 Rc 。不过,我们很少在 Rust 编程中看到解引用算符,这是由于 Rust 的强制解引用的特性所导致的。
当作为函数的参数、函数的返回值、方法的调用参数时,Rust 会自动地解引用。这就是为什么我们可以将 &String 或 &Vec<T> 类型的值作为参数传递给接受 str 或 &[T] 类型的参数的函数,因为 String 实现了 Deref<Target = str> ,Vec<t> 实现了 Deref<Target = [T]> 。
Deref 和 DerefMut 仅应实现于智能指针类型。最常见的误用或滥用就是,人们经常希望强行把某种面向对象编程风格的数据继承塞到 Rust 编程中。这是不可能的,因为 Rust 不是面向对象的。让我们用一个例子来领会到底为什么这是不可以的:
#![allow(unused)] fn main() { use std::ops::Deref; struct Human { health_points: u32, } enum Weapon { Spear, Axe, Sword, } // a Soldier is just a Human with a Weapon // 士兵是手持武器的人类 struct Soldier { human: Human, weapon: Weapon, } impl Deref for Soldier { type Target = Human; fn deref(&self) -> &Human { &self.human } } enum Mount { Horse, Donkey, Cow, } // a Knight is just a Soldier with a Mount // 骑士是胯骑坐骑的士兵 struct Knight { soldier: Soldier, mount: Mount, } impl Deref for Knight { type Target = Soldier; fn deref(&self) -> &Soldier { &self.soldier } } enum Spell { MagicMissile, FireBolt, ThornWhip, } // a Mage is just a Human who can cast Spells // 法师是口诵咒语的人类 struct Mage { human: Human, spells: Vec<Spell>, } impl Deref for Mage { type Target = Human; fn deref(&self) -> &Human { &self.human } } enum Staff { Wooden, Metallic, Plastic, } // a Wizard is just a Mage with a Staff // 巫师是腰别法宝的法师 struct Wizard { mage: Mage, staff: Staff, } impl Deref for Wizard { type Target = Mage; fn deref(&self) -> &Mage { &self.mage } } fn borrows_human(human: &Human) {} fn borrows_soldier(soldier: &Soldier) {} fn borrows_knight(knight: &Knight) {} fn borrows_mage(mage: &Mage) {} fn borrows_wizard(wizard: &Wizard) {} fn example(human: Human, soldier: Soldier, knight: Knight, mage: Mage, wizard: Wizard) { // all types can be used as Humans borrows_human(&human); borrows_human(&soldier); borrows_human(&knight); borrows_human(&mage); borrows_human(&wizard); // Knights can be used as Soldiers borrows_soldier(&soldier); borrows_soldier(&knight); // Wizards can be used as Mages borrows_mage(&mage); borrows_mage(&wizard); // Knights & Wizards passed as themselves borrows_knight(&knight); borrows_wizard(&wizard); } }
事实上,并不可以这么做。首先,强制解引用仅用于引用,所以我们不能移交属权:
#![allow(unused)] fn main() { fn takes_human(human: Human) {} fn example(human: Human, soldier: Soldier, knight: Knight, mage: Mage, wizard: Wizard) { // all types CANNOT be used as Humans takes_human(human); takes_human(soldier); // ❌ takes_human(knight); // ❌ takes_human(mage); // ❌ takes_human(wizard); // ❌ } }
其次,强制解引用不可用于泛型编程。例如某特性仅对人类实现:
#![allow(unused)] fn main() { trait Rest { fn rest(&self); } impl Rest for Human { fn rest(&self) {} } fn take_rest<T: Rest>(rester: &T) { rester.rest() } fn example(human: Human, soldier: Soldier, knight: Knight, mage: Mage, wizard: Wizard) { // all types CANNOT be used as Rest types, only Human take_rest(&human); take_rest(&soldier); // ❌ take_rest(&knight); // ❌ take_rest(&mage); // ❌ take_rest(&wizard); // ❌ } }
强制解引用可以用于许多情况,但绝不是所有情况。例如对于算符的操作数而言就不行,即便算符仅是一种方法调用的语法糖。比如,我们希望使用 += 算符来表达法师学习咒语。
#![allow(unused)] fn main() { impl DerefMut for Wizard { fn deref_mut(&mut self) -> &mut Mage { &mut self.mage } } impl AddAssign<Spell> for Mage { fn add_assign(&mut self, spell: Spell) { self.spells.push(spell); } } fn example(mut mage: Mage, mut wizard: Wizard, spell: Spell) { mage += spell; wizard += spell; // ❌ wizard not coerced to mage here // ❌ 在这里,巫师不能强制转换为法师 wizard.add_assign(spell); // oof, we have to call it like this 🤦 // 所以,我们必须要这样做 🤦 } }
在带有面向对象风格的数据继承的语言中,方法中的 self 值的类型总是等同于调用该方法的类型。但是在 Rust 语言中,self 值的类型总是等同于实现该方法时的类型。
#![allow(unused)] fn main() { struct Human { profession: &'static str, health_points: u32, } impl Human { // self will always be a Human here, even if we call it on a Soldier // 该方法中的 self 的类型永远是 Human ,即便我们在 Soldier 类型上调用 fn state_profession(&self) { println!("I'm a {}!", self.profession); } } struct Soldier { profession: &'static str, human: Human, weapon: Weapon, } fn example(soldier: &Soldier) { assert_eq!("servant", soldier.human.profession); assert_eq!("spearman", soldier.profession); soldier.human.state_profession(); // prints "I'm a servant!" soldier.state_profession(); // still prints "I'm a servant!" 🤦 } }
上述特性常令人感到困惑,特别是在对新类型实现 Deref 和 DerefMut 的时候。例如我们想要设计一个 SortedVec 类型,相比于 Vec 类型,它总是处于已排序的状态。我们可能会这样做:
#![allow(unused)] fn main() { struct SortedVec<T: Ord>(Vec<T>); impl<T: Ord> SortedVec<T> { fn new(mut vec: Vec<T>) -> Self { vec.sort(); SortedVec(vec) } fn push(&mut self, t: T) { self.0.push(t); self.0.sort(); } } }
显然我们不能为其实现 DerefMut<Target = Vec<T>> ,因为这可能会破坏排序状态。实现 Deref<Target = Vec<T>> 必须要保证功能的正确性。尝试指出下列代码中的 bug :
use std::ops::Deref; struct SortedVec<T: Ord>(Vec<T>); impl<T: Ord> SortedVec<T> { fn new(mut vec: Vec<T>) -> Self { vec.sort(); SortedVec(vec) } fn push(&mut self, t: T) { self.0.push(t); self.0.sort(); } } impl<T: Ord> Deref for SortedVec<T> { type Target = Vec<T>; fn deref(&self) -> &Vec<T> { &self.0 } } fn main() { let sorted = SortedVec::new(vec![2, 8, 6, 3]); sorted.push(1); let sortedClone = sorted.clone(); sortedClone.push(4); }
鉴于我们从未对 SortedVec 实现 Clone 特性,所以当我们调用 .clone() 方法的时候,编译器会使用强制解引用将该方法调用解析为 Vec 的方法调用,所以该方法返回的是 Vec 而不是 SortedVec !
fn main() { let sorted: SortedVec<i32> = SortedVec::new(vec![2, 8, 6, 3]); sorted.push(1); // still sorted // calling clone on SortedVec actually returns a Vec 🤦 let sortedClone: Vec<i32> = sorted.clone(); sortedClone.push(4); // sortedClone no longer sorted 💀 }
切记,Rust 并非设计为面向对象的语言,也并不将面向对象编程的模式作为一等公民,所以以上的限制、约束和令人困惑的特性并不被认为是在语言中是错误的。
本节的主旨即是使读者领会为什么不要自作聪明地实现 Deref 和 DerefMut 特性。这类特性确仅适合于智能指针类的类型,目前来讲标准库中的智能指针的实现,确需要这样的不稳定特性以及一些编译器魔法才能工作。如果我们确需要一些类似于Deref 和 DerefMut 的特性,不妨使用 AsRef 和 AsMut 特性。我们将在后面的章节中对这类特性做出说明。
Index & IndexMut
预备知识
- Self
- Methods
- Associated Types
- Generic Parameters
- Generic Types vs Associated Types
- Subtraits & Supertraits
- Sized
#![allow(unused)] fn main() { trait Index<Idx: ?Sized> { type Output: ?Sized; fn index(&self, index: Idx) -> &Self::Output; } trait IndexMut<Idx>: Index<Idx> where Idx: ?Sized { fn index_mut(&mut self, index: Idx) -> &mut Self::Output; } }
对于实现 Index<T, Output = U> 的类型,我们可以使用 [] 索引算符对 T 类型的值索引 &U 类型的值。作为语法糖,编译器也会为索引操作返回的值自动添加一个 * 解引用算符。
fn main() { // Vec<i32> impls Index<usize, Output = i32> so // indexing Vec<i32> should produce &i32s and yet... // 鉴于 Vec<i32> 实现了 Index<usize, Output = i32> // 所以对 Vec<i32> 的索引应当返回 &i32 类型的值,但是。。。 let vec = vec![1, 2, 3, 4, 5]; let num_ref: &i32 = vec[0]; // ❌ expected &i32 found i32 // above line actually desugars to // 以上代码等价于 let num_ref: &i32 = *vec[0]; // ❌ expected &i32 found i32 // both of these alternatives work // 以下是建议使用的一对形式 let num: i32 = vec[0]; // ✅ let num_ref: &i32 = &vec[0]; // ✅ }
令人困惑的是,似乎 Index 特性没有遵循它自己的方法签名,但其实真正有问题的是语法糖。
鉴于 Idx 是泛型类型,Index 特性对多个给定类型可以多次实现。并且对于 Vec<T> ,我们不仅可以对 usize 索引,还可以对 Range<usize> 索引得到切片。
fn main() { let vec = vec![1, 2, 3, 4, 5]; assert_eq!(&vec[..], &[1, 2, 3, 4, 5]); // ✅ assert_eq!(&vec[1..], &[2, 3, 4, 5]); // ✅ assert_eq!(&vec[..4], &[1, 2, 3, 4]); // ✅ assert_eq!(&vec[1..4], &[2, 3, 4]); // ✅ }
为了展示如何自己实现 Index 特性,以下是一个有趣的例子,它设计了一个 Vec 的包装结构,其使得循环索引和负数索引成为可能:
#![allow(unused)] fn main() { use std::ops::Index; struct WrappingIndex<T>(Vec<T>); impl<T> Index<usize> for WrappingIndex<T> { type Output = T; fn index(&self, index: usize) -> &T { &self.0[index % self.0.len()] } } impl<T> Index<i128> for WrappingIndex<T> { type Output = T; fn index(&self, index: i128) -> &T { let self_len = self.0.len() as i128; let idx = (((index % self_len) + self_len) % self_len) as usize; &self.0[idx] } } #[test] // ✅ fn indexes() { let wrapping_vec = WrappingIndex(vec![1, 2, 3]); assert_eq!(1, wrapping_vec[0_usize]); assert_eq!(2, wrapping_vec[1_usize]); assert_eq!(3, wrapping_vec[2_usize]); } #[test] // ✅ fn wrapping_indexes() { let wrapping_vec = WrappingIndex(vec![1, 2, 3]); assert_eq!(1, wrapping_vec[3_usize]); assert_eq!(2, wrapping_vec[4_usize]); assert_eq!(3, wrapping_vec[5_usize]); } #[test] // ✅ fn neg_indexes() { let wrapping_vec = WrappingIndex(vec![1, 2, 3]); assert_eq!(1, wrapping_vec[-3_i128]); assert_eq!(2, wrapping_vec[-2_i128]); assert_eq!(3, wrapping_vec[-1_i128]); } #[test] // ✅ fn wrapping_neg_indexes() { let wrapping_vec = WrappingIndex(vec![1, 2, 3]); assert_eq!(1, wrapping_vec[-6_i128]); assert_eq!(2, wrapping_vec[-5_i128]); assert_eq!(3, wrapping_vec[-4_i128]); } }
Idx 的类型并不非得是数字类型或 Range 类型,甚至还可以是枚举!例如我们可以在一支篮球队中,对打什么位置索引从而得到队伍里打这个位置的队员:
#![allow(unused)] fn main() { use std::ops::Index; enum BasketballPosition { PointGuard, ShootingGuard, Center, PowerForward, SmallForward, } struct BasketballPlayer { name: &'static str, position: BasketballPosition, } struct BasketballTeam { point_guard: BasketballPlayer, shooting_guard: BasketballPlayer, center: BasketballPlayer, power_forward: BasketballPlayer, small_forward: BasketballPlayer, } impl Index<BasketballPosition> for BasketballTeam { type Output = BasketballPlayer; fn index(&self, position: BasketballPosition) -> &BasketballPlayer { match position { BasketballPosition::PointGuard => &self.point_guard, BasketballPosition::ShootingGuard => &self.shooting_guard, BasketballPosition::Center => &self.center, BasketballPosition::PowerForward => &self.power_forward, BasketballPosition::SmallForward => &self.small_forward, } } } }
Drop
预备知识
#![allow(unused)] fn main() { trait Drop { fn drop(&mut self); } }
对于实现 Drop 特性的类型,在该类型脱离作用域并销毁前,其 drop 方法会被调用。通常,不必为我们的类型实现这一特性,除非该类型持有某种外部的资源,且该资源需要显式释放。
标准库中的 BufWriter 类型允许我们对向 Write 类型写入的时候进行缓存。显然,当 BufWriter 销毁前应当把缓存的内容写入 Writer 实例,这就是 Drop 所允许我们做到的!对于实现了 Drop 的 BufWriter 来说,其实例在销毁前会总会调用 flush 方法。
#![allow(unused)] fn main() { impl<W: Write> Drop for BufWriter<W> { fn drop(&mut self) { self.flush_buf(); } } }
并且,在 Rust 中 Mutex 类型之所以没有 unlock() 方法,就是因为它完全不需要!鉴于 Drop 特性的实现,调用 Mutex 的 lock() 方法返回的 MutexGuard 类型,在脱离作用域时会自动地释放 Mutex 。
#![allow(unused)] fn main() { impl<T: ?Sized> Drop for MutexGuard<'_, T> { fn drop(&mut self) { unsafe { self.lock.inner.raw_unlock(); } } } }
简而言之,如果你正在设计某种需要显示释放的资源的抽象包装,那么这正是 Drop 特性大显神威的地方。
转换特性
From & Into
预备知识
#![allow(unused)] fn main() { trait From<T> { fn from(T) -> Self; } }
实现 From<T> 特性的类型允许我们从 T 类型转换到自身的类型 Self 。
#![allow(unused)] fn main() { trait Into<T> { fn into(self) -> T; } }
实现 Into<T> 特性的类型允许我们从自身的类型 Self 转换到 T 类型。
这是一对恰好相反的特性,如同一枚硬币的两面。注意,我们只能手动实现 From<T> 特性,而不能手动实现 Into<T> 特性,因为 Into<T> 特性已经被通用泛型实现所自动实现。
#![allow(unused)] fn main() { impl<T, U> Into<U> for T where U: From<T>, { fn into(self) -> U { U::from(self) } } }
这两个特性同时存在的一个好处在于,我们可以在为泛型类型添加约束的时候,使用两种稍有不同的记号:
#![allow(unused)] fn main() { fn function<T>(t: T) where // these bounds are equivalent // 以下两种记号等价 T: From<i32>, i32: Into<T> { // these examples are equivalent // 以下两种记号等价 let example: T = T::from(0); let example: T = 0.into(); } }
对于具体使用哪种记号并无一定之规,请根据实际情况做出最恰当的选择。接下来我们看看 Point 类型的例子:
#![allow(unused)] fn main() { struct Point { x: i32, y: i32, } impl From<(i32, i32)> for Point { fn from((x, y): (i32, i32)) -> Self { Point { x, y } } } impl From<[i32; 2]> for Point { fn from([x, y]: [i32; 2]) -> Self { Point { x, y } } } fn example() { // using From let origin = Point::from((0, 0)); let origin = Point::from([0, 0]); // using Into let origin: Point = (0, 0).into(); let origin: Point = [0, 0].into(); } }
这样的转换并不是对称的,如果我们想将 Point 转换为元组或数组,那么我们需要显式地编写相应的代码:
#![allow(unused)] fn main() { struct Point { x: i32, y: i32, } impl From<(i32, i32)> for Point { fn from((x, y): (i32, i32)) -> Self { Point { x, y } } } impl From<Point> for (i32, i32) { fn from(Point { x, y }: Point) -> Self { (x, y) } } impl From<[i32; 2]> for Point { fn from([x, y]: [i32; 2]) -> Self { Point { x, y } } } impl From<Point> for [i32; 2] { fn from(Point { x, y }: Point) -> Self { [x, y] } } fn example() { // from (i32, i32) into Point let point = Point::from((0, 0)); let point: Point = (0, 0).into(); // from Point into (i32, i32) let tuple = <(i32, i32)>::from(point); let tuple: (i32, i32) = point.into(); // from [i32; 2] into Point let point = Point::from([0, 0]); let point: Point = [0, 0].into(); // from Point into [i32; 2] let array = <[i32; 2]>::from(point); let array: [i32; 2] = point.into(); } }
借由 From<T> 特性,我们可以省却大量编写模板代码的麻烦。例如,我们现在具有一个包含三个 Point 的类型 Triangle 类型,以下是构造该类型的几种办法:
#![allow(unused)] fn main() { struct Point { x: i32, y: i32, } impl Point { fn new(x: i32, y: i32) -> Point { Point { x, y } } } impl From<(i32, i32)> for Point { fn from((x, y): (i32, i32)) -> Point { Point { x, y } } } struct Triangle { p1: Point, p2: Point, p3: Point, } impl Triangle { fn new(p1: Point, p2: Point, p3: Point) -> Triangle { Triangle { p1, p2, p3 } } } impl<P> From<[P; 3]> for Triangle where P: Into<Point> { fn from([p1, p2, p3]: [P; 3]) -> Triangle { Triangle { p1: p1.into(), p2: p2.into(), p3: p3.into(), } } } fn example() { // manual construction let triangle = Triangle { p1: Point { x: 0, y: 0, }, p2: Point { x: 1, y: 1, }, p3: Point { x: 2, y: 2, }, }; // using Point::new let triangle = Triangle { p1: Point::new(0, 0), p2: Point::new(1, 1), p3: Point::new(2, 2), }; // using From<(i32, i32)> for Point let triangle = Triangle { p1: (0, 0).into(), p2: (1, 1).into(), p3: (2, 2).into(), }; // using Triangle::new + From<(i32, i32)> for Point let triangle = Triangle::new( (0, 0).into(), (1, 1).into(), (2, 2).into(), ); // using From<[Into<Point>; 3]> for Triangle let triangle: Triangle = [ (0, 0), (1, 1), (2, 2), ].into(); } }
对于 From<T> 特性的使用并无一定之规,运用你的智慧明智地使用它吧!
使用 Into<T> 特性的一个神奇之处在于,对于那些本来只能接受特定类型参数的函数,现在你可以有更多不同的选择:
#![allow(unused)] fn main() { struct Person { name: String, } impl Person { // accepts: // - String fn new1(name: String) -> Person { Person { name } } // accepts: // - String // - &String // - &str // - Box<str> // - Cow<'_, str> // - char // since all of the above types can be converted into String fn new2<N: Into<String>>(name: N) -> Person { Person { name: name.into() } } } }
错误处理 Error Handling
讲解错误处理与 Error 特性的最佳时机,莫过于在 Display , Debug , Any 和 From 之后, TryFrom 之前,这就是为什么我要将 错误处理 这一节硬塞在 转换特性 这一章里。
Error
预备知识
- Self
- Methods
- Default Impls
- Generic Blanket Impls
- Subtraits & Supertraits
- Trait Objects
- Display & ToString
- Debug
- Any
- From & Into
#![allow(unused)] fn main() { trait Error: Debug + Display { // provided default impls // 提供默认实现 fn source(&self) -> Option<&(dyn Error + 'static)>; fn backtrace(&self) -> Option<&Backtrace>; fn description(&self) -> &str; fn cause(&self) -> Option<&dyn Error>; } }
在 Rust 中,错误是被返回的,而不是被抛出的。让我们看看下面的例子:
由于整数的除零操作会导致 panic ,为了程序的健壮性,我们显式地实现了安全的 safe_div 除法函数,它的返回值是 Result :
#![allow(unused)] fn main() { use std::fmt; use std::error; #[derive(Debug, PartialEq)] struct DivByZero; impl fmt::Display for DivByZero { fn fmt(&self, f: &mut fmt::Formatter<'_>) -> fmt::Result { write!(f, "division by zero error") } } impl error::Error for DivByZero {} fn safe_div(numerator: i32, denominator: i32) -> Result<i32, DivByZero> { if denominator == 0 { return Err(DivByZero); } Ok(numerator / denominator) } #[test] // ✅ fn test_safe_div() { assert_eq!(safe_div(8, 2), Ok(4)); assert_eq!(safe_div(5, 0), Err(DivByZero)); } }
由于错误是被返回的,而不是被抛出的,它们必须被显式地处理。如果当前函数没有处理该错误的能力,那么该错误应当原路返回到上一级调用函数。最理想的返回错误的方法是使用 ? 算符,它是现在已经过时的 try! 宏的语法糖:
#![allow(unused)] fn main() { macro_rules! try { (expr:expr) => { match expr { // if Ok just unwrap the value // 正常情况下直接解除 Result 的包装 Ok(val) => val, // if Err map the err value using From and return // 否则将该错误进行适当转换后,返回到上级调用函数 Err(err) => { return Err(From::from(err)); } } }; } }
例如,如果我们的函数其功能是将文件读为一个 String ,那么使用 ? 算符来将可能的错误 io::Error 返回给上级调用函数就很方便:
#![allow(unused)] fn main() { use std::io::Read; use std::path::Path; use std::io; use std::fs::File; fn read_file_to_string(path: &Path) -> Result<String, io::Error> { let mut file = File::open(path)?; // ⬆️ io::Error let mut contents = String::new(); file.read_to_string(&mut contents)?; // ⬆️ io::Error Ok(contents) } }
又例如,如果我们的文件是一系列数字,我们想将它们加在一起,可以这样编写代码:
#![allow(unused)] fn main() { use std::io::Read; use std::path::Path; use std::io; use std::fs::File; fn sum_file(path: &Path) -> Result<i32, /* What to put here? */> { // 这里填写什么类型好呢? let mut file = File::open(path)?; // ⬆️ io::Error let mut contents = String::new(); file.read_to_string(&mut contents)?; // ⬆️ io::Error let mut sum = 0; for line in contents.lines() { sum += line.parse::<i32>()?; // ⬆️ ParseIntError } Ok(sum) } }
现在 Rusult 的类型又如何?该函数内部可能产生 io::Error 或 ParseIntError 两种错误。我们将介绍三种解决此类问题的方法,从最简单但不优雅的方法,到最健壮的方法:
方法一,我们注意到,所有实现了 Error 的类型同时也实现了 Display ,因此我们可以将错误映射到 String 并以此为错误类型:
#![allow(unused)] fn main() { use std::fs::File; use std::io; use std::io::Read; use std::path::Path; fn sum_file(path: &Path) -> Result<i32, String> { let mut file = File::open(path) .map_err(|e| e.to_string())?; // ⬆️ io::Error -> String let mut contents = String::new(); file.read_to_string(&mut contents) .map_err(|e| e.to_string())?; // ⬆️ io::Error -> String let mut sum = 0; for line in contents.lines() { sum += line.parse::<i32>() .map_err(|e| e.to_string())?; // ⬆️ ParseIntError -> String } Ok(sum) } }
此方法的明显缺点在于,由于我们将所有的错误都序列化了,以至于丢弃了该错误的类型信息,这对于上级调用函数错误处理来讲,就不是那么方便了。
但此方法也有一个不明显的优点,那就是我们可以使用自定义的字符串,来提供丰富的上下文错误信息。例如,ParseIntError 通常序列化为 "invalid digit found in string" 这样模棱两可的文本,既没有提及无效的字符串是什么,也没有提及它要转换到什么样的数字类型。这样的信息对于我们调试程序来讲几乎没有什么帮助。不过我们可以提供更有意义的,且上下文相关的信息来明显改善这一点:
#![allow(unused)] fn main() { sum += line.parse::<i32>() .map_err(|_| format!("failed to parse {} into i32", line))?; }
The second approach takes advantage of this generic blanket impl from the standard library:
方法二,利用标准库的通用泛型实现:
#![allow(unused)] fn main() { impl<E: error::Error> From<E> for Box<dyn error::Error>; }
所有实现了 Error 特性的类型都可以隐式地使用 ? 转换为 Box<dyn error::Error> 类型。所以我们可以将 Rusult 的错误类型设为 Box<dyn error::Error> 类型,然后 ? 算符会帮我们实现这一隐式转换。
#![allow(unused)] fn main() { use std::fs::File; use std::io::Read; use std::path::Path; use std::error; fn sum_file(path: &Path) -> Result<i32, Box<dyn error::Error>> { let mut file = File::open(path)?; // ⬆️ io::Error -> Box<dyn error::Error> let mut contents = String::new(); file.read_to_string(&mut contents)?; // ⬆️ io::Error -> Box<dyn error::Error> let mut sum = 0; for line in contents.lines() { sum += line.parse::<i32>()?; // ⬆️ ParseIntError -> Box<dyn error::Error> } Ok(sum) } }
这看起来似乎有与第一种方法一样的缺点,丢弃了错误的类型信息。有时确实如此,但倘若上级调用函数知悉该函数的实现细节,那么它仍然可以通过 error::Error 特性的 downcast_ref() 方法来分辨错误的具体类型,这与实现了 dyn Any 特性的类型是一样的:
#![allow(unused)] fn main() { fn handle_sum_file_errors(path: &Path) { match sum_file(path) { Ok(sum) => println!("the sum is {}", sum), Err(err) => { if let Some(e) = err.downcast_ref::<io::Error>() { // handle io::Error } else if let Some(e) = err.downcast_ref::<ParseIntError>() { // handle ParseIntError } else { // we know sum_file can only return one of the // above errors so this branch is unreachable // 由于我们知道该函数只能返回以上两种错误, // 所以这一选择肢一般是不可能执行的 unreachable!(); } } } } }
方法三,处理错误的最健壮和类型安全的方法,是通过枚举来构建我们自己的错误类型:
#![allow(unused)] fn main() { use std::num::ParseIntError; use std::fs::File; use std::io; use std::io::Read; use std::path::Path; use std::error; use std::fmt; #[derive(Debug)] enum SumFileError { Io(io::Error), Parse(ParseIntError), } impl From<io::Error> for SumFileError { fn from(err: io::Error) -> Self { SumFileError::Io(err) } } impl From<ParseIntError> for SumFileError { fn from(err: ParseIntError) -> Self { SumFileError::Parse(err) } } impl fmt::Display for SumFileError { fn fmt(&self, f: &mut fmt::Formatter<'_>) -> fmt::Result { match self { SumFileError::Io(err) => write!(f, "sum file error: {}", err), SumFileError::Parse(err) => write!(f, "sum file error: {}", err), } } } impl error::Error for SumFileError { // the default impl for this method always returns None // but we can now override it to make it way more useful! // 在默认实现中,该方法总是返回 None ,现在重写它! fn source(&self) -> Option<&(dyn error::Error + 'static)> { Some(match self { SumFileError::Io(err) => err, SumFileError::Parse(err) => err, }) } } fn sum_file(path: &Path) -> Result<i32, SumFileError> { let mut file = File::open(path)?; // ⬆️ io::Error -> SumFileError let mut contents = String::new(); file.read_to_string(&mut contents)?; // ⬆️ io::Error -> SumFileError let mut sum = 0; for line in contents.lines() { sum += line.parse::<i32>()?; // ⬆️ ParseIntError -> SumFileError } Ok(sum) } fn handle_sum_file_errors(path: &Path) { match sum_file(path) { Ok(sum) => println!("the sum is {}", sum), Err(SumFileError::Io(err)) => { // handle io::Error }, Err(SumFileError::Parse(err)) => { // handle ParseIntError }, } } }
转换特性深入
TryFrom & TryInto
预备知识
- Self
- Functions
- Methods
- Associated Types
- Generic Parameters
- Generic Types vs Associated Types
- Generic Blanket Impls
- From & Into
- Error
TryFrom 和 TryInto 是可能失败版本的 From 和 Into 。
#![allow(unused)] fn main() { trait TryFrom<T> { type Error; fn try_from(value: T) -> Result<Self, Self::Error>; } trait TryInto<T> { type Error; fn try_into(self) -> Result<T, Self::Error>; } }
与 Into 相似地,我们不能手动实现 TryInto ,因为它已经为通用泛型实现所提供。
#![allow(unused)] fn main() { impl<T, U> TryInto<U> for T where U: TryFrom<T>, { type Error = U::Error; fn try_into(self) -> Result<U, U::Error> { U::try_from(self) } } }
例如,我们的程序要求 Point 的 x 和 y 的值必须要处于 -1000 到 1000 之间,相较于 From ,使用 TryFrom 可以告知上级调用者,某些转换可能失败了。
#![allow(unused)] fn main() { use std::convert::TryFrom; use std::error; use std::fmt; struct Point { x: i32, y: i32, } #[derive(Debug)] struct OutOfBounds; impl fmt::Display for OutOfBounds { fn fmt(&self, f: &mut fmt::Formatter<'_>) -> fmt::Result { write!(f, "out of bounds") } } impl error::Error for OutOfBounds {} // now fallible // TryFrom 的转换允许失败 impl TryFrom<(i32, i32)> for Point { type Error = OutOfBounds; fn try_from((x, y): (i32, i32)) -> Result<Point, OutOfBounds> { if x.abs() > 1000 || y.abs() > 1000 { return Err(OutOfBounds); } Ok(Point { x, y }) } } // still infallible // From 的转换不允许失败 impl From<Point> for (i32, i32) { fn from(Point { x, y }: Point) -> Self { (x, y) } } }
现在,我们对 Triangle 使用 TryFrom<[TryInto<Point>; 3]> 进行重构:
#![allow(unused)] fn main() { use std::convert::{TryFrom, TryInto}; use std::error; use std::fmt; struct Point { x: i32, y: i32, } #[derive(Debug)] struct OutOfBounds; impl fmt::Display for OutOfBounds { fn fmt(&self, f: &mut fmt::Formatter<'_>) -> fmt::Result { write!(f, "out of bounds") } } impl error::Error for OutOfBounds {} impl TryFrom<(i32, i32)> for Point { type Error = OutOfBounds; fn try_from((x, y): (i32, i32)) -> Result<Self, Self::Error> { if x.abs() > 1000 || y.abs() > 1000 { return Err(OutOfBounds); } Ok(Point { x, y }) } } struct Triangle { p1: Point, p2: Point, p3: Point, } impl<P> TryFrom<[P; 3]> for Triangle where P: TryInto<Point>, { type Error = P::Error; fn try_from([p1, p2, p3]: [P; 3]) -> Result<Self, Self::Error> { Ok(Triangle { p1: p1.try_into()?, p2: p2.try_into()?, p3: p3.try_into()?, }) } } fn example() -> Result<Triangle, OutOfBounds> { let t: Triangle = [(0, 0), (1, 1), (2, 2)].try_into()?; Ok(t) } }
FromStr
预备知识
#![allow(unused)] fn main() { trait FromStr { type Err; fn from_str(s: &str) -> Result<Self, Self::Err>; } }
实现 FromStr 特性的类型允许可失败地从 &str 转换至 Self 。使用这一特性的理想方式是,调用 &str 实例的 .parse() 方法:
#![allow(unused)] fn main() { use std::str::FromStr; fn example<T: FromStr>(s: &'static str) { // these are all equivalent // 以下方法互相等价 let t: Result<T, _> = FromStr::from_str(s); let t = T::from_str(s); let t: Result<T, _> = s.parse(); let t = s.parse::<T>(); // most idiomatic // 最理想的使用方式 } }
下例为 Point 实现了 FromStr 特性:
#![allow(unused)] fn main() { use std::error; use std::fmt; use std::iter::Enumerate; use std::num::ParseIntError; use std::str::{Chars, FromStr}; #[derive(Debug, Eq, PartialEq)] struct Point { x: i32, y: i32, } impl Point { fn new(x: i32, y: i32) -> Self { Point { x, y } } } #[derive(Debug, PartialEq)] struct ParsePointError; impl fmt::Display for ParsePointError { fn fmt(&self, f: &mut fmt::Formatter<'_>) -> fmt::Result { write!(f, "failed to parse point") } } impl From<ParseIntError> for ParsePointError { fn from(_e: ParseIntError) -> Self { ParsePointError } } impl error::Error for ParsePointError {} impl FromStr for Point { type Err = ParsePointError; fn from_str(s: &str) -> Result<Self, Self::Err> { let is_num = |(_, c): &(usize, char)| matches!(c, '0'..='9' | '-'); let isnt_num = |t: &(_, _)| !is_num(t); let get_num = |char_idxs: &mut Enumerate<Chars<'_>>| -> Result<(usize, usize), ParsePointError> { let (start, _) = char_idxs .skip_while(isnt_num) .next() .ok_or(ParsePointError)?; let (end, _) = char_idxs .skip_while(is_num) .next() .ok_or(ParsePointError)?; Ok((start, end)) }; let mut char_idxs = s.chars().enumerate(); let (x_start, x_end) = get_num(&mut char_idxs)?; let (y_start, y_end) = get_num(&mut char_idxs)?; let x = s[x_start..x_end].parse::<i32>()?; let y = s[y_start..y_end].parse::<i32>()?; Ok(Point { x, y }) } } #[test] // ✅ fn pos_x_y() { let p = "(4, 5)".parse::<Point>(); assert_eq!(p, Ok(Point::new(4, 5))); } #[test] // ✅ fn neg_x_y() { let p = "(-6, -2)".parse::<Point>(); assert_eq!(p, Ok(Point::new(-6, -2))); } #[test] // ✅ fn not_a_point() { let p = "not a point".parse::<Point>(); assert_eq!(p, Err(ParsePointError)); } }
FromStr 与 TryFrom<&str> 具有相同的函数签名。先实现哪个特性无关紧要,因为我们可以利用先实现的特性实现后实现的特性。例如,我们假定 Point 类型已经实现了 FromStr 特性,再来实现 TryFrom<&str> 特性:
#![allow(unused)] fn main() { impl TryFrom<&str> for Point { type Error = <Point as FromStr>::Err; fn try_from(s: &str) -> Result<Point, Self::Error> { <Point as FromStr>::from_str(s) } } }
AsRef & AsMut
预备知识
#![allow(unused)] fn main() { trait AsRef<T: ?Sized> { fn as_ref(&self) -> &T; } trait AsMut<T: ?Sized> { fn as_mut(&mut self) -> &mut T; } }
AsRef 特性的存在很大程度上便捷了引用转换,其最常见的使用是为函数的引用类型的参数的传入提供方便:
#![allow(unused)] fn main() { // accepts: // - &str // - &String fn takes_str(s: &str) { // use &str } // accepts: // - &str // - &String // - String fn takes_asref_str<S: AsRef<str>>(s: S) { let s: &str = s.as_ref(); // use &str } fn example(slice: &str, borrow: &String, owned: String) { takes_str(slice); takes_str(borrow); takes_str(owned); // ❌ takes_asref_str(slice); takes_asref_str(borrow); takes_asref_str(owned); // ✅ } }
另外一个常见的使用是,返回一个包装类型的内部私有数据的引用(该类型用于保证内部私有数据的不变性)。标准库中的 String 就是对 Vec<u8> 的这样一种包装:
#![allow(unused)] fn main() { struct String { vec: Vec<u8>, } }
之所以不公开内部的 Vec 数据,是因为一旦允许用户随意修改内部数据,就有可能破环 String 有效的 UTF-8 编码。但是,对外开放一个只读的字节数组的引用是安全的,所以有如下实现:
#![allow(unused)] fn main() { impl AsRef<[u8]> for String; }
通常来讲我们不对类型实现 AsRef 特性,除非该类型包装了其它类型以提供额外的功能,或是对内部类型提供了不变性的保护。
以下是实现 AsRef 特性的一个反例:
#![allow(unused)] fn main() { struct User { name: String, age: u32, } impl AsRef<String> for User { fn as_ref(&self) -> &String { &self.name } } impl AsRef<u32> for User { fn as_ref(&self) -> &u32 { &self.age } } }
乍看起来这似乎有几分道理,但是当我们对 User 类型添加新的成员时,缺点就暴露出来了:
#![allow(unused)] fn main() { struct User { name: String, email: String, age: u32, height: u32, } impl AsRef<String> for User { fn as_ref(&self) -> &String { // uh, do we return name or email here? // 既然我们要返回一个字符串引用,那具体应该返回什么呢? // name 和 email 都是字符串,如何选择呢? // 出于返回类型的限制,似乎我们也难以返回一个混合的字符串。 } } impl AsRef<u32> for User { fn as_ref(&self) -> &u32 { // uh, do we return age or height here? // 如上同理 } } }
User 类型由多个 String 和 u32 类型的成员所组成,但我们也不能说 User 是 String 或 u32 吧?即便由更加具体的类型来构造也不行:
#![allow(unused)] fn main() { struct User { name: Name, email: Email, age: Age, height: Height, } }
对于 User 这样的类型来讲,实现 AsRef 特性并没有什么太多意义。因为 AsRef 的存在仅是为了做一种最简单的引用转换,这种转换最好存在于语义上相类似的事务之间。Name,Email,Age 和 Height 其本身和 User 就不是一回事,在逻辑上谈不上转换。
下例展示了 AsRef 特性的正确用法,我们实现了一个新的类型 Moderator,它仅仅是包装了 User 类型,并对其添加了权限控制:
#![allow(unused)] fn main() { struct User { name: String, age: u32, } // unfortunately the standard library cannot provide // a generic blanket impl to save us from this boilerplate // 不幸的是,标准库并没有提供相应的通用泛型实现,我们不得不手动实现 impl AsRef<User> for User { fn as_ref(&self) -> &User { self } } enum Privilege { BanUsers, EditPosts, DeletePosts, } // although Moderators have some special // privileges they are still regular Users // and should be able to do all the same stuff // 尽管主持人类具有一些特殊的权限, // 但其仍然是普通的用户 // 所有用户类能做到的主持人类也应能做到 struct Moderator { user: User, privileges: Vec<Privilege> } impl AsRef<Moderator> for Moderator { fn as_ref(&self) -> &Moderator { self } } impl AsRef<User> for Moderator { fn as_ref(&self) -> &User { &self.user } } // this should be callable with Users // and Moderators (who are also Users) // 这个函数的参数可以是 User 也可以是 Moderator // ( Moderator 也是 User ) fn create_post<U: AsRef<User>>(u: U) { let user = u.as_ref(); // etc } fn example(user: User, moderator: Moderator) { create_post(&user); create_post(&moderator); // ✅ } }
之所以可以这样做,是因为 Moderator 就是 User 。下例是将 Deref 一节中的例子使用 AsRef 做出替代:
#![allow(unused)] fn main() { use std::convert::AsRef; struct Human { health_points: u32, } impl AsRef<Human> for Human { fn as_ref(&self) -> &Human { self } } enum Weapon { Spear, Axe, Sword, } // a Soldier is just a Human with a Weapon // 士兵是手持武器的人类 struct Soldier { human: Human, weapon: Weapon, } impl AsRef<Soldier> for Soldier { fn as_ref(&self) -> &Soldier { self } } impl AsRef<Human> for Soldier { fn as_ref(&self) -> &Human { &self.human } } enum Mount { Horse, Donkey, Cow, } // a Knight is just a Soldier with a Mount // 骑士是胯骑坐骑的士兵 struct Knight { soldier: Soldier, mount: Mount, } impl AsRef<Knight> for Knight { fn as_ref(&self) -> &Knight { self } } impl AsRef<Soldier> for Knight { fn as_ref(&self) -> &Soldier { &self.soldier } } impl AsRef<Human> for Knight { fn as_ref(&self) -> &Human { &self.soldier.human } } enum Spell { MagicMissile, FireBolt, ThornWhip, } // a Mage is just a Human who can cast Spells // 法师是口诵咒语的人类 struct Mage { human: Human, spells: Vec<Spell>, } impl AsRef<Mage> for Mage { fn as_ref(&self) -> &Mage { self } } impl AsRef<Human> for Mage { fn as_ref(&self) -> &Human { &self.human } } enum Staff { Wooden, Metallic, Plastic, } // a Wizard is just a Mage with a Staff // 巫师是腰别法宝的法师 struct Wizard { mage: Mage, staff: Staff, } impl AsRef<Wizard> for Wizard { fn as_ref(&self) -> &Wizard { self } } impl AsRef<Mage> for Wizard { fn as_ref(&self) -> &Mage { &self.mage } } impl AsRef<Human> for Wizard { fn as_ref(&self) -> &Human { &self.mage.human } } fn borrows_human<H: AsRef<Human>>(human: H) {} fn borrows_soldier<S: AsRef<Soldier>>(soldier: S) {} fn borrows_knight<K: AsRef<Knight>>(knight: K) {} fn borrows_mage<M: AsRef<Mage>>(mage: M) {} fn borrows_wizard<W: AsRef<Wizard>>(wizard: W) {} fn example(human: Human, soldier: Soldier, knight: Knight, mage: Mage, wizard: Wizard) { // all types can be used as Humans borrows_human(&human); borrows_human(&soldier); borrows_human(&knight); borrows_human(&mage); borrows_human(&wizard); // Knights can be used as Soldiers borrows_soldier(&soldier); borrows_soldier(&knight); // Wizards can be used as Mages borrows_mage(&mage); borrows_mage(&wizard); // Knights & Wizards passed as themselves borrows_knight(&knight); borrows_wizard(&wizard); } }
之所以 Deref 在上例之前的版本中不可使用,是因为自动解引用是一种隐式的转换,这就为程序员错误地使用留下了巨大的空间。
而 AsRef 在上例中可以使用,是因为其实现的转换是显式的,这样很大程度上就消除了犯错误的空间。
Borrow & BorrowMut
预备知识
- Self
- Methods
- Generic Parameters
- Subtraits & Supertraits
- Sized
- AsRef & AsMut
- PartialEq & Eq
- Hash
- PartialOrd & Ord
#![allow(unused)] fn main() { trait Borrow<Borrowed> where Borrowed: ?Sized, { fn borrow(&self) -> &Borrowed; } trait BorrowMut<Borrowed>: Borrow<Borrowed> where Borrowed: ?Sized, { fn borrow_mut(&mut self) -> &mut Borrowed; } }
这类特性存在的意义旨在于解决特定领域的问题,例如在 Hashset,HashMap,BTreeSet,BtreeMap 中使用 &str 查询 String 类型的键。
我们可以将 Borrow<T> 和 BorrowMut<T> 视作 AsRef<T> 和 AsMut<T> 的严格版本,其返回的引用 &T 具有与 Self 相同的 Eq,Hash 和 Ord 的实现。这一点在下例的注释中得到很好的解释:
#![allow(unused)] fn main() { use std::borrow::Borrow; use std::hash::Hasher; use std::collections::hash_map::DefaultHasher; use std::hash::Hash; fn get_hash<T: Hash>(t: T) -> u64 { let mut hasher = DefaultHasher::new(); t.hash(&mut hasher); hasher.finish() } fn asref_example<Owned, Ref>(owned1: Owned, owned2: Owned) where Owned: Eq + Ord + Hash + AsRef<Ref>, Ref: Eq + Ord + Hash { let ref1: &Ref = owned1.as_ref(); let ref2: &Ref = owned2.as_ref(); // refs aren't required to be equal if owned types are equal // 值相等,不意味着其引用一定相等 assert_eq!(owned1 == owned2, ref1 == ref2); // ❌ let owned1_hash = get_hash(&owned1); let owned2_hash = get_hash(&owned2); let ref1_hash = get_hash(&ref1); let ref2_hash = get_hash(&ref2); // ref hashes aren't required to be equal if owned type hashes are equal // 值的哈希值相等,其引用不一定相等 assert_eq!(owned1_hash == owned2_hash, ref1_hash == ref2_hash); // ❌ // ref comparisons aren't required to match owned type comparisons // 值的比较,与其应用的比较没有必然联系 assert_eq!(owned1.cmp(&owned2), ref1.cmp(&ref2)); // ❌ } fn borrow_example<Owned, Borrowed>(owned1: Owned, owned2: Owned) where Owned: Eq + Ord + Hash + Borrow<Borrowed>, Borrowed: Eq + Ord + Hash { let borrow1: &Borrowed = owned1.borrow(); let borrow2: &Borrowed = owned2.borrow(); // borrows are required to be equal if owned types are equal // 值相等,借用值也必须相等 assert_eq!(owned1 == owned2, borrow1 == borrow2); // ✅ let owned1_hash = get_hash(&owned1); let owned2_hash = get_hash(&owned2); let borrow1_hash = get_hash(&borrow1); let borrow2_hash = get_hash(&borrow2); // borrow hashes are required to be equal if owned type hashes are equal // 值的哈希值相等,借用值的哈希值也必须相等 assert_eq!(owned1_hash == owned2_hash, borrow1_hash == borrow2_hash); // ✅ // borrow comparisons are required to match owned type comparisons // 值的比较,与借用值的比较必须步调一致 assert_eq!(owned1.cmp(&owned2), borrow1.cmp(&borrow2)); // ✅ } }
理解这类特性存在的意义,有助于我们揭开 HashSet,HashMap,BTreeSet 和 BTreeMap 中某些方法的实现的神秘面纱。但是在实际应用中,几乎没有什么地方需要我们去实现这样的特性,因为再难找到一个需要我们对一个值再创造一个“借用”版本的类型的场景了。对于某种类型 T ,&T 就能解决 99.9% 的问题了,且 T: Borrow<T> 已经被通用泛型实现对 T 实现了,所以我们无需手动实现它,也无需去实现某种的对 U 有 T: Borrow<U> 了。
ToOwned
预备知识
#![allow(unused)] fn main() { trait ToOwned { type Owned: Borrow<Self>; fn to_owned(&self) -> Self::Owned; // provided default impls // 提供默认实现 fn clone_into(&self, target: &mut Self::Owned); } }
ToOwned 特性是 Clone 特性的泛型版本。 Clone 特性允许我们由 &T 类型得到 T 类型,而 ToOwned 特性允许我们由 &Borrow 类型得到 Owned 类型,其中 Owned: Borrow<Borrowed> 。
换句话讲,我们不能将 &str 克隆为 String,将 &Path 克隆为 PathBuf 或将 &OsStr 克隆为 OsString 。鉴于 clone 方法的签名不支持这样跨类型的克隆,这就是 ToOwned 特性存在的意义。
与 Borrow 和 BorrowMut 相同地,理解此类特性存在的意义对我们或有帮助,但是鲜少需要我们手动为自己的类实现该特性。
迭代特性
Iterator
预备知识
#![allow(unused)] fn main() { trait Iterator { type Item; fn next(&mut self) -> Option<Self::Item>; // provided default impls // 提供默认实现 fn size_hint(&self) -> (usize, Option<usize>); fn count(self) -> usize; fn last(self) -> Option<Self::Item>; fn advance_by(&mut self, n: usize) -> Result<(), usize>; fn nth(&mut self, n: usize) -> Option<Self::Item>; fn step_by(self, step: usize) -> StepBy<Self>; fn chain<U>( self, other: U ) -> Chain<Self, <U as IntoIterator>::IntoIter> where U: IntoIterator<Item = Self::Item>; fn zip<U>(self, other: U) -> Zip<Self, <U as IntoIterator>::IntoIter> where U: IntoIterator; fn map<B, F>(self, f: F) -> Map<Self, F> where F: FnMut(Self::Item) -> B; fn for_each<F>(self, f: F) where F: FnMut(Self::Item); fn filter<P>(self, predicate: P) -> Filter<Self, P> where P: FnMut(&Self::Item) -> bool; fn filter_map<B, F>(self, f: F) -> FilterMap<Self, F> where F: FnMut(Self::Item) -> Option<B>; fn enumerate(self) -> Enumerate<Self>; fn peekable(self) -> Peekable<Self>; fn skip_while<P>(self, predicate: P) -> SkipWhile<Self, P> where P: FnMut(&Self::Item) -> bool; fn take_while<P>(self, predicate: P) -> TakeWhile<Self, P> where P: FnMut(&Self::Item) -> bool; fn map_while<B, P>(self, predicate: P) -> MapWhile<Self, P> where P: FnMut(Self::Item) -> Option<B>; fn skip(self, n: usize) -> Skip<Self>; fn take(self, n: usize) -> Take<Self>; fn scan<St, B, F>(self, initial_state: St, f: F) -> Scan<Self, St, F> where F: FnMut(&mut St, Self::Item) -> Option<B>; fn flat_map<U, F>(self, f: F) -> FlatMap<Self, U, F> where F: FnMut(Self::Item) -> U, U: IntoIterator; fn flatten(self) -> Flatten<Self> where Self::Item: IntoIterator; fn fuse(self) -> Fuse<Self>; fn inspect<F>(self, f: F) -> Inspect<Self, F> where F: FnMut(&Self::Item); fn by_ref(&mut self) -> &mut Self; fn collect<B>(self) -> B where B: FromIterator<Self::Item>; fn partition<B, F>(self, f: F) -> (B, B) where F: FnMut(&Self::Item) -> bool, B: Default + Extend<Self::Item>; fn partition_in_place<'a, T, P>(self, predicate: P) -> usize where Self: DoubleEndedIterator<Item = &'a mut T>, T: 'a, P: FnMut(&T) -> bool; fn is_partitioned<P>(self, predicate: P) -> bool where P: FnMut(Self::Item) -> bool; fn try_fold<B, F, R>(&mut self, init: B, f: F) -> R where F: FnMut(B, Self::Item) -> R, R: Try<Ok = B>; fn try_for_each<F, R>(&mut self, f: F) -> R where F: FnMut(Self::Item) -> R, R: Try<Ok = ()>; fn fold<B, F>(self, init: B, f: F) -> B where F: FnMut(B, Self::Item) -> B; fn fold_first<F>(self, f: F) -> Option<Self::Item> where F: FnMut(Self::Item, Self::Item) -> Self::Item; fn all<F>(&mut self, f: F) -> bool where F: FnMut(Self::Item) -> bool; fn any<F>(&mut self, f: F) -> bool where F: FnMut(Self::Item) -> bool; fn find<P>(&mut self, predicate: P) -> Option<Self::Item> where P: FnMut(&Self::Item) -> bool; fn find_map<B, F>(&mut self, f: F) -> Option<B> where F: FnMut(Self::Item) -> Option<B>; fn try_find<F, R>( &mut self, f: F ) -> Result<Option<Self::Item>, <R as Try>::Error> where F: FnMut(&Self::Item) -> R, R: Try<Ok = bool>; fn position<P>(&mut self, predicate: P) -> Option<usize> where P: FnMut(Self::Item) -> bool; fn rposition<P>(&mut self, predicate: P) -> Option<usize> where Self: ExactSizeIterator + DoubleEndedIterator, P: FnMut(Self::Item) -> bool; fn max(self) -> Option<Self::Item> where Self::Item: Ord; fn min(self) -> Option<Self::Item> where Self::Item: Ord; fn max_by_key<B, F>(self, f: F) -> Option<Self::Item> where F: FnMut(&Self::Item) -> B, B: Ord; fn max_by<F>(self, compare: F) -> Option<Self::Item> where F: FnMut(&Self::Item, &Self::Item) -> Ordering; fn min_by_key<B, F>(self, f: F) -> Option<Self::Item> where F: FnMut(&Self::Item) -> B, B: Ord; fn min_by<F>(self, compare: F) -> Option<Self::Item> where F: FnMut(&Self::Item, &Self::Item) -> Ordering; fn rev(self) -> Rev<Self> where Self: DoubleEndedIterator; fn unzip<A, B, FromA, FromB>(self) -> (FromA, FromB) where Self: Iterator<Item = (A, B)>, FromA: Default + Extend<A>, FromB: Default + Extend<B>; fn copied<'a, T>(self) -> Copied<Self> where Self: Iterator<Item = &'a T>, T: 'a + Copy; fn cloned<'a, T>(self) -> Cloned<Self> where Self: Iterator<Item = &'a T>, T: 'a + Clone; fn cycle(self) -> Cycle<Self> where Self: Clone; fn sum<S>(self) -> S where S: Sum<Self::Item>; fn product<P>(self) -> P where P: Product<Self::Item>; fn cmp<I>(self, other: I) -> Ordering where I: IntoIterator<Item = Self::Item>, Self::Item: Ord; fn cmp_by<I, F>(self, other: I, cmp: F) -> Ordering where F: FnMut(Self::Item, <I as IntoIterator>::Item) -> Ordering, I: IntoIterator; fn partial_cmp<I>(self, other: I) -> Option<Ordering> where I: IntoIterator, Self::Item: PartialOrd<<I as IntoIterator>::Item>; fn partial_cmp_by<I, F>( self, other: I, partial_cmp: F ) -> Option<Ordering> where F: FnMut(Self::Item, <I as IntoIterator>::Item) -> Option<Ordering>, I: IntoIterator; fn eq<I>(self, other: I) -> bool where I: IntoIterator, Self::Item: PartialEq<<I as IntoIterator>::Item>; fn eq_by<I, F>(self, other: I, eq: F) -> bool where F: FnMut(Self::Item, <I as IntoIterator>::Item) -> bool, I: IntoIterator; fn ne<I>(self, other: I) -> bool where I: IntoIterator, Self::Item: PartialEq<<I as IntoIterator>::Item>; fn lt<I>(self, other: I) -> bool where I: IntoIterator, Self::Item: PartialOrd<<I as IntoIterator>::Item>; fn le<I>(self, other: I) -> bool where I: IntoIterator, Self::Item: PartialOrd<<I as IntoIterator>::Item>; fn gt<I>(self, other: I) -> bool where I: IntoIterator, Self::Item: PartialOrd<<I as IntoIterator>::Item>; fn ge<I>(self, other: I) -> bool where I: IntoIterator, Self::Item: PartialOrd<<I as IntoIterator>::Item>; fn is_sorted(self) -> bool where Self::Item: PartialOrd<Self::Item>; fn is_sorted_by<F>(self, compare: F) -> bool where F: FnMut(&Self::Item, &Self::Item) -> Option<Ordering>; fn is_sorted_by_key<F, K>(self, f: F) -> bool where F: FnMut(Self::Item) -> K, K: PartialOrd<K>; } }
实现 Iterator<Item = T> 的类型可以迭代产生 T 类型。注意:并不存在 IteratorMut 类型,因为可以通过在实现 Iterator 特性时指定 Item 关联类型,来选择其返回的是不可变引用、可变引用还是自有值。
Vec<T> 方法 | 返回类型 |
|---|---|
.iter() | Iterator<Item = &T> |
.iter_mut() | Iterator<Item = &mut T> |
.into_iter() | Iterator<Item = T> |
对于 Rust 的初学者而言可能有些费解,但是对于中级学习者而言则是顺理成章的一件事是 —— 绝大多数类型并不是自己的迭代器。这意味着,如果某种类型是可迭代的,那么应当实现某种额外的迭代器类型去迭代它,而不是让它自己迭代自己。
#![allow(unused)] fn main() { struct MyType { items: Vec<String> } impl MyType { fn iter(&self) -> impl Iterator<Item = &String> { MyTypeIterator { index: 0, items: &self.items } } } struct MyTypeIterator<'a> { index: usize, items: &'a Vec<String> } impl<'a> Iterator for MyTypeIterator<'a> { type Item = &'a String; fn next(&mut self) -> Option<Self::Item> { if self.index >= self.items.len() { None } else { let item = &self.items[self.index]; self.index += 1; Some(item) } } } }
出于教学的原因,我们在上例中从头手动实现了一个迭代器。而在这种情况下,最理想的做法是直接调用 Vec 的 iter 方法。
#![allow(unused)] fn main() { struct MyType { items: Vec<String> } impl MyType { fn iter(&self) -> impl Iterator<Item = &String> { self.items.iter() } } }
另外,最好了解这个通用泛型实现:
#![allow(unused)] fn main() { impl<I: Iterator + ?Sized> Iterator for &mut I; }
任何迭代器的可变引用也是一个迭代器。了解这样的性质有助于我们理解,为什么可以将迭代器的某些参数为 self 的方法当作具有 &mut self 参数的方法来使用。
举个例子,想象我们有这样一个函数,它处理一个具有三个以上值的迭代器,这个函数首先要取得该迭代器的前三个值并分别地处理他们,然后再依次迭代剩余的值。初学者可能会这样实现该函数:
#![allow(unused)] fn main() { fn example<I: Iterator<Item = i32>>(mut iter: I) { let first3: Vec<i32> = iter.take(3).collect(); for item in iter { // ❌ iter consumed in line above // ❌ iter 在上一行就已经被消耗掉了 // process remaining items // 处理剩余的值 } } }
糟糕,take 方法具有 self 参数,这意味着我们不能在不消耗掉整个迭代器的前提下调用该方法。以下可能是一个初学者的改进:
#![allow(unused)] fn main() { fn example<I: Iterator<Item = i32>>(mut iter: I) { let first3: Vec<i32> = vec![ iter.next().unwrap(), iter.next().unwrap(), iter.next().unwrap(), ]; for item in iter { // ✅ // process remaining items // 处理剩余的值 } } }
这是可行的,但是理想的改进方式莫过于:
#![allow(unused)] fn main() { fn example<I: Iterator<Item = i32>>(mut iter: I) { let first3: Vec<i32> = iter.by_ref().take(3).collect(); for item in iter { // ✅ // process remaining items // 处理剩余的值 } } }
这真是一个很隐蔽的方法,但是被我们抓到了。
同样,对于什么可以是迭代器,什么不可以是,并无一定之规。实现了 Iterator 特性的就是迭代器。而在标准库中,确有一些具有创造性的用例:
#![allow(unused)] fn main() { use std::sync::mpsc::channel; use std::thread; fn paths_can_be_iterated(path: &Path) { for part in path { // iterate over parts of a path // 迭代 path 的不同部分 } } fn receivers_can_be_iterated() { let (send, recv) = channel(); thread::spawn(move || { send.send(1).unwrap(); send.send(2).unwrap(); send.send(3).unwrap(); }); for received in recv { // iterate over received values // 迭代接收到的值 } } }
IntoIterator
预备知识
#![allow(unused)] fn main() { trait IntoIterator where <Self::IntoIter as Iterator>::Item == Self::Item, { type Item; type IntoIter: Iterator; fn into_iter(self) -> Self::IntoIter; } }
闻弦歌而知雅意,实现 IntoIterator 特性的类型可以被转换为迭代器。当用于 for-in 循环时,将自动调用该类型的 into_iter 方法.
#![allow(unused)] fn main() { // vec = Vec<T> for v in vec {} // v = T // above line desugared // 以上代码等价于 for v in vec.into_iter() {} }
不仅 Vec 实现了 IntoIterator 特性,&Vec 与 &mut Vec 同样如此。因此我们可以相应的对可变与不可变的引用,以及自有值进行迭代。
#![allow(unused)] fn main() { // vec = Vec<T> for v in &vec {} // v = &T // above example desugared // 以上代码等价于 for v in (&vec).into_iter() {} // vec = Vec<T> for v in &mut vec {} // v = &mut T // above example desugared // 以上代码等价于 for v in (&mut vec).into_iter() {} }
FromIterator
预备知识
#![allow(unused)] fn main() { trait FromIterator<A> { fn from_iter<T>(iter: T) -> Self where T: IntoIterator<Item = A>; } }
顾叶落而晓秋至,实现 FromIterator 特性的类型可以由迭代器而构造。FromIterator 特性最常见和最理想的使用方法是调用 Iterator 的 collect 方法:
#![allow(unused)] fn main() { fn collect<B>(self) -> B where B: FromIterator<Self::Item>; }
下例展示了如何将 Iterator<Item = char> 迭代器的值收集为 String :
#![allow(unused)] fn main() { fn filter_letters(string: &str) -> String { string.chars().filter(|c| c.is_alphabetic()).collect() } }
标准库中的全部集合类型都实现了 IntoIterator 和 FromIterator 特性,所以在它们之间进行转换是很方便的:
#![allow(unused)] fn main() { use std::collections::{BTreeSet, HashMap, HashSet, LinkedList}; // String -> HashSet<char> fn unique_chars(string: &str) -> HashSet<char> { string.chars().collect() } // Vec<T> -> BTreeSet<T> fn ordered_unique_items<T: Ord>(vec: Vec<T>) -> BTreeSet<T> { vec.into_iter().collect() } // HashMap<K, V> -> LinkedList<(K, V)> fn entry_list<K, V>(map: HashMap<K, V>) -> LinkedList<(K, V)> { map.into_iter().collect() } // and countless more possible examples // 还有数不胜数的例子 }
输入输出特性 I/O Traits
Read & Write
预备知识
#![allow(unused)] fn main() { trait Read { fn read(&mut self, buf: &mut [u8]) -> Result<usize>; // provided default impls // 提供默认实现 fn read_vectored(&mut self, bufs: &mut [IoSliceMut<'_>]) -> Result<usize>; fn is_read_vectored(&self) -> bool; unsafe fn initializer(&self) -> Initializer; fn read_to_end(&mut self, buf: &mut Vec<u8>) -> Result<usize>; fn read_to_string(&mut self, buf: &mut String) -> Result<usize>; fn read_exact(&mut self, buf: &mut [u8]) -> Result<()>; fn by_ref(&mut self) -> &mut Self where Self: Sized; fn bytes(self) -> Bytes<Self> where Self: Sized; fn chain<R: Read>(self, next: R) -> Chain<Self, R> where Self: Sized; fn take(self, limit: u64) -> Take<Self> where Self: Sized; } trait Write { fn write(&mut self, buf: &[u8]) -> Result<usize>; fn flush(&mut self) -> Result<()>; // provided default impls // 提供默认实现 fn write_vectored(&mut self, bufs: &[IoSlice<'_>]) -> Result<usize>; fn is_write_vectored(&self) -> bool; fn write_all(&mut self, buf: &[u8]) -> Result<()>; fn write_all_vectored(&mut self, bufs: &mut [IoSlice<'_>]) -> Result<()>; fn write_fmt(&mut self, fmt: Arguments<'_>) -> Result<()>; fn by_ref(&mut self) -> &mut Self where Self: Sized; } }
Generic blanket impls worth knowing:
值得关注的通用泛型实现:
#![allow(unused)] fn main() { impl<R: Read + ?Sized> Read for &mut R; impl<W: Write + ?Sized> Write for &mut W; }
对于任何实现了 Read 特性的类型,其可变的引用类型也实现了 Read 特性。Write 也是如此。知晓这一点有助于我们理解为什么,对于具有 self 参数的函数可以如同那些具有 &mut self 参数的函数一般使用。鉴于我们已经在 Iterator 特性一节中做出了相近的说明,对此我不再赘述。
我特别指出的是,在 &[u8] 实现 Read 的同时,Vec<u8> 实现了 Write,因此我们可以很方便地使用 String 来对我们的文件处理函数进行单元测试,因为它可以轻易地转换到 &[u8] 和转换自 Vec<u8> 。
#![allow(unused)] fn main() { use std::path::Path; use std::fs::File; use std::io::Read; use std::io::Write; use std::io; // function we want to test // 欲要测试此函数 fn uppercase<R: Read, W: Write>(mut read: R, mut write: W) -> Result<(), io::Error> { let mut buffer = String::new(); read.read_to_string(&mut buffer)?; let uppercase = buffer.to_uppercase(); write.write_all(uppercase.as_bytes())?; write.flush()?; Ok(()) } // in actual program we'd pass Files // 实际使用中我们传入文件 fn example(in_path: &Path, out_path: &Path) -> Result<(), io::Error> { let in_file = File::open(in_path)?; let out_file = File::open(out_path)?; uppercase(in_file, out_file) } // however in unit tests we can use Strings! // 但是在单元测试中我们使用 String ! #[test] // ✅ fn example_test() { let in_file: String = "i am screaming".into(); let mut out_file: Vec<u8> = Vec::new(); uppercase(in_file.as_bytes(), &mut out_file).unwrap(); let out_result = String::from_utf8(out_file).unwrap(); assert_eq!(out_result, "I AM SCREAMING"); } }
结语 Conclusion
We learned a lot together! Too much in fact. This is us now:
我们真是学习了太多!太多了!可能这就是我们现在的样子:

该漫画的创作者: The Jenkins Comic
讨论 Discuss
Discuss this article on
可以在如下地点讨论本文
通告 Notifications
Get notified when the next blog post get published by
在如下处得知我下一篇博文的详情
- 订阅我的推特 pretzelhammer 或者
- 订阅这个 repo (点击
Watch-> 点击Custom-> 选择Releases-> 点击Apply)
更多资料 Further Reading
- Sizedness in Rust
- Common Rust Lifetime Misconceptions
- Learning Rust in 2020
- Learn Assembly with Entirely Too Many Brainfuck Compilers
翻译 Translation
鉴于水平所限,
难免出现翻译错误,
如发现错误还请告知!
Rust 中的宏:带有示例的教程

在本篇教程中,我们将介绍有关 Rust 宏的全部内容,包括 Rust 中宏的引入以及在示例中演示如何使用 Rust 宏。
我们将包含一下内容:
什么是 Rust 中的宏?
Rust 对宏提供了出色的支持。使用宏可以编写代码,该代码可以在编译期间生成其他的代码,这被称为元编程。
宏提供了类似于函数的功能,却没有运行时成本。但是,由于在编译期间扩展了宏,因此存在一些编译时的开销。
Rust 的宏与 C 中的宏有很大的不同。Rust 宏可以应用于 token 树,但是 C 宏只能用于文本替换 (substitution)。
Rust 宏的类型
Rust 宏有两种类型:
- 声明式宏:使你能够编写类似于在 Rust 代码中作为参数运行的 match 表达式。它使用你提供的代码生成可以替换宏调用的代码。
- 过程宏:使你能够在 Rust 代码的抽象语法树 (AST) 上进行操作。过程宏是从一个(或两个)
TokenStream到另一个TokenStream的函数,其输出替换宏调用。
让我们深入学习声明式宏与过程宏,并探讨一些示例,学习如何在 Rust 中使用宏。
Rust 中的声明式宏
声明式宏通过macro_rules!来定义。声明式宏的功能性稍微差一些,但是提供了易于使用的接口来创建宏以移除重复的代码。常见的声明式宏如println!。声明式宏提供了类似 match 的接口,在匹配时,宏会被替换为对应的匹配分支内的代码。
创建声明式宏
// use macro_rules! <name of macro>{<Body>} macro_rules! add{ // macth like arm for macro (<span class="katex"><span class="katex-html" aria-hidden="true"><span class="base"><span class="strut" style="height:0.43056em;vertical-align:0em;"></span><span class="mord mathnormal">a</span><span class="mspace" style="margin-right:0.2777777777777778em;"></span><span class="mrel">:</span><span class="mspace" style="margin-right:0.2777777777777778em;"></span></span><span class="base"><span class="strut" style="height:0.625em;vertical-align:-0.19444em;"></span><span class="mord mathnormal">e</span><span class="mord mathnormal">x</span><span class="mord mathnormal">p</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mpunct">,</span></span></span></span>b:expr)=>{ // macro expand to this code { // <span class="katex"><span class="katex-html" aria-hidden="true"><span class="base"><span class="strut" style="height:0.69444em;vertical-align:0em;"></span><span class="mord mathnormal">aan</span><span class="mord mathnormal">d</span></span></span></span>b will be templated using the value/variable provided to macro <span class="katex"><span class="katex-html" aria-hidden="true"><span class="base"><span class="strut" style="height:0.66666em;vertical-align:-0.08333em;"></span><span class="mord mathnormal">a</span><span class="mord">+</span></span></span></span>b } } } fn main(){ // call to macro, <span class="katex"><span class="katex-html" aria-hidden="true"><span class="base"><span class="strut" style="height:0.43056em;vertical-align:0em;"></span><span class="mord mathnormal">a</span><span class="mspace" style="margin-right:0.2777777777777778em;"></span><span class="mrel">=</span><span class="mspace" style="margin-right:0.2777777777777778em;"></span></span><span class="base"><span class="strut" style="height:0.69444em;vertical-align:0em;"></span><span class="mord">1</span><span class="mord mathnormal">an</span><span class="mord mathnormal">d</span></span></span></span>b=2 add!(1,2); }
这段代码创建了一个可以将两个数相加的宏。[macro_rules!]与宏的名称,add以及宏的主体一起使用。
这个宏并没有将两个数相加,它只是将自己替换成了将两个数相加的代码。宏的每一个分支都携带了对应功能需要的参数,并且有多种类型可以分配给参数。如果add函数也可以采用单个参数,我们可以添加另一个分支:
macro_rules! add{ // first arm match add!(1,2), add!(2,3) etc (<span class="katex"><span class="katex-html" aria-hidden="true"><span class="base"><span class="strut" style="height:0.43056em;vertical-align:0em;"></span><span class="mord mathnormal">a</span><span class="mspace" style="margin-right:0.2777777777777778em;"></span><span class="mrel">:</span><span class="mspace" style="margin-right:0.2777777777777778em;"></span></span><span class="base"><span class="strut" style="height:0.625em;vertical-align:-0.19444em;"></span><span class="mord mathnormal">e</span><span class="mord mathnormal">x</span><span class="mord mathnormal">p</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mpunct">,</span></span></span></span>b:expr)=>{ { <span class="katex"><span class="katex-html" aria-hidden="true"><span class="base"><span class="strut" style="height:0.66666em;vertical-align:-0.08333em;"></span><span class="mord mathnormal">a</span><span class="mord">+</span></span></span></span>b } }; // Second arm macth add!(1), add!(2) etc (a:expr)=>{ { a } } } fn main(){ // call the macro let x=0; add!(1,2); add!(x); }
一个宏中可以有多个分支,可以根据不同的参数扩展为不同的代码。每个分支可以采用多个参数,以``符号开头,后跟 token 的类型。
item- 项,如:函数,结构体,模块等block- 块 (语句或表达式的代码块,被大括号包含)stmt- 语句pat- 模式expr- 表达式ty- 类型ident- 标识符path- 路径(如:foo,::std::mem::replace,transmute::<_, int>,...)meta- 元项 (meta item),即#[...]和#![...]属性中的内容tt- 单个 token 树vis- 可能为空的可见性 (Visibility) 限定词lifetime- 生命周期literal- 字面量表达式
在本例中,我们使用 token 类型为ty的typ参数作为数据类型,如u8,u16等。在数字相加之前,这个宏会将其转换为指定的类型。
macro_rules! add_as{ // using a ty token type for macthing datatypes passed to maccro (<span class="katex"><span class="katex-html" aria-hidden="true"><span class="base"><span class="strut" style="height:0.43056em;vertical-align:0em;"></span><span class="mord mathnormal">a</span><span class="mspace" style="margin-right:0.2777777777777778em;"></span><span class="mrel">:</span><span class="mspace" style="margin-right:0.2777777777777778em;"></span></span><span class="base"><span class="strut" style="height:0.625em;vertical-align:-0.19444em;"></span><span class="mord mathnormal">e</span><span class="mord mathnormal">x</span><span class="mord mathnormal">p</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mpunct">,</span></span></span></span>b:expr,typ:ty)=>{ a as <span class="katex"><span class="katex-html" aria-hidden="true"><span class="base"><span class="strut" style="height:0.80952em;vertical-align:-0.19444em;"></span><span class="mord mathnormal">t</span><span class="mord mathnormal" style="margin-right:0.03588em;">y</span><span class="mord mathnormal">p</span><span class="mord">+</span></span></span></span>b as typ } } fn main(){ println!("{}",add_as!(0,2,u8)); }
Rust 宏还支持传入非固定数量的参数。运算符和正则表达式非常类似。*用于 0 个或多个 token 类型,+用于 0 个或 1 个参数。
macro_rules! add_as{ ( // repeated block (a:expr) // seperator , // zero or more * )=>{ { // to handle the case without any arguments 0 // block to be repeated (+a)* } } } fn main(){ println!("{}",add_as!(1,2,3,4)); // => println!("{}",{0+1+2+3+4}) }
重复的 token 类型包含在()中,后面跟一个分隔符以及一个*或者+,表示 token 将要重复的次数。分隔符用来区分彼此的 token。后面跟*或+的<span class="katex"><span class="katex-html" aria-hidden="true"><span class="base"><span class="strut" style="height:1em;vertical-align:-0.25em;"></span><span class="mopen">(</span><span class="mclose">)</span><span class="mord">‘</span><span class="mord cjk_fallback">用于表示重复的代码块。在上面的示例中,</span><span class="mord">‘</span><span class="mord">+</span></span></span></span>a是需要重复的代码。
如果你仔细看这段代码,你会发现代码中添加了一个额外的 0 来使语法有效。要删除这个 0 并使add表达式和参数一样,我们需要创建一个名为 TT muncher 的新宏。
macro_rules! add{ // first arm in case of single argument and last remaining variable/number (a:expr)=>{ a }; // second arm in case of two arument are passed and stop recursion in case of odd number ofarguments (<span class="katex"><span class="katex-html" aria-hidden="true"><span class="base"><span class="strut" style="height:0.43056em;vertical-align:0em;"></span><span class="mord mathnormal">a</span><span class="mspace" style="margin-right:0.2777777777777778em;"></span><span class="mrel">:</span><span class="mspace" style="margin-right:0.2777777777777778em;"></span></span><span class="base"><span class="strut" style="height:0.625em;vertical-align:-0.19444em;"></span><span class="mord mathnormal">e</span><span class="mord mathnormal">x</span><span class="mord mathnormal">p</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mpunct">,</span></span></span></span>b:expr)=>{ { <span class="katex"><span class="katex-html" aria-hidden="true"><span class="base"><span class="strut" style="height:0.66666em;vertical-align:-0.08333em;"></span><span class="mord mathnormal">a</span><span class="mord">+</span></span></span></span>b } }; // add the number and the result of remaining arguments (<span class="katex"><span class="katex-html" aria-hidden="true"><span class="base"><span class="strut" style="height:0.43056em;vertical-align:0em;"></span><span class="mord mathnormal">a</span><span class="mspace" style="margin-right:0.2777777777777778em;"></span><span class="mrel">:</span><span class="mspace" style="margin-right:0.2777777777777778em;"></span></span><span class="base"><span class="strut" style="height:0.625em;vertical-align:-0.19444em;"></span><span class="mord mathnormal">e</span><span class="mord mathnormal">x</span><span class="mord mathnormal">p</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mpunct">,</span></span></span></span>(b:tt)*)=>{ { a+add!(<span class="katex"><span class="katex-html" aria-hidden="true"><span class="base"><span class="strut" style="height:1em;vertical-align:-0.25em;"></span><span class="mopen">(</span></span></span></span>b)*) } } } fn main(){ println!("{}",add!(1,2,3,4)); }
TT muncher 递归式的分别处理每个 token。一次处理一个 token 比较容易。这个宏有三个分支:
- 第一个分支处理传入单个参数的情况
- 第二个分支处理传入两个参数的情况
- 第三个分支通过传入剩余的参数再次调用
add宏
宏参数不需要逗号分隔符。多个 token 可以使用不同的 token 类型。举个例子,括号可以与ident token 类型一起使用。Rust 编译器采用匹配的分支,并从参数字符串中提取变量。
macro_rules! ok_or_return{ // match something(q,r,t,6,7,8) etc // compiler extracts function name and arguments. It injects the values in respective varibles. (<span class="katex"><span class="katex-html" aria-hidden="true"><span class="base"><span class="strut" style="height:0.43056em;vertical-align:0em;"></span><span class="mord mathnormal">a</span><span class="mspace" style="margin-right:0.2777777777777778em;"></span><span class="mrel">:</span><span class="mspace" style="margin-right:0.2777777777777778em;"></span></span><span class="base"><span class="strut" style="height:1em;vertical-align:-0.25em;"></span><span class="mord mathnormal">i</span><span class="mord mathnormal">d</span><span class="mord mathnormal">e</span><span class="mord mathnormal">n</span><span class="mord mathnormal">t</span><span class="mopen">(</span></span></span></span>(b:tt)*))=>{ { match a(<span class="katex"><span class="katex-html" aria-hidden="true"><span class="base"><span class="strut" style="height:1em;vertical-align:-0.25em;"></span><span class="mopen">(</span></span></span></span>b)*) { Ok(value)=>value, Err(err)=>{ return Err(err); } } } }; } fn some_work(i:i64,j:i64)->Result<(i64,i64),String>{ if i+j>2 { Ok((i,j)) } else { Err("error".to_owned()) } } fn main()->Result<(),String>{ ok_or_return!(some_work(1,4)); ok_or_return!(some_work(1,0)); Ok(()) }
如果某个操作返回Err或者某个操作的值返回Ok,则ok_or_return宏返回该函数。它将函数作为一个参数并在内部的 match 语句中执行。对于传递给函数的参数,它重复的使用。
通常,需要将几个宏放在同一个宏分组中。在本例中,使用了内部的宏规则。它有助于操作宏输入并编写干净的 TT muncher。
为了创建一个内部规则,添加一个以@开头的规则名作为参数。现在,除非明确将其指定为参数,否则该宏将永远不会匹配内部规则。
macro_rules! ok_or_return{ // internal rule. (@error <span class="katex"><span class="katex-html" aria-hidden="true"><span class="base"><span class="strut" style="height:0.43056em;vertical-align:0em;"></span><span class="mord mathnormal">a</span><span class="mspace" style="margin-right:0.2777777777777778em;"></span><span class="mrel">:</span><span class="mspace" style="margin-right:0.2777777777777778em;"></span></span><span class="base"><span class="strut" style="height:0.8888799999999999em;vertical-align:-0.19444em;"></span><span class="mord mathnormal">i</span><span class="mord mathnormal">d</span><span class="mord mathnormal">e</span><span class="mord mathnormal">n</span><span class="mord mathnormal">t</span><span class="mpunct">,</span></span></span></span>(b:tt)* )=>{ { match a(<span class="katex"><span class="katex-html" aria-hidden="true"><span class="base"><span class="strut" style="height:1em;vertical-align:-0.25em;"></span><span class="mopen">(</span></span></span></span>b)*) { Ok(value)=>value, Err(err)=>{ return Err(err); } } } }; // public rule can be called by the user. (<span class="katex"><span class="katex-html" aria-hidden="true"><span class="base"><span class="strut" style="height:0.43056em;vertical-align:0em;"></span><span class="mord mathnormal">a</span><span class="mspace" style="margin-right:0.2777777777777778em;"></span><span class="mrel">:</span><span class="mspace" style="margin-right:0.2777777777777778em;"></span></span><span class="base"><span class="strut" style="height:1em;vertical-align:-0.25em;"></span><span class="mord mathnormal">i</span><span class="mord mathnormal">d</span><span class="mord mathnormal">e</span><span class="mord mathnormal">n</span><span class="mord mathnormal">t</span><span class="mopen">(</span></span></span></span>(b:tt)*))=>{ ok_or_return!(@error a,<span class="katex"><span class="katex-html" aria-hidden="true"><span class="base"><span class="strut" style="height:1em;vertical-align:-0.25em;"></span><span class="mopen">(</span></span></span></span>b)*) }; } fn some_work(i:i64,j:i64)->Result<(i64,i64),String>{ if i+j>2 { Ok((i,j)) } else { Err("error".to_owned()) } } fn main()->Result<(),String>{ // instead of round bracket curly brackets can also be used ok_or_return!{some_work(1,4)}; ok_or_return!(some_work(1,0)); Ok(()) }
Rust 中声明式宏的高级解析
宏有时会执行需要解析 Rust 语言本身的任务。
将到目前为止我们已经介绍的概念放在一起,创建一个宏,该宏通过使pub关键字作为前缀,将结构体的可见性设置为公开。
首先,我们需要解析 Rust 结构体以获取它的名称,字段以及字段类型。
解析结构体的名称和字段
结构体的声明开头有一个可见性关键字(如pub),后面跟struct关键字,接着是结构体的名称,最后是结构体的主体。
#![allow(unused)] fn main() { macro_rules! make_public{ ( // use vis type for visibility keyword and ident for struct name <span class="katex"><span class="katex-html" aria-hidden="true"><span class="base"><span class="strut" style="height:0.65952em;vertical-align:0em;"></span><span class="mord mathnormal" style="margin-right:0.03588em;">v</span><span class="mord mathnormal">i</span><span class="mord mathnormal">s</span><span class="mspace" style="margin-right:0.2777777777777778em;"></span><span class="mrel">:</span><span class="mspace" style="margin-right:0.2777777777777778em;"></span></span><span class="base"><span class="strut" style="height:0.65952em;vertical-align:0em;"></span><span class="mord mathnormal" style="margin-right:0.03588em;">v</span><span class="mord mathnormal">i</span><span class="mord mathnormal">ss</span><span class="mord mathnormal">t</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal">u</span><span class="mord mathnormal">c</span><span class="mord mathnormal">t</span></span></span></span>struct_name:ident { } ) => { { pub struct struct_name{ } } } } }
vis对应可见性,<span class="katex"><span class="katex-html" aria-hidden="true"><span class="base"><span class="strut" style="height:0.8888799999999999em;vertical-align:-0.19444em;"></span><span class="mord mathnormal">s</span><span class="mord mathnormal">t</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal">u</span><span class="mord mathnormal">c</span><span class="mord"><span class="mord mathnormal">t</span><span class="msupsub"><span class="vlist-t vlist-t2"><span class="vlist-r"><span class="vlist" style="height:0.151392em;"><span style="top:-2.5500000000000003em;margin-left:0em;margin-right:0.05em;"><span class="pstrut" style="height:2.7em;"></span><span class="sizing reset-size6 size3 mtight"><span class="mord mathnormal mtight">n</span></span></span></span><span class="vlist-s"></span></span><span class="vlist-r"><span class="vlist" style="height:0.15em;"><span></span></span></span></span></span></span><span class="mord mathnormal">am</span><span class="mord mathnormal">e</span><span class="mord">‘</span><span class="mord cjk_fallback">对应结构体的名称。为了使结构体是外部可见的,我们需要添加</span><span class="mord">‘</span><span class="mord mathnormal">p</span><span class="mord mathnormal">u</span><span class="mord mathnormal">b</span><span class="mord">‘</span><span class="mord cjk_fallback">关键字并忽略</span><span class="mord">‘</span></span></span></span>vis变量。
一个结构体中可能包含多个字段,这些字段可能具有相同或不同的数据类型以及可见性。ty token 类型用于数据类型,vis 用于可见性以及ident用于字段名。我们将使用*来重复表示 0 个或多个字段。
#![allow(unused)] fn main() { macro_rules! make_public{ ( <span class="katex"><span class="katex-html" aria-hidden="true"><span class="base"><span class="strut" style="height:0.65952em;vertical-align:0em;"></span><span class="mord mathnormal" style="margin-right:0.03588em;">v</span><span class="mord mathnormal">i</span><span class="mord mathnormal">s</span><span class="mspace" style="margin-right:0.2777777777777778em;"></span><span class="mrel">:</span><span class="mspace" style="margin-right:0.2777777777777778em;"></span></span><span class="base"><span class="strut" style="height:0.65952em;vertical-align:0em;"></span><span class="mord mathnormal" style="margin-right:0.03588em;">v</span><span class="mord mathnormal">i</span><span class="mord mathnormal">ss</span><span class="mord mathnormal">t</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal">u</span><span class="mord mathnormal">c</span><span class="mord mathnormal">t</span></span></span></span>struct_name:ident { <span class="katex"><span class="katex-html" aria-hidden="true"><span class="base"><span class="strut" style="height:1em;vertical-align:-0.25em;"></span><span class="mopen">(</span><span class="mord">//</span><span class="mord mathnormal" style="margin-right:0.03588em;">v</span><span class="mord mathnormal">i</span><span class="mord mathnormal">s</span><span class="mord mathnormal" style="margin-right:0.10764em;">f</span><span class="mord mathnormal" style="margin-right:0.02778em;">or</span><span class="mord mathnormal" style="margin-right:0.10764em;">f</span><span class="mord mathnormal">i</span><span class="mord mathnormal">e</span><span class="mord mathnormal" style="margin-right:0.01968em;">l</span><span class="mord mathnormal">d</span><span class="mord mathnormal" style="margin-right:0.03588em;">v</span><span class="mord mathnormal">i</span><span class="mord mathnormal">s</span><span class="mord mathnormal">ibi</span><span class="mord mathnormal" style="margin-right:0.01968em;">l</span><span class="mord mathnormal">i</span><span class="mord mathnormal">t</span><span class="mord mathnormal" style="margin-right:0.03588em;">y</span><span class="mpunct">,</span><span class="mspace" style="margin-right:0.16666666666666666em;"></span><span class="mord mathnormal">i</span><span class="mord mathnormal">d</span><span class="mord mathnormal">e</span><span class="mord mathnormal">n</span><span class="mord mathnormal">t</span><span class="mord mathnormal" style="margin-right:0.10764em;">f</span><span class="mord mathnormal" style="margin-right:0.02778em;">or</span><span class="mord mathnormal" style="margin-right:0.10764em;">f</span><span class="mord mathnormal">i</span><span class="mord mathnormal">e</span><span class="mord mathnormal" style="margin-right:0.01968em;">l</span><span class="mord mathnormal">d</span><span class="mord mathnormal">nam</span><span class="mord mathnormal">e</span><span class="mord mathnormal">an</span><span class="mord mathnormal">d</span><span class="mord mathnormal">t</span><span class="mord mathnormal" style="margin-right:0.03588em;">y</span><span class="mord mathnormal" style="margin-right:0.10764em;">f</span><span class="mord mathnormal" style="margin-right:0.02778em;">or</span><span class="mord mathnormal" style="margin-right:0.10764em;">f</span><span class="mord mathnormal">i</span><span class="mord mathnormal">e</span><span class="mord mathnormal" style="margin-right:0.01968em;">l</span><span class="mord mathnormal">dd</span><span class="mord mathnormal">a</span><span class="mord mathnormal">t</span><span class="mord mathnormal">a</span><span class="mord mathnormal">t</span><span class="mord mathnormal" style="margin-right:0.03588em;">y</span><span class="mord mathnormal">p</span><span class="mord mathnormal">e</span></span></span></span>field_vis:vis <span class="katex"><span class="katex-html" aria-hidden="true"><span class="base"><span class="strut" style="height:0.8888799999999999em;vertical-align:-0.19444em;"></span><span class="mord mathnormal" style="margin-right:0.10764em;">f</span><span class="mord mathnormal">i</span><span class="mord mathnormal">e</span><span class="mord mathnormal" style="margin-right:0.01968em;">l</span><span class="mord"><span class="mord mathnormal">d</span><span class="msupsub"><span class="vlist-t vlist-t2"><span class="vlist-r"><span class="vlist" style="height:0.151392em;"><span style="top:-2.5500000000000003em;margin-left:0em;margin-right:0.05em;"><span class="pstrut" style="height:2.7em;"></span><span class="sizing reset-size6 size3 mtight"><span class="mord mathnormal mtight">n</span></span></span></span><span class="vlist-s"></span></span><span class="vlist-r"><span class="vlist" style="height:0.15em;"><span></span></span></span></span></span></span><span class="mord mathnormal">am</span><span class="mord mathnormal">e</span><span class="mspace" style="margin-right:0.2777777777777778em;"></span><span class="mrel">:</span><span class="mspace" style="margin-right:0.2777777777777778em;"></span></span><span class="base"><span class="strut" style="height:0.69444em;vertical-align:0em;"></span><span class="mord mathnormal">i</span><span class="mord mathnormal">d</span><span class="mord mathnormal">e</span><span class="mord mathnormal">n</span><span class="mord mathnormal">t</span><span class="mspace" style="margin-right:0.2777777777777778em;"></span><span class="mrel">:</span></span></span></span>field_type:ty ),* } ) => { { pub struct struct_name{ ( pub <span class="katex"><span class="katex-html" aria-hidden="true"><span class="base"><span class="strut" style="height:0.8888799999999999em;vertical-align:-0.19444em;"></span><span class="mord mathnormal" style="margin-right:0.10764em;">f</span><span class="mord mathnormal">i</span><span class="mord mathnormal">e</span><span class="mord mathnormal" style="margin-right:0.01968em;">l</span><span class="mord"><span class="mord mathnormal">d</span><span class="msupsub"><span class="vlist-t vlist-t2"><span class="vlist-r"><span class="vlist" style="height:0.151392em;"><span style="top:-2.5500000000000003em;margin-left:0em;margin-right:0.05em;"><span class="pstrut" style="height:2.7em;"></span><span class="sizing reset-size6 size3 mtight"><span class="mord mathnormal mtight">n</span></span></span></span><span class="vlist-s"></span></span><span class="vlist-r"><span class="vlist" style="height:0.15em;"><span></span></span></span></span></span></span><span class="mord mathnormal">am</span><span class="mord mathnormal">e</span><span class="mspace" style="margin-right:0.2777777777777778em;"></span><span class="mrel">:</span></span></span></span>field_type, )* } } } } }
从结构体中解析元数据
通常结构体会有一些附加的元数据或者过程宏,如#[derive(Debug)]。此元数据需要保持不变。解析这个元数据需要使用meta类型。
#![allow(unused)] fn main() { macro_rules! make_public{ ( // meta data about struct (#[meta:meta])* <span class="katex"><span class="katex-html" aria-hidden="true"><span class="base"><span class="strut" style="height:0.65952em;vertical-align:0em;"></span><span class="mord mathnormal" style="margin-right:0.03588em;">v</span><span class="mord mathnormal">i</span><span class="mord mathnormal">s</span><span class="mspace" style="margin-right:0.2777777777777778em;"></span><span class="mrel">:</span><span class="mspace" style="margin-right:0.2777777777777778em;"></span></span><span class="base"><span class="strut" style="height:0.65952em;vertical-align:0em;"></span><span class="mord mathnormal" style="margin-right:0.03588em;">v</span><span class="mord mathnormal">i</span><span class="mord mathnormal">ss</span><span class="mord mathnormal">t</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal">u</span><span class="mord mathnormal">c</span><span class="mord mathnormal">t</span></span></span></span>struct_name:ident { <span class="katex"><span class="katex-html" aria-hidden="true"><span class="base"><span class="strut" style="height:1em;vertical-align:-0.25em;"></span><span class="mopen">(</span><span class="mord">//</span><span class="mord mathnormal">m</span><span class="mord mathnormal">e</span><span class="mord mathnormal">t</span><span class="mord mathnormal">a</span><span class="mord mathnormal">d</span><span class="mord mathnormal">a</span><span class="mord mathnormal">t</span><span class="mord mathnormal">aab</span><span class="mord mathnormal">o</span><span class="mord mathnormal">u</span><span class="mord mathnormal">t</span><span class="mord mathnormal" style="margin-right:0.10764em;">f</span><span class="mord mathnormal">i</span><span class="mord mathnormal">e</span><span class="mord mathnormal" style="margin-right:0.01968em;">l</span><span class="mord mathnormal">d</span></span></span></span>(#[<span class="katex"><span class="katex-html" aria-hidden="true"><span class="base"><span class="strut" style="height:0.8888799999999999em;vertical-align:-0.19444em;"></span><span class="mord mathnormal" style="margin-right:0.10764em;">f</span><span class="mord mathnormal">i</span><span class="mord mathnormal">e</span><span class="mord mathnormal" style="margin-right:0.01968em;">l</span><span class="mord"><span class="mord mathnormal">d</span><span class="msupsub"><span class="vlist-t vlist-t2"><span class="vlist-r"><span class="vlist" style="height:0.151392em;"><span style="top:-2.5500000000000003em;margin-left:0em;margin-right:0.05em;"><span class="pstrut" style="height:2.7em;"></span><span class="sizing reset-size6 size3 mtight"><span class="mord mathnormal mtight">m</span></span></span></span><span class="vlist-s"></span></span><span class="vlist-r"><span class="vlist" style="height:0.15em;"><span></span></span></span></span></span></span><span class="mord mathnormal">e</span><span class="mord mathnormal">t</span><span class="mord mathnormal">a</span><span class="mspace" style="margin-right:0.2777777777777778em;"></span><span class="mrel">:</span><span class="mspace" style="margin-right:0.2777777777777778em;"></span></span><span class="base"><span class="strut" style="height:1em;vertical-align:-0.25em;"></span><span class="mord mathnormal">m</span><span class="mord mathnormal">e</span><span class="mord mathnormal">t</span><span class="mord mathnormal">a</span><span class="mclose">])</span><span class="mord">∗</span></span></span></span>field_vis:vis <span class="katex"><span class="katex-html" aria-hidden="true"><span class="base"><span class="strut" style="height:0.8888799999999999em;vertical-align:-0.19444em;"></span><span class="mord mathnormal" style="margin-right:0.10764em;">f</span><span class="mord mathnormal">i</span><span class="mord mathnormal">e</span><span class="mord mathnormal" style="margin-right:0.01968em;">l</span><span class="mord"><span class="mord mathnormal">d</span><span class="msupsub"><span class="vlist-t vlist-t2"><span class="vlist-r"><span class="vlist" style="height:0.151392em;"><span style="top:-2.5500000000000003em;margin-left:0em;margin-right:0.05em;"><span class="pstrut" style="height:2.7em;"></span><span class="sizing reset-size6 size3 mtight"><span class="mord mathnormal mtight">n</span></span></span></span><span class="vlist-s"></span></span><span class="vlist-r"><span class="vlist" style="height:0.15em;"><span></span></span></span></span></span></span><span class="mord mathnormal">am</span><span class="mord mathnormal">e</span><span class="mspace" style="margin-right:0.2777777777777778em;"></span><span class="mrel">:</span><span class="mspace" style="margin-right:0.2777777777777778em;"></span></span><span class="base"><span class="strut" style="height:0.69444em;vertical-align:0em;"></span><span class="mord mathnormal">i</span><span class="mord mathnormal">d</span><span class="mord mathnormal">e</span><span class="mord mathnormal">n</span><span class="mord mathnormal">t</span><span class="mspace" style="margin-right:0.2777777777777778em;"></span><span class="mrel">:</span></span></span></span>field_type:ty ),*(,)+ } ) => { { (#[<span class="katex"><span class="katex-html" aria-hidden="true"><span class="base"><span class="strut" style="height:1em;vertical-align:-0.25em;"></span><span class="mord mathnormal">m</span><span class="mord mathnormal">e</span><span class="mord mathnormal">t</span><span class="mord mathnormal">a</span><span class="mclose">])</span><span class="mspace" style="margin-right:0.2222222222222222em;"></span><span class="mbin">∗</span><span class="mspace" style="margin-right:0.2222222222222222em;"></span></span><span class="base"><span class="strut" style="height:0.8888799999999999em;vertical-align:-0.19444em;"></span><span class="mord mathnormal">p</span><span class="mord mathnormal">u</span><span class="mord mathnormal">b</span><span class="mord mathnormal">s</span><span class="mord mathnormal">t</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal">u</span><span class="mord mathnormal">c</span><span class="mord mathnormal">t</span></span></span></span>struct_name{ <span class="katex"><span class="katex-html" aria-hidden="true"><span class="base"><span class="strut" style="height:1em;vertical-align:-0.25em;"></span><span class="mopen">(</span></span></span></span>(#[<span class="katex"><span class="katex-html" aria-hidden="true"><span class="base"><span class="strut" style="height:0.8888799999999999em;vertical-align:-0.19444em;"></span><span class="mord mathnormal" style="margin-right:0.10764em;">f</span><span class="mord mathnormal">i</span><span class="mord mathnormal">e</span><span class="mord mathnormal" style="margin-right:0.01968em;">l</span><span class="mord"><span class="mord mathnormal">d</span><span class="msupsub"><span class="vlist-t vlist-t2"><span class="vlist-r"><span class="vlist" style="height:0.151392em;"><span style="top:-2.5500000000000003em;margin-left:0em;margin-right:0.05em;"><span class="pstrut" style="height:2.7em;"></span><span class="sizing reset-size6 size3 mtight"><span class="mord mathnormal mtight">m</span></span></span></span><span class="vlist-s"></span></span><span class="vlist-r"><span class="vlist" style="height:0.15em;"><span></span></span></span></span></span></span><span class="mord mathnormal">e</span><span class="mord mathnormal">t</span><span class="mord mathnormal">a</span><span class="mspace" style="margin-right:0.2777777777777778em;"></span><span class="mrel">:</span><span class="mspace" style="margin-right:0.2777777777777778em;"></span></span><span class="base"><span class="strut" style="height:1em;vertical-align:-0.25em;"></span><span class="mord mathnormal">m</span><span class="mord mathnormal">e</span><span class="mord mathnormal">t</span><span class="mord mathnormal">a</span><span class="mclose">])</span><span class="mspace" style="margin-right:0.2222222222222222em;"></span><span class="mbin">∗</span><span class="mspace" style="margin-right:0.2222222222222222em;"></span></span><span class="base"><span class="strut" style="height:0.8888799999999999em;vertical-align:-0.19444em;"></span><span class="mord mathnormal">p</span><span class="mord mathnormal">u</span><span class="mord mathnormal">b</span></span></span></span>field_name : field_type, )* } } } } }
我们的make_public宏已经就绪。为了查看它是如何工作的,我们使用 Rust Playground 将宏扩展为已经编译的实际代码。
macro_rules! make_public{ ( (#[<span class="katex"><span class="katex-html" aria-hidden="true"><span class="base"><span class="strut" style="height:0.61508em;vertical-align:0em;"></span><span class="mord mathnormal">m</span><span class="mord mathnormal">e</span><span class="mord mathnormal">t</span><span class="mord mathnormal">a</span><span class="mspace" style="margin-right:0.2777777777777778em;"></span><span class="mrel">:</span><span class="mspace" style="margin-right:0.2777777777777778em;"></span></span><span class="base"><span class="strut" style="height:1em;vertical-align:-0.25em;"></span><span class="mord mathnormal">m</span><span class="mord mathnormal">e</span><span class="mord mathnormal">t</span><span class="mord mathnormal">a</span><span class="mclose">])</span><span class="mord">∗</span></span></span></span>vis:vis struct struct_name:ident { ( (#[field_meta:meta])* <span class="katex"><span class="katex-html" aria-hidden="true"><span class="base"><span class="strut" style="height:0.8888799999999999em;vertical-align:-0.19444em;"></span><span class="mord mathnormal" style="margin-right:0.10764em;">f</span><span class="mord mathnormal">i</span><span class="mord mathnormal">e</span><span class="mord mathnormal" style="margin-right:0.01968em;">l</span><span class="mord"><span class="mord mathnormal">d</span><span class="msupsub"><span class="vlist-t vlist-t2"><span class="vlist-r"><span class="vlist" style="height:0.151392em;"><span style="top:-2.5500000000000003em;margin-left:0em;margin-right:0.05em;"><span class="pstrut" style="height:2.7em;"></span><span class="sizing reset-size6 size3 mtight"><span class="mord mathnormal mtight" style="margin-right:0.03588em;">v</span></span></span></span><span class="vlist-s"></span></span><span class="vlist-r"><span class="vlist" style="height:0.15em;"><span></span></span></span></span></span></span><span class="mord mathnormal">i</span><span class="mord mathnormal">s</span><span class="mspace" style="margin-right:0.2777777777777778em;"></span><span class="mrel">:</span><span class="mspace" style="margin-right:0.2777777777777778em;"></span></span><span class="base"><span class="strut" style="height:0.65952em;vertical-align:0em;"></span><span class="mord mathnormal" style="margin-right:0.03588em;">v</span><span class="mord mathnormal">i</span><span class="mord mathnormal">s</span></span></span></span>field_name:ident : <span class="katex"><span class="katex-html" aria-hidden="true"><span class="base"><span class="strut" style="height:0.8888799999999999em;vertical-align:-0.19444em;"></span><span class="mord mathnormal" style="margin-right:0.10764em;">f</span><span class="mord mathnormal">i</span><span class="mord mathnormal">e</span><span class="mord mathnormal" style="margin-right:0.01968em;">l</span><span class="mord"><span class="mord mathnormal">d</span><span class="msupsub"><span class="vlist-t vlist-t2"><span class="vlist-r"><span class="vlist" style="height:0.2805559999999999em;"><span style="top:-2.5500000000000003em;margin-left:0em;margin-right:0.05em;"><span class="pstrut" style="height:2.7em;"></span><span class="sizing reset-size6 size3 mtight"><span class="mord mathnormal mtight">t</span></span></span></span><span class="vlist-s"></span></span><span class="vlist-r"><span class="vlist" style="height:0.15em;"><span></span></span></span></span></span></span><span class="mord mathnormal" style="margin-right:0.03588em;">y</span><span class="mord mathnormal">p</span><span class="mord mathnormal">e</span><span class="mspace" style="margin-right:0.2777777777777778em;"></span><span class="mrel">:</span><span class="mspace" style="margin-right:0.2777777777777778em;"></span></span><span class="base"><span class="strut" style="height:1em;vertical-align:-0.25em;"></span><span class="mord mathnormal">t</span><span class="mord mathnormal" style="margin-right:0.03588em;">y</span><span class="mclose">)</span><span class="mpunct">,</span><span class="mspace" style="margin-right:0.16666666666666666em;"></span><span class="mord">∗</span></span></span></span>(,)+ } ) => { (#[meta])* pub struct struct_name{ ( (#[field_meta:meta])* pub <span class="katex"><span class="katex-html" aria-hidden="true"><span class="base"><span class="strut" style="height:0.8888799999999999em;vertical-align:-0.19444em;"></span><span class="mord mathnormal" style="margin-right:0.10764em;">f</span><span class="mord mathnormal">i</span><span class="mord mathnormal">e</span><span class="mord mathnormal" style="margin-right:0.01968em;">l</span><span class="mord"><span class="mord mathnormal">d</span><span class="msupsub"><span class="vlist-t vlist-t2"><span class="vlist-r"><span class="vlist" style="height:0.151392em;"><span style="top:-2.5500000000000003em;margin-left:0em;margin-right:0.05em;"><span class="pstrut" style="height:2.7em;"></span><span class="sizing reset-size6 size3 mtight"><span class="mord mathnormal mtight">n</span></span></span></span><span class="vlist-s"></span></span><span class="vlist-r"><span class="vlist" style="height:0.15em;"><span></span></span></span></span></span></span><span class="mord mathnormal">am</span><span class="mord mathnormal">e</span><span class="mspace" style="margin-right:0.2777777777777778em;"></span><span class="mrel">:</span></span></span></span>field_type, )* } } } fn main(){ make_public!{ #[derive(Debug)] struct Name{ n:i64, t:i64, g:i64, } } }
扩展后的代码如下所示:
// some imports macro_rules! make_public { ( (#[ meta : meta]) * <span class="katex"><span class="katex-html" aria-hidden="true"><span class="base"><span class="strut" style="height:0.65952em;vertical-align:0em;"></span><span class="mord mathnormal" style="margin-right:0.03588em;">v</span><span class="mord mathnormal">i</span><span class="mord mathnormal">s</span><span class="mspace" style="margin-right:0.2777777777777778em;"></span><span class="mrel">:</span><span class="mspace" style="margin-right:0.2777777777777778em;"></span></span><span class="base"><span class="strut" style="height:0.65952em;vertical-align:0em;"></span><span class="mord mathnormal" style="margin-right:0.03588em;">v</span><span class="mord mathnormal">i</span><span class="mord mathnormal">ss</span><span class="mord mathnormal">t</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal">u</span><span class="mord mathnormal">c</span><span class="mord mathnormal">t</span></span></span></span> struct_name : ident { <span class="katex"><span class="katex-html" aria-hidden="true"><span class="base"><span class="strut" style="height:1em;vertical-align:-0.25em;"></span><span class="mopen">(</span></span></span></span> (#[<span class="katex"><span class="katex-html" aria-hidden="true"><span class="base"><span class="strut" style="height:0.8888799999999999em;vertical-align:-0.19444em;"></span><span class="mord mathnormal" style="margin-right:0.10764em;">f</span><span class="mord mathnormal">i</span><span class="mord mathnormal">e</span><span class="mord mathnormal" style="margin-right:0.01968em;">l</span><span class="mord"><span class="mord mathnormal">d</span><span class="msupsub"><span class="vlist-t vlist-t2"><span class="vlist-r"><span class="vlist" style="height:0.151392em;"><span style="top:-2.5500000000000003em;margin-left:0em;margin-right:0.05em;"><span class="pstrut" style="height:2.7em;"></span><span class="sizing reset-size6 size3 mtight"><span class="mord mathnormal mtight">m</span></span></span></span><span class="vlist-s"></span></span><span class="vlist-r"><span class="vlist" style="height:0.15em;"><span></span></span></span></span></span></span><span class="mord mathnormal">e</span><span class="mord mathnormal">t</span><span class="mord mathnormal">a</span><span class="mspace" style="margin-right:0.2777777777777778em;"></span><span class="mrel">:</span><span class="mspace" style="margin-right:0.2777777777777778em;"></span></span><span class="base"><span class="strut" style="height:1em;vertical-align:-0.25em;"></span><span class="mord mathnormal">m</span><span class="mord mathnormal">e</span><span class="mord mathnormal">t</span><span class="mord mathnormal">a</span><span class="mclose">])</span><span class="mord">∗</span></span></span></span> field_vis : vis <span class="katex"><span class="katex-html" aria-hidden="true"><span class="base"><span class="strut" style="height:0.8888799999999999em;vertical-align:-0.19444em;"></span><span class="mord mathnormal" style="margin-right:0.10764em;">f</span><span class="mord mathnormal">i</span><span class="mord mathnormal">e</span><span class="mord mathnormal" style="margin-right:0.01968em;">l</span><span class="mord"><span class="mord mathnormal">d</span><span class="msupsub"><span class="vlist-t vlist-t2"><span class="vlist-r"><span class="vlist" style="height:0.151392em;"><span style="top:-2.5500000000000003em;margin-left:0em;margin-right:0.05em;"><span class="pstrut" style="height:2.7em;"></span><span class="sizing reset-size6 size3 mtight"><span class="mord mathnormal mtight">n</span></span></span></span><span class="vlist-s"></span></span><span class="vlist-r"><span class="vlist" style="height:0.15em;"><span></span></span></span></span></span></span><span class="mord mathnormal">am</span><span class="mord mathnormal">e</span><span class="mspace" style="margin-right:0.2777777777777778em;"></span><span class="mrel">:</span><span class="mspace" style="margin-right:0.2777777777777778em;"></span></span><span class="base"><span class="strut" style="height:0.69444em;vertical-align:0em;"></span><span class="mord mathnormal">i</span><span class="mord mathnormal">d</span><span class="mord mathnormal">e</span><span class="mord mathnormal">n</span><span class="mord mathnormal">t</span><span class="mspace" style="margin-right:0.2777777777777778em;"></span><span class="mrel">:</span></span></span></span> field_type : ty), * (,) + }) => { (#[<span class="katex"><span class="katex-html" aria-hidden="true"><span class="base"><span class="strut" style="height:1em;vertical-align:-0.25em;"></span><span class="mord mathnormal">m</span><span class="mord mathnormal">e</span><span class="mord mathnormal">t</span><span class="mord mathnormal">a</span><span class="mclose">])</span><span class="mspace" style="margin-right:0.2222222222222222em;"></span><span class="mbin">∗</span><span class="mspace" style="margin-right:0.2222222222222222em;"></span></span><span class="base"><span class="strut" style="height:0.8888799999999999em;vertical-align:-0.19444em;"></span><span class="mord mathnormal">p</span><span class="mord mathnormal">u</span><span class="mord mathnormal">b</span><span class="mord mathnormal">s</span><span class="mord mathnormal">t</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal">u</span><span class="mord mathnormal">c</span><span class="mord mathnormal">t</span></span></span></span> struct_name { <span class="katex"><span class="katex-html" aria-hidden="true"><span class="base"><span class="strut" style="height:1em;vertical-align:-0.25em;"></span><span class="mopen">(</span></span></span></span> (#[<span class="katex"><span class="katex-html" aria-hidden="true"><span class="base"><span class="strut" style="height:0.8888799999999999em;vertical-align:-0.19444em;"></span><span class="mord mathnormal" style="margin-right:0.10764em;">f</span><span class="mord mathnormal">i</span><span class="mord mathnormal">e</span><span class="mord mathnormal" style="margin-right:0.01968em;">l</span><span class="mord"><span class="mord mathnormal">d</span><span class="msupsub"><span class="vlist-t vlist-t2"><span class="vlist-r"><span class="vlist" style="height:0.151392em;"><span style="top:-2.5500000000000003em;margin-left:0em;margin-right:0.05em;"><span class="pstrut" style="height:2.7em;"></span><span class="sizing reset-size6 size3 mtight"><span class="mord mathnormal mtight">m</span></span></span></span><span class="vlist-s"></span></span><span class="vlist-r"><span class="vlist" style="height:0.15em;"><span></span></span></span></span></span></span><span class="mord mathnormal">e</span><span class="mord mathnormal">t</span><span class="mord mathnormal">a</span><span class="mspace" style="margin-right:0.2777777777777778em;"></span><span class="mrel">:</span><span class="mspace" style="margin-right:0.2777777777777778em;"></span></span><span class="base"><span class="strut" style="height:1em;vertical-align:-0.25em;"></span><span class="mord mathnormal">m</span><span class="mord mathnormal">e</span><span class="mord mathnormal">t</span><span class="mord mathnormal">a</span><span class="mclose">])</span><span class="mspace" style="margin-right:0.2222222222222222em;"></span><span class="mbin">∗</span><span class="mspace" style="margin-right:0.2222222222222222em;"></span></span><span class="base"><span class="strut" style="height:0.8888799999999999em;vertical-align:-0.19444em;"></span><span class="mord mathnormal">p</span><span class="mord mathnormal">u</span><span class="mord mathnormal">b</span></span></span></span> field_name : field_type,) * } } } fn main() { pub struct name { pub n: i64, pub t: i64, pub g: i64, } }
声明式宏的限制
声明式宏有一些限制。一些与 Rust 宏本身有关,一些是声明式宏所特有的。
- 缺少宏的自动提示与扩展的支持
- 调试声明式宏非常困难
- 有限的修改功能
- (编译后产生)超大的二进制文件
- 需要更长的编译时间(声明式宏与过程宏都有这个问题)
Rust 中的过程宏
过程宏是宏的更高级的版本。过程宏允许你扩展已存在的 Rust 语法。它接受任意的输入并返回合法的 Rust 代码。
过程宏是一个接受TokenStream作为输入并返回另一个TokenStream作为输出。过程宏操作输入的TokenStream以产生一个输出流。
这里有三种类型的过程宏:
- 属性式宏
- 派生宏
- 函数式宏
我们将会在下面详细的介绍每一种类型的过程宏。
属性式宏
属性式宏可以让你创建一个依附于某一项的自定义属性,并允许你操作该项。它还可以携带参数。
#![allow(unused)] fn main() { #[some_attribute_macro(some_argument)] fn perform_task(){ // some code } }
在上面的代码中,some_attribute_macros是一个属性宏,它操作perform_task函数。
为了写一个属性式宏,使用cargo new macro-demo --lib创建一个项目。一旦项目就绪,更新Cargo.toml来告诉项目将要创建一个过程宏。
# Cargo.toml
[lib]
proc-macro = true
现在我们开始尝试编写过程宏。
过程宏是一个接收TokenStream作为输入,并返回另一个TokenStream的函数。为了编写一个过程宏,我们需要编写一个解析器解析TokenStream。Rust 社区有一个非常棒的库:syn,用来解析TokenStream。
syn 为 Rust 语法提供了现成的解析器用来解析TokenStream。你也可以通过组合 syn 提供的更加底层的解析器来解析你的语法。
在Cargo.toml中添加syn和quote:
# Cargo.toml
[dependencies]
syn = {version="1.0.57",features=["full","fold"]}
quote = "1.0.8"
现在我们可以使用编译器为编写过程宏而提供proc_macro库在lib.rs中编写属性式宏。一个过程宏库不能导出过程宏以外的其他任何东西,并且在 crate 中定义的过程宏不能在该 crate 中使用。
#![allow(unused)] fn main() { // lib.rs extern crate proc_macro; use proc_macro::{TokenStream}; use quote::{quote}; // using proc_macro_attribute to declare an attribute like procedural macro #[proc_macro_attribute] // _metadata is argument provided to macro call and _input is code to which attribute like macro attaches pub fn my_custom_attribute(_metadata: TokenStream, _input: TokenStream) -> TokenStream { // returing a simple TokenStream for Struct TokenStream::from(quote!{struct H{}}) } }
为了测试我们添加的宏,通过创建一个名为tests的文件夹并在其中添加attribute_macro.rs文件来创建一个集成测试。在这个文件中,我们测试我们的属性式宏。
#![allow(unused)] fn main() { // tests/attribute_macro.rs use macro_demo::*; // macro converts struct S to struct H #[my_custom_attribute] struct S{} #[test] fn test_macro(){ // due to macro we have struct H in scope let demo=H{}; } }
使用cargo test命令运行上面的测试代码。
既然我们理解了过程宏的基本概念,让我们使用syn来操作并解析更高级的TokenStream。
为了学习syn是如何解析并操作TokenStream的,我们以syn的Github仓库 的一个示例为例。这个示例创建了一个在值变更时跟踪变量的 Rust 宏。
首先,我们需要弄清楚宏是如何操作它依附的代码的。
#![allow(unused)] fn main() { #[trace_vars(a)] fn do_something(){ let a=9; a=6; a=0; } }
trace_vars宏传入它需要跟踪的变量名,并且一旦传入的变量a的值发生改变,就会注入了一条打印语句。它跟踪了输入变量的值。
首先,解析属性式宏依附的代码。syn为 Rust 函数语法提供了一个内置的解析器。ItemFn将会解析函数,并且当语法是非法时抛出一个错误。
#![allow(unused)] fn main() { #[proc_macro_attribute] pub fn trace_vars(_metadata: TokenStream, input: TokenStream) -> TokenStream { // parsing rust function to easy to use struct let input_fn = parse_macro_input!(input as ItemFn); TokenStream::from(quote!{fn dummy(){}}) } }
既然我们有了已解析的输入,让我们转到元数据。对于元数据,没有内置的解析器会起作用,因此我们需要使用syn的parse模块编写我们自己的解析器。
#![allow(unused)] fn main() { #[trace_vars(a,c,b)] // we need to parse a "," seperated list of tokens // code }
为了让syn起作用,我们需要实现syn提供的Parse特征。Punctuated被用来创建一个以,分隔的Ident的向量。
#![allow(unused)] fn main() { struct Args{ vars:HashSet<Ident> } impl Parse for Args{ fn parse(input: ParseStream) -> Result<Self> { // parses a,b,c, or a,b,c where a,b and c are Indent let vars = Punctuated::<Ident, Token![,]>::parse_terminated(input)?; Ok(Args { vars: vars.into_iter().collect(), }) } } }
一旦我们实现了Parse特征,我们就可以使用parse_macro_input宏来解析元数据了。
#![allow(unused)] fn main() { #[proc_macro_attribute] pub fn trace_vars(metadata: TokenStream, input: TokenStream) -> TokenStream { let input_fn = parse_macro_input!(input as ItemFn); // using newly created struct Args let args= parse_macro_input!(metadata as Args); TokenStream::from(quote!{fn dummy(){}}) } }
现在,当变量的值变更时,我们将修改input_fn以添加println!。为了添加这个功能,我们需要过滤出赋值语句,并在该行之后插入一条打印语句。
#![allow(unused)] fn main() { impl Args { fn should_print_expr(&self, e: &Expr) -> bool { match *e { Expr::Path(ref e) => { // variable shouldn't start wiht :: if e.path.leading_colon.is_some() { false // should be a single variable like `x=8` not n::x=0 } else if e.path.segments.len() != 1 { false } else { // get the first part let first = e.path.segments.first().unwrap(); // check if the variable name is in the Args.vars hashset self.vars.contains(&first.ident) && first.arguments.is_empty() } } _ => false, } } // used for checking if to print let i=0 etc or not fn should_print_pat(&self, p: &Pat) -> bool { match p { // check if variable name is present in set Pat::Ident(ref p) => self.vars.contains(&p.ident), _ => false, } } // manipulate tree to insert print statement fn assign_and_print(&mut self, left: Expr, op: &dyn ToTokens, right: Expr) -> Expr { // recurive call on right of the assigment statement let right = fold::fold_expr(self, right); // returning manipulated sub-tree parse_quote!({ left #op #right; println!(concat!(stringify!(#left), " = {:?}"), #left); }) } // manipulating let statement fn let_and_print(&mut self, local: Local) -> Stmt { let Local { pat, init, .. } = local; let init = self.fold_expr(*init.unwrap().1); // get the variable name of assigned variable let ident = match pat { Pat::Ident(ref p) => &p.ident, _ => unreachable!(), }; // new sub tree parse_quote! { let #pat = { #[allow(unused_mut)] let #pat = #init; println!(concat!(stringify!(#ident), " = {:?}"), #ident); ident }; } } } }
在上面的示例中,quote宏用于模版化并编写 Rust。#用来插入变量的值。
现在我们将会对input_fn进行深度优先搜索 (DFS) 并插入一条打印语句。syn提供了一个Fold特征,它可以为任何Item实现 DFS。我们只需要修改与我们要操作的标记类型相对应的特征方法。
#![allow(unused)] fn main() { impl Fold for Args { fn fold_expr(&mut self, e: Expr) -> Expr { match e { // for changing assignment like a=5 Expr::Assign(e) => { // check should print if self.should_print_expr(&e.left) { self.assign_and_print(*e.left, &e.eq_token, *e.right) } else { // continue with default travesal using default methods Expr::Assign(fold::fold_expr_assign(self, e)) } } // for changing assigment and operation like a+=1 Expr::AssignOp(e) => { // check should print if self.should_print_expr(&e.left) { self.assign_and_print(*e.left, &e.op, *e.right) } else { // continue with default behaviour Expr::AssignOp(fold::fold_expr_assign_op(self, e)) } } // continue with default behaviour for rest of expressions _ => fold::fold_expr(self, e), } } // for let statements like let d=9 fn fold_stmt(&mut self, s: Stmt) -> Stmt { match s { Stmt::Local(s) => { if s.init.is_some() && self.should_print_pat(&s.pat) { self.let_and_print(s) } else { Stmt::Local(fold::fold_local(self, s)) } } _ => fold::fold_stmt(self, s), } } } }
Fold特征用于对Item进行 DFS。它可以让你对不同的 token 类型执行不同的行为。
现在我们可以使用fold_item_fn在解析的代码中注入打印语句。
#![allow(unused)] fn main() { #[proc_macro_attribute] pub fn trace_var(args: TokenStream, input: TokenStream) -> TokenStream { // parse the input let input = parse_macro_input!(input as ItemFn); // parse the arguments let mut args = parse_macro_input!(args as Args); // create the ouput let output = args.fold_item_fn(input); // return the TokenStream TokenStream::from(quote!(#output)) } }
这个代码示例来自 syn examples,这是一个非常出色的学习过程宏的资源。
自定义派生宏
在 Rust 中自定义派生宏可以自动实现特征。这些宏让你可以通过使用#[derive(Trait)]来实现该特征。
syn对派生宏有出色的支持。
#![allow(unused)] fn main() { #[derive(Trait)] struct MyStruct{} }
为了在 Rust 中编写自定义派生宏,我们可以使用DeriveInput来解析输入以派生宏。我们也可以使用proc_macro_derive宏来自定义派生宏。
#![allow(unused)] fn main() { #[proc_macro_derive(Trait)] pub fn derive_trait(input: proc_macro::TokenStream) -> proc_macro::TokenStream { let input = parse_macro_input!(input as DeriveInput); let name = input.ident; let expanded = quote! { impl Trait for #name { fn print(&self) -> usize { println!("{}","hello from #name") } } }; proc_macro::TokenStream::from(expanded) } }
使用syn可以编写更多高级的派生宏。可以在 syn examples中查看本示例。
函数式宏
函数式宏和声明式宏很像,因为它们都通过!进行调用并且看起来都很像函数调用。它们对括号内的代码进行操作。
在 Rust 中,这是如何编写函数式宏的示例:
#![allow(unused)] fn main() { #[proc_macro] pub fn a_proc_macro(_input: TokenStream) -> TokenStream { TokenStream::from(quote!( fn anwser()->i32{ 5 } )) } }
函数式宏不是在运行时执行的,而是在编译时执行的。它们可以用在 Rust 代码中的每一处地方。函数式宏同样接收一个TokenStream并返回一个TokenStream。
使用过程宏的好处包括:
- 使用
span更好的进行错误处理 - 更好的控制输出
- 社区提供的
syn和quote - 比声明式宏更强大
结论
在 Rust 宏教程中,我们涉及了 Rust 中宏的所有基础概念,定义了声明式宏和过程宏,并学习了如何通过使用各种语法以及社区提供的类库来编写这两种类型的宏。我们还介绍了使用每一种 Rust 宏的优势。
libp2p 教程:使用 Rust 构建 p2p 应用
在过去几年中,由于围绕区块链和加密货币 (cryptocurrencies) 的火热炒作 (hype),去中心化应用的发展势头风光一时无两。人们对去中心化的兴趣日益浓厚的另一个因素是,人们越来越意识到在数据隐私与垄断 (monopolization) 方面,将大多数网络信息交到一小部分公司手中的弊端 (downside)。
不管怎样,除了 (aside from) 所有的加密与区块链技术外,最近在去中心化软件领域出现了一些非常有趣的进展。
值得关注的包括 IPFS;全新的分布式编码平台 Radicle;去中心化社交网络 Scuttlebutt;以及 Fediverse 中的其他应用程序,如 Mastodon。
在这篇教程中,我们将会向你展示如何使用 Rust 和 libp2p 来构建一个非常简单的 p2p 应用程序。其中 libp2p 是一个非常棒的库,对于不同语言,它处于不同的成熟阶段。
我们将使用简单的命令行界面构建一个烹饪食谱应用程序,使我们能够:
- 创建食谱
- 发布食谱
- 列出本地食谱清单
- 列出我们在网络中发现的其他成员
- 列出指定成员发布的食谱
- 列出我们其他成员的所有食谱
我们将通过 300 行左右的 Rust 代码来实现所有上述功能。让我们开始吧!
安装 Rust
为了继续以下内容,你需要的只是安装最新的 Rust 版本 (1.47+)。
首先,创建一个新的 Rust 工程:
cargo new rust-p2p-example
cd rust-p2p-example
然后,编辑Cargo.toml文件并添加你所需要的依赖:
[dependencies]
libp2p = { version = "0.31", features = ["tcp-tokio", "mdns-tokio"] }
tokio = { version = "0.3", features = ["io-util", "io-std", "stream", "macros", "rt", "rt-multi-thread", "fs", "time", "sync"] }
serde = {version = "=1.0", features = ["derive"] }
serde_json = "1.0"
once_cell = "1.5"
log = "0.4"
pretty_env_logger = "0.4"
就像上面所说的一样,我们将会使用 libp2p 来开发 p2p 应用的网络部分。更值得一提的是,我们将使其与 tokio 异步运行时配合使用 (use it in concert with)。我们将使用 Serde 作为 Json 的序列化与反序列化器,以及其他用于日志打印以及初始化状态的帮助类库。
什么是 libp2p?
libp2p 是一个专注于模块化构建 p2p 应用的协议簇。
libp2p 有多语言的实现类库,如:JavaScript,Go 以及 Rust。这些库都实现了相同的libp2p规范,因此,一个 Go 语言的libp2p客户端可以无缝的与 JavaScript 实现的另一个客户端进行交互,只要它们在选择的协议栈方面兼容即可。这些协议涵盖了从基本网络传输协议到安全层协议以及多路复用的广泛范围。
在本文中我们不会深入讲解libp2p的细节,但是如果你想要更深入的学习,libp2p 官方文档将很好地概述我们在此过程中会遇到的各种概念。
libp2p 是如何工作的
为了查看libp2p的实际效果,我们将从定义一些需要的常量和类型开始构建食谱应用。
#![allow(unused)] fn main() { const STORAGE_FILE_PATH: &str = "./recipes.json"; type Result<T> = std::result::Result<T, Box<dyn std::error::Error + Send + Sync + 'static>>; static KEYS: Lazy<identity::Keypair> = Lazy::new(|| identity::Keypair::generate_ed25519()); static PEER_ID: Lazy<PeerId> = Lazy::new(|| PeerId::from(KEYS.public())); static TOPIC: Lazy<Topic> = Lazy::new(|| Topic::new("recipes")); }
我们将在名为recipes.json的 JSON 文件中存储本地食谱,应用的可执行程序将与其放在同一目录下。我们将定义一个名为Result的帮助类型,它将有助于传播任意的错误。
然后,我们使用once_cell::Lazy来懒加载一些东西。首要的是,我们使用它来生成密钥对,并从公钥中派生所谓的 (so-called) PeerId。我们还创建了一个Topic,它是libp2p中另一个关键的概念。
这是什么意思呢?简而言之,在整个 p2p 网络中,PeerId是一个特定成员的唯一的标志符。我们从密钥对中派生它以确保它的唯一性。而且这个密钥对可以让我们与网络中其他的成员进行安全通信,确保没有人可以冒充 (impersonate) 我们。
另一方面,Topic是 Floodsub 中的概念,它实现了libp2p中的 pub/sub 接口。Topic是一种我们可以订阅并发送消息的组件 - 举个例子,只监听 pub/sub 网络中流量的子集。
我们需要为食谱定义一些类型:
#![allow(unused)] fn main() { type Recipes = Vec<Recipe>; #[derive(Debug, Serialize, Deserialize)] struct Recipe { id: usize, name: String, ingredients: String, instructions: String, public: bool, } }
以及一些我们想要发送的消息类型:
#![allow(unused)] fn main() { #[derive(Debug, Serialize, Deserialize)] enum ListMode { ALL, One(String), } #[derive(Debug, Serialize, Deserialize)] struct ListRequest { mode: ListMode, } #[derive(Debug, Serialize, Deserialize)] struct ListResponse { mode: ListMode, data: Recipes, receiver: String, } enum EventType { Response(ListResponse), Input(String), } }
这个食谱相当简单。它有一个 ID,一个名称,一些配料 (ingredient) 以及烹饪的方法。而且,我们还添加了一个public标记以便区分我们想要分享的食谱以及想要保留的食谱。
正如开头提到的,这里有两种方式可以拉到其他成员的食谱清单:拉取全部获取某一个成员的食谱清单,通过ListMode来表示。
ListRequest和ListResponse仅仅是ListMode的封装,以及使用它们的发送时间。
EventType枚举用来区分来自其他成员的响应以及我们自己的输入。稍后我们将介绍为什么这种差异很重要。
创建一个libp2p客户端
让我们开始编写 main 函数,以便在 p2p 网络中创建一个成员。
#[tokio::main] async fn main() { pretty_env_logger::init(); info!("Peer Id: {}", PEER_ID.clone()); let (response_sender, mut response_rcv) = mpsc::unbounded_channel(); let auth_keys = Keypair::<X25519Spec>::new() .into_authentic(&KEYS) .expect("can create auth keys");
我们初始化日志并创建了一个异步channel来与应用的其他部分进行通信。稍后,我们将使用此channel将来自libp2p网络栈的响应发送回我们的应用程序以进行处理。
另外,我们为 Noise 加密协议创建了一些授权密钥,这些密钥将用于保护网络中的流量。为了达到这个目的,我们创建了一个新的密钥对,然后使用into_authentic函数通过身份密钥对其进行签名。
下一步很重要并涉及libp2p的核心概念:创建所谓的Transport:
#![allow(unused)] fn main() { let transp = TokioTcpConfig::new() .upgrade(upgrade::Version::V1) .authenticate(NoiseConfig::xx(auth_keys).into_authenticated()) .multiplex(mplex::MplexConfig::new()) .boxed(); }
transport 是一个面向连接的与其他成员进行通信的网络协议蔟。在同一个应用程序中可能也会使用多个 transport - 举个例子,TCP/IP,Websocket 或者 UDP 同时针对不同的用例进行通信。
在本例中,我们将使用 Tokio 的异步TCP 作为基础。一旦 TCP 连接建立,为了通信安全,我们将使用Noise对其进行upgrade操作。一个基于 web 的示例是在 HTTP 之上使用 TLS 创建安全连接。
我们将使用NoiseConfig::xx的握手模式,这是唯一一个可以与其他libp2p应用交互的选项。
libp2p的好处是,我们可以编写一个 Rust 客户端,另一个编写 JavaScript 客户端,只要在两个语言版本的库中都实现了(相同的)协议,它们就可以轻松地进行通信。
最后,我们还对 transport 进行多路复用,它可以让我们在相同的 transport 上复用多个 substream 或者连接。
理论性的东西有点多!但是所有这些都可以在 libp2p 文档中找到。这只是创建 p2p transport 众多方法中的其中一种。
下一个概念是NetworkBehaviour。这实际上是libp2p中定义网络和所有成员逻辑的部分 - 举个例子,当接收到事件应该做什么以及应该发送什么事件。
#![allow(unused)] fn main() { let mut behaviour = RecipeBehaviour { floodsub: Floodsub::new(PEER_ID.clone()), mdns: TokioMdns::new().expect("can create mdns"), response_sender, }; behaviour.floodsub.subscribe(TOPIC.clone()); }
在这里,正如上面所提及的,我们将使用FloodSub协议处理这些事件。我们也使用 mDNS,这是一种在本地网络中发现其他成员的协议。我们还会在这放置 channel 中的sender,以便可以使用它将事件传播到应用程序的主要模块中。
现在,我们已经从 behavior 中订阅了在之前创建的FloodSub主题,这意味着我们将接收并可以发送该主题的事件。
我们几乎已经完成了libp2p的设置。我们需要了解的最后一个概念是Swarm。
#![allow(unused)] fn main() { let mut swarm = SwarmBuilder::new(transp, behaviour, PEER_ID.clone()) .executor(Box::new(|fut| { tokio::spawn(fut); })) .build(); }
Swarm 管理使用 transport 创建的连接,并执行我们创建的网络行为(如:触发或接收事件),并为我们提供一种从外部获取它们的方法。
我们使用 transport,behavior和 PEER_ID 创建了Swarm。执行器告诉Swarm使用Tokio运行时在内部运行,但是我们也可以在这里使用其他的异步运行时。
剩下的唯一一件事就是启动我们的Swarm:
#![allow(unused)] fn main() { Swarm::listen_on( &mut swarm, "/ip4/0.0.0.0/tcp/0" .parse() .expect("can get a local socket")) .expect("swarm can be started"); }
与 TCP 服务器类似,我们仅使用本地 IP 调用listen_on,让操作系统为我们确定端口。这将以之前的所有设置来启动Swarm,但实际上我们还没有定义任何逻辑。
让我们从处理用户输入开始。
在libp2p中处理用户输入
对于用户输入,我们仅仅依赖 STDIN。因此在调用Swarm::listen_on之前,我们将会添加:
#![allow(unused)] fn main() { let mut stdin = tokio::io::BufReader::new(tokio::io::stdin()).lines(); }
它在 STDIN 之上定义了一个异步 reader,它可以逐行读取字节流。如果我们按下 enter 键,这里将会传入一个新的消息。
下一步我们将创建事件循环,它将会监听来自 STDIN,Swarm以及在上面定义的响应 channel 中的事件。
#![allow(unused)] fn main() { loop { let evt = { tokio::select! { line = stdin.next_line() => Some(EventType::Input(line.expect("can get line").expect("can read line from stdin"))), event = swarm.next() => { info!("Unhandled Swarm Event: {:?}", event); None }, response = response_rcv.recv() => Some(EventType::Response(response.expect("response exists"))), } }; ... } }
我们使用 Tokio 的select宏来等待几种异步流程,并处理第一个完成的流程。对于Swarm事件我们不做任何处理;这些事件都在之后将看到的RecipeBehaviour中进行处理,但我们仍需要调用swarm.next()以驱动Swarm转发。
让我们添加一些事件处理逻辑来取代上面的...:
#![allow(unused)] fn main() { if let Some(event) = evt { match event { EventType::Response(resp) => { ... } EventType::Input(line) => match line.as_str() { "ls p" => handle_list_peers(&mut swarm).await, cmd if cmd.starts_with("ls r") => handle_list_recipes(cmd, &mut swarm).await, cmd if cmd.starts_with("create r") => handle_create_recipe(cmd).await, cmd if cmd.starts_with("publish r") => handle_publish_recipe(cmd).await, _ => error!("unknown command"), }, } } }
如果 evt 是一个事件,我们将会对其进行匹配并判断是否是Response还是Input事件。我们现在先看下Input事件。
ls p列出所有的已知成员ls r列出所有的本地食谱ls r {peerId}列出指定成员发布的食谱ls r all列出所有已知成员发布的食谱publish r {recipeId}发布指定的食谱create r {recipeName}|{recipeIngredients}|{recipeInstructions}通过给定的数据以及自增的 ID 创建一个新的食谱
在这里,列出成员的所有食谱意味着要向所有成员发送一个关于食谱的请求并等待它们的响应,然后展示结果。在 p2p 网络中,这可能要花一点事件因为某些成员可能会在地球的另一端,我们甚至不知道它们是否会对我们进行响应。这和发送一个请求到 HTTP 服务器不一样,举个例子:
先看下列出成员清单的逻辑:
#![allow(unused)] fn main() { async fn handle_list_peers(swarm: &mut Swarm<RecipeBehaviour>) { info!("Discovered Peers:"); let nodes = swarm.mdns.discovered_nodes(); let mut unique_peers = HashSet::new(); for peer in nodes { unique_peers.insert(peer); } unique_peers.iter().for_each(|p| info!("{}", p)); } }
在这里,我们可以使用mDNS来发现所有的节点,遍历并展示它们。
接下来,让我们创建并发布食谱,在处理 (tackle) 列表命令之前:
#![allow(unused)] fn main() { async fn handle_create_recipe(cmd: &str) { if let Some(rest) = cmd.strip_prefix("create r") { let elements: Vec<&str> = rest.split("|").collect(); if elements.len() < 3 { info!("too few arguments - Format: name|ingredients|instructions"); } else { let name = elements.get(0).expect("name is there"); let ingredients = elements.get(1).expect("ingredients is there"); let instructions = elements.get(2).expect("instructions is there"); if let Err(e) = create_new_recipe(name, ingredients, instructions).await { error!("error creating recipe: {}", e); }; } } } async fn handle_publish_recipe(cmd: &str) { if let Some(rest) = cmd.strip_prefix("publish r") { match rest.trim().parse::<usize>() { Ok(id) => { if let Err(e) = publish_recipe(id).await { info!("error publishing recipe with id {}, {}", id, e) } else { info!("Published Recipe with id: {}", id); } } Err(e) => error!("invalid id: {}, {}", rest.trim(), e), }; } } }
在这两种情况下,我们都需要解析字符串以获取被|分隔的数据,如果是public,则需要解析给定的食谱 id,如果给定的输入不合法,则打印一下错误日志。
对于create,我们通过给定的数据调用create_new_recipe函数。让我们查看一下与食谱的本地 JSON 存储交互所需的所有辅助函数。
#![allow(unused)] fn main() { async fn create_new_recipe(name: &str, ingredients: &str, instructions: &str) -> Result<()> { let mut local_recipes = read_local_recipes().await?; let new_id = match local_recipes.iter().max_by_key(|r| r.id) { Some(v) => v.id + 1, None => 0, }; local_recipes.push(Recipe { id: new_id, name: name.to_owned(), ingredients: ingredients.to_owned(), instructions: instructions.to_owned(), public: false, }); write_local_recipes(&local_recipes).await?; info!("Created recipe:"); info!("Name: {}", name); info!("Ingredients: {}", ingredients); info!("Instructions:: {}", instructions); Ok(()) } async fn publish_recipe(id: usize) -> Result<()> { let mut local_recipes = read_local_recipes().await?; local_recipes .iter_mut() .filter(|r| r.id == id) .for_each(|r| r.public = true); write_local_recipes(&local_recipes).await?; Ok(()) } async fn read_local_recipes() -> Result<Recipes> { let content = fs::read(STORAGE_FILE_PATH).await?; let result = serde_json::from_slice(&content)?; Ok(result) } async fn write_local_recipes(recipes: &Recipes) -> Result<()> { let json = serde_json::to_string(&recipes)?; fs::write(STORAGE_FILE_PATH, &json).await?; Ok(()) } }
最基本的构造代码块是read_local_recipes以及write_local_recipes,它们仅从存储中读取并反序列化食谱,以及序列化食谱并将其写入本地存储。
publish_recipe函数从文件中获取所有的食谱,通过给定的 ID 来查询食谱,并将它的public标记设置为 true。
当创建一个食谱时,我们也会从文件中读取所有的食谱,并在最后添加新的食谱,然后将全部数据写回并覆盖原文件。这不是很高效,但是它足够简单且可行。
使用libp2p发送消息
接下来让我们看下list命令,并探索如何将消息发送给其他成员。
在list命令中,这里可能有三种情况:
#![allow(unused)] fn main() { async fn handle_list_recipes(cmd: &str, swarm: &mut Swarm<RecipeBehaviour>) { let rest = cmd.strip_prefix("ls r "); match rest { Some("all") => { let req = ListRequest { mode: ListMode::ALL, }; let json = serde_json::to_string(&req).expect("can jsonify request"); swarm.floodsub.publish(TOPIC.clone(), json.as_bytes()); } Some(recipes_peer_id) => { let req = ListRequest { mode: ListMode::One(recipes_peer_id.to_owned()), }; let json = serde_json::to_string(&req).expect("can jsonify request"); swarm.floodsub.publish(TOPIC.clone(), json.as_bytes()); } None => { match read_local_recipes().await { Ok(v) => { info!("Local Recipes ({})", v.len()); v.iter().for_each(|r| info!("{:?}", r)); } Err(e) => error!("error fetching local recipes: {}", e), }; } }; } }
我们解析输入的命令,剥离 (strip) ls r部分,并检查是否还有剩余的部分命令。如果没有,我们仅读取本地的食谱并使用在之前定义的辅助函数将它们打印出来。
如果我们遇到了all关键字,我们将创建一个带有ListMode::ALL集合的ListRequest,将其序列化成 JSON,并在Swarm中使用FloodSub实例将其发布到之前提到的主题中。
如果我们在命令中遇到成员 ID,我们将仅发送带有该成员 ID 的ListMode::One。我们可以检查它是否是一个合法的成员 ID,或者是否是一个我们已经发现的成员 ID,但是为了保持简单:如果其上没有任何监听,则不会做任何处理。
这就是我们要向网络中发送消息所需要的一切。现在的问题是,这些消息会发生什么?它们在哪里被处理?
在本例中的 p2p 应用中,请记住我们既是事件的Sender也是事件的Receiver,因此在我们的实现中,需要处理输入以及响应事件。
使用libp2p对消息进行响应
我们的RecipeBehaviour终于在这里出现了。先对其进行定义:
#![allow(unused)] fn main() { #[derive(NetworkBehaviour)] struct RecipeBehaviour { floodsub: Floodsub, mdns: TokioMdns, #[behaviour(ignore)] response_sender: mpsc::UnboundedSender<ListResponse>, } }
behavior 本身仅仅是一个结构体,但是我们使用了libp2p中的NetworkBehaviour派生宏,因此我们不需要手动实现特征的所有函数。
这个派生宏为结构体中所有未声明behaviour(ignore)的成员实现了 NetworkBehaviour 特征。在这里我们忽略了 channel,因为它与我们的 behavior 没有直接的关系。
接下来就是为FloodsubEvent和MdnsEvent实现jnject_event函数。
先从mDNS开始:
#![allow(unused)] fn main() { impl NetworkBehaviourEventProcess<MdnsEvent> for RecipeBehaviour { fn inject_event(&mut self, event: MdnsEvent) { match event { MdnsEvent::Discovered(discovered_list) => { for (peer, _addr) in discovered_list { self.floodsub.add_node_to_partial_view(peer); } } MdnsEvent::Expired(expired_list) => { for (peer, _addr) in expired_list { if !self.mdns.has_node(&peer) { self.floodsub.remove_node_from_partial_view(&peer); } } } } } } }
当这个处理器接收到一个事件时,将会调用inject_event函数。对于mDNS来说,这里只有两种事件Discovered和Expired,它们将在当我们在网络中发现一个新的成员或者一个成员离开时被触发。在这两种情况下,我们都可以在FloodSub的部分视图中将其添加或移除,该视图是要将消息传播到的节点列表。
对于 pub/sub 事件来说,inject_event有点复杂。我们需要对传入的ListRequest和ListResponse有效负载做出反应。如果我们发送了ListRequest,成员将会接收到一个请求,该请求会拉取它本地发布的食谱,并将其返回。
将它们返回给请求成员的唯一方式就是在网络中发布它们的食谱。由于 pub/sub 是我们唯一的机制,因此我们需要对传入的请求以及响应做出反应。
让我们来看它是如何工作的:
#![allow(unused)] fn main() { impl NetworkBehaviourEventProcess<FloodsubEvent> for RecipeBehaviour { fn inject_event(&mut self, event: FloodsubEvent) { match event { FloodsubEvent::Message(msg) => { if let Ok(resp) = serde_json::from_slice::<ListResponse>(&msg.data) { if resp.receiver == PEER_ID.to_string() { info!("Response from {}:", msg.source); resp.data.iter().for_each(|r| info!("{:?}", r)); } } else if let Ok(req) = serde_json::from_slice::<ListRequest>(&msg.data) { match req.mode { ListMode::ALL => { info!("Received ALL req: {:?} from {:?}", req, msg.source); respond_with_public_recipes( self.response_sender.clone(), msg.source.to_string(), ); } ListMode::One(ref peer_id) => { if peer_id == &PEER_ID.to_string() { info!("Received req: {:?} from {:?}", req, msg.source); respond_with_public_recipes( self.response_sender.clone(), msg.source.to_string(), ); } } } } } _ => (), } } } }
我们匹配了传入的消息,并试图将其序列化成一个请求或响应。当我们接收到一个响应时,我们仅将带有调用者成员 ID 的响应打印出来,成员 ID 可以通过msg.source获取。当我们接收到一个请求时,我们需要区分ALL和One这两种情况。
对于One,我们检查给定的成员 ID 是否和我们一样 - 该请求其实是针对我们的。如果是,我们将返回发布的食谱,我们同样对ALL这样进行响应。
在这两种情况下,我们都将调用respond_with_public_recipes辅助函数:
#![allow(unused)] fn main() { fn respond_with_public_recipes(sender: mpsc::UnboundedSender<ListResponse>, receiver: String) { tokio::spawn(async move { match read_local_recipes().await { Ok(recipes) => { let resp = ListResponse { mode: ListMode::ALL, receiver, data: recipes.into_iter().filter(|r| r.public).collect(), }; if let Err(e) = sender.send(resp) { error!("error sending response via channel, {}", e); } } Err(e) => error!("error fetching local recipes to answer ALL request, {}", e), } }); } }
在这个辅助函数中,我们使用 Tokio 生成器异步执行 Future,该 Future 将读取所有的本地食谱,并以此创建一个ListResponse,然后通过channel_sender将数据发送给我们的事件循环,在事件循环中,我们将会这样处理:
#![allow(unused)] fn main() { EventType::Response(resp) => { let json = serde_json::to_string(&resp).expect("can jsonify response"); swarm.floodsub.publish(TOPIC.clone(), json.as_bytes()); } }
如果我们注意到“内部”通过Response事件发送,我们将其序列化成 JSON 格式并将其发送到网络中。
使用libp2p进行测试
上面那些是实现过程,现在让我们对其进行测试。
为了检查我们的实现是否工作,让我们在多个命令行中使用以下命令启动应用程序:
RUST_LOG=info cargo run
请注意,应用程序需要一个同级目录下的recipes.json文件。
当应用启动时,我们获取以下日志,并打印出成员 ID:
INFO rust_peer_to_peer_example > Peer Id: 12D3KooWDc1FDabQzpntvZRWeDZUL351gJRy3F4E8VN5Gx2pBCU2
现在,我们需要输入 enter 来启动事件循环。
输入ls p之后,我们获取到了发现的成员列表:
ls p
INFO rust_peer_to_peer_example > Discovered Peers:
INFO rust_peer_to_peer_example > 12D3KooWCK6X7mFk9HeWw69WF1ueWa3XmphZ2Mu7ZHvEECj5rrhG
INFO rust_peer_to_peer_example > 12D3KooWLGN85pv5XTDALGX5M6tRgQtUGMWXWasWQD6oJjMcEENA
使用 ls r,我们将获取到本地食谱:
ls r
INFO rust_peer_to_peer_example > Local Recipes (3)
INFO rust_peer_to_peer_example > Recipe { id: 0, name: " Coffee", ingredients: "Coffee", instructions: "Make Coffee", public: true }
INFO rust_peer_to_peer_example > Recipe { id: 1, name: " Tea", ingredients: "Tea, Water", instructions: "Boil Water, add tea", public: false }
INFO rust_peer_to_peer_example > Recipe { id: 2, name: " Carrot Cake", ingredients: "Carrots, Cake", instructions: "Make Carrot Cake", public: true }
调用ls r all将向其他所有成员发送一个请求,并返回它们的食谱:
ls r all
INFO rust_peer_to_peer_example > Response from 12D3KooWCK6X7mFk9HeWw69WF1ueWa3XmphZ2Mu7ZHvEECj5rrhG:
INFO rust_peer_to_peer_example > Recipe { id: 0, name: " Coffee", ingredients: "Coffee", instructions: "Make Coffee", public: true }
INFO rust_peer_to_peer_example > Recipe { id: 2, name: " Carrot Cake", ingredients: "Carrots, Cake", instructions: "Make Carrot Cake", public: true }
如果我们使用带有成员 ID 的ls r命令,将会发生同样的事情:
ls r 12D3KooWCK6X7mFk9HeWw69WF1ueWa3XmphZ2Mu7ZHvEECj5rrhG
INFO rust_peer_to_peer_example > Response from 12D3KooWCK6X7mFk9HeWw69WF1ueWa3XmphZ2Mu7ZHvEECj5rrhG:
INFO rust_peer_to_peer_example > Recipe { id: 0, name: " Coffee", ingredients: "Coffee", instructions: "Make Coffee", public: true }
INFO rust_peer_to_peer_example > Recipe { id: 2, name: " Carrot Cake", ingredients: "Carrots, Cake", instructions: "Make Carrot Cake", public: true }
它确实有用!你也可以在同样的网络中使用更多的客户端进行尝试。
你可以在 Github 中获取本教程的完整代码示例。
结论
在本文中我们介绍了如何使用 Rust 以及libp2p构建一个简单的,去中心化的应用程序。
如果你来自 web 后端,那么你对许多的网络概念可能都很熟悉,但是构建 p2p 应用程序仍然需要一种根本不同的设计和构建方法。
libp2p类库已经十分成熟,并且由于 Rust 在加密领域十分流行,因此出现了一个新兴的 (emerge),丰富的生态系统,用于构建功能强大的去中心化应用程序。
「转」Rust 的 Pin 和 Unpin
2019年2月28号,Rust 1.33版发布,增加了新的pinning API,主要包括这几个:
std::pin::Pinstd::marker::Unpinstd::marker::PhantomPinnedimpl !Unpin for T
刚开始接触这些概念的时候感觉特别绕,有点难理解透彻。网上也有不少讲Pin和Unpin的文章,但总感觉讲得不是特别清楚。直接去看 std::pin 模块的文档理解起来也挺有难度的。所以这篇文章我将尝试由浅入深的梳理一下Pin和Unpin,希望能帮助大家理解这些概念。
概念
我们先看一下Pin官方文档上的定义:
#![allow(unused)] fn main() { /// /// This is a wrapper around a kind of pointer which makes that pointer "pin" its /// value in place, preventing the value referenced by that pointer from being moved /// unless it implements [`Unpin`]. #[stable(feature = "pin", since = "1.33.0")] #[lang = "pin"] #[fundamental] #[repr(transparent)] #[derive(Copy, Clone)] pub struct Pin<P> { pointer: P, } #[stable(feature = "pin", since = "1.33.0")] impl<P: Deref> Deref for Pin<P> { type Target = P::Target; fn deref(&self) -> &P::Target { Pin::get_ref(Pin::as_ref(self)) } } #[stable(feature = "pin", since = "1.33.0")] impl<P: DerefMut<Target: Unpin>> DerefMut for Pin<P> { fn deref_mut(&mut self) -> &mut P::Target { Pin::get_mut(Pin::as_mut(self)) } } }
我先来从宏观层面解读一下。Pin是一个这样的智能指针,他内部包裹了另外一个指针 P,并且只要 P 指针指向的内容(我们称为 T )没有实现Unpin,则可以保证 T 永远不会被移动 (move)。Pin这个单词也很形象的表示Pin就像钉子一样可以把T钉住。所以Pin一般来说用Pin<P<T>>这种方式表示 (P 是 Pointer 的缩写,T 是 Type 的缩写)。这个定义初看有点绕,我们来划几个重点:
Pin自身是一个智能指针。为什么呢?因为他 impl 了Deref和DerefMut。Pin包裹的内容只能是指针,不能是其他普通类型。比如Pin<u32>就没有意义。Pin具有“钉住” T 不能移动的功能,这个功能是否生效取决于 T 是否 implUnpin。简单的说,如果 T 实现了Unpin,Pin的“钉住”功能完全失效了,这时候的Pin<P<T>>就等价于P<T>。Unpin是一个auto trait,编译器默认会给所有类型实现Unpin。唯独有几个例外,他们实现的是!Unpin。这几个例外是PhantomPinned,编译器为async/await desugar之后生成的implFuture的结构体。- 所以
Pin<P<T>>默认情况下的“钉住”功能是不生效的,只针对上面说的这几个impl!Unpin的情况生效。
看了这几条可能还有点懵,没关系,我们开始逐条剖析。首先要搞清楚的是到底什么是move以及为什么有些情况我们要防止move发生?
到底什么是move?
根据官方定义:所有权转移的这个过程就是move。我们先看一个大家都非常熟悉的例子:
fn main() { let mut s1 = String::from("Hello"); let s2 = s1; // s1的所有权转移给了s2,这里发生了move // let s3 = s1; // s1的所有权以及转移走了,不能再move,否则会报错:error[E0382]: use of moved value: `s1` }
基本概念这里不多解释了,我们需要搞明白的是let s2 = s1;这一行到底发生了什么事情。

借用了 TRPL 书上的这张图。s1和s2两个变量都是在栈上分配内存,字符串 “Hello” 是在堆上分配内存,其中ptr字段就是指向该字符串的指针。move发生的时候编译器会在栈上开辟一块新内存s2,然后原封不动把s1栈上的内容拷贝到s2,随即立马让原s1的内存失效。
再看一个 move 的列子:
fn main() { let mut x = String::from("xxx"); let mut y = String::from("yyy"); std::mem::swap(&mut x, &mut y); assert_eq!("yyy", &x); assert_eq!("xxx", &y); }
我们通过std::mem::swap()方法交换了两个可变借用&mut的内容,这里也发生了move。
像这两种move在 Rust 里面很稀松平常,使用起来丝毫不会引发什么问题。那到底是什么情况需要防止move的发生呢?
还真有,那就是自引用结构体!
自引用结构体的 move
自引用结构体 (Self-Referential Structs) 是一个这个样的结构体,它内部某个成员是对另外一个成员的引用。比如这样:
struct Test<'a> { a: String, b: &'a String, } fn main() { let a = String::from("Hello"); let _test = Test { a, b: &a }; // let _test = Test { a, b: &a }; // | - ^^ value borrowed here after move // | | // | value moved here }
但事实上我们没办法通过Safe Rust构造一个像 Test 这样的自引用结构体,Rust 目前对自引用结构体支持还很不完善。只能变通一下使用指针:
#![allow(unused)] fn main() { #[derive(Debug)] struct Test { a: String, b: *const String, // 改成指针 } impl Test { fn new(txt: &str) -> Self { Test { a: String::from(txt), b: std::ptr::null(), } } fn init(&mut self) { let self_ref: *const String = &self.a; self.b = self_ref; } fn a(&self) -> &str { &self.a } fn b(&self) -> &String { unsafe {&*(self.b)} } } }
我们来试一下这个自引用结构体的 move:
fn main() { let mut test1 = Test::new("test1"); test1.init(); let mut test2 = Test::new("test2"); test2.init(); println!("a: {}, b: {}", test1.a(), test1.b()); // 使用swap()函数交换两者,这里发生了move std::mem::swap(&mut test1, &mut test2); test1.a = "I've totally changed now!".to_string(); println!("a: {}, b: {}", test2.a(), test2.b()); }
这是打印结果:
a: test1, b: test1
a: test1, b: I've totally changed now!
有没有发现,出问题了!问题出在哪?原因是 Test 结构体中的字段 b 是一个指向字段 a 的指针,它在栈上存的是字段 a 的地址。通过swap()函数交换两个 Test 结构体之后,字段 a, b 分别移动到对方的内存区域上,但是 a 和 b 本身的内容没有变。也就是指针 b 依然指向的是原来的地址,但是这个地址现在已经属于另外一个结构体了!这不仅不是自引用结构体了,更可怕的是这个指针可能导致更危险的问题,这是 Rust 决不允许出现的!👇下面这张图可以帮助理解:
更关键的是 Rust 的Generator和async/await这一套都是基于自引用结构体实现的。如果不能从根源上解决这个问题,Rust 号称的Memory Safe的根基就完全动摇了。
更多关于async/await的原理,强烈推荐阅读这两本书:
- https://rust-lang.github.io/async-book
- https://cfsamson.github.io/books-futures-explained
所以我们来找一下导致这个问题的根源,然后想办法从根源上解决它!
根源是什么?
我们发现上面的例子最关键的一行代码是std::mem::swap(&mut test1, &mut test2),就是它导致了我们自引用结构体失效引发了内存安全问题。所以我们是不是只要避免这个swap()函数应用到我们自引用结构体上就行?可是怎么去避免呢?我们来看一下swap()方法的定义:
#![allow(unused)] fn main() { #[inline] #[stable(feature = "rust1", since = "1.0.0")] pub fn swap<T>(x: &mut T, y: &mut T) { // SAFETY: the raw pointers have been created from safe mutable references satisfying all the // constraints on `ptr::swap_nonoverlapping_one` unsafe { ptr::swap_nonoverlapping_one(x, y); } } }
它的参数要求是可变借用&mut,所以只要我们想办法让Safe Rust下不暴露可变借用即可!
还是以 Test 为例,它自身没办法限制自己不能可变借用,因为我们直接用&mut Test{...}就可以轻松拿到。那从标准库中去找找,Box<T>呢?先不考虑它性能问题,我们把结构体 T 包裹在Box中,看Box能不能保证不暴露&mut T出去。看一下 API 文档,很遗憾不能。Box::leak()返回值就是&mut T,更甚者Box impl 了DerefMut,就算不用leak()我们也可以通过* &mut Box<T>解引用轻松拿到&mut T!
不用找了,在Pin之前的标准库中确实没有这样的 API 能够防止在Safe Rust下不暴露&mut T。
所以,接下来是该Pin登场的时候了!
Pin 闪亮登场
我们找到了问题的根源在哪,Pin就是从根源上解决这个问题的。现在我们很清晰了,似乎是不是可以用一句话概括:Pin就是一个不会让你在Safe Rust暴露可变借用&mut的智能指针?
答案是:不全正确。这就是Pin概念起初让大家一脸懵逼的地方。下面让Pin自己来解答大家的疑惑,Pin说:“你们不是想让我保证被我包裹的指针P<T>永远钉住不让move吗?我可以答应,但我有一个原则。那就是我永远不能钉住持有通行证的朋友,这张通行证就是Unpin。如果没有这张通行证,请放心,我会把你钉得死死的!”
举个例子。比如我是Pin,你是P<T>,如果你 impl 了Unpin,我会提供两种办法让你在Safe Rust下拿到&mut T:
- 第一种,使用:
Pin::get_mut()
#![allow(unused)] fn main() { impl<'a, T: ?Sized> Pin<&'a mut T> { #[stable(feature = "pin", since = "1.33.0")] #[inline(always)] pub fn get_mut(self) -> &'a mut T where T: Unpin { self.pointer } } }
- 第二种,我 impl 了
DerefMut,你可以解引用拿到&mut T
#![allow(unused)] fn main() { #[stable(feature = "pin", since = "1.33.0")] impl<P: DerefMut<Target: Unpin>> DerefMut for Pin<P> { fn deref_mut(&mut self) -> &mut P::Target { Pin::get_mut(Pin::as_mut(self)) } } }
可rustc爸爸太宽容了,他默认给你们所有类型发了通行证(都实现了Unpin)!搞得我都几乎快要失业了!
#![allow(unused)] fn main() { #[lang = "unpin"] pub auto trait Unpin {} #[stable(feature = "pin", since = "1.33.0")] impl<'a, T: ?Sized + 'a> Unpin for &'a T {} #[stable(feature = "pin", since = "1.33.0")] impl<'a, T: ?Sized + 'a> Unpin for &'a mut T {} #[stable(feature = "pin_raw", since = "1.38.0")] impl<T: ?Sized> Unpin for *const T {} #[stable(feature = "pin_raw", since = "1.38.0")] impl<T: ?Sized> Unpin for *mut T {} }
唯一让我欣慰的是,他给我留了一个叫PhantomPinned的小伙伴。别看他名字很奇怪,他可是我很喜欢的得力助手!因为他实现的是!Unpin!
#![allow(unused)] fn main() { #[stable(feature = "pin", since = "1.33.0")] #[derive(Debug, Copy, Clone, Eq, PartialEq, Ord, PartialOrd, Hash)] pub struct PhantomPinned; #[stable(feature = "pin", since = "1.33.0")] impl !Unpin for PhantomPinned {} }
rustc爸爸还说,你们如果想“改邪归正”去掉Unpin也可以,有两种办法:
- 使用
PhantomPinned。有了它,rustc爸爸不会让你实现Unpin。
#![allow(unused)] fn main() { use std::marker::PhantomPinned; #[derive(Debug)] struct Test { a: String, b: *const String, _marker: PhantomPinned, } }
- 得自己手动impl
!Unpin。前提是你要使用nightly版本,并且需要引入#![feature(negative_impls)]:
#![allow(unused)] #![feature(negative_impls)] fn main() { #[derive(Debug)] struct Test { a: String, b: *const String, } impl !Unpin for Test {} }
满足以上任意两个条件之一的话,我就会保证你没办法在Safe Rust下拿到可变借用&mut T(不信你去翻翻我的 API),拿不到&mut T你就没办法作用到std::mem::swap()上,也就是说你被我钉住了!你以为rustc爸爸给我施了魔法么?你错了,我的工作原理就是这么简单!感谢 Rust 世界丰富而强大的类型系统,我的其他兄弟Sync,Send也是这样,我们都没有所谓的魔法!
当然我还是提供了一个unsafe的get_unchecked_mut(),不管你有没有实现Unpin,你都可以通过调用这个方法拿到&mut T,但是你需要遵守Pin的契约(参考下面),否则出了什么问题后果自负!
#![allow(unused)] fn main() { impl<'a, T: ?Sized> Pin<&'a mut T> { #[stable(feature = "pin", since = "1.33.0")] #[inline(always)] pub unsafe fn get_unchecked_mut(self) -> &'a mut T { self.pointer } } }
Pin的契约:
对于
Pin<P<T>>,
- 如果
P<T>符合Unpin,那P<T>从被Pin包裹到被销毁,都要一直保证P<T>不被钉住- 如果
P<T>符合!Unpin,那P<T>从被Pin包裹到被销毁,都要一直保证P<T>被钉住
通过以上Pin的自述,我们再用一句话来总结:如果你实现了Unpin,Pin可以让你在Safe Rust下拿到&mut T,否则会把你在Safe Rust下钉住(也就是拿不到&mut T)。
接下来我们使用Pin来修复一下上面自引用结构体的问题。
如何构造一个 Pin
首先我们要梳理清楚怎样把P<T>用Pin包裹起来,也就是怎样构造一个Pin。查看文档会发现主要有这几种方式:
Pin::new()
#![allow(unused)] fn main() { impl<P: Deref<Target: Unpin>> Pin<P> { #[stable(feature = "pin", since = "1.33.0")] #[inline(always)] pub fn new(pointer: P) -> Pin<P> { // Safety: the value pointed to is `Unpin`, and so has no requirements // around pinning. unsafe { Pin::new_unchecked(pointer) } } } }
如果你的 P 指向的 T 是Unpin的话,你可以安全的调用Pin::new()构造一个Pin。可以看到它底层实际上是调用unsafe的Pin::new_unchecked(),之所以Pin::new()是安全的,是因为Unpin的情况下Pin的”钉住“效果是不起作用的,跟正常的指针一样了。
Pin::new_unchecked()
#![allow(unused)] fn main() { impl<P: Deref> Pin<P> { #[stable(feature = "pin", since = "1.33.0")] #[inline(always)] pub unsafe fn new_unchecked(pointer: P) -> Pin<P> { Pin { pointer } } } }
这个方法很简单,但它是unsafe的。标为unsafe的原因是编译器没办法保证使用者后续操作一定遵守Pin的契约。只要有存在违反契约的可能性,就必须用unsafe标记,因为这是使用者的问题,编译器没办法保证。如果使用者通过Pin::new_unchecked()构造一个Pin<P<T>>之后Pin的生命周期结束了,但P<T>依然存在,则后续操作依然可能被move,造成内存不安全。
#![allow(unused)] fn main() { use std::mem; use std::pin::Pin; fn move_pinned_ref<T>(mut a: T, mut b: T) { unsafe { let p: Pin<&mut T> = Pin::new_unchecked(&mut a); // This should mean the pointee `a` can never move again. } mem::swap(&mut a, &mut b); // The address of `a` changed to `b`'s stack slot, so `a` got moved even // though we have previously pinned it! We have violated the pinning API contract. } }
其他
包括Box::pin(),Rc::pin()和Arc::pin()等,底层都是调用上面的Pin::new_unchecked(),不再阐述。
Pin 的应用
Pin可以分为栈上还是堆上,取决于你要Pin的那个指针 P 是在栈上还是堆上。比如Pin<&mut T>是栈上,Pin<Box<T>>是在堆上。
Pin 到栈上
use std::marker::PhantomPinned; #[derive(Debug)] struct Test { a: String, b: *const String, _marker: PhantomPinned, } impl Test { fn new(txt: &str) -> Self { Test { a: String::from(txt), b: std::ptr::null(), _marker: PhantomPinned, // This makes our type `!Unpin` } } fn init<'a>(self: Pin<&'a mut Self>) { let self_ptr: *const String = &self.a; let this = unsafe { self.get_unchecked_mut() }; this.b = self_ptr; } fn a<'a>(self: Pin<&'a Self>) -> &'a str { &self.get_ref().a } fn b<'a>(self: Pin<&'a Self>) -> &'a String { unsafe { &*(self.b) } } } pub fn main() { let mut test1 = unsafe { Pin::new_unchecked(&mut Test::new("test1")) }; Test::init(test1.as_mut()); let mut test2 = unsafe { Pin::new_unchecked(&mut Test::new("test2")) }; Test::init(test2.as_mut()); println!("a: {}, b: {}", Test::a(test1.as_ref()), Test::b(test1.as_ref())); std::mem::swap(test1.get_mut(), test2.get_mut()); println!("a: {}, b: {}", Test::a(test2.as_ref()), Test::b(test2.as_ref())); }
我们尝试把&mut Test钉在栈上,然后尝试去调用get_mut()作为参数传给std::mem::swap(),发现编译不通过。Rust 编译器从编译阶段就阻止我们去犯错了。
| std::mem::swap(test1.get_mut(), test2.get_mut());
| ^^^^^^^ within `Test`, the trait `Unpin` is not implemented for `PhantomPinned`
|
Pin 到堆上
use std::pin::Pin; use std::marker::PhantomPinned; #[derive(Debug)] struct Test { a: String, b: *const String, _marker: PhantomPinned, } impl Test { fn new(txt: &str) -> Pin<Box<Self>> { let t = Test { a: String::from(txt), b: std::ptr::null(), _marker: PhantomPinned, }; let mut boxed = Box::pin(t); let self_ptr: *const String = &boxed.as_ref().a; unsafe { boxed.as_mut().get_unchecked_mut().b = self_ptr }; boxed } fn a<'a>(self: Pin<&'a Self>) -> &'a str { &self.get_ref().a } fn b<'a>(self: Pin<&'a Self>) -> &'a String { unsafe { &*(self.b) } } } pub fn main() { let mut test1 = Test::new("test1"); let mut test2 = Test::new("test2"); println!("a: {}, b: {}",test1.as_ref().a(), test1.as_ref().b()); // std::mem::swap(test1.get_mut(), test2.get_mut()); // std::mem::swap(&mut *test1, &mut *test2); println!("a: {}, b: {}",test2.as_ref().a(), test2.as_ref().b()); }
这里使用Box::pin()把 Test 钉在了堆上。取消注释任意一行都会编译不通过,因为 Test 是!Unpin的。
Future
#![allow(unused)] fn main() { #[stable(feature = "futures_api", since = "1.36.0")] pub trait Future { type Output; fn poll(self: Pin<&mut Self>, cx: &mut Context<'_>) -> Poll<Self::Output>; } }
接下来讲一下Pin目前最重要的一个应用:Future。当初 2018 年官方异步组引入Pin API的初衷就是为了解决Future内部自引用的问题。因为async/await就是通过Generator实现的,Generator是通过匿名结构体实现的。如果async函数中存在跨await的引用,会导致底层Generator存在跨yield的引用,那根据Generator生成的匿名结构体就会是一个自引用结构体!然后这个自引用结构体会impl Future,异步的Runtime在调用Future::poll()函数查询状态的时候,需要一个可变借用(即&mut Self)。如果这个&mut Self不包裹在Pin里面的话,开发者自己impl Future就会利用std::mem::swap()之类的函数move掉&mut Self!所以这就是Future的poll()必须要使用Pin<&mut Self>的原因。
#![allow(unused)] fn main() { // 这个async块中存在跨await的借用! let mut fut = async { let to_borrow = String::from("Hello"); let borrowed = &to_borrow; SomeResource::some_task().await; println!("{} world!", borrowed); }; }
当然还有非常重要的一点不能忘了!Pin只对实现!Unpin的类型才有钉住的效果,这个impl Future的匿名结构体有impl !Unpin吗?当然有,前面说了只有几种特例是默认!Unpin,这个匿名结构体就是其中之一。
#![allow(unused)] fn main() { pub const fn from_generator<T>(gen: T) -> impl Future<Output = T::Return> where T: Generator<ResumeTy, Yield = ()>, { #[rustc_diagnostic_item = "gen_future"] struct GenFuture<T: Generator<ResumeTy, Yield = ()>>(T); // We rely on the fact that async/await futures are immovable in order to create // self-referential borrows in the underlying generator. impl<T: Generator<ResumeTy, Yield = ()>> !Unpin for GenFuture<T> {} impl<T: Generator<ResumeTy, Yield = ()>> Future for GenFuture<T> { type Output = T::Return; fn poll(self: Pin<&mut Self>, cx: &mut Context<'_>) -> Poll<Self::Output> { // SAFETY: Safe because we're !Unpin + !Drop, and this is just a field projection. let gen = unsafe { Pin::map_unchecked_mut(self, |s| &mut s.0) }; // Resume the generator, turning the `&mut Context` into a `NonNull` raw pointer. The // `.await` lowering will safely cast that back to a `&mut Context`. match gen.resume(ResumeTy(NonNull::from(cx).cast::<Context<'static>>())) { GeneratorState::Yielded(()) => Poll::Pending, GeneratorState::Complete(x) => Poll::Ready(x), } } } GenFuture(gen) } }
划重点impl <T: Generator<ResumeTy, Yield = ()>> !Unpin for GenFuture<T> {},只有亲眼所见才能让大家信服。
其他
Pin除了上面这些内容外还有其他几个概念,比如Pin projection,Structural pin和Non-structural pin,笔者自己用的也不多,详细可以看官方文档或查阅其他资料。
futures-rs 中还有不少和Pin有关的 API,如果深入使用futures-rs的话,不可避免的需要频繁的和Pin打交道。
总结
下面是摘抄自官方 Async Book 上关于Pin的黄金8条作为总结,这些几乎就是Pin API 的全部了。
- If T: Unpin (which is the default), then Pin<'a, T> is entirely equivalent to &'a mut T. in other words: Unpin means it's OK for this type to be moved even when pinned, so Pin will have no effect on such a type.
- Getting a &mut T to a pinned T requires unsafe if T: !Unpin.
- Most standard library types implement Unpin. The same goes for most "normal" types you encounter in Rust. A Future generated by async/await is an exception to this rule.
- You can add a !Unpin bound on a type on nightly with a feature flag, or by adding std::marker::PhantomPinned to your type on stable.
- You can either pin data to the stack or to the heap.
- Pinning a !Unpin object to the stack requires unsafe
- Pinning a !Unpin object to the heap does not require unsafe. There is a shortcut for doing this using Box::pin.
- For pinned data where T: !Unpin you have to maintain the invariant that its memory will not get invalidated or repurposed from the moment it gets pinned until when drop is called. This is an important part of the pin contract.
2018 年 Rust 异步组的核心成员 @withoutboats 在他个人博客分享了稳定async/await的整个心路历程,感觉这一路也是充满曲折。比如Pin刚开始还需要区分Pin,PinMut,PinBox等,现在精简到只需要一个Pin<P>就能搞定。还有更早的时候还计划引入一个叫Move的 trait 来标记该类型是否可以move等等。我这篇文章里面的代码基于 1.48 版,不确定Pin以后会不会有更新,而且Pin目前还存在一个unsoundness的问题。不管怎样,一切简单优雅的设计背后一定隐藏着复杂和艰辛,感谢 Rust 官方过去的努力,让我们能够有内存安全、无畏并发和符合人体工程的编程体验!
使用 GDB 调试 Rust 应用

根据你以前对编程语言和生态系统的了解,调试可能不是你从未做过的事情,或者说是你开发过程中绝对固定的流程。
举个例子,在 Java (Kotlin 或者其他 JVM 语言) 生态系统中,由于其复杂工具的悠久历史,许多人(包括我自己)在正常的开发周期中都依赖调试器。在许多动态类型的语言中,这个工作流未被广泛的采用。
当然,这些是概括。几乎每种编程语言都具有某种调试机制,但是开发人员是否使用调试器似乎取决于工具的质量和可用性以及他们正在从事的任务。
无论如何,拥有良好的调试能力是开发过程中的关键部分。在这篇 Rust GDB 教程中,我们将会向你展示如何使用最棒的 Rust 调试工具:GNU Project Debugger (GDB) 来调试 Rust 应用程序。
我们将涵盖以下内容:
GDB 是什么
GNU Project Debugger (GDB) 是 Richard Stallman 编写的极其古老的程序,它在 1986 年自称是“GNU 项目的首席 GNUisance”。GDB 支持多种语言,例如 C/C++ 以及现代语言如 GO 和 Rust。
GDB 是一个命令行应用程序,但是有很多的 GUI 界面以及 IDE 将它进行了集成。举个例子,一个现代的,基于浏览器的实现是 gdbgui。在本篇教程中,我们将使用它的命令行界面,因为它可以在任何地方运行,不需要外部依赖,并且足够简单,可以用于我们要完成的工作。
GDB 可以运行在 Linux,MacOS 以及 Windows 中,并且大多数 Linux 的发行版预装了 GDB。你可以阅读 GDB文档以获取平台的安装说明。
GDB 十分复杂且功能强大,因此在本教程中我们不会深入探讨 GDB。我们将使用它最基本的功能,如设置断点,运行程序,逐步执行,打印变量等等。
在 Rust 中设置 GDB
为了继续本文以下内容,你需要安装最新版的 Rust (1.39+) 以及最新版的 GDB (8.x+)。可能也需要一个 TCP 包的发送工具,比如:netcat。
同样,你需要确保在rustc的同级目录中有rust-gdb可执行程序。如果你使用 Rustup 安装并更新 Rust,这应该默认就存在的。
首先,创建一个新的 Rust 项目:
cargo new rust-gdb-example
cd rust-gdb-example
接下来,编辑Cargo.toml文件并添加你需要的依赖。
[dependencies]
tokio = { version = "1.1", features=["full"] }
在这里,我们只添加 Tokio 依赖,因为我们将构建一个非常基础的异步 TCP 示例来演示我们可以像调试“普通函数”那样调试异步函数。
在src/lib.rs中添加以下代码:
#![allow(unused)] fn main() { #[derive(Clone, Debug)] pub enum AnimalType { Cat, Dog, } #[derive(Clone, Debug)] pub struct Animal { pub kind: AnimalType, pub name: String, pub age: usize, } #[derive(Clone, Debug)] pub struct Person { pub name: String, pub pets: Vec<Animal>, pub age: usize, } }
这些只是我们将在示例程序中调试的基础类型。
rust-gdb是什么?
rust-gdb是 Rust (如:使用 Rustup) 安装时附带的预构建二进制文件,且会自动安装。
基本上,rust-gdb是将外部 Python 的 pretty-printing 脚本加载到 GDB 中的封装。在调试更加复杂的 Rust 程序时将很有用(并且在一定程度上是必需的),因为它可以显著改善 Rust 数据类型的显示。
举个例子,带有 pretty-printing 的Vec<Animal>代码如下所示:
#![allow(unused)] fn main() { Vec(size=3) = {rust_gdb_example::Animal {kind: rust_gdb_example::AnimalType::Cat, name: "Chip", age: 4}, rust_gdb_example::Animal {kind: rust_gdb_example::AnimalType::Cat, name: "Nacho", age: 6}, rust_gdb_example::Animal {kind: rust_gdb_example::AnimalType::Dog, name: "Taco", age: 2}} }
不带 pretty-printing 的代码如下所示:
#![allow(unused)] fn main() { alloc::vec::Vec<rust_gdb_example::Animal> {buf: alloc::raw_vec::RawVec<rust_gdb_example::Animal, alloc::alloc::Global> {ptr: core::ptr::unique::Unique<rust_gdb_example::Animal> {pointer: 0x5555555a1480, _marker: core::marker::PhantomData<rust_gdb_example::Animal>}, cap: 3, alloc: alloc::alloc::Global}, len: 3} }
pretty-printing 脚本为大多数广泛使用的 Rust 结构如Vec,Option,Result等提供了格式化,隐藏了它们的内部信息并展示了实际的 Rust 类型 - 这是我们在大多数时间都会感兴趣的内容。
这也是此时涉及 Rust 的调试方法的明显限制之一。如果你有复杂的嵌套的数据类型,你将需要知道它们的内部信息,或者使用某种黑魔法来正确的检查值。随着时间的流逝,这种情况会有所改善,但是从目前的情况来看,如果你使用这种方法调试复杂的实际软件,将会遇到问题。
在不进行设置的情况下,我们从一个示例程序开始,并使用它启动rust-gdb。
rust-gdb示例
让我们从一个在 Rust 中使用 GDB 的基本示例开始。
在你的项目中创建examples文件夹并添加带有以下内容的basic.rs文件:
use rust_gdb_example::*; fn main() { let animals: Vec<Animal> = vec![ Animal { kind: AnimalType::Cat, name: "Chip".to_string(), age: 4, }, Animal { kind: AnimalType::Cat, name: "Nacho".to_string(), age: 6, }, Animal { kind: AnimalType::Dog, name: "Taco".to_string(), age: 2, }, ]; get_chip(&animals); } fn get_chip(animals: &Vec<Animal>) { let chip = animals.get(0); println!("chip: {:?}", chip); }
这个非常简单的程序初始化了一个 animals 列表,并在最后调用了一个函数,该函数打印了 animals 列表中第一个元素。
为了调试这个程序,我们需要将其构建并使用rust-gdb执行构建的二进制文件。请确保使用调试模式对其进行构建而不是发布模式。
#![allow(unused)] fn main() { cargo build --example basic Finished dev [unoptimized + debuginfo] target(s) in 0.28s rust-gdb target/debug/examples/basic }
如果我们不是在构建示例,而是在构建二进制文件,二进制文件将在target/debug目录下。
在运行rust-gdb时,GDB 会打印几行欢迎信息和一个输入提示(gdb)。
如果你之前没有使用过 GDB,GDB cheat sheet 将会对你有所帮助。
我们可以通过使用break命令或缩写b来设置一个断点:
#![allow(unused)] fn main() { (gdb) b get_chip Breakpoint 1 at 0x13e3c: file examples/basic.rs, line 26. (gdb) info b Num Type Disp Enb Address What 1 breakpoint keep y 0x0000000000013e3c in basic::get_chip at examples/basic.rs:26 }
我们可以在某一行上设置断点(如:basic.rs:17),或者在某个函数中设置断点。我们可以使用info b来查看断点,它向我们展示了断点的位置,数字(以便我们可以删除,禁用或启用它),以及它是否被启用(Enb)。
info命令可以使用其他的选项,比如info locals,它展示了本地变量,info args,它显示了传入的函数参数以及更多的选项。
既然我们设置了断点,我们可以通过执行run(或r)来运行程序:
#![allow(unused)] fn main() { (gdb) r Starting program: /home/zupzup/dev/oss/rust/rust-gdb-example/target/debug/examples/basic [Thread debugging using libthread_db enabled] Using host libthread_db library "/lib/x86_64-linux-gnu/libthread_db.so.1". Breakpoint 1, basic::get_chip (animals=0x7fffffffd760) at examples/basic.rs:26 26 let chip = animals.get(0); }
它启动了程序。我们停在了定义的断点上,位于get_chip函数的第一行。在这里,我们可以查看函数的参数并尝试打印它们。
#![allow(unused)] fn main() { (gdb) info args animals = 0x7fffffffd760 (gdb) p animals <span class="katex"><span class="katex-html" aria-hidden="true"><span class="base"><span class="strut" style="height:0.64444em;vertical-align:0em;"></span><span class="mord">1</span><span class="mspace" style="margin-right:0.2777777777777778em;"></span><span class="mrel">=</span><span class="mspace" style="margin-right:0.2777777777777778em;"></span></span><span class="base"><span class="strut" style="height:1em;vertical-align:-0.25em;"></span><span class="mopen">(</span><span class="mord">∗</span><span class="mord mathnormal">m</span><span class="mord mathnormal">u</span><span class="mord mathnormal">t</span><span class="mord mathnormal">a</span><span class="mord mathnormal" style="margin-right:0.01968em;">ll</span><span class="mord mathnormal">oc</span><span class="mspace" style="margin-right:0.2777777777777778em;"></span><span class="mrel">::</span><span class="mspace" style="margin-right:0.2777777777777778em;"></span></span><span class="base"><span class="strut" style="height:0.43056em;vertical-align:0em;"></span><span class="mord mathnormal" style="margin-right:0.03588em;">v</span><span class="mord mathnormal">ec</span><span class="mspace" style="margin-right:0.2777777777777778em;"></span><span class="mrel">::</span><span class="mspace" style="margin-right:0.2777777777777778em;"></span></span><span class="base"><span class="strut" style="height:0.72243em;vertical-align:-0.0391em;"></span><span class="mord mathnormal" style="margin-right:0.22222em;">V</span><span class="mord mathnormal">ec</span><span class="mspace" style="margin-right:0.2777777777777778em;"></span><span class="mrel"><</span><span class="mspace" style="margin-right:0.2777777777777778em;"></span></span><span class="base"><span class="strut" style="height:0.980548em;vertical-align:-0.286108em;"></span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal">u</span><span class="mord mathnormal">s</span><span class="mord"><span class="mord mathnormal">t</span><span class="msupsub"><span class="vlist-t vlist-t2"><span class="vlist-r"><span class="vlist" style="height:0.15139200000000003em;"><span style="top:-2.5500000000000003em;margin-left:0em;margin-right:0.05em;"><span class="pstrut" style="height:2.7em;"></span><span class="sizing reset-size6 size3 mtight"><span class="mord mathnormal mtight" style="margin-right:0.03588em;">g</span></span></span></span><span class="vlist-s"></span></span><span class="vlist-r"><span class="vlist" style="height:0.286108em;"><span></span></span></span></span></span></span><span class="mord mathnormal">d</span><span class="mord"><span class="mord mathnormal">b</span><span class="msupsub"><span class="vlist-t vlist-t2"><span class="vlist-r"><span class="vlist" style="height:0.151392em;"><span style="top:-2.5500000000000003em;margin-left:0em;margin-right:0.05em;"><span class="pstrut" style="height:2.7em;"></span><span class="sizing reset-size6 size3 mtight"><span class="mord mathnormal mtight">e</span></span></span></span><span class="vlist-s"></span></span><span class="vlist-r"><span class="vlist" style="height:0.15em;"><span></span></span></span></span></span></span><span class="mord mathnormal">x</span><span class="mord mathnormal">am</span><span class="mord mathnormal" style="margin-right:0.01968em;">pl</span><span class="mord mathnormal">e</span><span class="mspace" style="margin-right:0.2777777777777778em;"></span><span class="mrel">::</span><span class="mspace" style="margin-right:0.2777777777777778em;"></span></span><span class="base"><span class="strut" style="height:0.73354em;vertical-align:-0.0391em;"></span><span class="mord mathnormal">A</span><span class="mord mathnormal">nima</span><span class="mord mathnormal" style="margin-right:0.01968em;">l</span><span class="mspace" style="margin-right:0.2777777777777778em;"></span><span class="mrel">></span></span><span class="base"><span class="strut" style="height:1em;vertical-align:-0.25em;"></span><span class="mclose">)</span><span class="mord">0</span><span class="mord mathnormal">x</span><span class="mord">7</span><span class="mord mathnormal">fffffffd</span><span class="mord">760</span><span class="mopen">(</span><span class="mord mathnormal" style="margin-right:0.03588em;">g</span><span class="mord mathnormal">d</span><span class="mord mathnormal">b</span><span class="mclose">)</span><span class="mord mathnormal">p</span><span class="mspace" style="margin-right:0.2222222222222222em;"></span><span class="mbin">∗</span><span class="mspace" style="margin-right:0.2222222222222222em;"></span></span><span class="base"><span class="strut" style="height:0.69444em;vertical-align:0em;"></span><span class="mord mathnormal">anima</span><span class="mord mathnormal" style="margin-right:0.01968em;">l</span><span class="mord mathnormal">s</span></span></span></span>2 = Vec(size=3) = {rust_gdb_example::Animal {kind: rust_gdb_example::AnimalType::Cat, name: "Chip", age: 4}, rust_gdb_example::Animal {kind: rust_gdb_example::AnimalType::Cat, name: "Nacho", age: 6}, rust_gdb_example::Animal {kind: rust_gdb_example::AnimalType::Dog, name: "Taco", age: 2}} }
info args命令提供了传入参数的概览。当我们使用p(print同样有用)打印 animals时,GDB 告诉我们处理的是指向Vec<Animal>的指针,但是并没有向我们展示任何有关Vec内容的信息,因为它只是一个指针。
你也可以使用display来打印变量,并且这里有很多格式的选项(如:字符串,指针,整型等)。print和display的区别是,使用display,在每次逐步执行指令之后,都会再次打印该值。这对于监控值的变更将很有用。
我们需要使用*animals来解引用指针。如果我们将其打印,我们会获得完整的,可读的 animal 列表。基础指针的戏法 (juggle) 以及类型转换是我们在引用结构体时处处需要的东西。
OK,我们现在在哪儿?让我们执行f或frame来查看我们到底在哪里:
#![allow(unused)] fn main() { (gdb) f 0 basic::get_chip (animals=0x7fffffffd760) at examples/basic.rs:26 26 let chip = animals.get(0); }
好吧,在我们设置的第一个断点那里。如果只有一种方法可以以图形化的方式来查看我们在源代码中的位置...
布局和检查状态
GDB 中的布局可以帮助你查看你处于 Rust 代码中什么位置上。使用layout src命令打开一个命令行界面:

我们的命令行提示在它的右下方。使用这种方式,我们再也不需要疑惑我们处于代码中什么位置上了。这里还有其他的布局,如layout split,它展示了代码以及相应的汇编:

看起来十分简洁。如果你想要摆脱这样的布局,你可以使用CTRL+X a。如果界面的渲染变混乱了,使用CTRL+L将会刷新界面(这会时而触发)。
与其他调试器一样,我们可以使用n或者next逐行执行代码,或者使用s或者step跳入函数内部。如果你想重复这个操作,你可以简单的按下回车键,然后上一个命令就会重复执行了。
让我们再往下执行,并在调用Vec<Animal>的.get方法查看chip变量的内部是什么:
#![allow(unused)] fn main() { (gdb) n 28 println!("chip: {:?}", chip); (gdb) p chip 3 = core::option::Option<&rust_gdb_example::Animal>::Some(0x5555555a1480) (gdb) print *(0x5555555a1480 as &rust_gdb_example::Animal) 4 = rust_gdb_example::Animal {kind: rust_gdb_example::AnimalType::Cat, name: "Chip", age: 4} }
我们执行n,现在我们处于下一行上 (28)。在这里,我们试图打印chip,然后我们看到它是一个Option类型,其中包含了一个Animal的引用。不幸的是,GDB 再一次只向我们展示了它的地址。我们需要将其转换成&rust_gdb_example::Animal,然后查看 animal 中真实的值。
一个很棒的事情就是大部分这些事情都是自动完成的。因此如果你键入rust_gd,并按下TAB键,这些都将自动完成。和AnimalType以及其他类型,函数,作用域中的变量一样。
我们也可以打印函数定义:
#![allow(unused)] fn main() { (gdb) p get_chip 11 = {fn (*mut alloc::vec::Vec<rust_gdb_example::Animal>)} 0x555555569370 <basic::get_chip> }
如果你想到这个函数的结尾处,我们可以使用finish,然后跳出并来到调用该函数的地方。如果我们使用当前的断点完成了某个调试,我们可以使用continue或者c来继续执行程序 - 在这里,将会简单的运行程序并到达它的结尾处。
#![allow(unused)] fn main() { (gdb) finish Run till exit from #0 basic::get_chip (animals=0x7fffffffd760) at examples/basic.rs:28 chip: Some(Animal { kind: Cat, name: "Chip", age: 4 }) 0x0000555555567d87 in basic::main () at examples/basic.rs:22 22 get_chip(&animals); (gdb) c Continuing. [Inferior 1 (process 61203) exited normally] }
这是不是很棒!这些都是你调试 Rust 程序的必要功能。让我们来查看另一个示例并探索更高级的技术。
操作状态和观察点
首先,让我们在examples文件夹下的nested.rs文件中创建另一个示例:
use rust_gdb_example::*; fn main() { let animals: Vec<Animal> = vec![ Animal { kind: AnimalType::Cat, name: "Chip".to_string(), age: 4, }, Animal { kind: AnimalType::Cat, name: "Nacho".to_string(), age: 6, }, Animal { kind: AnimalType::Dog, name: "Taco".to_string(), age: 2, }, ]; let mut some_person = Person { name: "Some".to_string(), pets: animals, age: 24, }; println!("person: {:?}", some_person); some_person.age = 100; some_person.name = some_func(&some_person.name); } fn some_func(name: &str) -> String { name.chars().rev().collect() }
我们再一次创建了 animal 列表。但是这一次,我们也创建了Person并将 animals 设置为他们的宠物。而且,我们会打印 person,将他们的年龄设置为100并重置他们的名字(这是 some_func 做得事情)。
在我们调试这个程序之前,我们需要再一次构建它,并使用rust-gdb执行二进制文件:
cargo build --example nested
rust-gdb target/debug/examples/nested
感觉真不错。让我们在第 22 行和第 27 行设置断点并运行该程序:
#![allow(unused)] fn main() { (gdb) b nested.rs:22 Breakpoint 1 at 0x17abf: file examples/nested.rs, line 22. (gdb) b nested.rs:27 Breakpoint 2 at 0x17b13: file examples/nested.rs, line 27. (gdb) info b Num Type Disp Enb Address What 1 breakpoint keep y 0x0000000000017abf in nested::main at examples/nested.rs:22 2 breakpoint keep y 0x0000000000017b13 in nested::main at examples/nested.rs:27 (gdb) r Starting program: /home/zupzup/dev/oss/rust/rust-gdb-example/target/debug/examples/nested [Thread debugging using libthread_db enabled] Using host libthread_db library "/lib/x86_64-linux-gnu/libthread_db.so.1". Breakpoint 1, nested::main () at examples/nested.rs:22 22 let mut some_person = Person { }
我们在第一个断点处,该位置创建了 person。让我们继续打印语句。接着,我们将在some_person.age设置所谓的观察点。这个观察点将会在some_person.age每一次改变的时候通知我们。
#![allow(unused)] fn main() { (gdb) c (gdb) watch some_person.age Hardware watchpoint 3: some_person.age (gdb) n person: Person { name: "Some", pets: [Animal { kind: Cat, name: "Chip", age: 4 }, Animal { kind: Cat, name: "Nacho", age: 6 }, Animal { kind: Dog, name: "Taco", age: 2 }], age: 24 } 28 some_person.age = 100; (gdb) n Hardware watchpoint 3: some_person.age Old value = 24 New value = 100 0x000055555556bba8 in nested::main () at examples/nested.rs:28 28 some_person.age = 100; }
GDB 向我们展示了哪一个观察点被触发,以及对应的新值和旧值。
让我们再一次通过调用run来重新运行该程序,并确认我们想要重新运行。这次,当我们来到第二个断点处时,让我们通过使用set来手动修改它的值:
#![allow(unused)] fn main() { (gdb) set some_person.age = 22 (gdb) p some_person 1 = rust_gdb_example::Person {name: "Some", pets: Vec(size=3) = {rust_gdb_example::Animal {kind: rust_gdb_example::AnimalType::Cat, name: "Chip", age: 4}, rust_gdb_example::Animal {kind: rust_gdb_example::AnimalType::Cat, name: "Nacho", age: 6}, rust_gdb_example::Animal {kind: rust_gdb_example::AnimalType::Dog, name: "Taco", age: 2}}, age: 22} }
如你所见,我们可以使用set ..args来操作我们变量的状态。这在原始类型中可以很好的工作,但是对于复杂的值,略微有些棘手 (tricky),如 Rust 标准库 或者外部第三方的 crate 中的类型。这是另一个缺点 (drawback),但是在将来有希望会所有改善。
另一个很棒的特性是我们可以试图执行函数并查看它们的返回值:
#![allow(unused)] fn main() { (gdb) p some_func("Hello") <span class="katex"><span class="katex-html" aria-hidden="true"><span class="base"><span class="strut" style="height:0.64444em;vertical-align:0em;"></span><span class="mord">3</span><span class="mspace" style="margin-right:0.2777777777777778em;"></span><span class="mrel">=</span><span class="mspace" style="margin-right:0.2777777777777778em;"></span></span><span class="base"><span class="strut" style="height:1.036108em;vertical-align:-0.286108em;"></span><span class="mord">"</span><span class="mord mathnormal">o</span><span class="mord mathnormal" style="margin-right:0.01968em;">ll</span><span class="mord mathnormal" style="margin-right:0.08125em;">eH</span><span class="mord">"</span><span class="mopen">(</span><span class="mord mathnormal" style="margin-right:0.03588em;">g</span><span class="mord mathnormal">d</span><span class="mord mathnormal">b</span><span class="mclose">)</span><span class="mord mathnormal">p</span><span class="mord mathnormal">so</span><span class="mord mathnormal">m</span><span class="mord"><span class="mord mathnormal">e</span><span class="msupsub"><span class="vlist-t vlist-t2"><span class="vlist-r"><span class="vlist" style="height:0.3361079999999999em;"><span style="top:-2.5500000000000003em;margin-left:0em;margin-right:0.05em;"><span class="pstrut" style="height:2.7em;"></span><span class="sizing reset-size6 size3 mtight"><span class="mord mathnormal mtight" style="margin-right:0.10764em;">f</span></span></span></span><span class="vlist-s"></span></span><span class="vlist-r"><span class="vlist" style="height:0.286108em;"><span></span></span></span></span></span></span><span class="mord mathnormal">u</span><span class="mord mathnormal">n</span><span class="mord mathnormal">c</span><span class="mopen">(</span><span class="mord">"</span><span class="mord mathnormal">De</span><span class="mord mathnormal">b</span><span class="mord mathnormal" style="margin-right:0.03588em;">ug</span><span class="mord">"</span><span class="mclose">)</span></span></span></span>4 = "gubeD" (gdb) p some_func(some_person.name) <span class="katex"><span class="katex-html" aria-hidden="true"><span class="base"><span class="strut" style="height:0.64444em;vertical-align:0em;"></span><span class="mord">5</span><span class="mspace" style="margin-right:0.2777777777777778em;"></span><span class="mrel">=</span><span class="mspace" style="margin-right:0.2777777777777778em;"></span></span><span class="base"><span class="strut" style="height:1.036108em;vertical-align:-0.286108em;"></span><span class="mord">"</span><span class="mord mathnormal">e</span><span class="mord mathnormal">m</span><span class="mord mathnormal">o</span><span class="mord mathnormal" style="margin-right:0.05764em;">S</span><span class="mord">"</span><span class="mopen">(</span><span class="mord mathnormal" style="margin-right:0.03588em;">g</span><span class="mord mathnormal">d</span><span class="mord mathnormal">b</span><span class="mclose">)</span><span class="mord mathnormal">se</span><span class="mord mathnormal">t</span><span class="mord mathnormal">so</span><span class="mord mathnormal">m</span><span class="mord"><span class="mord mathnormal">e</span><span class="msupsub"><span class="vlist-t vlist-t2"><span class="vlist-r"><span class="vlist" style="height:0.15139200000000003em;"><span style="top:-2.5500000000000003em;margin-left:0em;margin-right:0.05em;"><span class="pstrut" style="height:2.7em;"></span><span class="sizing reset-size6 size3 mtight"><span class="mord mathnormal mtight">p</span></span></span></span><span class="vlist-s"></span></span><span class="vlist-r"><span class="vlist" style="height:0.286108em;"><span></span></span></span></span></span></span><span class="mord mathnormal">erso</span><span class="mord mathnormal">n</span><span class="mord">.</span><span class="mord mathnormal">nam</span><span class="mord mathnormal">e</span><span class="mspace" style="margin-right:0.2777777777777778em;"></span><span class="mrel">=</span><span class="mspace" style="margin-right:0.2777777777777778em;"></span></span><span class="base"><span class="strut" style="height:1.036108em;vertical-align:-0.286108em;"></span><span class="mord mathnormal">so</span><span class="mord mathnormal">m</span><span class="mord"><span class="mord mathnormal">e</span><span class="msupsub"><span class="vlist-t vlist-t2"><span class="vlist-r"><span class="vlist" style="height:0.3361079999999999em;"><span style="top:-2.5500000000000003em;margin-left:0em;margin-right:0.05em;"><span class="pstrut" style="height:2.7em;"></span><span class="sizing reset-size6 size3 mtight"><span class="mord mathnormal mtight" style="margin-right:0.10764em;">f</span></span></span></span><span class="vlist-s"></span></span><span class="vlist-r"><span class="vlist" style="height:0.286108em;"><span></span></span></span></span></span></span><span class="mord mathnormal">u</span><span class="mord mathnormal">n</span><span class="mord mathnormal">c</span><span class="mopen">(</span><span class="mord mathnormal">so</span><span class="mord mathnormal">m</span><span class="mord"><span class="mord mathnormal">e</span><span class="msupsub"><span class="vlist-t vlist-t2"><span class="vlist-r"><span class="vlist" style="height:0.15139200000000003em;"><span style="top:-2.5500000000000003em;margin-left:0em;margin-right:0.05em;"><span class="pstrut" style="height:2.7em;"></span><span class="sizing reset-size6 size3 mtight"><span class="mord mathnormal mtight">p</span></span></span></span><span class="vlist-s"></span></span><span class="vlist-r"><span class="vlist" style="height:0.286108em;"><span></span></span></span></span></span></span><span class="mord mathnormal">erso</span><span class="mord mathnormal">n</span><span class="mord">.</span><span class="mord mathnormal">nam</span><span class="mord mathnormal">e</span><span class="mclose">)</span><span class="mopen">(</span><span class="mord mathnormal" style="margin-right:0.03588em;">g</span><span class="mord mathnormal">d</span><span class="mord mathnormal">b</span><span class="mclose">)</span><span class="mord mathnormal">p</span><span class="mord mathnormal">so</span><span class="mord mathnormal">m</span><span class="mord"><span class="mord mathnormal">e</span><span class="msupsub"><span class="vlist-t vlist-t2"><span class="vlist-r"><span class="vlist" style="height:0.15139200000000003em;"><span style="top:-2.5500000000000003em;margin-left:0em;margin-right:0.05em;"><span class="pstrut" style="height:2.7em;"></span><span class="sizing reset-size6 size3 mtight"><span class="mord mathnormal mtight">p</span></span></span></span><span class="vlist-s"></span></span><span class="vlist-r"><span class="vlist" style="height:0.286108em;"><span></span></span></span></span></span></span><span class="mord mathnormal">erso</span><span class="mord mathnormal">n</span></span></span></span>6 = rust_gdb_example::Person {name: "emoS", pets: Vec(size=3) = {rust_gdb_example::Animal {kind: rust_gdb_example::AnimalType::Cat, name: "Chip", age: 4}, rust_gdb_example::Animal {kind: rust_gdb_example::AnimalType::Cat, name: "Nacho", age: 6}, rust_gdb_example::Animal {kind: rust_gdb_example::AnimalType::Dog, name: "Taco", age: 2}}, age: 22} }
我们可以调用作用域内的some_func函数,它需要传入一个字面量字符串。我们可以通过some_person.name对其进行调用,并可以使用set来重置some_person.name的值。
这个功能十分强大,并且可以在调试期间影响到表达式与函数的结果,这有助于发现并解决问题。它对于解决一些简单的场景十分有用,但是如果你试图执行一个包含 I/O 或其他更复杂的操作的函数时,你可能会遇到障碍。但是对于 99% 的场景,已有的功能可以很好的完成工作。
说到 I/O,让我们查看最后一个示例:如何使用 GDB 调试 Rust 中的异步网络应用。
调试一个异步网络应用
最后同样重要的是,我们将会试图调试一个异步网络应用,运行在 tokio 异步运行时中。
让我们在examples文件夹下创建tokio.rs:
use std::io; use tokio::io::AsyncWriteExt; use tokio::net::{TcpListener, TcpStream}; #[tokio::main] async fn main() -> io::Result<()> { let listener = TcpListener::bind("127.0.0.1:8080").await?; println!("Accepting TCP on port 8080"); loop { let (socket, _) = listener.accept().await?; tokio::spawn(async move { process(socket).await }); } } async fn process(mut socket: TcpStream) { socket .write_all(b"Hello") .await .expect("can write to socket"); }
这是一个非常简单的程序,它在本地8080端口开启了一个 TCP 监听,对于每一个接入的连接,异步调用process函数来处理请求。
process函数简单的写回一个Hello,这让它其成为最简单的“网络应用”。
然而,我们在这里并不追求复杂性。相反,我们正在尝试确定在调试异步程序(如 Web 服务器)时使用 GDB 的工作流程是否发生了变化。
让我们编译这个示例并使用生成的二进制文件启动rust-gdb:
cargo build --example tokio
rust-gdb target/debug/examples/tokio
到目前为止还挺好。
让我们在第 17 行的process函数的开始部分设下一个断点:
#![allow(unused)] fn main() { (gdb) b tokio.rs:17 (gdb) info b Num Type Disp Enb Address What 1 breakpoint keep y <MULTIPLE> 1.1 y 0x000000000009aa87 in tokio::process::{{closure}} at examples/tokio.rs:17 1.2 y 0x00000000000a57fa in tokio::process at examples/tokio.rs:17 }
有趣的是,断点被分为了1.1和1.2。这在 GDB 中被称为位置。发生这种情况的原因可能是因为优化,比如内联 (inline),举个例子,GDB 将在内联或模版化的函数中设下断点。我假设这是因为tokio::main宏,它将所有的代码都封装在了 Tokio 运行时中。
如果我们愿意,我们可以禁用每一个位置,但是在本例中这不是重点。让我们运行下这个程序:
#![allow(unused)] fn main() { (gdb) r Starting program: /home/zupzup/dev/oss/rust/rust-gdb-example/target/debug/examples/tokio [Thread debugging using libthread_db enabled] Using host libthread_db library "/lib/x86_64-linux-gnu/libthread_db.so.1". [New Thread 0x7ffff7c1e700 (LWP 55035)] [New Thread 0x7ffff7a1d700 (LWP 55036)] [New Thread 0x7ffff781c700 (LWP 55037)] [New Thread 0x7ffff761b700 (LWP 55038)] [New Thread 0x7ffff741a700 (LWP 55039)] [New Thread 0x7ffff7219700 (LWP 55040)] [New Thread 0x7ffff7018700 (LWP 55041)] [New Thread 0x7ffff6e17700 (LWP 55042)] Accepting TCP on port 8080 }
我们的监听器已经启动并正在运行,我们甚至可以看到 Tokio 运行时在后台生成的线程。
让我们使用netcat在其他终端会话中发送一些数据到这个 endpoint 中。
nc 127.0.0.1 8080
这将触发process中的断点:
#![allow(unused)] fn main() { [Switching to Thread 0x7ffff6e17700 (LWP 55041)] Thread 9 "tokio-runtime-w" hit Breakpoint 1, tokio::process::{{closure}} () at examples/tokio.rs:18 18 socket (gdb) p socket 4 = tokio::net::tcp::stream::TcpStream {io: tokio::io::poll_evented::PollEvented<mio::net::tcp::stream::TcpStream> {io: core::option::Option<mio::net::tcp::stream::TcpStream>::Some(mio::net::tcp::stream::TcpStream {inner: mio::io_source::IoSource<std::net::tcp::TcpStream> {state: mio::sys::unix::IoSourceState, inner: std::net::tcp::TcpStream (std::sys_common::net::TcpStream {inner: std::sys::unix::net::Socket (std::sys::unix::fd::FileDesc {fd: 11})}), selector_id: mio::io_source::SelectorId {id: core::sync::atomic::AtomicUsize {v: core::cell::UnsafeCell<usize> {value: 1}}}}}), registration: tokio::io::driver::registration::Registration {handle: tokio::io::driver::Handle {inner: alloc::sync::Weak<tokio::io::driver::Inner> {ptr: core::ptr::non_null::NonNull<alloc::sync::ArcInner<tokio::io::driver::Inner>> {pointer: 0x55555573a560}}}, shared: tokio::util::slab::Ref<tokio::io::driver::scheduled_io::ScheduledIo> {value: 0x55555573ec20}}}} (gdb) c }
当断点被触发,GDB 通知我们这发生在运行时生成的其中一个线程中,并且我们拥有一个socket变量,我们可以对其施加影响。
socket是一个 Tokio 的 TcpStream,但是我们并不能从打印它中了解到什么。在这里,数字11代表着一个文件修饰符,它可以打开一个网络连接,但是其余的可能是 Tokio 和 mio 的内部信息。
无论如何,它确实工作了 - 我们成功的在多线程中运行的异步处理器中设置了一个断点。这意味着如果有相同的方法同样会奏效,举个例子,一个运行的 Actix 或 warp 的 web 服务器,在其中一个处理函数中设置了一个断点,来对传入的 HTTP 请求数据施加影响。
在我们使用c继续执行后,我们第二个终端中显示了Hello的响应。
#![allow(unused)] fn main() { nc 127.0.0.1 8080 Hello }
我们使用 GDB 调试 Rust 应用程序的旅程到此结束。
你可以在 Github 获取本例的完整代码。
结论
在这篇 Rust 调试教程中,我们演示了如何使用 GDB 调试一个 Rust 应用程序。在大多数情况下,如果你要做的只是逐步执行具有断点的程序,那么它可以工作的很好,尤其是带了rust-gdb pretty-printing 扩展的程序。
当涉及更加复杂的功能时,你可能已经习惯于使用其他语言复杂的 GUI 调试器,这是一个活跃的开发领域,我希望 Rust 的调试生态系统可以得到改善。与 Java 和 C/C++ 中最好的调试器相比,Rust 将花费多长时间以及整体调试体验将有多好,这很难说,这取决于 Rust 中对此类工具的需求。
本篇教程的目的是为你提供一个工具,以最少的额外功能或必要知识来调试 Rust 程序。该背景应当涵盖你在 Rust 编程中将遇到的大多数情况.
解释 Rust 中的原子性
当处理原子性以及内存排序选项时理解它们可以帮助我们更好的理解多线程编程以及为什么 Rust 可以帮助我们编写安全高性能的多线程代码。
尝试通过阅读随机的文章或者 Rust (或 C++) 中的文档来理解原子性,就像是通过逆向工程E = MC^2来学物理一样。
我将会在本文中尽最大的努力来向你我解释这个概念。如果我成功了,比例将会是WTF?/AHA! < 1。
多处理器编程
当我们为多个 CPU 编写代码时,有一些细微的 (subtle) 的事情需要考虑。你将看到,如果编译器或 CPU 认为重排我们编写的代码可以获得更快的执行速度,它们就会这么做。在单线程的程序中,我们不需要考虑什么,但是一旦我们开始编写多线程程序时,编译器重排可能就会给我们带来问题。
然而,虽然编译器的顺序可以通过查看反汇编的代码进行检查,当系统运行在多个 CPU 之上时,事情可能会变得更加复杂。
当线程在不同的 CPU 上运行时,CPU 内部的指令重排可以导致一些难以调试的问题,因为我们大多数时候观察的只是 CPU 重排,执行推断 (speculative),流水线 (pipeline) 以及缓存的副作用。
我也不认为 CPU 可以提前知道它将如何运行你的代码。
原子性解决的问题与内存的加载与存储有关。任何不会操作内存的指令重排都不会对我们关心的内容产生影响。
除非另有说明,否则我在这里将使用一个主要参考:Intel® 64 and IA-32 Architectures Software Developer’s Manual Volume 3A。因此当我说参考了 Intel 开发人员参考手册的某一章节,便指的是这篇文章。
让我们从最底层开始,用适合我们的方式来获取更好的理解。
强 vs 弱内存排序
首先,我们需要正确的理解一些概念。在处理内存方面,CPU 提供了不同的保证。我们可以将其区分为从弱 (Weak) 到强 (Strong)。但是,这不是一个精确的规范,因此有些模型介于两者之间。
为了抽象这些差异,Rust 有一个抽象机的概念。它从 C++ 中借用了这个模型。这个抽象机需要一个抽象,它可以针对弱 CPU 和强 CPU (以及介于两者之间的状态)编程。
你可以看到,C++ 抽象机指定了很多访问内存的方式。如果我们在相同语言中针对强弱处理器应该使用相同的语义,则必须使用这些访问内存的方式。
具有强内存模型的 CPU 提供了一些重要的保证,让我们在抽象机中使用的语义不会做任何操作。这一点也不花哨,这仅是对编译器的提示,让其不要对程序员编写的内存操作顺序做任何改变。
然而在使用弱内存模型的系统中,可能需要设置内存栏栅或使用特殊的指令来防止同步问题。根据经验学习这种抽象机的最好方式是使用具有弱有序的 CPU。然而,因为大多数程序员都是在具有强内存模型的 CPU 上编程,因此我们将只需要指出差异就可以理解为什么该语义是它们表现的那样。
目前大多数使用 AMD 或 Intel 处理器的电脑都使用强有序。这就意味着 CPU 会保证不会重排确定的操作顺序。可以在 Intel 开发人员手册第 8.2.2 节找到这个保证的相关示例。
- 读操作不会和其他读操作重新排序。
- 写操作不会和旧的读操作重新排序。
- 写内存操作不会和其他(带有异常的)写操作重新排序。
重要的是,它还包含一个不受保证的示例:
- 读操作可能会与旧的写到不同地址的操作重新排序,但是不会与写到相同地址的操作重新排序。
最后一个示例对于理解后面的SeqCst内存排序至关重要,现在这里只是为它做个说明。
现在,在之后的章节,我将会试图理清它们的差异。但是我仍将使用抽象机的弱模型作为解释的基础...
⚠️ 我将指出使用这个提示的强有序 CPU 的差异。
CPU 缓存
通常,一个 CPU 有三种级别的缓存:L1,L2,L3。其中 L2 和 L3在各个核心之间共享,L1 是每个核心的缓存。我们的挑战就在这里开始。
L1 缓存使用了某种 MESI 缓存协议。名字听起来可能很神秘,但是该协议其实很简单。它是缓存中以下不同状态的首字母缩写 (acronym):
这些状态适用于 L1 缓存中的每一个缓存行:
(M) Modified - 修改(脏数据)。需要将数据写回主内存。
(E) Exclusive - 只存在 L1 缓存中。不需要被同步(清理)。
(S) Shared - 可能存在其他的缓存中。目前与主内存一起使用。
(I) Invalid - 缓存行是无效的。其他缓存可能会将其修改。
在 Intel 开发者手册的第 11.4 节中,有更多关于缓存状态的描述。
我们可以通过对 CPU 中的每一个缓存行分配一个带有四种状态的枚举,对 L1 缓存进行建模。
这听起来是不是很熟悉?
在 Rust 中我们有两种类型的引用 & 共享引用 (shared references) 和 &mut 独占引用(exclusive references)。
如果你不再将它们视为
mutable和immutable,这将对你有很大的帮助。因为并非一直如此。允许内部可变性 (interior mutability) 的原子和类型确实打破了这种心智模型。相反,我们应当将它们视为exclusive和shared。这确实可以很好的映射到 E 和 S (L1 缓存中可能存在的两种状态数据)。在语言中对其进行建模可以很好的提供一些优化,而其他不存在这些语义的语言却无法做到。
在 Rust 中,只有内存是
Exclusive且默认可以被修改。这意味着,只要我们不会打破规则以及可变的
Shared引用,所有的 Rust 程序可以假设运行在核心上的 L1 缓存是最新的,不需要做任何同步。当然,许多程序需要在核心之间
Shared内存才能工作,但是明确并谨慎这么做可以更好的让代码在多处理器上运行。
处理器之间的通信
如果我们确实想要访问并改变Shared内存,其他的核心是如何知道它们的 L1 缓存是非法的呢?
如果数据存在不同核心的 L1 缓存中(请记住,它处于Shared状态)并被修改时,缓存行是无效的。为了通知其他核心它们的缓存数据是无效的,就必须有一些可以在核心之间通信的方式,对吗?
是的,确实如此,但是,很难找到有关确切详细信息的文档。每个核心都有一个我们可以当作邮箱的东西。
该邮箱可以缓存一定数量的消息。每条缓存的消息总是可以避免中断 CPU 并且强制它立即处理发往其他核心的每条消息。
现在,CPU 会在某个时刻检查该邮箱并相应的更新其缓存。
让我们举一个关于标记为Shared缓存行的一个示例。
如果 CPU 修改了这个缓存行,它在其他缓存中就会无效。修改数据的核心会向其余的 CPU 发送一条消息。当其他核心检查它们的邮箱时,它们将会发现当前这个缓存行是无效的,然后它的状态会在其他核心中的每个缓冲中相应的更新。
在每个核心上的 L1 缓存接着在主内存(或 L2/L3 缓存)中拉取正确的值,并将它的装态重新设置为Shared。
⚠️ 在强有序的 CPU 中,这个模型以几种不同的方式进行工作。如果一个核心修改了一个
Shared缓存行,它将会在这个值实际被修改之前,强制其他核心将相应的缓存行设置为无效。这样的 CPU 有一个 缓存连贯性 (coherency) 机制,它可以改变其他核心中缓存的状态。
内存排序
既然我们对如何设计 CPU 之间的协调有了一些了解,我们可以介绍一些不同的内存排序以及它们的含义。
在 Rust 中,std::sync::atomic::Ordering 代表内存排序,它有 5 个可能的值。
心智模型
实际上,由于 Rust 的类型系统,很难对其构建一个心智模型(如:我们无法获取一个Atomic的指针),但是我发现想象一个观察者核心(即一个核心作为观察者)很有用。处于某种原因,这个观察者核心对我们执行原子操作的同一块内存很感兴趣,所以我们将每个模型一分为二:它在运行的核心上看起来怎样以及在观察者核心上看起来怎样。
请记住,Rust 从 C++20 中继承了原子的内存模型,C 同样也是从 C++ 中拷贝的。在这些语言中,类型系统不会像在 Safe Rust 中一样约束你,因此使用指针访问
Atomic更容易。
Relaxed
在当前 CPU 中:
原子性中的 Relaxed 内存排序将会阻止编译器进行指令重排,但是,在弱排序的 CPU 中,它可能会重排所有其他的内存访问顺序。如果你只是将计数器加 1,那当然没有问题,但是如果你使用了一个 flag 实现了自旋锁 (spin-lock),它可能会给你带来一些问题,因为你不相信 flag 前后的“正常”内存访问已被设置,没有重新排序。
在观察者 CPU 中:
编译器和 CPU 都可以自由地对其他任何内存访问进行过重排,除了彼此切换两个Relaxed的加载/存储。观察者核心可能观察到操作的顺序与我们代码中编写的顺序不一样。如果我们按此顺序编写它们,它们将始终可以在Relaxed操作 B 之前看到Relaxed操作 A。
因此,Relaxed是可能的内存排序中最弱的。这表明该操作不会与其他 CPU 进行任何的同步。
在强有序的 CPU 中,所有的内存操作默认都具有 Acquire/Release 语义。因此,这仅是向编译器提示“这些操作不能在它们之间重新排序”。在强有序的系统中使用这些操作的原因是:它们允许编译器在合适的情况下对所有其他内存访问操作进行重排。
如果你想知道为什么似乎可以使用
Relaxed并获得与Acquire/Release相同的结果,这就是原因。然而,重要的是尝试理解“抽象机”模型,而不仅仅是依靠在强有序 CPU 中运行实验中所获得的经验。你的代码可能在不同的 CPU 中被中断。查看这篇文章,它们在强有序和弱有序的 CPU 中运行相同的代码,以了解它们之间的区别。
Acquire
在当前 CPU 中:
在Acquire访问操作之后写入的任何内存操作都将保留在该操作之后。这意味着它与Release内存排序标志配对,形成了一种“内存三明治”。所有在加载 (load) 和存储 (store) 之间的内存访问操作都将与其他 CPU 进行同步。
在弱有序的系统中,这可能导致在Acquire操作之前使用专门的 CPU 指令,它会强制当前的核心处理其邮箱中所有的消息(许多 CPU 都具有序列化及内存排序指令)。很有可能还会实现内存栏栅,以防止 CPU 在Acquire加载之前对内存访问操作的顺序进行重排。
内存栏栅 (memory fences)
由于我们是第一次遇到这个术语,就不要假装所有人都了解它然后将它放过。内存栏栅是个硬件概念。它通过强制 CPU 在隔离之前完成对内存的
loads/stores以防止对 CPU 指令进行重排,因此请确保在对栏栅重新排序之前没有进行任何此类操作,而后才可以对其进行此类操作。为了能够区分只读,只写以及读写指令,它们被命名为不同的名称。可以防止读写指令重排的栏栅被称为 full fence。
让我们快速浏览 Intel 开发者手册中的一个 full fence。(比较简短,我还做了总结)
程序的同步也可以通过序列化指令进行(参阅 8.3 节)。这些指令通常用于关键过程或任务边界,以强制完成之前的所有指令,然后跳转到新的代码块或进行上下文切换。和 I/O 指令及锁指令一样,处理器在执行序列化指令之前,一直等到之前的所有指令都已完成,并且所有缓存的写操作都已在内存中执行。SFENCE,LFENCE 以及 MFENCE 指令提供了一种性能高效的方式,可确保在在产生弱有序结果及消耗该数据的惯例之间加载和存储内存排序操作。
MFENCE - 在程序指令流中,序列化在 MFENCE 指令之前发生的所有存储和加载操作。
你可以参阅 Intel 开发者手册的第 8.2 节及 8.3 节文档,发现 MFENCE 是这样的一个指令。在强有序处理器上不会经常看到这些指令,因为很少需要它们,但在弱有序系统中,它们对于实现抽象机中使用的
Acquire/Release模型至关重要。
在观察者 CPU 中:
因为Acquire是一个load操作,它不会修改内存,所以不需要对其进行观察。
但是,这里有个注意事项 (caveat),如果观察者核心本身做了Acquire加载操作,它将会看到Acquire加载到Release存储(包括存储)之间发生的所有内存操作。这意味着需要执行一些全局的同步。让我们在之后介绍到Release时再进行讨论。
Acquire通常用于写锁,在成功获取锁之后,某些操作需要保留。出于这个确切的原因,Acquire仅在加载 (load) 操作时有意义。如果你将Acquire作为存储 (store) 操作的内存排序进行传递,Rust 中涉及存储的大多数原子方法都会发生恐慌 (panic)。
⚠️ 在强有序的 CPU 中,这将是一个 no-op,因此不会在性能方面产生任何成本。但是,这将阻止编译器对在
Acquire操作之后发生的所有写入的内存操作进行重新排序,以使它们在Acquire操作之前发生。
Release
在当前 CPU 中:
与Acquire相反,任何在Release内存排序标志之前编写的内存操作都将停留在该标志之前。这意味着它与Acquire内存排序标志配对。
在弱有序 CPU 中,编译器可能会插入一个内存栏栅来确保 CPU 不会对Release操作之前的内存操作进行重排,让这些操作在Release之后发生。这也做了一个保证,其他所有执行Acquire的核心一定可以看到在Acquire之后,Release之前的所有内存操作。
因此,不仅需要在本地正确地对操作进行排序,还保证了此时更改对于观察者核心必须是可见的。
这意味着一些全局同步一定会在每一个Acquire访问之前,或Release存储之后发生。这基本上给了我们两个选择:
Acquire加载 (load) 必须确保它处理了所有的消息,并且如果有任何其他的核心将我们载入的内存设置为无效,它可以拉取到正确的值。Release存储 (store) 必须是原子性的并且在它修改某个值之前,将其他所有持有该值的缓存置为无效。
不过,仅执行其中一项就足够了。这部分使其比SeqCst弱,但是性能更高。
在观察者 CPU 中:
观察者 CPU 可能看不到任何特定顺序的这些更改,除非它本身使用内存的Acquire加载 (load)。如果确实是这样,它会看到在Acquire和Release之间修改过的所有内存,包括Release存储 (store) 本身。
Release经常与Acquire一起使用以写锁。对于一个函数锁,在成功获取到锁之后 (在锁释放之前),一些操作需要被保留。出于这个原因,与Acquire排序相反,如果你传递Release排序操作,Rust 中的大多数加载 (load) 方法都会发生恐慌 (panic)。
⚠️ 在强有序的 CPU 中,在修改值之前,共享(
Shared)值的所有实例在该值存在的所有 L1 缓存中均无效。这意味着Acquire加载 (load) 对所有相关的内存都已经有了一个更新后的视图,Release存储 (store) 将立即将其他包含数据的核心上的任何缓存行置为无效。这就是为什么这些语义在这样的系统上没有性能成本的原因。
AcqRel
该语义旨在用于同时加载 (load) 并存储 (store) 一个值时的操作。AtomicBool::compare_and_swap就是一个这样的操作。因为这个操作既加载 (load) 又存储 (store) 某个值,与Relaxed操作相比,这在弱有序系统上可能很重要。
我们可以或多或少的将这个操作看作是栏栅。在它之前写入的内存操作不会跨越此边界重新排序,而在它之后写入的内存操作不会在此边界之前重新排序。
⚠️ 阅读
Acquire和Release段落,此处同样适用。
SeqCst
⚠️ 在本文的这个部分,我将使用强有序的 CPU 作为基础进行讨论。你在这里将看不到“强有序”的片段。
SeqCst代表顺序一致性 (Sequential Consistency),它不仅给了和Acquire/Release一样的保证,还承诺建立一个单一的全量修改顺序。
SeqCst已经因为用作推荐的排序方式而受到批评,并且很难证明有充足的理由使用它,因此我对使用它有很多反对意见。也有人批评它有点功能破损。
此图应该可以说明SeqCst在哪些方面可能无法维持其保证:
如何将其修复请参阅Repairing Sequential Consistency in C/C++11 。
明白了吗?从现在开始,我们将关注于SeqCst的实践方面,而不是其理论基础。
只知道围绕它进行了一些讨论,并且Acquire/Release很可能解决你的大部分难题,至少在强有序的 CPU 上。
让我们考虑将SeqCst与Acquire/Release操作进行对比。
我将使用这个 Gotbolt 示例进行解释:
代码如下所示:
#![allow(unused)] fn main() { use std::sync::atomic::{AtomicBool, Ordering}; static X: AtomicBool = AtomicBool::new(true); static Y: AtomicBool = AtomicBool::new(true); pub fn example(val: bool) -> bool { let x = X.load(Ordering::Acquire); X.store(val | x, Ordering::Release); let y = Y.load(Ordering::Acquire); x || y } }
使用Acquire/Release输出的汇编程序如下所示:
movb example::X.0.0(%rip), %al # load(Acquire)
testb %al, %al
setne %al
orb %dil, %al
movb %al, example::X.0.0(%rip) # store(Release)
movb 1, %al # load(Acquire)
retq
在弱有序的 CPU 中,指令可能不同,但是结果必须是一致的。
使用Release内存排序的存储 (store) 操作是movb %al, example::X.0.0(%rip)。我们知道在强有序的系统中,如果其他缓存中包含这个数据,可以确保能够立即在其他缓存中将其设置为Invalid。
所以问题是什么?
为了将其指明,我们浏览一下在 C++ 规范中关于 Release-Acquire 的相关部分:
仅在 Release 和 Acquire 相同原子变量的线程之间建立同步。其他线程可以看到不同于同步线程中看到的内存访问顺序。
Rust 的Release文档再次重申 (re-iterates) 并指出:
特别是,所有之前的写入操作对执行此值的 Acquire (或更强)加载 (load) 的所有线程都是可见的。
现在是时候仔细看看我在开始时提到的 non-guarantee。Intel 开发者手册 在第 8.2.3.4 节进行了更详细的说明:
8.2.3.4:Loads 可能会与早期的 Stores 一起重排到不同的位置
Intel 64 位内存排序模型允许将加载 (load) 与早期的存储 (store) 重排到不同的位置。然而,加载 (load) 不会与存储 (store) 重排到相同的位置。
所以,如果我们将这个信息放在一起,我们可以有以下情形:
#![allow(unused)] fn main() { let x = X.load(Ordering::Acquire); X.store(val | x, Ordering::Release); # earlier store to different location let y = Y.load(Ordering::Acquire); # load // *Could* get reordered on the CPU to this: let x = X.load(Ordering::Acquire); let y = Y.load(Ordering::Acquire); X.store(val | x, Ordering::Release); }
现在,我已经尽我最大的努力在 Intel CPU 上引发导致问题的情况,但是我无法得到一个简单的示例可以可靠地表明这一点。但是从理论上讲,从抽象机的规格和描述来看,Acquire/Release并不能阻止这种情况。
如果我们将代码改为:
#![allow(unused)] fn main() { use std::sync::atomic::{AtomicBool, Ordering}; static X: AtomicBool = AtomicBool::new(true); static Y: AtomicBool = AtomicBool::new(true); pub fn example(val: bool) -> bool { let x = X.load(Ordering::SeqCst); X.store(val | x, Ordering::SeqCst); let y = Y.load(Ordering::SeqCst); x || y } }
我们得到了如下汇编代码:
movb example::X.0.0(%rip), %al
testb %al, %al
setne %al
orb %dil, %al
xchgb %al, example::X.0.0(%rip)
movb 1, %al
retq
一个有趣的改变是存储 (store) 操作从简单的加载 (load) 变为特殊的指令xchgb %al, example::X.0.0(%rip)。这是一个原子操作(xchg有一个隐式的lock前缀)。
因为xchg指令是一个locked指令,当内存被获取,并在修改后置为无效,它将会确保在其他核心上的所有缓存行指的是同一块被锁住的内存。此外,它还可以作为内存的 full fence,我们可以在 Intel 开发者手册中得出:
8.2.3.9:加载 (load) 和存储 (store) 不会与锁指令一起重排
内存排序模型可以防止使用较早或较晚的锁指令对加载 (load) 和存储 (store) 进行重排。本节的示例仅说明在加载 (load) 或存储 (store) 之前执行锁指令的情况。读者应该注意,如果在加载 (load) 或存储 (store) 后执行了锁指令,则也将阻止重排。
对于我们的观察者核心这是一个可观测的改变。
顺序一致性 (Sequential Consistency)
如果我们依赖于加载 (load) 操作发生后获取到的某个值,如标记
Release之后,如果我们使用Acquire/Release语义,我们可以在Release操作之前观察到该值确实被改变了。至少在理论上是这样。
使用锁指令可以防止这种情况。因此,除了有
Acquire/Release保证之外,它还确保在这两者之间不会发生任何其他内存操作(读取或写入)。单一的全量修改顺序
在弱有序的 CPU 中,
SeqCst也提供了一些保证,这些保证在默认情况下只能在强有序的 CPU 中得到,其中最重要的是单一全量修改顺序。这意味着如果我们有两个观察者核心,它们将以相同的顺序看到所有的
SeqCst操作。Acquire/Release不会提供这种保证。观察者 a 可以以与观察者 b 不同的顺序看到两个修改(请记住邮箱的类比 (analogy))。假设核心 A 需要使用了基于
Acquire排序的compare_and_swap获取标志 X,而核心 B 在 Y 上执行了相同的操作。两者都执行相同的操作,然后使用Release存储 (store) 将标志的值改回。没有什么可以阻止观察者 A 看到标志 Y 在标志 X 之前变回,观察者 B则相反。
SeqCst阻止了这一切的发生。在强有序的系统中,在其他所有的核心中都可以立即看到每个存储 (
store),因此在这里修改顺序不是一个真正的问题。
SeqCst是最强的内存排序,它的开销也比其他的略高。
你可以在上面看到一个解释了为什么的例子,因为每个原子指令都涉及 CPU 缓存一致性机制并锁定其他缓存中内存位置的开销。在拥有正确程序的情况下,我们所需的此类指令越少,性能就越好。
原子操作
除了上面讨论的内存栏栅之外,在std::sync::atomic模块中使用原子类型还可以访问一些我们通常在 Rust 中看不到的重要 CPU 指令:
从多核 Intel® EM64T 和 IA32 架构实现可扩展的原子锁开始:
用户级锁涉及利用处理器的原子指令来原子地更新存储空间。原子指令涉及利用指令上的锁前缀,并将目标操作数分配给内存地址。以下指令可以在当前的 Intel 处理器上带上一个锁前缀从而可以原子的运行:ADD,ADC,AND,BTC,BTR,BTS,CMPXCHG,CMPXCH8B,DEC,INC,NEG,NOT,OR,SBB,SUB,XOR,XADD 以及 XCHG...
当我们使用一个原子的方法时,如 AtomicUsize 中的fetch_add,编译器实际上会更改它发出的指令,将两个数字在 CPU 上相加。相反,其汇编代码看起来像(一个 AT&T 方言)lock addq ..., ...而不是我们通常期望的addq ..., ...。
原子操作是作为一个不可分割的 (indivisible) 单元执行的一组操作。禁止任何观察者在对其操作时看到任何子操作或获取相同的数据。来自其他核心中针对相同数据的冲突操作 B 必须等待,直到第一个原子操作 A 完成。
让我们举一个增加计数器的例子。这里有三步:
加载数据,修改数据,存储数据。对于每个步骤,另一个核心可能会在我们完成之前加载相同的数据,对其进行修改并将值进行存储。
LOAD NUMBER ---- a competing core can load the same value here ---- INCREASE NUMBER ---- a competing core can increase the same value ---- ---- a competing core can store its data here ---- STORE NUMBER ---- we overwrite that data here ----通常,在存储数据之前,我们希望阻止任何人从加载数据的角度进行观察和干预。这就是原子操作要为我们解决的问题。
原子的一个普通用例是自旋锁 (spin-locks)。一个非常简单(并且 unsafe)的代码如下所示:
#![allow(unused)] fn main() { static LOCKED: AtomicBool = AtomicBool::new(false); static mut COUNTER: usize = 0; pub fn spinlock(inc: usize) { while LOCKED.compare_and_swap(false, true, Ordering::Acquire) {} unsafe { COUNTER += inc }; LOCKED.store(false, Ordering::Release); } }
它的汇编代码如下所示:
#![allow(unused)] fn main() { xorl %eax, %eax lock cmpxchgb %cl, example::LOCKED(%rip) jne .LBB0_1 addq %rdi, example::COUNTER(%rip) movb 0, example::LOCKED(%rip) retq }
lock cmpxchgb %cl, example::LOCKED(%rip)是我们在compare_and_swap中做的原子操作。lock cmpxchgb是一个锁操作;它读取一个标志,并且在条件满足时,将值修改。
在 Intel 开发者手册的第 8.2.5 节中:
多处理器系统中的处理机制可能取决于强有序模型。在这里,程序可以使用诸如 XCHG 指令或 LOCK 前缀之类的锁指令来确保原子的执行对内存的 read-modify-write 操作。锁操作通常类似于 I/O 操作,因为它们需要等待之前所有的指令完成,并且等待所有缓存的写操作在内存中执行(请参阅第 8.1.2 节 “总线锁定”)。
这个锁 (lock) 指令前缀干了什么?
这变得有点技术含量,但是据我所知,对此进行建模的一种简单方法是,当从缓存中获取内存时,它已将缓存行状态设置为Modified。
这样,从核心的 L1 缓存中获取数据的那一刻起,就将其标记为Modified。处理器使用缓存一致性机制确保存在该状态的所有其他缓存都将其更新为Invalid - 即使它们尚未处理其邮箱中的所有消息。
如果消息传递是同步变更的正常方式,则锁指令(以及其他内存排序或序列化指令)涉及一种更昂贵,功能更强大的机制,它可以绕过消息传递,将缓存行锁定在其他缓存中(因此当缓存在运行时,不会发生加载或存储操作),并相应地将其设置为无效,这会迫使缓存从内存中获取更新后的值。
如果你对这一方面感兴趣,请参阅 Intel® 64 和 IA-32 架构软件开发者手册。
在 64 位系统中,缓存行通常是 64 个字节。 这可能因具体的 CPU 而异,但是要考虑的重要一点是,如果内存跨越两条缓存行,则使用的锁机制要昂贵的多,并且可能涉及总线锁定和其他硬件技术。
跨缓存行边界的原子操作在不同的体系结构中具有不同的支持。
结论
你还在这儿吗?如果在的话,请放轻松,今天我们要讲的内容已经结束了。感谢你一直陪伴我并读完了这篇文章,我真诚的希望你可以享受本文并可以从中获得一些收获。
我从根本上相信,即使你在日常生活中从未使用过std::sync::atomic模块,但围绕自己在努力处理的问题建立良好的心智模型对你的个人目的以及编写代码的方式都会有很多好处。
下次再见👋!
Rust 和 TUI:在 Rust 中构建命令行界面

Rust 是一门拥有良好的交叉编译支持的底层系统编程语言,这使其成为编写命令行程序的主要候选语言。从重新实现广泛使用的工具 (如 ripgrep,exa,bat) 到功能完善的终端 UI 工具(如:GitUI,Spotify TUI,Bandwhich,KMon,Diskonaut)都是比较著名 (Prominent) 的例子。
甚至有比较流行的 shell 实现 (如 Alacritty 和 Nushell)。使用 Rust 重写这众多的工具 (且保持稳定的增长) 的原因包括 Rewrite it in Rust (RIIR) meme 以及 Rust 绝佳的编写命令行应用程序的生态系统。
当谈到 Rust 命令行库的生态系统,我想专门提一下 Clap 和 TUI,它们都是上面提到的许多工具中所必须的。Clap 是一个命令行解析器,具有出色的 API 和大量可用的功能,如果不需要,可以禁用其中的许多功能以加快编译速度。
什么是 TUI?
TUI 是一个用于构建终端用户界面的框架。它支持多个用于绘制终端的“后端”。这些后端控制与终端交互的实际逻辑,如设置正确的字符集,清空屏幕等,而 TUI 是一个更高级的界面,它提供了用于组成用户界面的小部件和其他帮助程序。
在本篇教程中,我们将学习如何使用将 Crossterm 作为后端的 TUI 实现一个简单的终端应用程序。除了渲染和事件处理管道的初始化之外,我们不会直接与 Crossterm 进行交互,因此该示例只需要做很小的修改,就可以在其他 TUI 后端下工作。
为了演示 TUI 是如何工作的,我们将构建一个简单的 app 来管理你的宠物,其中使用本地 JSON 文件作为数据存储。最终的产品将会如下所示:
第一张图展示了带有菜单的欢迎界面。菜单中的高亮字符表示用户需要点击以执行操作的热键。如果按下p键,用户将会来到第二个(宠物)屏幕,他们可以在这里管理宠物。用户可以通过列表进行导航,使用a来添加随机的新宠物,使用d来删除当前选中的宠物。按下q可以关闭 app。
这个 app 相当简单,但是它对于展示 TUI 的工作原理以及如何构建这类应用的基础模块已经足够。使用我为这篇教程编写的 Rust 命令行示例代码,你可以编辑该代码以对其进行扩展,为添加新宠物新增一个表单等。
使用 TUI 时,可以调整应用程序的大小,并可以响应式的进行更改,从而将不同 UI 的元素配置比例保持在适当的位置。这是使用现有的部件时 TUI 要做的其中一件事。
事不宜迟 (without further ado),让我们开始吧!
设置 Rust app
要进行后续操作,你需要做的是安装最新的 Rust (1.45+;在编写本文时最新版本是 Rust 1.49.0)。
首先,创建一个新的 Rust 项目:
cargo new rust-cli-example
cd rust-cli-example
然后编辑Cargo.toml文件,并添加以下你所需要的依赖:
[dependencies]
crossterm = { version = "0.19", features = [ "serde" ] }
serde = {version = "1.0", features = ["derive"] }
serde_json = "1.0"
chrono = { version = "0.4", features = ["serde"] }
rand = { version = "0.7.3", default-features = false, features = ["std"] }
tui = { version = "0.14", default-features = false, features = ['crossterm', 'serde'] }
thiserror = "1.0"
除了使用 Crossterm 作为 TUI 的后端。我们还需要 Serde 用来处理 JSON,Chrono 用来处理宠物的创建日期以及 Rand 用于创建随机数。
正如你在上面的配置中所见,我们在 TUI 中选择了crossterm和serde特性。
让我们从定义一些基础的数据结构以及常量开始。
定义数据结构
首先,让我们为本地“数据库” JSON 文件定义一个常量,以及宠物对应的结构体:
#![allow(unused)] fn main() { const DB_PATH: &str = "./data/db.json"; #[derive(Serialize, Deserialize, Clone)] struct Pet { id: usize, name: String, category: String, age: usize, created_at: DateTime<Utc>, } }
当处理数据库文件时,我们可能会遇到 I/O 异常。虽然为所有的潜在异常实现异常处理不在本文要讲述的范围内,我们仍然定义一些内部的错误类型:
#![allow(unused)] fn main() { #[derive(Error, Debug)] pub enum Error { #[error("error reading the DB file: {0}")] ReadDBError(#[from] io::Error), #[error("error parsing the DB file: {0}")] ParseDBError(#[from] serde_json::Error), } }
db.json文件是一个简单的用 JSON 表示的Pet结构的列表。
#![allow(unused)] fn main() { [ { "id": 1, "name": "Chip", "category": "cats", "age": 4, "created_at": "2020-09-01T12:00:00Z" }, ... ] }
我们也需要输入事件的数据结构。我们将会使用在 TUI 示例仓库中的 Crossterm 示例中使用的相同的方法。
#![allow(unused)] fn main() { enum Event<I> { Input(I), Tick, } }
事件可能是用户的输入或者是简单的tick。我们将会定义 tick 的速率(如:200毫秒),如果在该速率内没有输入事件则发送一个Tick,否则提交一个输入。
最后,为菜单结构定义一个枚举,因此可以轻松确定我们在应用程序中的位置:
#![allow(unused)] fn main() { #[derive(Copy, Clone, Debug)] enum MenuItem { Home, Pets, } impl From<MenuItem> for usize { fn from(input: MenuItem) -> usize { match input { MenuItem::Home => 0, MenuItem::Pets => 1, } } } }
我们目前只有两个页面 - Home 和 Pets - 我们实现了From特征将它们转换成usize。这让我们可以使用 TUI 组件中的枚举凸显菜单中当前选中的选项卡。
先不进行初始化,让我们设置 TUI 和 crossterm,以便可以开始在屏幕上渲染内容并对用户事件做出响应。
渲染和输入
首先,将终端设置成raw模式,这消除了等待用户对输入做出响应时按下Enter键的需要。
fn main() -> Result<(), Box<dyn std::error::Error>> { enable_raw_mode().expect("can run in raw mode"); ...
然后,设置一个mpsc(多生产者,单消费者)管道来与输出处理以及渲染循环通信。
#![allow(unused)] fn main() { let (tx, rx) = mpsc::channel(); let tick_rate = Duration::from_millis(200); thread::spawn(move || { let mut last_tick = Instant::now(); loop { let timeout = tick_rate .checked_sub(last_tick.elapsed()) .unwrap_or_else(|| Duration::from_secs(0)); if event::poll(timeout).expect("poll works") { if let CEvent::Key(key) = event::read().expect("can read events") { tx.send(Event::Input(key)).expect("can send events"); } } if last_tick.elapsed() >= tick_rate { if let Ok(_) = tx.send(Event::Tick) { last_tick = Instant::now(); } } } }); }
创建了通道之后,定义上面提到的 tick 速率并生成一个线程。我们的输入循环将在这个线程中执行。建议按照此代码段使用 TUI 和 Crossterm 来设置输入循环。
这个想法是想要计算下一个 tick (timeout),然后使用event::poll一直等待直到事件发生的那一刻,如果有事件发生,则通过我们通道发送该输入事件,该通道中带有用户按下的按键。
如果在这段时间没有发生用户事件,我们简单的发送一个Tick事件并重新开始。使用tick_rate,你可以调整 (tune) 应用程序的响应能力。但是如果将该值设置的很低同样意味着这个循环运行会占用很多资源。
这个逻辑在另一个线程中生成,因为我们需要主线程渲染这个应用。这么做的话,我们的输入循环就不会阻塞渲染线程。
将后端设置为Crossterm的 TUI 终端需要一些步骤:
#![allow(unused)] fn main() { let stdout = io::stdout(); let backend = CrosstermBackend::new(stdout); let mut terminal = Terminal::new(backend)?; terminal.clear()?; }
我们使用stdout定义了一个CrosstermBackend并在 TUI 终端中使用,首先对终端进行 clear,然后隐式的检查一切运行良好。如果有任何出错,我们简单的 panic 并将应用终止;由于我们没有获取更改渲染事件的任何内容,因此这里真的没有其他更好的应对方法。
至此,我们需要一个样板 (boilerplate) 设置来创建一个输入循环以及一个可以绘制的终端。
让我们构建第一个 UI 元素 - 基于 tab 的菜单!
渲染 TUI 中的部件
在我们创建菜单之前,我们需要实现一个渲染循环,它在每一次迭代中调用terminal.draw()。
#![allow(unused)] fn main() { loop { terminal.draw(|rect| { let size = rect.size(); let chunks = Layout::default() .direction(Direction::Vertical) .margin(2) .constraints( [ Constraint::Length(3), Constraint::Min(2), Constraint::Length(3), ] .as_ref(), ) .split(size); ... }
我们使用闭包提供了一个draw函数,它接收一个Rect作为参数。这只是 TUI 中使用的矩形布局原语,用于定义应在何处渲染的部件。
下一步是定义布局的chunks。我们有传统垂直布局,其中包含三个框:
- 菜单
- 内容
- 页尾
我们使用 TUI 中的Layout来定义这个,设置方向以及一些约束条件。这些约束条件定义了应该如何组合布局中不同的部分。在我们的示例中,我们将菜单部分的长度定义为 3 (本质上是 3 行),中间的内容部分长度至少是 2,页尾长度是 3。这意味着,如果你在全屏中运行这个 app,菜单和页尾的高度为 3 行始终不变,而内容部分将增长到其余的大小。
这些约束条件是一个功能强大的系统,我们在后面还会介绍设置百分比和比率的选项。最后,我们将布局分成多个布局块。
我们布局中最简单的 UI 组件就是带有假版权的静态页尾,让我们开始感受一下如何创建并渲染一个部件:
#![allow(unused)] fn main() { let copyright = Paragraph::new("pet-CLI 2020 - all rights reserved") .style(Style::default().fg(Color::LightCyan)) .alignment(Alignment::Center) .block( Block::default() .borders(Borders::ALL) .style(Style::default().fg(Color::White)) .title("Copyright") .border_type(BorderType::Plain), ); rect.render_widget(copyright, chunks[2]); }
我们使用Paragraph部件,它是预先存在于 TUI 中许多部件的其中一个。我们使用硬编码文本定义一个段落,通过在默认风格中使用.fg来设置不同的前景色来自定义风格,设置居中对齐,然后定义一个块。
这个块很重要因为它是一个“基础”部件,意味着它可以渲染到其他所有的部件中。Block定义了一个区域,你可以在该区域中围绕要呈现的内容放置标题和可选边框。
在这里,我们创建了一个标题为 “Copyright” 的框,它具有完整的边框,可以创建漂亮的三框垂直布局。
然后,我们使用draw方法中的rect调用render_widget,将我们的段落渲染成chunks[2],它是布局中的第三个部分(底下的部分)。
这就是在 TUI 中渲染部件的全部内容。很简单,对不堵?
构建一个基于 tab 的菜单
现在,我们终于可以处理 (tackle) 基于 tab 的菜单了。幸运的是,TUI 开箱即用 (out of box),其中有一个Tabs部件,我们无需做很多事情即可使其工作。为了管理有关哪个菜单项出于激活状态,我们需要在渲染循环之前添加两行:
#![allow(unused)] fn main() { ... let menu_titles = vec!["Home", "Pets", "Add", "Delete", "Quit"]; let mut active_menu_item = MenuItem::Home; ... loop { terminal.draw(|rect| { ... }
在第一行中,我们定义了硬编码的菜单标题并且active_menu_item存储了当前被选中的菜单项,初始化时将其设置为Home。
因为我们只有两个页面,所以它只能被设置为Home或者Pets,但是你可以想象如何将这种方法用于基本的上层路由。
为了渲染菜单,我们首先需要创建一个Span(是的,就像是 HTML 中的 标签)元素列表以持有这些菜单标签,然后将它们放置在Tabs部件中:
#![allow(unused)] fn main() { let menu = menu_titles .iter() .map(|t| { let (first, rest) = t.split_at(1); Spans::from(vec![ Span::styled( first, Style::default() .fg(Color::Yellow) .add_modifier(Modifier::UNDERLINED), ), Span::styled(rest, Style::default().fg(Color::White)), ]) }) .collect(); let tabs = Tabs::new(menu) .select(active_menu_item.into()) .block(Block::default().title("Menu").borders(Borders::ALL)) .style(Style::default().fg(Color::White)) .highlight_style(Style::default().fg(Color::Yellow)) .divider(Span::raw("|")); rect.render_widget(tabs, chunks[0]); }
我们遍历硬编码菜单标签,然后在每个标签的第一个字符处分割字符串。我们给第一个字符添加不同的颜色和下划线,让它与其他字符的风格不一样,以提示用户,它们需要按下该字符以激活对应的菜单项。
这个操作的结果是一个Spans元素,它是一个Span元素列表,其实就是多个可选风格的文本片段。这些Spans会被放置在Tabs部件中。
我们使用active_menu_item调用.select()并设置一个高亮风格,它与其它普通风格有所不同。这意味着如果一个菜单项被选中,它将完全变成黄色,而未被选中的只有第一个字符是黄色,其他字符是白色。我们还定义了一个分隔符,然后再设置一个带有边框和标题的基本块,以保持和我们的样式一致。
和 copyright 一致,我们使用chunk[0]将 tab 菜单渲染进布局的第一个部分。
现在,三分之二的布局元素已经完成。然而,我们在这里使用active_menu_item定义一个有状态的元素来判断哪一个菜单项是激活状态,这将如何改变?
让我们接下来进行输入处理来解决这个秘密。
处理 TUI 中的输入
在渲染loop {}中,在terminal.draw()调用完成之后,我们添加了另一段代码:我们的输入处理。
这意味着我们总是首先渲染当前的状态然后对新的输入做出反应。我们只需在channel的接收端等待输入即可,这是我们在开始时就设置的:
#![allow(unused)] fn main() { match rx.recv()? { Event::Input(event) => match event.code { KeyCode::Char('q') => { disable_raw_mode()?; terminal.show_cursor()?; break; } KeyCode::Char('h') => active_menu_item = MenuItem::Home, KeyCode::Char('p') => active_menu_item = MenuItem::Pets, _ => {} }, Event::Tick => {} } } // end of render loop }
当发生了一个事件,我们对传入的KeyCode进行匹配。如果用户按下q,表示想要关闭 app,这表示我们想要做一些清理,将终端的状态设置成我们最初获得终端时相同的状态。在真实的应用中,这个清理应该发生在任何的严重错误中。否则,终端保持在raw模式并看起来很混乱。
我们禁用了raw模式并再一次展示光标,因此用户应该在启动 app 之前处于“普通”的终端模式。
如果我们遇到了h,我们将激活的菜单设置为Home,如果是p,则将菜单设置为Pets。这是我们需要的全部路由逻辑。
而且,在terminal.draw闭包中,我们需要为这个路由添加一些逻辑:
#![allow(unused)] fn main() { match active_menu_item { MenuItem::Home => rect.render_widget(render_home(), chunks[1]), MenuItem::Pets => { ... } } ... fn render_home<'a>() -> Paragraph<'a> { let home = Paragraph::new(vec![ Spans::from(vec![Span::raw("")]), Spans::from(vec![Span::raw("Welcome")]), Spans::from(vec![Span::raw("")]), Spans::from(vec![Span::raw("to")]), Spans::from(vec![Span::raw("")]), Spans::from(vec![Span::styled( "pet-CLI", Style::default().fg(Color::LightBlue), )]), Spans::from(vec![Span::raw("")]), Spans::from(vec![Span::raw("Press 'p' to access pets, 'a' to add random new pets and 'd' to delete the currently selected pet.")]), ]) .alignment(Alignment::Center) .block( Block::default() .borders(Borders::ALL) .style(Style::default().fg(Color::White)) .title("Home") .border_type(BorderType::Plain), ); home } }
我们匹配active_menu_item,如果是Home,则简单的渲染一个基本的欢迎信息告诉用户他们在哪儿,并给他们一些说明如何与这个 app 进行交互。
这就是我们需要的输入处理的全部内容。如果我们运行这段代码,我们已经可以与 tab 进行交互了。但是我们还缺少宠物管理应用程序的实质:宠物的处理。
在 TUI 中创建有状态的部件
第一步是从 JSON 文件中加载宠物然后在左侧展示宠物的名字,以及在右侧展示选中宠物的细节(默认选中第一个)。
在此申明一下,由于本教程的范围有限,因此该应用程序无法处理错误;如果读取文件失败,则应用程序将会崩溃,而不显示有用的错误。从本质上将,错误处理与其他 UI 应用程序中的工作方式相同:对错误进行分类,如:像用户显示有用的错误Paragraph,以提示纠正问题或采取某个行为。
顺便说一句,让我们看一下上一节中active_menu_item匹配项的缺失部分:
#![allow(unused)] fn main() { match active_menu_item { MenuItem::Home => rect.render_widget(render_home(), chunks[1]), MenuItem::Pets => { let pets_chunks = Layout::default() .direction(Direction::Horizontal) .constraints( [Constraint::Percentage(20), Constraint::Percentage(80)].as_ref(), ) .split(chunks[1]); let (left, right) = render_pets(&pet_list_state); rect.render_stateful_widget(left, pets_chunks[0], &mut pet_list_state); rect.render_widget(right, pets_chunks[1]); } } }
如果我们在Pets页面,我们创建一个新的布局。这一次,我们想要一个水平布局,因为我们想要彼此相邻的展示两个元素:列表视图以及详情视图。在这里,我们想要列表视图占据屏幕的 20%,剩下的留给详情视图。
请注意,在.split中,我们使用chunk[1]而不是矩形的大小。这意味着我们将描述的chunk[1]矩形区域分割成两块水平视图。然后调用render_pets,返回我们要渲染的左右部分,我们只需将它们渲染到响应的pets_chunks中即可。
但是等一下,这是什么?我们为列表视图调用render_stateful_widget,这代表什么意思?
TUI,作为一个完整且出色的框架,它具有创建有状态的部件的能力。List部件是可以带状态的部件之一。为此,我们需要先在渲染循环之前创建一个ListState:
#![allow(unused)] fn main() { let mut pet_list_state = ListState::default(); pet_list_state.select(Some(0)); loop { ... }
我们初始化宠物列表状态并默认选择第一个项。我们还将pet_list_state传入render_pets函数中。这个函数执行以下所有逻辑:
- 从数据库文件中获取宠物信息
- 将它们转换成列表项
- 创建宠物列表
- 查找当前选中的宠物
- 使用选中的宠物数据渲染一个表格
- 返回这两个部件
这内容有点多,因此代码比较长,但是我们将逐行介绍:
#![allow(unused)] fn main() { fn read_db() -> Result<Vec<Pet>, Error> { let db_content = fs::read_to_string(DB_PATH)?; let parsed: Vec<Pet> = serde_json::from_str(&db_content)?; Ok(parsed) } fn render_pets<'a>(pet_list_state: &ListState) -> (List<'a>, Table<'a>) { let pets = Block::default() .borders(Borders::ALL) .style(Style::default().fg(Color::White)) .title("Pets") .border_type(BorderType::Plain); let pet_list = read_db().expect("can fetch pet list"); let items: Vec<_> = pet_list .iter() .map(|pet| { ListItem::new(Spans::from(vec![Span::styled( pet.name.clone(), Style::default(), )])) }) .collect(); let selected_pet = pet_list .get( pet_list_state .selected() .expect("there is always a selected pet"), ) .expect("exists") .clone(); let list = List::new(items).block(pets).highlight_style( Style::default() .bg(Color::Yellow) .fg(Color::Black) .add_modifier(Modifier::BOLD), ); let pet_detail = Table::new(vec![Row::new(vec![ Cell::from(Span::raw(selected_pet.id.to_string())), Cell::from(Span::raw(selected_pet.name)), Cell::from(Span::raw(selected_pet.category)), Cell::from(Span::raw(selected_pet.age.to_string())), Cell::from(Span::raw(selected_pet.created_at.to_string())), ])]) .header(Row::new(vec![ Cell::from(Span::styled( "ID", Style::default().add_modifier(Modifier::BOLD), )), Cell::from(Span::styled( "Name", Style::default().add_modifier(Modifier::BOLD), )), Cell::from(Span::styled( "Category", Style::default().add_modifier(Modifier::BOLD), )), Cell::from(Span::styled( "Age", Style::default().add_modifier(Modifier::BOLD), )), Cell::from(Span::styled( "Created At", Style::default().add_modifier(Modifier::BOLD), )), ])) .block( Block::default() .borders(Borders::ALL) .style(Style::default().fg(Color::White)) .title("Detail") .border_type(BorderType::Plain), ) .widths(&[ Constraint::Percentage(5), Constraint::Percentage(20), Constraint::Percentage(20), Constraint::Percentage(5), Constraint::Percentage(20), ]); (list, pet_detail) } }
首先,我们定义了read_db函数,它简单的读取 JSON 文件并将它解析成宠物的Vec。
然后在render_pets中,该函数返回List和Table的元组(都是 TUI 部件),我们首先为列表视图定义周围的pets块。
在获取到宠物数据之后,我们将宠物名字转换成ListItems。然后,我们试图在基于pet_list_state的列表中查找选中的宠物。如果失败或者我们没有宠物,在这个简单的版本中,该应用将会崩溃,因为我们正如上面所说,没有做任何有意义的错误处理。
一旦我们有了一个选中的宠物,我们将使用列表项创建一个List部件,定义一个高亮的风格,因此我们可以看到当前选中的是哪一个宠物。
最后,我们创建了pet_details表格,其中为宠物结构中的列名设置一个硬编码的 header。我们还定义了Rows列表,它包含每个宠物数据转换后的字符串。
我们将此表格渲染为带有Details标题和边框的基本块。并使用百分比定义五列的相对宽度。因此,该表格在调整大小时也会做出响应。
这是宠物的整个渲染逻辑。剩下的要添加的唯一功能是添加随机新宠物和删除所选宠物的功能,以使该应用更具交互性。
首先,我们先添加两个辅助函数来新增和删除宠物:
#![allow(unused)] fn main() { fn add_random_pet_to_db() -> Result<Vec<Pet>, Error> { let mut rng = rand::thread_rng(); let db_content = fs::read_to_string(DB_PATH)?; let mut parsed: Vec<Pet> = serde_json::from_str(&db_content)?; let catsdogs = match rng.gen_range(0, 1) { 0 => "cats", _ => "dogs", }; let random_pet = Pet { id: rng.gen_range(0, 9999999), name: rng.sample_iter(Alphanumeric).take(10).collect(), category: catsdogs.to_owned(), age: rng.gen_range(1, 15), created_at: Utc::now(), }; parsed.push(random_pet); fs::write(DB_PATH, &serde_json::to_vec(&parsed)?)?; Ok(parsed) } fn remove_pet_at_index(pet_list_state: &mut ListState) -> Result<(), Error> { if let Some(selected) = pet_list_state.selected() { let db_content = fs::read_to_string(DB_PATH)?; let mut parsed: Vec<Pet> = serde_json::from_str(&db_content)?; parsed.remove(selected); fs::write(DB_PATH, &serde_json::to_vec(&parsed)?)?; pet_list_state.select(Some(selected - 1)); } Ok(()) } }
在这两个函数中,我们加载宠物列表,操作后将其写回文件。在remove_pet_at_index中,我们也需要减少pet_list_state,因此如果我们在列表中最后一个宠物上时,我们将自动跳到前一个宠物上。
最后,我们需要使用Up和Down在宠物列表中为导航添加错误处理,用法和使用a和d对宠物进行增减一样。
#![allow(unused)] fn main() { KeyCode::Char('a') => { add_random_pet_to_db().expect("can add new random pet"); } KeyCode::Char('d') => { remove_pet_at_index(&mut pet_list_state).expect("can remove pet"); } KeyCode::Down => { if let Some(selected) = pet_list_state.selected() { let amount_pets = read_db().expect("can fetch pet list").len(); if selected >= amount_pets - 1 { pet_list_state.select(Some(0)); } else { pet_list_state.select(Some(selected + 1)); } } } KeyCode::Up => { if let Some(selected) = pet_list_state.selected() { let amount_pets = read_db().expect("can fetch pet list").len(); if selected > 0 { pet_list_state.select(Some(selected - 1)); } else { pet_list_state.select(Some(amount_pets - 1)); } } } }
在Up和Down这两种情况中,我们需要确定列表不会下溢或上溢。在这里简单的例子中,我们只是在这些键被按下时读取宠物列表,这非常的低效,但是足够简单。比如:在真实的应用中,当前数量的宠物将在共享内存的某个地方中持有,但是在本篇教程中,这种幼稚的方法就足够 (suffice) 了。
在任何情况下,我们只需增加或减少pet_list_state选择的值,可以让用户使用Up和Down滚动浏览宠物列表。如果使用cargo run启动应用,你可以测试不同的热键绑定,使用a添加一些随机的宠物,导航到宠物列表并再次使用d删除它们。
你可以在 Github 上找到本教程的完整代码。
结论
正如我在本教程的介绍中所提到的,Rust 创建终端应用的生态非常好,我希望这篇文章可以帮助你了解到使用 TUI 和 Crossterm 之类的库都能干些什么。
我是命令行应用的脑残粉。它们真的非常块,轻量且足够小,而且作为 Vimer,我对于使用键盘来与应用进行交互不是很恐惧。终端 UI 的另一个好处是它们可以被用于无头 (headless) 的环境,如:使用 SSH 登陆的远程服务器或者在恢复/调试的场景。
Rust 及其丰富的生态系统使构建命令行应用变得轻而易举,我为人们将来在该领域构建和发布的内容感到兴奋。
在 Android 中运行 Rust
为了我目前的一位客户,我们决定将 Rust 作为我们主要的编程语言。做出这个决定的原因有很多:除了技术优势 (merit) 外,还有一个无可争议的 (undisputable) 事实就是:Rust 仍然是一门相对较新的语言,花哨 (fancy) 且时髦 (hip) - 当你是一家初创公司 (startup) 时,使用十几年前的技术可能会让你陷入困境。我的意思是 - 不使用创新的技术如何进行创新?最快的成功方式就是对其大肆宣传 (aboard the hype train)。
”用户持有自己的数据“应该是产品的一个卖点,它不能是一个完全通过浏览器访问的服务,而应该是一种可以分发给用户,并让其运行在用户设备上的某个东西。我们在内部已经运行了一些 headless (一种无界面的软件运行模式) 实例,只要再完成一些琐碎的 (trivial) 工作,就可以为 Windows 和 Linux 系统制作可重新分发的程序包。但是我们知道如果程序包只能运行在桌面操作系统中时,将会严重阻碍应用的普及 - 如果我们想让它脱颖而出 (take off),则需要该应用程序的移动版本。这意味着我们必须要知道如何让我们的程序运行在 Android 或者 iOS 系统中。因为我对交叉编译与自动化构建已经有了一些经验,我主动的研究了这个主题。
获取工具
先从基础开始,我需要获取 Rust 交叉编译器。幸运的是,Rust 让此操作变得十分简单,因为只需要调用以下命令:
rustup target add armv7-linux-androideabi # For 32-bit ARM.
rustup target add aarch64-linux-android # For 64-bit ARM.
# x86_64 is mainly useful for running your app in the emulator.
# Speaking of hardware, there are some commercial x86-based tablets,
# and there's also hobbyists running Android-x86 on their laptops.
rustup target add x86_64-linux-android
(注意:以后只会显示 aarch64 架构的所有示例)
我还需要 Android 的构建工具。在经过一番调研之后,我来到 Android Studio 的下载页面 并抓取了归档的命令行工具。尽管 SDK 包有 80+ MiB 大小,却依然只有所需工具的最小子集,所以我听从了互联网的建议并使用sdkmanager来安装额外的部件。
cd ~/android/sdk/cmdline-tools/bin/
<span class="katex"><span class="katex-html" aria-hidden="true"><span class="base"><span class="strut" style="height:1em;vertical-align:-0.25em;"></span><span class="mord">./</span><span class="mord mathnormal">s</span><span class="mord mathnormal">d</span><span class="mord mathnormal">kmana</span><span class="mord mathnormal" style="margin-right:0.03588em;">g</span><span class="mord mathnormal" style="margin-right:0.02778em;">er</span><span class="mspace" style="margin-right:0.2222222222222222em;"></span><span class="mbin">−</span><span class="mspace" style="margin-right:0.2222222222222222em;"></span></span><span class="base"><span class="strut" style="height:0.84444em;vertical-align:-0.15em;"></span><span class="mord">−</span><span class="mord mathnormal">s</span><span class="mord mathnormal">d</span><span class="mord"><span class="mord mathnormal" style="margin-right:0.03148em;">k</span><span class="msupsub"><span class="vlist-t vlist-t2"><span class="vlist-r"><span class="vlist" style="height:0.151392em;"><span style="top:-2.5500000000000003em;margin-left:-0.03148em;margin-right:0.05em;"><span class="pstrut" style="height:2.7em;"></span><span class="sizing reset-size6 size3 mtight"><span class="mord mathnormal mtight" style="margin-right:0.02778em;">r</span></span></span></span><span class="vlist-s"></span></span><span class="vlist-r"><span class="vlist" style="height:0.15em;"><span></span></span></span></span></span></span><span class="mord mathnormal">oo</span><span class="mord mathnormal">t</span><span class="mspace" style="margin-right:0.2777777777777778em;"></span><span class="mrel">=</span><span class="mspace" style="margin-right:0.2777777777777778em;"></span></span><span class="base"><span class="strut" style="height:0.69444em;vertical-align:0em;"></span><span class="mord">"</span></span></span></span>{HOME}/android/sdk" --install 'build-tools;29.0.2'
<span class="katex"><span class="katex-html" aria-hidden="true"><span class="base"><span class="strut" style="height:1em;vertical-align:-0.25em;"></span><span class="mord">./</span><span class="mord mathnormal">s</span><span class="mord mathnormal">d</span><span class="mord mathnormal">kmana</span><span class="mord mathnormal" style="margin-right:0.03588em;">g</span><span class="mord mathnormal" style="margin-right:0.02778em;">er</span><span class="mspace" style="margin-right:0.2222222222222222em;"></span><span class="mbin">−</span><span class="mspace" style="margin-right:0.2222222222222222em;"></span></span><span class="base"><span class="strut" style="height:0.84444em;vertical-align:-0.15em;"></span><span class="mord">−</span><span class="mord mathnormal">s</span><span class="mord mathnormal">d</span><span class="mord"><span class="mord mathnormal" style="margin-right:0.03148em;">k</span><span class="msupsub"><span class="vlist-t vlist-t2"><span class="vlist-r"><span class="vlist" style="height:0.151392em;"><span style="top:-2.5500000000000003em;margin-left:-0.03148em;margin-right:0.05em;"><span class="pstrut" style="height:2.7em;"></span><span class="sizing reset-size6 size3 mtight"><span class="mord mathnormal mtight" style="margin-right:0.02778em;">r</span></span></span></span><span class="vlist-s"></span></span><span class="vlist-r"><span class="vlist" style="height:0.15em;"><span></span></span></span></span></span></span><span class="mord mathnormal">oo</span><span class="mord mathnormal">t</span><span class="mspace" style="margin-right:0.2777777777777778em;"></span><span class="mrel">=</span><span class="mspace" style="margin-right:0.2777777777777778em;"></span></span><span class="base"><span class="strut" style="height:0.69444em;vertical-align:0em;"></span><span class="mord">"</span></span></span></span>{HOME}/android/sdk" --install 'cmdline-tools;latest'
<span class="katex"><span class="katex-html" aria-hidden="true"><span class="base"><span class="strut" style="height:1em;vertical-align:-0.25em;"></span><span class="mord">./</span><span class="mord mathnormal">s</span><span class="mord mathnormal">d</span><span class="mord mathnormal">kmana</span><span class="mord mathnormal" style="margin-right:0.03588em;">g</span><span class="mord mathnormal" style="margin-right:0.02778em;">er</span><span class="mspace" style="margin-right:0.2222222222222222em;"></span><span class="mbin">−</span><span class="mspace" style="margin-right:0.2222222222222222em;"></span></span><span class="base"><span class="strut" style="height:0.84444em;vertical-align:-0.15em;"></span><span class="mord">−</span><span class="mord mathnormal">s</span><span class="mord mathnormal">d</span><span class="mord"><span class="mord mathnormal" style="margin-right:0.03148em;">k</span><span class="msupsub"><span class="vlist-t vlist-t2"><span class="vlist-r"><span class="vlist" style="height:0.151392em;"><span style="top:-2.5500000000000003em;margin-left:-0.03148em;margin-right:0.05em;"><span class="pstrut" style="height:2.7em;"></span><span class="sizing reset-size6 size3 mtight"><span class="mord mathnormal mtight" style="margin-right:0.02778em;">r</span></span></span></span><span class="vlist-s"></span></span><span class="vlist-r"><span class="vlist" style="height:0.15em;"><span></span></span></span></span></span></span><span class="mord mathnormal">oo</span><span class="mord mathnormal">t</span><span class="mspace" style="margin-right:0.2777777777777778em;"></span><span class="mrel">=</span><span class="mspace" style="margin-right:0.2777777777777778em;"></span></span><span class="base"><span class="strut" style="height:0.69444em;vertical-align:0em;"></span><span class="mord">"</span></span></span></span>{HOME}/android/sdk" --install 'platform-tools'
<span class="katex"><span class="katex-html" aria-hidden="true"><span class="base"><span class="strut" style="height:1em;vertical-align:-0.25em;"></span><span class="mord">./</span><span class="mord mathnormal">s</span><span class="mord mathnormal">d</span><span class="mord mathnormal">kmana</span><span class="mord mathnormal" style="margin-right:0.03588em;">g</span><span class="mord mathnormal" style="margin-right:0.02778em;">er</span><span class="mspace" style="margin-right:0.2222222222222222em;"></span><span class="mbin">−</span><span class="mspace" style="margin-right:0.2222222222222222em;"></span></span><span class="base"><span class="strut" style="height:0.84444em;vertical-align:-0.15em;"></span><span class="mord">−</span><span class="mord mathnormal">s</span><span class="mord mathnormal">d</span><span class="mord"><span class="mord mathnormal" style="margin-right:0.03148em;">k</span><span class="msupsub"><span class="vlist-t vlist-t2"><span class="vlist-r"><span class="vlist" style="height:0.151392em;"><span style="top:-2.5500000000000003em;margin-left:-0.03148em;margin-right:0.05em;"><span class="pstrut" style="height:2.7em;"></span><span class="sizing reset-size6 size3 mtight"><span class="mord mathnormal mtight" style="margin-right:0.02778em;">r</span></span></span></span><span class="vlist-s"></span></span><span class="vlist-r"><span class="vlist" style="height:0.15em;"><span></span></span></span></span></span></span><span class="mord mathnormal">oo</span><span class="mord mathnormal">t</span><span class="mspace" style="margin-right:0.2777777777777778em;"></span><span class="mrel">=</span><span class="mspace" style="margin-right:0.2777777777777778em;"></span></span><span class="base"><span class="strut" style="height:0.69444em;vertical-align:0em;"></span><span class="mord">"</span></span></span></span>{HOME}/android/sdk" --install 'platforms;android-29'
尽管 Android 支持运行 native 代码,但是大多数应用还是采用 Java 或者 Kotlin 来编写,SDK 反应了这一点。为了能够使用 native 代码,我还需要一个工具 - 原生开发工具套件 (Native Development kit)。NDK 下载页面 提供了几个版本以供选择 - 在经过一段深思熟虑后,我决定使用 LTS 版本:r21e。
足够简单!或想太多?
搞定了开发工具之后,我决定试着直接编译项目。
<span class="katex"><span class="katex-html" aria-hidden="true"><span class="base"><span class="strut" style="height:0.8888799999999999em;vertical-align:-0.19444em;"></span><span class="mord mathnormal">c</span><span class="mord mathnormal">a</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal" style="margin-right:0.03588em;">g</span><span class="mord mathnormal">o</span><span class="mord mathnormal">b</span><span class="mord mathnormal">u</span><span class="mord mathnormal">i</span><span class="mord mathnormal" style="margin-right:0.01968em;">l</span><span class="mord mathnormal">d</span><span class="mspace" style="margin-right:0.2222222222222222em;"></span><span class="mbin">−</span><span class="mspace" style="margin-right:0.2222222222222222em;"></span></span><span class="base"><span class="strut" style="height:0.80952em;vertical-align:-0.19444em;"></span><span class="mord">−</span><span class="mord mathnormal">t</span><span class="mord mathnormal">a</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal" style="margin-right:0.03588em;">g</span><span class="mord mathnormal">e</span><span class="mord mathnormal">t</span><span class="mspace" style="margin-right:0.2777777777777778em;"></span><span class="mrel">=</span><span class="mspace" style="margin-right:0.2777777777777778em;"></span></span><span class="base"><span class="strut" style="height:0.77777em;vertical-align:-0.08333em;"></span><span class="mord mathnormal">aa</span><span class="mord mathnormal">rc</span><span class="mord mathnormal">h</span><span class="mord">64</span><span class="mspace" style="margin-right:0.2222222222222222em;"></span><span class="mbin">−</span><span class="mspace" style="margin-right:0.2222222222222222em;"></span></span><span class="base"><span class="strut" style="height:0.77777em;vertical-align:-0.08333em;"></span><span class="mord mathnormal" style="margin-right:0.01968em;">l</span><span class="mord mathnormal">in</span><span class="mord mathnormal">ux</span><span class="mspace" style="margin-right:0.2222222222222222em;"></span><span class="mbin">−</span><span class="mspace" style="margin-right:0.2222222222222222em;"></span></span><span class="base"><span class="strut" style="height:1em;vertical-align:-0.25em;"></span><span class="mord mathnormal">an</span><span class="mord mathnormal">d</span><span class="mord mathnormal">ro</span><span class="mord mathnormal">i</span><span class="mord mathnormal">d</span><span class="mord">‘‘‘</span><span class="mord cjk_fallback">和预期的一样,构建失败了,并且错误信息占满了整个屏幕。经过筛选</span><span class="mopen">(</span><span class="mord mathnormal">s</span><span class="mord mathnormal">i</span><span class="mord mathnormal" style="margin-right:0.10764em;">f</span><span class="mord mathnormal">t</span><span class="mclose">)</span><span class="mord cjk_fallback">后,显示存在一个链接错误:</span><span class="mord">‘‘‘</span><span class="mord mathnormal">co</span><span class="mord mathnormal">n</span><span class="mord mathnormal">so</span><span class="mord mathnormal" style="margin-right:0.01968em;">l</span><span class="mord mathnormal" style="margin-right:0.02778em;">eerror</span><span class="mspace" style="margin-right:0.2777777777777778em;"></span><span class="mrel">:</span><span class="mspace" style="margin-right:0.2777777777777778em;"></span></span><span class="base"><span class="strut" style="height:0.8888799999999999em;vertical-align:-0.19444em;"></span><span class="mord mathnormal" style="margin-right:0.01968em;">l</span><span class="mord mathnormal">inkin</span><span class="mord mathnormal" style="margin-right:0.03588em;">g</span><span class="mord mathnormal" style="margin-right:0.02691em;">w</span><span class="mord mathnormal">i</span><span class="mord mathnormal">t</span><span class="mord mathnormal">h</span><span class="mord">‘</span><span class="mord mathnormal">cc</span><span class="mord">‘</span><span class="mord mathnormal" style="margin-right:0.10764em;">f</span><span class="mord mathnormal">ai</span><span class="mord mathnormal" style="margin-right:0.01968em;">l</span><span class="mord mathnormal">e</span><span class="mord mathnormal">d</span><span class="mspace" style="margin-right:0.2777777777777778em;"></span><span class="mrel">:</span><span class="mspace" style="margin-right:0.2777777777777778em;"></span></span><span class="base"><span class="strut" style="height:0.69444em;vertical-align:0em;"></span><span class="mord mathnormal">e</span><span class="mord mathnormal">x</span><span class="mord mathnormal">i</span><span class="mord mathnormal">t</span><span class="mord mathnormal">co</span><span class="mord mathnormal">d</span><span class="mord mathnormal">e</span><span class="mspace" style="margin-right:0.2777777777777778em;"></span><span class="mrel">:</span><span class="mspace" style="margin-right:0.2777777777777778em;"></span></span><span class="base"><span class="strut" style="height:1em;vertical-align:-0.25em;"></span><span class="mord">1/</span><span class="mord mathnormal">u</span><span class="mord mathnormal" style="margin-right:0.02778em;">sr</span><span class="mord">/</span><span class="mord mathnormal">bin</span><span class="mord">/</span><span class="mord mathnormal" style="margin-right:0.01968em;">l</span><span class="mord mathnormal">d</span><span class="mspace" style="margin-right:0.2777777777777778em;"></span><span class="mrel">:</span><span class="mspace" style="margin-right:0.2777777777777778em;"></span></span><span class="base"><span class="strut" style="height:0.8888799999999999em;vertical-align:-0.19444em;"></span><span class="mord mathnormal">s</span><span class="mord mathnormal">t</span><span class="mord mathnormal">a</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal">t</span><span class="mord mathnormal">u</span><span class="mord mathnormal">p</span><span class="mord">.48656</span><span class="mord mathnormal">c</span><span class="mord">6</span><span class="mord mathnormal">c</span><span class="mord">6</span><span class="mord mathnormal" style="margin-right:0.10764em;">f</span><span class="mord">20546865726521.</span><span class="mord mathnormal">o</span><span class="mspace" style="margin-right:0.2777777777777778em;"></span><span class="mrel">:</span><span class="mspace" style="margin-right:0.2777777777777778em;"></span></span><span class="base"><span class="strut" style="height:1em;vertical-align:-0.25em;"></span><span class="mord mathnormal" style="margin-right:0.00773em;">R</span><span class="mord mathnormal">e</span><span class="mord mathnormal" style="margin-right:0.01968em;">l</span><span class="mord mathnormal">oc</span><span class="mord mathnormal">a</span><span class="mord mathnormal">t</span><span class="mord mathnormal">i</span><span class="mord mathnormal">o</span><span class="mord mathnormal">n</span><span class="mord mathnormal">s</span><span class="mord mathnormal">in</span><span class="mord mathnormal" style="margin-right:0.03588em;">g</span><span class="mord mathnormal">e</span><span class="mord mathnormal">n</span><span class="mord mathnormal" style="margin-right:0.02778em;">er</span><span class="mord mathnormal">i</span><span class="mord mathnormal">c</span><span class="mord mathnormal" style="margin-right:0.05764em;">E</span><span class="mord mathnormal">L</span><span class="mord mathnormal" style="margin-right:0.13889em;">F</span><span class="mopen">(</span><span class="mord mathnormal" style="margin-right:0.10903em;">EM</span><span class="mspace" style="margin-right:0.2777777777777778em;"></span><span class="mrel">:</span><span class="mspace" style="margin-right:0.2777777777777778em;"></span></span><span class="base"><span class="strut" style="height:1em;vertical-align:-0.25em;"></span><span class="mord">183</span><span class="mclose">)</span><span class="mord">/</span><span class="mord mathnormal">u</span><span class="mord mathnormal" style="margin-right:0.02778em;">sr</span><span class="mord">/</span><span class="mord mathnormal">bin</span><span class="mord">/</span><span class="mord mathnormal" style="margin-right:0.01968em;">l</span><span class="mord mathnormal">d</span><span class="mspace" style="margin-right:0.2777777777777778em;"></span><span class="mrel">:</span><span class="mspace" style="margin-right:0.2777777777777778em;"></span></span><span class="base"><span class="strut" style="height:0.8888799999999999em;vertical-align:-0.19444em;"></span><span class="mord mathnormal">s</span><span class="mord mathnormal">t</span><span class="mord mathnormal">a</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal">t</span><span class="mord mathnormal">u</span><span class="mord mathnormal">p</span><span class="mord">.48656</span><span class="mord mathnormal">c</span><span class="mord">6</span><span class="mord mathnormal">c</span><span class="mord">6</span><span class="mord mathnormal" style="margin-right:0.10764em;">f</span><span class="mord">20546865726521.</span><span class="mord mathnormal">o</span><span class="mspace" style="margin-right:0.2777777777777778em;"></span><span class="mrel">:</span><span class="mspace" style="margin-right:0.2777777777777778em;"></span></span><span class="base"><span class="strut" style="height:0.8888799999999999em;vertical-align:-0.19444em;"></span><span class="mord mathnormal" style="margin-right:0.02778em;">error</span><span class="mord mathnormal">a</span><span class="mord mathnormal">dd</span><span class="mord mathnormal">in</span><span class="mord mathnormal" style="margin-right:0.03588em;">g</span><span class="mord mathnormal" style="margin-right:0.03588em;">sy</span><span class="mord mathnormal">mb</span><span class="mord mathnormal">o</span><span class="mord mathnormal" style="margin-right:0.01968em;">l</span><span class="mord mathnormal">s</span><span class="mspace" style="margin-right:0.2777777777777778em;"></span><span class="mrel">:</span><span class="mspace" style="margin-right:0.2777777777777778em;"></span></span><span class="base"><span class="strut" style="height:0.8888799999999999em;vertical-align:-0.19444em;"></span><span class="mord mathnormal" style="margin-right:0.10764em;">f</span><span class="mord mathnormal">i</span><span class="mord mathnormal" style="margin-right:0.01968em;">l</span><span class="mord mathnormal">e</span><span class="mord mathnormal">in</span><span class="mord mathnormal" style="margin-right:0.02691em;">w</span><span class="mord mathnormal">ro</span><span class="mord mathnormal">n</span><span class="mord mathnormal" style="margin-right:0.03588em;">g</span><span class="mord mathnormal" style="margin-right:0.10764em;">f</span><span class="mord mathnormal" style="margin-right:0.02778em;">or</span><span class="mord mathnormal">ma</span><span class="mord mathnormal">t</span><span class="mord mathnormal">co</span><span class="mord mathnormal" style="margin-right:0.01968em;">ll</span><span class="mord mathnormal">ec</span><span class="mord mathnormal">t</span><span class="mord">2</span><span class="mspace" style="margin-right:0.2777777777777778em;"></span><span class="mrel">:</span><span class="mspace" style="margin-right:0.2777777777777778em;"></span></span><span class="base"><span class="strut" style="height:0.43056em;vertical-align:0em;"></span><span class="mord mathnormal" style="margin-right:0.02778em;">error</span><span class="mspace" style="margin-right:0.2777777777777778em;"></span><span class="mrel">:</span><span class="mspace" style="margin-right:0.2777777777777778em;"></span></span><span class="base"><span class="strut" style="height:1em;vertical-align:-0.25em;"></span><span class="mord mathnormal" style="margin-right:0.01968em;">l</span><span class="mord mathnormal">d</span><span class="mord mathnormal">re</span><span class="mord mathnormal">t</span><span class="mord mathnormal">u</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal">n</span><span class="mord mathnormal">e</span><span class="mord mathnormal">d</span><span class="mord">1</span><span class="mord mathnormal">e</span><span class="mord mathnormal">x</span><span class="mord mathnormal">i</span><span class="mord mathnormal">t</span><span class="mord mathnormal">s</span><span class="mord mathnormal">t</span><span class="mord mathnormal">a</span><span class="mord mathnormal">t</span><span class="mord mathnormal">u</span><span class="mord mathnormal">s</span><span class="mord">‘‘‘</span><span class="mord cjk_fallback">我认为这</span><span class="mopen">(</span><span class="mord cjk_fallback">错误提示</span><span class="mclose">)</span><span class="mord cjk_fallback">足够简单</span><span class="mspace" style="margin-right:0.2222222222222222em;"></span><span class="mbin">−</span><span class="mspace" style="margin-right:0.2222222222222222em;"></span></span><span class="base"><span class="strut" style="height:1em;vertical-align:-0.25em;"></span><span class="mord mathnormal" style="margin-right:0.07153em;">C</span><span class="mord mathnormal">a</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal" style="margin-right:0.03588em;">g</span><span class="mord mathnormal">o</span><span class="mord cjk_fallback">试图使用系统的链接器</span><span class="mopen">(</span><span class="mord mathnormal" style="margin-right:0.01968em;">l</span><span class="mord mathnormal" style="margin-right:0.03148em;">ink</span><span class="mord mathnormal" style="margin-right:0.02778em;">er</span><span class="mclose">)</span><span class="mord cjk_fallback">而不是</span><span class="mord mathnormal">A</span><span class="mord mathnormal">n</span><span class="mord mathnormal">d</span><span class="mord mathnormal">ro</span><span class="mord mathnormal">i</span><span class="mord mathnormal">d</span><span class="mord mathnormal" style="margin-right:0.10903em;">N</span><span class="mord mathnormal" style="margin-right:0.07153em;">DK</span><span class="mord cjk_fallback">的链接器。我可以使用</span><span class="mord">‘</span><span class="mord mathnormal" style="margin-right:0.07153em;">CC</span><span class="mord">‘</span><span class="mord cjk_fallback">和</span><span class="mord">‘</span><span class="mord mathnormal">L</span><span class="mord mathnormal" style="margin-right:0.02778em;">D</span><span class="mord">‘</span><span class="mord cjk_fallback">环境变量让</span><span class="mord mathnormal" style="margin-right:0.07153em;">C</span><span class="mord mathnormal">a</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal" style="margin-right:0.03588em;">g</span><span class="mord mathnormal">o</span><span class="mord cjk_fallback">指向正确的链接器。</span><span class="mord">‘‘‘</span><span class="mord mathnormal">co</span><span class="mord mathnormal">n</span><span class="mord mathnormal">so</span><span class="mord mathnormal" style="margin-right:0.01968em;">l</span><span class="mord mathnormal">e</span></span></span></span> export ANDROID_NDK_ROOT="<span class="katex"><span class="katex-html" aria-hidden="true"><span class="base"><span class="strut" style="height:1em;vertical-align:-0.25em;"></span><span class="mord"><span class="mord mathnormal" style="margin-right:0.08125em;">H</span><span class="mord mathnormal" style="margin-right:0.05764em;">OME</span></span><span class="mord">/</span><span class="mord mathnormal">an</span><span class="mord mathnormal">d</span><span class="mord mathnormal">ro</span><span class="mord mathnormal">i</span><span class="mord mathnormal">d</span><span class="mord">/</span><span class="mord mathnormal">n</span><span class="mord mathnormal">d</span><span class="mord mathnormal" style="margin-right:0.03148em;">k</span><span class="mord">"</span></span></span></span> export TOOLCHAIN="<span class="katex"><span class="katex-html" aria-hidden="true"><span class="base"><span class="strut" style="height:1em;vertical-align:-0.25em;"></span><span class="mord"><span class="mord mathnormal">A</span><span class="mord mathnormal" style="margin-right:0.10903em;">N</span><span class="mord mathnormal" style="margin-right:0.02778em;">D</span><span class="mord mathnormal" style="margin-right:0.02778em;">RO</span><span class="mord mathnormal" style="margin-right:0.07847em;">I</span><span class="mord"><span class="mord mathnormal" style="margin-right:0.02778em;">D</span><span class="msupsub"><span class="vlist-t vlist-t2"><span class="vlist-r"><span class="vlist" style="height:0.32833099999999993em;"><span style="top:-2.5500000000000003em;margin-left:-0.02778em;margin-right:0.05em;"><span class="pstrut" style="height:2.7em;"></span><span class="sizing reset-size6 size3 mtight"><span class="mord mathnormal mtight" style="margin-right:0.10903em;">N</span></span></span></span><span class="vlist-s"></span></span><span class="vlist-r"><span class="vlist" style="height:0.15em;"><span></span></span></span></span></span></span><span class="mord mathnormal" style="margin-right:0.02778em;">D</span><span class="mord"><span class="mord mathnormal" style="margin-right:0.07153em;">K</span><span class="msupsub"><span class="vlist-t vlist-t2"><span class="vlist-r"><span class="vlist" style="height:0.32833099999999993em;"><span style="top:-2.5500000000000003em;margin-left:-0.07153em;margin-right:0.05em;"><span class="pstrut" style="height:2.7em;"></span><span class="sizing reset-size6 size3 mtight"><span class="mord mathnormal mtight" style="margin-right:0.00773em;">R</span></span></span></span><span class="vlist-s"></span></span><span class="vlist-r"><span class="vlist" style="height:0.15em;"><span></span></span></span></span></span></span><span class="mord mathnormal" style="margin-right:0.13889em;">OOT</span></span><span class="mord">/</span><span class="mord mathnormal">t</span><span class="mord mathnormal">oo</span><span class="mord mathnormal" style="margin-right:0.01968em;">l</span><span class="mord mathnormal">c</span><span class="mord mathnormal">hain</span><span class="mord mathnormal">s</span><span class="mord">/</span><span class="mord mathnormal" style="margin-right:0.01968em;">ll</span><span class="mord mathnormal" style="margin-right:0.03588em;">v</span><span class="mord mathnormal">m</span><span class="mord">/</span><span class="mord mathnormal">p</span><span class="mord mathnormal">re</span><span class="mord mathnormal">b</span><span class="mord mathnormal">u</span><span class="mord mathnormal">i</span><span class="mord mathnormal">lt</span><span class="mord">/</span><span class="mord mathnormal" style="margin-right:0.01968em;">l</span><span class="mord mathnormal">in</span><span class="mord mathnormal">ux</span><span class="mspace" style="margin-right:0.2222222222222222em;"></span><span class="mbin">−</span><span class="mspace" style="margin-right:0.2222222222222222em;"></span></span><span class="base"><span class="strut" style="height:0.84444em;vertical-align:-0.15em;"></span><span class="mord mathnormal">x</span><span class="mord">8</span><span class="mord"><span class="mord">6</span><span class="msupsub"><span class="vlist-t vlist-t2"><span class="vlist-r"><span class="vlist" style="height:0.30110799999999993em;"><span style="top:-2.5500000000000003em;margin-left:0em;margin-right:0.05em;"><span class="pstrut" style="height:2.7em;"></span><span class="sizing reset-size6 size3 mtight"><span class="mord mtight">6</span></span></span></span><span class="vlist-s"></span></span><span class="vlist-r"><span class="vlist" style="height:0.15em;"><span></span></span></span></span></span></span><span class="mord">4"</span></span></span></span> export CC="<span class="katex"><span class="katex-html" aria-hidden="true"><span class="base"><span class="strut" style="height:1em;vertical-align:-0.25em;"></span><span class="mord"><span class="mord mathnormal" style="margin-right:0.02778em;">TOO</span><span class="mord mathnormal">L</span><span class="mord mathnormal" style="margin-right:0.07153em;">C</span><span class="mord mathnormal" style="margin-right:0.08125em;">H</span><span class="mord mathnormal">A</span><span class="mord mathnormal" style="margin-right:0.07847em;">I</span><span class="mord mathnormal" style="margin-right:0.10903em;">N</span></span><span class="mord">/</span><span class="mord mathnormal">bin</span><span class="mord">/</span><span class="mord mathnormal">aa</span><span class="mord mathnormal">rc</span><span class="mord mathnormal">h</span><span class="mord">64</span><span class="mspace" style="margin-right:0.2222222222222222em;"></span><span class="mbin">−</span><span class="mspace" style="margin-right:0.2222222222222222em;"></span></span><span class="base"><span class="strut" style="height:0.77777em;vertical-align:-0.08333em;"></span><span class="mord mathnormal" style="margin-right:0.01968em;">l</span><span class="mord mathnormal">in</span><span class="mord mathnormal">ux</span><span class="mspace" style="margin-right:0.2222222222222222em;"></span><span class="mbin">−</span><span class="mspace" style="margin-right:0.2222222222222222em;"></span></span><span class="base"><span class="strut" style="height:0.77777em;vertical-align:-0.08333em;"></span><span class="mord mathnormal">an</span><span class="mord mathnormal">d</span><span class="mord mathnormal">ro</span><span class="mord mathnormal">i</span><span class="mord mathnormal">d</span><span class="mord">29</span><span class="mspace" style="margin-right:0.2222222222222222em;"></span><span class="mbin">−</span><span class="mspace" style="margin-right:0.2222222222222222em;"></span></span><span class="base"><span class="strut" style="height:0.8888799999999999em;vertical-align:-0.19444em;"></span><span class="mord mathnormal">c</span><span class="mord mathnormal" style="margin-right:0.01968em;">l</span><span class="mord mathnormal">an</span><span class="mord mathnormal" style="margin-right:0.03588em;">g</span><span class="mord">"</span></span></span></span> export LD="<span class="katex"><span class="katex-html" aria-hidden="true"><span class="base"><span class="strut" style="height:1em;vertical-align:-0.25em;"></span><span class="mord"><span class="mord mathnormal" style="margin-right:0.02778em;">TOO</span><span class="mord mathnormal">L</span><span class="mord mathnormal" style="margin-right:0.07153em;">C</span><span class="mord mathnormal" style="margin-right:0.08125em;">H</span><span class="mord mathnormal">A</span><span class="mord mathnormal" style="margin-right:0.07847em;">I</span><span class="mord mathnormal" style="margin-right:0.10903em;">N</span></span><span class="mord">/</span><span class="mord mathnormal">bin</span><span class="mord">/</span><span class="mord mathnormal">aa</span><span class="mord mathnormal">rc</span><span class="mord mathnormal">h</span><span class="mord">64</span><span class="mspace" style="margin-right:0.2222222222222222em;"></span><span class="mbin">−</span><span class="mspace" style="margin-right:0.2222222222222222em;"></span></span><span class="base"><span class="strut" style="height:0.77777em;vertical-align:-0.08333em;"></span><span class="mord mathnormal" style="margin-right:0.01968em;">l</span><span class="mord mathnormal">in</span><span class="mord mathnormal">ux</span><span class="mspace" style="margin-right:0.2222222222222222em;"></span><span class="mbin">−</span><span class="mspace" style="margin-right:0.2222222222222222em;"></span></span><span class="base"><span class="strut" style="height:0.77777em;vertical-align:-0.08333em;"></span><span class="mord mathnormal">an</span><span class="mord mathnormal">d</span><span class="mord mathnormal">ro</span><span class="mord mathnormal">i</span><span class="mord mathnormal">d</span><span class="mspace" style="margin-right:0.2222222222222222em;"></span><span class="mbin">−</span><span class="mspace" style="margin-right:0.2222222222222222em;"></span></span><span class="base"><span class="strut" style="height:0.69444em;vertical-align:0em;"></span><span class="mord mathnormal" style="margin-right:0.01968em;">l</span><span class="mord mathnormal">d</span><span class="mord">"</span></span></span></span> cargo build --target=aarch64-linux-android
让我失望的是,这并没有起作用。我不愿意花费一天的时间来和 Cargo 纠缠 (wrestle),因此我决定寻找是否有其他人给出了解决方案 - 很快,我便找到看似十分完美的工具。
cargo-apk
cargo-apk 是一个可以简单的将 Cargo 项目构建成.apk的工具。你所需要做得就是安装这个工具,在Cargo.toml文件中添加一些配置,然后你就可以继续了。
# cargo-apk compiles your code to an .so file,
# which is then loaded by the Android runtime
[lib]
path = "src/main.rs"
crate-type = ["cdylib"]
# Android-specic configuration follows.
[package.metadata.android]
# Name of your APK as shown in the app drawer and in the app switcher
apk_label = "Hip Startup"
# The target Android API level.
target_sdk_version = 29
min_sdk_version = 26
# See: https://developer.android.com/guide/topics/manifest/activity-element#screen
orientation = "portrait"
有了上面添加的配置,我试图使用cargo-apk来构建项目。
<span class="katex"><span class="katex-html" aria-hidden="true"><span class="base"><span class="strut" style="height:0.8888799999999999em;vertical-align:-0.19444em;"></span><span class="mord mathnormal">c</span><span class="mord mathnormal">a</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal" style="margin-right:0.03588em;">g</span><span class="mord mathnormal">o</span><span class="mord mathnormal">in</span><span class="mord mathnormal">s</span><span class="mord mathnormal">t</span><span class="mord mathnormal">a</span><span class="mord mathnormal" style="margin-right:0.01968em;">ll</span><span class="mord mathnormal">c</span><span class="mord mathnormal">a</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal" style="margin-right:0.03588em;">g</span><span class="mord mathnormal">o</span><span class="mspace" style="margin-right:0.2222222222222222em;"></span><span class="mbin">−</span><span class="mspace" style="margin-right:0.2222222222222222em;"></span></span><span class="base"><span class="strut" style="height:0.8888799999999999em;vertical-align:-0.19444em;"></span><span class="mord mathnormal">a</span><span class="mord mathnormal">p</span><span class="mord mathnormal" style="margin-right:0.03148em;">k</span></span></span></span> export ANDROID_SDK_ROOT="<span class="katex"><span class="katex-html" aria-hidden="true"><span class="base"><span class="strut" style="height:1em;vertical-align:-0.25em;"></span><span class="mord"><span class="mord mathnormal" style="margin-right:0.08125em;">H</span><span class="mord mathnormal" style="margin-right:0.05764em;">OME</span></span><span class="mord">/</span><span class="mord mathnormal">an</span><span class="mord mathnormal">d</span><span class="mord mathnormal">ro</span><span class="mord mathnormal">i</span><span class="mord mathnormal">d</span><span class="mord">/</span><span class="mord mathnormal">s</span><span class="mord mathnormal">d</span><span class="mord mathnormal" style="margin-right:0.03148em;">k</span><span class="mord">"</span></span></span></span> export ANDROID_NDK_ROOT="<span class="katex"><span class="katex-html" aria-hidden="true"><span class="base"><span class="strut" style="height:1em;vertical-align:-0.25em;"></span><span class="mord"><span class="mord mathnormal" style="margin-right:0.08125em;">H</span><span class="mord mathnormal" style="margin-right:0.05764em;">OME</span></span><span class="mord">/</span><span class="mord mathnormal">an</span><span class="mord mathnormal">d</span><span class="mord mathnormal">ro</span><span class="mord mathnormal">i</span><span class="mord mathnormal">d</span><span class="mord">/</span><span class="mord mathnormal">n</span><span class="mord mathnormal">d</span><span class="mord mathnormal" style="margin-right:0.03148em;">k</span><span class="mord">"</span></span></span></span> cargo apk build --target aarch64-linux-android
令人惊奇的是,它成功了!(等等) 额,好吧,我再一次遇到了链接错误。但是这一次,它不是关于重定位和文件格式的神秘错误,而是一个缺少链接库的错误提示:
error: linking with `aarch64-linux-android29-clang` failed: exit code: 1
aarch64-linux-android/bin/ld: cannot find -lsqlite3
clang: error: linker command failed with exit code 1 (use -v to see invocation)
依赖,依赖,依赖
我们的项目使用 SQLite,这是一个 C 库。尽管 Rust 社区在每个可能的场合都吹捧 (tout) ”用 Rust 重写“在某种程度上是臭名昭著的,但是实际上某些与流行库一起使用的 crate 并不需要重新实现,因为这需要大量的 (colossal) 工作。相反,它们仅提供在 Rust 代码中调用库的方式,既可以作为 C 函数重新导出,也可以提供更加友好的 API 并稍微抽象化 FFI 调用。我们使用的 rusqlite 并没有什么不同,意味着我们也需要构建 SQLite。
SQLite 使用 GNU Autotool 进行构建。在对环境变量和用于配置的选项有了一些了解之后,我仔细浏览了 NDK 的文档 - 我找到了一个在各种构建系统(包括 Autotools) 中使用 NDK 的文档页面。尽管 Google 提供了 LTS 版本的 NDK,以及最新版本的文档,但在 r21 LTS 和最新的 r22 之间发生了变化,事情变得稍微有点棘手。幸运的是,Wayback 机器具有该页面的历史版本,让我能够找到合适的 NDK r21 的说明。
<span class="katex"><span class="katex-html" aria-hidden="true"><span class="base"><span class="strut" style="height:0.83333em;vertical-align:-0.15em;"></span><span class="mord mathnormal">A</span><span class="mord mathnormal" style="margin-right:0.10903em;">N</span><span class="mord mathnormal" style="margin-right:0.02778em;">D</span><span class="mord mathnormal" style="margin-right:0.02778em;">RO</span><span class="mord mathnormal" style="margin-right:0.07847em;">I</span><span class="mord"><span class="mord mathnormal" style="margin-right:0.02778em;">D</span><span class="msupsub"><span class="vlist-t vlist-t2"><span class="vlist-r"><span class="vlist" style="height:0.32833099999999993em;"><span style="top:-2.5500000000000003em;margin-left:-0.02778em;margin-right:0.05em;"><span class="pstrut" style="height:2.7em;"></span><span class="sizing reset-size6 size3 mtight"><span class="mord mathnormal mtight">A</span></span></span></span><span class="vlist-s"></span></span><span class="vlist-r"><span class="vlist" style="height:0.15em;"><span></span></span></span></span></span></span><span class="mord mathnormal" style="margin-right:0.13889em;">P</span><span class="mord mathnormal" style="margin-right:0.07847em;">I</span><span class="mspace" style="margin-right:0.2777777777777778em;"></span><span class="mrel">=</span><span class="mspace" style="margin-right:0.2777777777777778em;"></span></span><span class="base"><span class="strut" style="height:0.64444em;vertical-align:0em;"></span><span class="mord">29</span></span></span></span> TOOLCHAIN="<span class="katex"><span class="katex-html" aria-hidden="true"><span class="base"><span class="strut" style="height:1em;vertical-align:-0.25em;"></span><span class="mord"><span class="mord mathnormal">A</span><span class="mord mathnormal" style="margin-right:0.10903em;">N</span><span class="mord mathnormal" style="margin-right:0.02778em;">D</span><span class="mord mathnormal" style="margin-right:0.02778em;">RO</span><span class="mord mathnormal" style="margin-right:0.07847em;">I</span><span class="mord"><span class="mord mathnormal" style="margin-right:0.02778em;">D</span><span class="msupsub"><span class="vlist-t vlist-t2"><span class="vlist-r"><span class="vlist" style="height:0.32833099999999993em;"><span style="top:-2.5500000000000003em;margin-left:-0.02778em;margin-right:0.05em;"><span class="pstrut" style="height:2.7em;"></span><span class="sizing reset-size6 size3 mtight"><span class="mord mathnormal mtight" style="margin-right:0.10903em;">N</span></span></span></span><span class="vlist-s"></span></span><span class="vlist-r"><span class="vlist" style="height:0.15em;"><span></span></span></span></span></span></span><span class="mord mathnormal" style="margin-right:0.02778em;">D</span><span class="mord"><span class="mord mathnormal" style="margin-right:0.07153em;">K</span><span class="msupsub"><span class="vlist-t vlist-t2"><span class="vlist-r"><span class="vlist" style="height:0.32833099999999993em;"><span style="top:-2.5500000000000003em;margin-left:-0.07153em;margin-right:0.05em;"><span class="pstrut" style="height:2.7em;"></span><span class="sizing reset-size6 size3 mtight"><span class="mord mathnormal mtight" style="margin-right:0.00773em;">R</span></span></span></span><span class="vlist-s"></span></span><span class="vlist-r"><span class="vlist" style="height:0.15em;"><span></span></span></span></span></span></span><span class="mord mathnormal" style="margin-right:0.13889em;">OOT</span></span><span class="mord">/</span><span class="mord mathnormal">t</span><span class="mord mathnormal">oo</span><span class="mord mathnormal" style="margin-right:0.01968em;">l</span><span class="mord mathnormal">c</span><span class="mord mathnormal">hain</span><span class="mord mathnormal">s</span><span class="mord">/</span><span class="mord mathnormal" style="margin-right:0.01968em;">ll</span><span class="mord mathnormal" style="margin-right:0.03588em;">v</span><span class="mord mathnormal">m</span><span class="mord">/</span><span class="mord mathnormal">p</span><span class="mord mathnormal">re</span><span class="mord mathnormal">b</span><span class="mord mathnormal">u</span><span class="mord mathnormal">i</span><span class="mord mathnormal">lt</span><span class="mord">/</span><span class="mord mathnormal" style="margin-right:0.01968em;">l</span><span class="mord mathnormal">in</span><span class="mord mathnormal">ux</span><span class="mspace" style="margin-right:0.2222222222222222em;"></span><span class="mbin">−</span><span class="mspace" style="margin-right:0.2222222222222222em;"></span></span><span class="base"><span class="strut" style="height:0.84444em;vertical-align:-0.15em;"></span><span class="mord mathnormal">x</span><span class="mord">8</span><span class="mord"><span class="mord">6</span><span class="msupsub"><span class="vlist-t vlist-t2"><span class="vlist-r"><span class="vlist" style="height:0.30110799999999993em;"><span style="top:-2.5500000000000003em;margin-left:0em;margin-right:0.05em;"><span class="pstrut" style="height:2.7em;"></span><span class="sizing reset-size6 size3 mtight"><span class="mord mtight">6</span></span></span></span><span class="vlist-s"></span></span><span class="vlist-r"><span class="vlist" style="height:0.15em;"><span></span></span></span></span></span></span><span class="mord">4"</span><span class="mord mathnormal">i</span></span></span></span> export CC="<span class="katex"><span class="katex-html" aria-hidden="true"><span class="base"><span class="strut" style="height:1em;vertical-align:-0.25em;"></span><span class="mord"><span class="mord mathnormal" style="margin-right:0.02778em;">TOO</span><span class="mord mathnormal">L</span><span class="mord mathnormal" style="margin-right:0.07153em;">C</span><span class="mord mathnormal" style="margin-right:0.08125em;">H</span><span class="mord mathnormal">A</span><span class="mord mathnormal" style="margin-right:0.07847em;">I</span><span class="mord mathnormal" style="margin-right:0.10903em;">N</span></span><span class="mord">/</span><span class="mord mathnormal">bin</span><span class="mord">/</span><span class="mord mathnormal">aa</span><span class="mord mathnormal">rc</span><span class="mord mathnormal">h</span><span class="mord">64</span><span class="mspace" style="margin-right:0.2222222222222222em;"></span><span class="mbin">−</span><span class="mspace" style="margin-right:0.2222222222222222em;"></span></span><span class="base"><span class="strut" style="height:0.77777em;vertical-align:-0.08333em;"></span><span class="mord mathnormal" style="margin-right:0.01968em;">l</span><span class="mord mathnormal">in</span><span class="mord mathnormal">ux</span><span class="mspace" style="margin-right:0.2222222222222222em;"></span><span class="mbin">−</span><span class="mspace" style="margin-right:0.2222222222222222em;"></span></span><span class="base"><span class="strut" style="height:0.69444em;vertical-align:0em;"></span><span class="mord mathnormal">an</span><span class="mord mathnormal">d</span><span class="mord mathnormal">ro</span><span class="mord mathnormal">i</span><span class="mord mathnormal">d</span></span></span></span>{ANDROID_API}-clang"
<span class="katex"><span class="katex-html" aria-hidden="true"><span class="base"><span class="strut" style="height:0.8777699999999999em;vertical-align:-0.19444em;"></span><span class="mord mathnormal">e</span><span class="mord mathnormal">x</span><span class="mord mathnormal">p</span><span class="mord mathnormal" style="margin-right:0.02778em;">or</span><span class="mord mathnormal" style="margin-right:0.07847em;">tCXX</span><span class="mspace" style="margin-right:0.2777777777777778em;"></span><span class="mrel">=</span><span class="mspace" style="margin-right:0.2777777777777778em;"></span></span><span class="base"><span class="strut" style="height:0.69444em;vertical-align:0em;"></span><span class="mord">"</span></span></span></span>{TOOLCHAIN}/bin/aarch64-linux-android<span class="katex"><span class="katex-html" aria-hidden="true"><span class="base"><span class="strut" style="height:0.83333em;vertical-align:-0.15em;"></span><span class="mord"><span class="mord mathnormal">A</span><span class="mord mathnormal" style="margin-right:0.10903em;">N</span><span class="mord mathnormal" style="margin-right:0.02778em;">D</span><span class="mord mathnormal" style="margin-right:0.02778em;">RO</span><span class="mord mathnormal" style="margin-right:0.07847em;">I</span><span class="mord"><span class="mord mathnormal" style="margin-right:0.02778em;">D</span><span class="msupsub"><span class="vlist-t vlist-t2"><span class="vlist-r"><span class="vlist" style="height:0.32833099999999993em;"><span style="top:-2.5500000000000003em;margin-left:-0.02778em;margin-right:0.05em;"><span class="pstrut" style="height:2.7em;"></span><span class="sizing reset-size6 size3 mtight"><span class="mord mathnormal mtight">A</span></span></span></span><span class="vlist-s"></span></span><span class="vlist-r"><span class="vlist" style="height:0.15em;"><span></span></span></span></span></span></span><span class="mord mathnormal" style="margin-right:0.13889em;">P</span><span class="mord mathnormal" style="margin-right:0.07847em;">I</span></span><span class="mspace" style="margin-right:0.2222222222222222em;"></span><span class="mbin">−</span><span class="mspace" style="margin-right:0.2222222222222222em;"></span></span><span class="base"><span class="strut" style="height:0.8888799999999999em;vertical-align:-0.19444em;"></span><span class="mord mathnormal">c</span><span class="mord mathnormal" style="margin-right:0.01968em;">l</span><span class="mord mathnormal">an</span><span class="mord mathnormal" style="margin-right:0.03588em;">g</span><span class="mspace" style="margin-right:0.2222222222222222em;"></span><span class="mbin">+</span><span class="mspace" style="margin-right:0.2222222222222222em;"></span></span><span class="base"><span class="strut" style="height:0.77777em;vertical-align:-0.08333em;"></span><span class="mord">+</span><span class="mord">"</span></span></span></span> export AR="<span class="katex"><span class="katex-html" aria-hidden="true"><span class="base"><span class="strut" style="height:1em;vertical-align:-0.25em;"></span><span class="mord"><span class="mord mathnormal" style="margin-right:0.02778em;">TOO</span><span class="mord mathnormal">L</span><span class="mord mathnormal" style="margin-right:0.07153em;">C</span><span class="mord mathnormal" style="margin-right:0.08125em;">H</span><span class="mord mathnormal">A</span><span class="mord mathnormal" style="margin-right:0.07847em;">I</span><span class="mord mathnormal" style="margin-right:0.10903em;">N</span></span><span class="mord">/</span><span class="mord mathnormal">bin</span><span class="mord">/</span><span class="mord mathnormal">aa</span><span class="mord mathnormal">rc</span><span class="mord mathnormal">h</span><span class="mord">64</span><span class="mspace" style="margin-right:0.2222222222222222em;"></span><span class="mbin">−</span><span class="mspace" style="margin-right:0.2222222222222222em;"></span></span><span class="base"><span class="strut" style="height:0.77777em;vertical-align:-0.08333em;"></span><span class="mord mathnormal" style="margin-right:0.01968em;">l</span><span class="mord mathnormal">in</span><span class="mord mathnormal">ux</span><span class="mspace" style="margin-right:0.2222222222222222em;"></span><span class="mbin">−</span><span class="mspace" style="margin-right:0.2222222222222222em;"></span></span><span class="base"><span class="strut" style="height:0.77777em;vertical-align:-0.08333em;"></span><span class="mord mathnormal">an</span><span class="mord mathnormal">d</span><span class="mord mathnormal">ro</span><span class="mord mathnormal">i</span><span class="mord mathnormal">d</span><span class="mspace" style="margin-right:0.2222222222222222em;"></span><span class="mbin">−</span><span class="mspace" style="margin-right:0.2222222222222222em;"></span></span><span class="base"><span class="strut" style="height:0.69444em;vertical-align:0em;"></span><span class="mord mathnormal">a</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord">"</span></span></span></span> export AS="<span class="katex"><span class="katex-html" aria-hidden="true"><span class="base"><span class="strut" style="height:1em;vertical-align:-0.25em;"></span><span class="mord"><span class="mord mathnormal" style="margin-right:0.02778em;">TOO</span><span class="mord mathnormal">L</span><span class="mord mathnormal" style="margin-right:0.07153em;">C</span><span class="mord mathnormal" style="margin-right:0.08125em;">H</span><span class="mord mathnormal">A</span><span class="mord mathnormal" style="margin-right:0.07847em;">I</span><span class="mord mathnormal" style="margin-right:0.10903em;">N</span></span><span class="mord">/</span><span class="mord mathnormal">bin</span><span class="mord">/</span><span class="mord mathnormal">aa</span><span class="mord mathnormal">rc</span><span class="mord mathnormal">h</span><span class="mord">64</span><span class="mspace" style="margin-right:0.2222222222222222em;"></span><span class="mbin">−</span><span class="mspace" style="margin-right:0.2222222222222222em;"></span></span><span class="base"><span class="strut" style="height:0.77777em;vertical-align:-0.08333em;"></span><span class="mord mathnormal" style="margin-right:0.01968em;">l</span><span class="mord mathnormal">in</span><span class="mord mathnormal">ux</span><span class="mspace" style="margin-right:0.2222222222222222em;"></span><span class="mbin">−</span><span class="mspace" style="margin-right:0.2222222222222222em;"></span></span><span class="base"><span class="strut" style="height:0.77777em;vertical-align:-0.08333em;"></span><span class="mord mathnormal">an</span><span class="mord mathnormal">d</span><span class="mord mathnormal">ro</span><span class="mord mathnormal">i</span><span class="mord mathnormal">d</span><span class="mspace" style="margin-right:0.2222222222222222em;"></span><span class="mbin">−</span><span class="mspace" style="margin-right:0.2222222222222222em;"></span></span><span class="base"><span class="strut" style="height:0.69444em;vertical-align:0em;"></span><span class="mord mathnormal">a</span><span class="mord mathnormal">s</span><span class="mord">"</span></span></span></span> export LD="<span class="katex"><span class="katex-html" aria-hidden="true"><span class="base"><span class="strut" style="height:1em;vertical-align:-0.25em;"></span><span class="mord"><span class="mord mathnormal" style="margin-right:0.02778em;">TOO</span><span class="mord mathnormal">L</span><span class="mord mathnormal" style="margin-right:0.07153em;">C</span><span class="mord mathnormal" style="margin-right:0.08125em;">H</span><span class="mord mathnormal">A</span><span class="mord mathnormal" style="margin-right:0.07847em;">I</span><span class="mord mathnormal" style="margin-right:0.10903em;">N</span></span><span class="mord">/</span><span class="mord mathnormal">bin</span><span class="mord">/</span><span class="mord mathnormal">aa</span><span class="mord mathnormal">rc</span><span class="mord mathnormal">h</span><span class="mord">64</span><span class="mspace" style="margin-right:0.2222222222222222em;"></span><span class="mbin">−</span><span class="mspace" style="margin-right:0.2222222222222222em;"></span></span><span class="base"><span class="strut" style="height:0.77777em;vertical-align:-0.08333em;"></span><span class="mord mathnormal" style="margin-right:0.01968em;">l</span><span class="mord mathnormal">in</span><span class="mord mathnormal">ux</span><span class="mspace" style="margin-right:0.2222222222222222em;"></span><span class="mbin">−</span><span class="mspace" style="margin-right:0.2222222222222222em;"></span></span><span class="base"><span class="strut" style="height:0.77777em;vertical-align:-0.08333em;"></span><span class="mord mathnormal">an</span><span class="mord mathnormal">d</span><span class="mord mathnormal">ro</span><span class="mord mathnormal">i</span><span class="mord mathnormal">d</span><span class="mspace" style="margin-right:0.2222222222222222em;"></span><span class="mbin">−</span><span class="mspace" style="margin-right:0.2222222222222222em;"></span></span><span class="base"><span class="strut" style="height:0.69444em;vertical-align:0em;"></span><span class="mord mathnormal" style="margin-right:0.01968em;">l</span><span class="mord mathnormal">d</span><span class="mord">"</span></span></span></span> export RANLIB="<span class="katex"><span class="katex-html" aria-hidden="true"><span class="base"><span class="strut" style="height:1em;vertical-align:-0.25em;"></span><span class="mord"><span class="mord mathnormal" style="margin-right:0.02778em;">TOO</span><span class="mord mathnormal">L</span><span class="mord mathnormal" style="margin-right:0.07153em;">C</span><span class="mord mathnormal" style="margin-right:0.08125em;">H</span><span class="mord mathnormal">A</span><span class="mord mathnormal" style="margin-right:0.07847em;">I</span><span class="mord mathnormal" style="margin-right:0.10903em;">N</span></span><span class="mord">/</span><span class="mord mathnormal">bin</span><span class="mord">/</span><span class="mord mathnormal">aa</span><span class="mord mathnormal">rc</span><span class="mord mathnormal">h</span><span class="mord">64</span><span class="mspace" style="margin-right:0.2222222222222222em;"></span><span class="mbin">−</span><span class="mspace" style="margin-right:0.2222222222222222em;"></span></span><span class="base"><span class="strut" style="height:0.77777em;vertical-align:-0.08333em;"></span><span class="mord mathnormal" style="margin-right:0.01968em;">l</span><span class="mord mathnormal">in</span><span class="mord mathnormal">ux</span><span class="mspace" style="margin-right:0.2222222222222222em;"></span><span class="mbin">−</span><span class="mspace" style="margin-right:0.2222222222222222em;"></span></span><span class="base"><span class="strut" style="height:0.77777em;vertical-align:-0.08333em;"></span><span class="mord mathnormal">an</span><span class="mord mathnormal">d</span><span class="mord mathnormal">ro</span><span class="mord mathnormal">i</span><span class="mord mathnormal">d</span><span class="mspace" style="margin-right:0.2222222222222222em;"></span><span class="mbin">−</span><span class="mspace" style="margin-right:0.2222222222222222em;"></span></span><span class="base"><span class="strut" style="height:0.69444em;vertical-align:0em;"></span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal">an</span><span class="mord mathnormal" style="margin-right:0.01968em;">l</span><span class="mord mathnormal">ib</span><span class="mord">"</span></span></span></span> export STRIP="<span class="katex"><span class="katex-html" aria-hidden="true"><span class="base"><span class="strut" style="height:1em;vertical-align:-0.25em;"></span><span class="mord"><span class="mord mathnormal" style="margin-right:0.02778em;">TOO</span><span class="mord mathnormal">L</span><span class="mord mathnormal" style="margin-right:0.07153em;">C</span><span class="mord mathnormal" style="margin-right:0.08125em;">H</span><span class="mord mathnormal">A</span><span class="mord mathnormal" style="margin-right:0.07847em;">I</span><span class="mord mathnormal" style="margin-right:0.10903em;">N</span></span><span class="mord">/</span><span class="mord mathnormal">bin</span><span class="mord">/</span><span class="mord mathnormal">aa</span><span class="mord mathnormal">rc</span><span class="mord mathnormal">h</span><span class="mord">64</span><span class="mspace" style="margin-right:0.2222222222222222em;"></span><span class="mbin">−</span><span class="mspace" style="margin-right:0.2222222222222222em;"></span></span><span class="base"><span class="strut" style="height:0.77777em;vertical-align:-0.08333em;"></span><span class="mord mathnormal" style="margin-right:0.01968em;">l</span><span class="mord mathnormal">in</span><span class="mord mathnormal">ux</span><span class="mspace" style="margin-right:0.2222222222222222em;"></span><span class="mbin">−</span><span class="mspace" style="margin-right:0.2222222222222222em;"></span></span><span class="base"><span class="strut" style="height:0.77777em;vertical-align:-0.08333em;"></span><span class="mord mathnormal">an</span><span class="mord mathnormal">d</span><span class="mord mathnormal">ro</span><span class="mord mathnormal">i</span><span class="mord mathnormal">d</span><span class="mspace" style="margin-right:0.2222222222222222em;"></span><span class="mbin">−</span><span class="mspace" style="margin-right:0.2222222222222222em;"></span></span><span class="base"><span class="strut" style="height:0.8888799999999999em;vertical-align:-0.19444em;"></span><span class="mord mathnormal">s</span><span class="mord mathnormal">t</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal">i</span><span class="mord mathnormal">p</span><span class="mord">"</span></span></span></span> ./configure --host=aarch64-linux-android --with-pic
<span class="katex"><span class="katex-html" aria-hidden="true"><span class="base"><span class="strut" style="height:0.77777em;vertical-align:-0.08333em;"></span><span class="mord mathnormal" style="margin-right:0.03148em;">mak</span><span class="mord mathnormal">e</span><span class="mspace" style="margin-right:0.2222222222222222em;"></span><span class="mbin">−</span><span class="mspace" style="margin-right:0.2222222222222222em;"></span></span><span class="base"><span class="strut" style="height:0.85396em;vertical-align:-0.19444em;"></span><span class="mord mathnormal" style="margin-right:0.05724em;">j</span></span></span></span>(nproc)
Pick me up, Scotty
使用上述方法,成功构建了 SQLite,生成了libsqlite3.so。现在只需要知道如何让 Cargo 使用它即可。在浏览 Cargo Book 时,我遇到了讲述环境变量的一个章节,它提及了RUSTFLAGS。和 Make 或 CMake 对待CFLAGS和CXXFLAGS一样,RUSTFLAGS的内容被 Cargo 传递给rustc编译器,允许它影响编译器的行为。
尽管这种方式十分简单,但是对我来说不是很优雅,因此我进一步深入研究了其他选项。继续浏览 Cargo Book,我遇到了描述项目配置的章节,可以肯定的是,有一种方法可以指定 RUSTFLAGS。然而,无论我如何尝试,我始终都会收到来自 Cargo 的提示,告诉我关于未使用的 manifest 键的信息。
warning: unused manifest key: target.aarch64-linux-android.rustflags
浏览 Cargo Book 的更多章节,我遇到了关于构建脚本的章节。它们毫无疑问是一个强大的工具,但是我已经花费了很多时间摸索 (fumble) 学习 Cargo 的配置,不想再花更多的时间阅读关于如何编写构建脚本的内容,因此,最终我选择了环境变量的解决方案,并且可能会在之后尝试使用构建脚本的方式(不可能)。
我在终端中输入命令,并焦急的观察它的执行过程。
<span class="katex"><span class="katex-html" aria-hidden="true"><span class="base"><span class="strut" style="height:0.68333em;vertical-align:0em;"></span><span class="mord mathnormal" style="margin-right:0.00773em;">R</span><span class="mord mathnormal" style="margin-right:0.10903em;">U</span><span class="mord mathnormal" style="margin-right:0.13889em;">STF</span><span class="mord mathnormal">L</span><span class="mord mathnormal">A</span><span class="mord mathnormal" style="margin-right:0.05764em;">GS</span><span class="mspace" style="margin-right:0.2777777777777778em;"></span><span class="mrel">=</span><span class="mspace" style="margin-right:0.2777777777777778em;"></span></span><span class="base"><span class="strut" style="height:0.77777em;vertical-align:-0.08333em;"></span><span class="mord">"</span><span class="mspace" style="margin-right:0.2222222222222222em;"></span><span class="mbin">−</span><span class="mspace" style="margin-right:0.2222222222222222em;"></span></span><span class="base"><span class="strut" style="height:0.68333em;vertical-align:0em;"></span><span class="mord mathnormal">L</span></span></span></span>(pwd)/sqlite-autoconf-3340000/.libs/" cargo apk build --target aarch64-linux-android
再一次,它。。。在某种程度上成功了。虽然链接器不再将错误解释成缺失库,但是cargo-apk无法找到该链接器并将其添加到最终的 APK 文件中。
'lib/arm64-v8a/libstartup.so'...
Shared library "libsqlite3.so" not found.
Verifying alignment of target/debug/apk/statup.apk (4)...
49 AndroidManifest.xml (OK - compressed)
997 lib/arm64-v8a/libstartup.so (OK - compressed)
Verification succesful
当我还没有编译libsqlite3.so时,我返回上一步仔细阅读了链接器产生的错误信息。链接器组合了很多的目标文件,这些目标文件都位于target/aarch64-linux-android/debug/deps目录下。如果我将.so文件放在这里会发生什么?
<span class="katex"><span class="katex-html" aria-hidden="true"><span class="base"><span class="strut" style="height:0.8888799999999999em;vertical-align:-0.19444em;"></span><span class="mord mathnormal">c</span><span class="mord mathnormal">p</span><span class="mord mathnormal">s</span><span class="mord mathnormal" style="margin-right:0.01968em;">ql</span><span class="mord mathnormal">i</span><span class="mord mathnormal">t</span><span class="mord mathnormal">e</span><span class="mspace" style="margin-right:0.2222222222222222em;"></span><span class="mbin">−</span><span class="mspace" style="margin-right:0.2222222222222222em;"></span></span><span class="base"><span class="strut" style="height:0.8888799999999999em;vertical-align:-0.19444em;"></span><span class="mord mathnormal">a</span><span class="mord mathnormal">u</span><span class="mord mathnormal">t</span><span class="mord mathnormal">oco</span><span class="mord mathnormal">n</span><span class="mord mathnormal" style="margin-right:0.10764em;">f</span><span class="mspace" style="margin-right:0.2222222222222222em;"></span><span class="mbin">−</span><span class="mspace" style="margin-right:0.2222222222222222em;"></span></span><span class="base"><span class="strut" style="height:1em;vertical-align:-0.25em;"></span><span class="mord">3340000/.</span><span class="mord mathnormal" style="margin-right:0.01968em;">l</span><span class="mord mathnormal">ib</span><span class="mord mathnormal">s</span><span class="mord">/</span><span class="mord mathnormal">s</span><span class="mord mathnormal" style="margin-right:0.01968em;">ql</span><span class="mord mathnormal">i</span><span class="mord mathnormal">t</span><span class="mord mathnormal">e</span><span class="mord">3.</span><span class="mord mathnormal">so</span><span class="mord mathnormal">t</span><span class="mord mathnormal">a</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal" style="margin-right:0.03588em;">g</span><span class="mord mathnormal">e</span><span class="mord mathnormal">t</span><span class="mord">/</span><span class="mord mathnormal">aa</span><span class="mord mathnormal">rc</span><span class="mord mathnormal">h</span><span class="mord">64</span><span class="mspace" style="margin-right:0.2222222222222222em;"></span><span class="mbin">−</span><span class="mspace" style="margin-right:0.2222222222222222em;"></span></span><span class="base"><span class="strut" style="height:0.77777em;vertical-align:-0.08333em;"></span><span class="mord mathnormal" style="margin-right:0.01968em;">l</span><span class="mord mathnormal">in</span><span class="mord mathnormal">ux</span><span class="mspace" style="margin-right:0.2222222222222222em;"></span><span class="mbin">−</span><span class="mspace" style="margin-right:0.2222222222222222em;"></span></span><span class="base"><span class="strut" style="height:1em;vertical-align:-0.25em;"></span><span class="mord mathnormal">an</span><span class="mord mathnormal">d</span><span class="mord mathnormal">ro</span><span class="mord mathnormal">i</span><span class="mord mathnormal">d</span><span class="mord">/</span><span class="mord mathnormal">d</span><span class="mord mathnormal">e</span><span class="mord mathnormal">b</span><span class="mord mathnormal" style="margin-right:0.03588em;">ug</span><span class="mord">/</span><span class="mord mathnormal">d</span><span class="mord mathnormal">e</span><span class="mord mathnormal">p</span><span class="mord mathnormal">s</span></span></span></span> cargo apk build --target aarch64-linux-android
让我惊讶的是,它成功了!
'lib/arm64-v8a/libstartup.so'...
'lib/arm64-v8a/libsqlite3.so'...
Verifying alignment of target/debug/apk/startup.apk (4)...
49 AndroidManifest.xml (OK - compressed)
997 lib/arm64-v8a/libstatup.so (OK - compressed)
15881608 lib/arm64-v8a/libsqlite3.so (OK - compressed)
Verification succesful
我现在有了一个可以安装在 Android 手机上的.apk文件。真是个巨大的成功!
应用 和 Activity
将 Rust 代码编译进.apk中后,我们剩下要做的就是要搞清楚如何将 Rust 代码与编写 UI 的 Java 代码合并。我天真的在 DuckDuckGo 中输入“如何组合 APK”。在阅读顶层几个结果后,明白了这明显是不可能的,至少在对 Android 应用的工作原理没有更深的了解的情况下是不可能的。但是,并不是说没有其他的方法,因为文章提出了另一种方法 - 将 Activity 组合到一个应用程序里。
如果你像我一样,之前从未开发过 Android,可能会疑惑“什么是 Activity”:当你设计一个应用时,它就是所谓的“界面”或者“视图”。例如,在购物应用中:
- 登陆页面是一个 Activity
- 产品搜索页面是一个 Activity
- 所选产品的详情页面是一个 Activity
- 购物车页面是一个 Activity
- 结账页面是一个 Activity
这里的每个页面可能都包含一些交互元素,如无处不在的汉堡包菜单。如果你愿意,从理论上来讲,你可以将整个应用程序放在一个单独的 Activity 中,但是开发难度比较大。当然,关于 Activity 还有很多内容可以介绍,但是目前和我们要讲的内容关系不大。
让我们继续介绍有关 Rust 的内容。虽然我的问题的解决方案是将 Activity 组合到一个应用程序中,但是我不确定用 Rust 构建的.apk文件是如何与所有这些联系在一起的。在仔细研究了 cargo-apk 代码之后,我意识到它本质是将我的代码封装进一些胶水 (glue) 代码中,并为 Android 的运行创建 NativeActivity。
为了将 Activity 组合进一个应用中,我需要修改 (tinker with) 应用程序的AndroidManifest.xml文件,在文档中添加合适的 Activity 节点。但是我应该如何知道cargo-apk生成的 NativeActivity 的属性呢?幸运的是,当cargo-apk工作时,它会生成一个最小版的AndroidManifest.xml文件,并将其放在生成的.apk旁边。其中 NativeActivity 的声明如下所示:
<activity
android:name="android.app.NativeActivity"
android:label="startup"
android:screenOrientation="portrait"
android:launchMode="standard"
android:configChanges="orientation|keyboardHidden|screenSize">
<meta-data android:name="android.app.lib_name" android:value="startup" />
<intent-filter>
<action android:name="android.intent.action.MAIN" />
<category android:name="android.intent.category.LAUNCHER" />
</intent-filter>
</activity>
我要做的就是将上面的代码片段复制并粘贴到 Java 应用程序的 manifest 中。
当然,这只是在应用的 manifest 中添加了一条语句,告诉应用将要包含哪些 Activity。Java 应用程序的构建过程不会知道libstartup.so文件的位置,并自动的将其包含在内。幸运的是,我只需要将库文件复制到指定的文件夹下即可,Gradle (Android 应用的构建工具) 会自动将它们采集起来。
<span class="katex"><span class="katex-html" aria-hidden="true"><span class="base"><span class="strut" style="height:0.77777em;vertical-align:-0.08333em;"></span><span class="mord mathnormal" style="margin-right:0.03148em;">mk</span><span class="mord mathnormal">d</span><span class="mord mathnormal">i</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mspace" style="margin-right:0.2222222222222222em;"></span><span class="mbin">−</span><span class="mspace" style="margin-right:0.2222222222222222em;"></span></span><span class="base"><span class="strut" style="height:1em;vertical-align:-0.25em;"></span><span class="mord mathnormal">p</span><span class="mord mathnormal">an</span><span class="mord mathnormal">d</span><span class="mord mathnormal">ro</span><span class="mord mathnormal">i</span><span class="mord mathnormal">d</span><span class="mord">/</span><span class="mord mathnormal">a</span><span class="mord mathnormal">pp</span><span class="mord">/</span><span class="mord mathnormal">src</span><span class="mord">/</span><span class="mord mathnormal">main</span><span class="mord">/</span><span class="mord mathnormal">jni</span><span class="mord mathnormal">L</span><span class="mord mathnormal">ib</span><span class="mord mathnormal">s</span><span class="mord">/</span><span class="mord mathnormal">a</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal">m</span><span class="mord">64</span><span class="mspace" style="margin-right:0.2222222222222222em;"></span><span class="mbin">−</span><span class="mspace" style="margin-right:0.2222222222222222em;"></span></span><span class="base"><span class="strut" style="height:0.64444em;vertical-align:0em;"></span><span class="mord mathnormal" style="margin-right:0.03588em;">v</span><span class="mord">8</span><span class="mord mathnormal">a</span></span></span></span> cp sqlite-autoconf-3340000/.libs/libsqlite3.so android/app/src/main/jniLibs/arm64-v8a/
<span class="katex"><span class="katex-html" aria-hidden="true"><span class="base"><span class="strut" style="height:1em;vertical-align:-0.25em;"></span><span class="mord mathnormal">c</span><span class="mord mathnormal">pt</span><span class="mord mathnormal">a</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal" style="margin-right:0.03588em;">g</span><span class="mord mathnormal">e</span><span class="mord mathnormal">t</span><span class="mord">/</span><span class="mord mathnormal">aa</span><span class="mord mathnormal">rc</span><span class="mord mathnormal">h</span><span class="mord">64</span><span class="mspace" style="margin-right:0.2222222222222222em;"></span><span class="mbin">−</span><span class="mspace" style="margin-right:0.2222222222222222em;"></span></span><span class="base"><span class="strut" style="height:0.77777em;vertical-align:-0.08333em;"></span><span class="mord mathnormal" style="margin-right:0.01968em;">l</span><span class="mord mathnormal">in</span><span class="mord mathnormal">ux</span><span class="mspace" style="margin-right:0.2222222222222222em;"></span><span class="mbin">−</span><span class="mspace" style="margin-right:0.2222222222222222em;"></span></span><span class="base"><span class="strut" style="height:1em;vertical-align:-0.25em;"></span><span class="mord mathnormal">an</span><span class="mord mathnormal">d</span><span class="mord mathnormal">ro</span><span class="mord mathnormal">i</span><span class="mord mathnormal">d</span><span class="mord">/</span><span class="mord mathnormal">d</span><span class="mord mathnormal">e</span><span class="mord mathnormal">b</span><span class="mord mathnormal" style="margin-right:0.03588em;">ug</span><span class="mord">/</span><span class="mord mathnormal" style="margin-right:0.01968em;">l</span><span class="mord mathnormal">ib</span><span class="mord mathnormal">s</span><span class="mord mathnormal">t</span><span class="mord mathnormal">a</span><span class="mord mathnormal">t</span><span class="mord mathnormal">u</span><span class="mord mathnormal">p</span><span class="mord">.</span><span class="mord mathnormal">so</span><span class="mord mathnormal">an</span><span class="mord mathnormal">d</span><span class="mord mathnormal">ro</span><span class="mord mathnormal">i</span><span class="mord mathnormal">d</span><span class="mord">/</span><span class="mord mathnormal">a</span><span class="mord mathnormal">pp</span><span class="mord">/</span><span class="mord mathnormal">src</span><span class="mord">/</span><span class="mord mathnormal">main</span><span class="mord">/</span><span class="mord mathnormal">jni</span><span class="mord mathnormal">L</span><span class="mord mathnormal">ib</span><span class="mord mathnormal">s</span><span class="mord">/</span><span class="mord mathnormal">a</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal">m</span><span class="mord">64</span><span class="mspace" style="margin-right:0.2222222222222222em;"></span><span class="mbin">−</span><span class="mspace" style="margin-right:0.2222222222222222em;"></span></span><span class="base"><span class="strut" style="height:1em;vertical-align:-0.25em;"></span><span class="mord mathnormal" style="margin-right:0.03588em;">v</span><span class="mord">8</span><span class="mord mathnormal">a</span><span class="mord">/</span></span></span></span> cd android/ && ./gradlew && ./gradlew build
这些都完成后,我启动了构建,它成功了!我将.apk安装在我闲置的 (laying around) Android 设备中,但是...好像有哪里不太对劲呢!

我的应用一旦安装成功后,会在应用的启动界面产生两个快捷方式。其中一个启动 Java 的 UI 界面,而另一个启动包含 Rust 代码的 NativeActivity。在阅读了更多关于 Activity 和 AndroidManifest 的内容后,我了解到,造成此问题的部分是 NativeActivity 的
但是,仍然存在一个问题:我如何让 Java 的 Activity 要求 Rust 的Activity 为其工作?
恶意的 (Malicious) Intent
Android 中的 Activity 可以毫无问题的相互启动 - 如果这不可能,则无法真正在两者之间传递用户信息。调用另一个 Activity 的标准方法是通过 startActivity() 方法,该方法接收一个参数:Intent 类实例。
尽管 Intent 类的名称是不言而喻的 (self-explanatory),但是起初它的用法可能有点不直观。在它最基本的形式中,它仅包含对调用 Activity 实例的引用,以及我们要调用的 Activity 的类句柄。(确切的说,一个 Intent 需要调用一个 Context。Activity 只是 Context 的一种类型)。
但是,Intent 也可以用于传达为什么一个 Activity 会调用另一个 Activity 的信息(例如 action),可以用来区分例如“显示某些内容”和“编辑某些内容”;或要操作的数据 URI 及其 MIME 类型。除了 get/set 方法,Intent 还可以容纳几乎任何数量的“额外”数据,这些数据通常作为键值对存储。
Intent 提供了一种在 Activity 之间传递信息的标准化方式。调用者向被调用者提供处理其请求所需的一切信息,并且它可以接收包含所有请求信息的另一个 Intent 作为返回值。使用 Java 编写代码时,没有什么问题,但是,将 Rust 代码放入 NativeActivity 会发生什么?
如果你查看继承树,你可以看到 NativeActivity 继承了 Activity - 这意味着它可以访问 Activity 所有非私有方法。我可以调用getIntent()并从调用者中获取数据。除此之外,由于这是 Java 方法,并且我是在 native 代码中运行,因此需要使用 JNI (Java Native Interface) 执行函数调用。不幸的是,NativeActivity 没有任何其他的机制来传递信息或使用 Intent。这让我十分沮丧 (dismay),因为这意味着我必须要与 JNI 一起工作。
JNI 之旅
在这一点上,我花了太多时间却没有取得明显的 (tangible) 成果,这让我感到十分沮丧。另一方面,我意识到使用 JNI 带来了一些新的可能 - 不必使用 Activity 和 Intent,我可以将代码粘贴在函数中,并通过调用参数和返回值进行通信。有了这个新思路,我开始了对 JNI 的研究。
因为在 Java 中,万物皆对象,并且代码不能存在于类之外的部分 - native 代码也必须是类的一部分。因为我不需要持久化,因此简单的使用静态方法就很有用。
package com.startup.hip;
public class RustCode {
public static native void doStuff();
}
上面是一个 Java 类的最小示例,其中带有一个标记为native的静态方法。有了这个,我需要实现相应的功能。但是我应该如何正确的使用函数签名呢?
幸运的是,Java 具有为 JNI 生成 C 语言头文件的功能。在 Java SE9 之前,它是一个独立的工具 - javah;后来,它作为-h选项合并到了主要的javac编译器可执行文件中。该选项需要一个目录参数,用来放置生成的.h文件。用法十分简单。
javac -h ./ RustCode.java
调用上面的命令将创建一个com_startup_hip_RustCode.h文件,其中包含函数定义。
#include <jni.h>
JNIEXPORT void JNICALL Java_com_startup_hip_RustCode_doStuff(JNIEnv *, jclass);
有了这些知识,我就可以继续在 Rust 中创建适当的函数了。
C++ 闪回
当处理外部代码时,Rust 和 C 很像,主要是使用 extern 块。此外,与 C++ 一样,Rust 可以使用 name mangling - 这不足为奇,因为这门语言对范型和宏提供了强大的支持。幸运的是,Rust 提供了一种简单的方式来禁用 name mangling - 使用 #[no mangle] 注解。
#![allow(unused)] fn main() { use jni::{objects::JClass, JNIEnv}; #[no_mangle] pub extern "C" fn Java_com_startup_hip_RustCode_doStuff( _env: JNIEnv, _class: JClass, ) {} }
创建了函数声明之后,接下来我需要编写对应的实现。
接收参数
通常,native 函数需要接收一些参数。在本例中,它是一个包含代码的字符串,该代码随后将被传递给服务端。
package com.startup.hip;
public class RustCode {
public static native void doStuff(String code);
}
修改 Java 代码之后,我重新生成了 C 语言的头文件并据此编辑了 Rust 代码。
#![allow(unused)] fn main() { use jni::{objects::JClass, JNIEnv}; #[no_mangle] pub extern "C" fn Java_com_startup_hip_RustCode_doStuff( _env: JNIEnv, _class: JClass, code: JString, ) {} }
这很简单。现在我需要从 Java 字符串中提取文本并将其传递给 Rust 代码。这比我预期 (anticipate) 要复杂的多。问题在于,JVM 内部使用 UTF-8 的修改版本存储字符串,而 Rust 字符串必须是有效的 UTF-8。尽管 Rust 具有用于处理任意字符串的类型,但是我们的代码仅使用“经典”的字符串类型,对其进行全部修改需要大量工作。
幸运的是,jni库带有内置的机制,可以通过特殊的 JNIStr 类型在标准 UTF-8 和 JVM 修改后的 UTF-8 之间进行转换。在仔细阅读了文档之后,我想到了以下代码:
#![allow(unused)] fn main() { // Convert from JString – a thinly wrapped JObject – to a JavaStr let code_jvm = env.get_string(code).unwrap(); // Create a String from JavaStr, causing text conversion let code_rust = String::from(code_jvm); }
现在我有了一个 Rust 字符串,可以将其传递给之后的 Rust 代码。又是个巨大的成功!
返回值
接收参数只是故事的一半,我还需要一个返回值,巧的是,它也是一个字符串 - 一个代表服务端返回值的字符串。
package com.startup.hip;
public class RustCode {
public static native String doStuff(String code);
}
我再一次修改了 Java 代码,重新生成了 C 语言的头文件,并据此编辑 Rust 代码。
use jni::{objects::JClass, JNIEnv};
#[no_mangle]
pub extern "C" fn Java_com_startup_hip_RustCode_doStuff<'a>(
env: JNIEnv<'a>,
_class: JClass,
code: JString,
) -> JString<'a>
{
// function body here
}
如你所见,JNI 中的返回值仍然作为返回值处理。剩下要做的事就是创建保存结果的 JString。与get_string()类似,JNIEnv结构还包含一个new_string()函数,该函数的功能与名称指代的完全相同。
#![allow(unused)] fn main() { // Copy-pasted from earlier snippet let code_rust = String::from(env.get_string(code_jni).unwrap()); let result = match some_rust_function(code_rust) { Ok(value) => format!("OK {}", value), Err(e) => format!("ER {:?}", e), }; return env.new_string(result).unwrap(); }
就像这样,我的 JNI 封装器就完成了。现在,我可以在 Java 代码中调用 Rust 函数,将值传递给调用并接收返回值。
Rust 的错误处理
尽管代码如预期一样执行,但是我不喜欢出现的.unwrap()调用次数。毕竟,错误处理是 Rust 的重要组成部分,仅仅因为我正在进行语言的互操作,并不意味着就可以忽略此事。恰恰相反,我认为两种语言的接触面应该尽可能简单,以防止最终发现一些晦涩的错误是由于互操作性差而引起的。而且,必须检查 Java 的返回值以确定调用是否成功,这使得整个过程使用起来有些笨拙 (clunky)。
我没有重复造轮子,而是对如何更好的将 Rust 的 Result<A, B> 方式转换成 Java 侧的代码进行了思考。幸运的是,我的 Rust 函数的返回值都是字符串。至于错误,大多数错误要么是不可恢复的,要么是由错误的输入引起的 - 这意味着我可以放弃 (forego) 使用精确的错误代码,而仅仅依靠正确格式的错误信息 - 这又是指字符串。因此Result<A, B>可以变成Result<String, String>。
定义 Java 类
尽管 Java 支持范型(虽然有点欺骗的感觉),但是我不想从 JNI 中深入了解使用范型的细节。我决定创建一个 Java 类,大致表示Result<String, String>语义。
public class Result {
private boolean ok;
private String value;
public Result(boolean is_ok, String value) {
this.ok = is_ok;
this.value = value;
}
public boolean isOk() {
return this.ok;
}
public boolean isError() {
return !this.ok;
}
public String getValue() {
return this.ok ? this.value : null;
}
public String getError() {
return this.ok ? null : this.value;
}
}
尽管完成了这项工作,但与 Rust 相比,它有一些缺点 - 最严重的就是当访问错误的结果变量时返回null。由于 null 对于 Java 字符串来说是一个没有问题的值,因此调用getValue()可能没有注意并将其传递给其他地方导致在无关紧要的代码中弹出 NullPointerException。尽管可以通过抛出异常来轻松地改善这个问题,我仍决定使用最好的方式来处理这个问题,以便此处以后永远也不需要添加新的内容。
从 JNI 中返回一个对象
剩下的唯一一件事就是从 Rust 函数中返回 Result 类的实例。经过一番搜索后,我找到了名为 NewObject() 的 JNI 函数。该函数有四个参数:
- JNI 环境的句柄
- 我们想要创建的类的句柄
- 构造函数签名
- 构造函数的参数
Rust 函数将 JNI 环境句柄作为其参数之一,因此已经进行了处理。构造函数参数可以作为数组传递,我需要找到另外两个函数参数。
为了获取该函数的句柄,JNI 提供了FindClass()函数。它有两个参数:环境句柄和类的完全限定名 - 简单的说就是类的“导入名”,但是.用/代替。例如java.lang.String变成java/lang/String。在本例中是指,com.startup.hip.Result变成com/startup/hip/Result。
构造函数签名是一个字符串,它很好的描述了构造函数签名需要多少个参数以及哪些类型。乍一看,这让人有些困惑 - 但后来我想起 Java 支持函数重载,并且还包括构造函数。由于一个类可能有多个构造函数,所以我必须让 JNI 知道我想使用哪个构造函数。在互联网上搜索了之后,我发现最简单的学习函数签名的方法就是编译 Java 类。然后使用 Java 的反汇编工具:javap。
javac android/app/src/main/java/com/startup/hip/Result.java
javap -s android/app/src/main/java/com/startup/hip/Result.class
Compiled from "Result.java"
public class com.startup.hip.Result {
public com.startup.hip.Result(boolean, java.lang.String);
descriptor: (ZLjava/lang/String;)V
public boolean isOk();
descriptor: ()Z
public boolean isError();
descriptor: ()Z
public java.lang.String getValue();
descriptor: ()Ljava/lang/String;
public java.lang.String getError();
descriptor: ()Ljava/lang/String;
}
执行了上述的命令,现在我知道了我想要使用的函数签名是(ZLjava/lang/String;)V。
在所有步骤都准备就绪之后,是时候创建持有构造函数参数的数组,并调用NewObject()。
#![allow(unused)] fn main() { fn create_java_result<'e>( env: &JNIEnv<'e>, is_ok: bool, value: &str, ) -> JObject<'e> { let class = env .find_class("com/startup/hip/Result") .unwrap(); let args: [JValue<'e>; 2] = [ JValue::Bool(u8::from(is_ok)), JValue::Object(JObject::from(env.new_string(value).unwrap())), ]; env.new_object(class, "(ZLjava/lang/String;)V", &args) .unwrap() } }
现在,我可以从 native 函数中返回自定义的Result Java 类了。
使用更通用的解决方案
尽管上面的代码可以很好的实现这个目的,但是它有一个缺点:它显示地采用了布尔值和字符串,要求调用者自己处理 Result 并使用适当的参数调用函数。编写“错误应该尽早返回”的逻辑很繁琐 (tedious),但是幸运的是,Rust 为此提供了一个解决方案 - ? 运算符。但是我们的代码从不同的库中调用函数,这些函数又使用了不同的错误类型 - 这意味着我们无法使用Result<OurType, OurError>,并且必须执行类似 (akin) Result<OurType, std::error::Error>的操作 - 这是不可能的,因为 Rust 不允许将特征用作函数的返回类型。
解决此问题的标准方法是使用 Box
#![allow(unused)] fn main() { fn rust_result_to_java_result<'e, T>( env: &JNIEnv<'e>, result: anyhow::Result<T>, ) -> JObject<'e> where T: Display, { let (is_ok, value) = match result { Ok(v) => (true, format!("{}", v)), Err(e) => (false, format!("{:?}", e)), }; create_java_result(env, is_ok, value) } fn actually_do_stuff<'a>( env: JNIEnv<'a>, code: JString, ) -> anyhow::Result<String> { let code = String::from(env.get_string(code)?); let intermediate_value = some_rust_function(code)?; other_rust_function(intermediate_value) } #[no_mangle] pub extern "C" fn Java_com_startup_hip_RustCode_doStuff<'a>( env: JNIEnv<'a>, _class: JClass, code: JString, ) -> JObject<'a> { rust_result_to_java_result(actually_do_stuff(env, code)) } }
更简单了!现在我可以返回任何想要的结果,并将其转换为 Java 类的实例,以供 Java 代码使用。
封装
在 Android 中运行 Rust 并不是一件容易的事,但是我对最终找到的解决方案感到满意。我们使用及其普通 (bog-standard) 的 Rust 编写代码并将其编译到共享库中,然后由 JVM 在运行时加载。尽管 JNI 乍一看有点令人生畏 (intimidate),但是使用此标准化解决方案意味着 Java 代码和 Gradle 构建系统都不关心我们的 native 代码是用 Rust 编写的。使用 Cargo 进行交叉编译仍然有些棘手 (tricky),因为事实证明cargo-apk设置了许多环境变量以使整个过程正常运行。我们的代码还依赖于外部库 - 但是所有的这些都可以通过一堆 shell 脚本来解决。
如果你想要自己尝试一下,我已经准备了一个公共 Github 仓库,其中包含了一个最小的 Android 应用程序,既包含用 Rust 编写的部分,还依赖于外部的 C 库。该项目的许可证是 zlib。因此可以随意的获取源代码并将其用于你的个人目的。
参考
- Android NDK documentation: other build systems: Autoconf
- crates.io: cargo-apk
- cargo-apk: ndk-glue/src/lib.rs
- cargo-apk: nkd-build/src/cargo.rs
- Android developer documentation: app manifest:
- Android developer documentation: Activity
- Android developer documentation: NativeActivity
- Android developer documentation: Intent
- crates.io: jni
- Java SE 11: JNI specification
- Java SE 9: tools: javah
- The Rust Programming Language: Calling Rust Functions from Other Languages
- Java SE 11: tools: javap
- Thorn Technologies: Using JNI to call C functions from Android Java
- Code Ranch: How to create new objects with JNI
- Stack Overflow: Java signature for method
Rust 中常见的有关生命周期的误解
译者:SHJ
目录
引言
我曾经也抱有上述的这些误解,并且现在仍有许多初学者深陷其中。本文中我使用的术语可能并不那么官方,因此下面列出了一个表格,记录我使用的短语及其想表达的含义。
| 短语 | 意义 |
|---|---|
T | 1) 所有可能类型的集合 或 2) 上述集合中的某一个具体类型 |
| 所有权类型 | 某些非引用类型,其自身拥有所有权 例如 i32, String, Vec 等等 |
| 1) 借用类型 或 2) 引用类型 | 引用类型,不考虑可变性 例如 &i32, &mut i32 等等 |
| 1) 可变引用 或 2) 独占引用 | 独占可变引用, 即 &mut T |
| 1) 不可变引用 或 2) 共享引用 | 可共享不可变引用, 即 &T |
误解
简单来讲,一个变量的生命周期是指一段时期,在这段时期内,该变量所指向的内存地址中的数据是有效的,这段时期是由编译器静态分析得出的,有效性由编译器保证。接下来我将探讨这些常见误解的细节。
1) T 只包含所有权类型
这更像是对泛型的误解而非对生命周期的误解,但在 Rust 中,泛型与生命周期的关系是如此紧密,以至于不可能只讨论其中一个而忽视另外一个。
当我刚开始学习 Rust 时,我知道 i32, &i32, 和 &mut i32 是不同的类型,同时我也知泛型 T 表示所有可能类型的集合。然而,尽管能分别理解这两个概念,但我却没能将二者结合起来。在当时我这位 Rust 初学者的眼里,泛型是这样运作的:
| 类型 | T | &T | &mut T |
| 例子 | i32 | &i32 | &mut i32 |
其中 T 包全体所有权类型;&T 包括全体不可变引用;&mut T 包括全体可变引用;T, &T, 和 &mut T 是不相交的有限集。简洁明了,符合直觉,却完全错误。事实上泛型是这样运作的:
| 类型 | T | &T | &mut T |
| 例子 | i32, &i32, &mut i32, &&i32, &mut &mut i32, ... | &i32, &&i32, &&mut i32, ... | &mut i32, &mut &mut i32, &mut &i32, ... |
T, &T, 和 &mut T 都是无限集,因为你可以借用一个类型无限次。T 是 &T 和 &mut T 的超集。&T 和 &mut T 是不相交的集合. 下面有一些例子来验证这些概念:
#![allow(unused)] fn main() { trait Trait {} impl<T> Trait for T {} impl<T> Trait for &T {} // 编译错误 impl<T> Trait for &mut T {} // 编译错误 }
上述代码不能编译通过:
#![allow(unused)] fn main() { error[E0119]: conflicting implementations of trait `Trait` for type `&_`: --> src/lib.rs:5:1 | 3 | impl<T> Trait for T {} | ------------------- first implementation here 4 | 5 | impl<T> Trait for &T {} | ^^^^^^^^^^^^^^^^^^^^ conflicting implementation for `&_` error[E0119]: conflicting implementations of trait `Trait` for type `&mut _`: --> src/lib.rs:7:1 | 3 | impl<T> Trait for T {} | ------------------- first implementation here ... 7 | impl<T> Trait for &mut T {} | ^^^^^^^^^^^^^^^^^^^^^^^^ conflicting implementation for `&mut _` }
编译器不允许我们为 &T 和 &mut T 实现 Trait,因为这与我们为 T 实现的 Trait 发生了冲突,而 T 已经包括了 &T 和 &mut T. 因为 &T 和 &mut T 是不相交的,所以下面的代码可以通过编译:
#![allow(unused)] fn main() { trait Trait {} impl<T> Trait for &T {} // 编译通过 impl<T> Trait for &mut T {} // 编译通过 }
关键点回顾
T是&T和&mut T的超集&T和&mut T是不相交的集合
2) 如果 T: 'static 那么 T 直到程序结束为止都一定是有效的
错误的推论
T: 'static应该视为 “T有着'static生命周期”&'static T和T: 'static是一回事- 若
T: 'static则T一定是不可变的 - 若
T: 'static则T只能在编译期创建
让大多数 Rust 初学者第一次接触 'static 生命周期注解的代码示例大概是这样的:
fn main() { let str_literal: &'static str = "字符串字面量"; }
他们被告知说 "字符串字面量" 是被硬编码到编译出来的二进制文件当中去的,并在运行时被加载到只读内存中,所以它不可变且在程序的整个运行期间都有效,这也使其生命周期为 'static. 在了解到 Rust 使用 static 来定义静态变量这一语法后,这一观点还会被进一步加强。
static BYTES: [u8; 3] = [1, 2, 3]; static mut MUT_BYTES: [u8; 3] = [1, 2, 3]; fn main() { MUT_BYTES[0] = 99; // 编译错误,修改静态变量是 unsafe 的 unsafe { MUT_BYTES[0] = 99; assert_eq!(99, MUT_BYTES[0]); } }
关于静态变量
- 它们只能在编译期创建
- 它们应当是不可变的,修改静态变量是 unsafe 的
- 它们在整个程序运行期间有效
静态变量的默认生命周期很有可能是 'static , 对吧?所以可以合理推测 'static 生命周期也要遵循同样的规则,对吧?
确实,但 带有 'static 生命周期注解的类型和一个被 'static 约束 的类型是不一样的。后者可以于运行时被动态分配,能被安全自由地修改,也可以被 drop, 还能存活任意的时长。
区分 &'static T 和 T: 'static 是非常重要的一点。
&'static T 是一个指向 T 的不可变引用,其中 T 可以被安全地无期限地持有,甚至可以直到程序结束。这只有在 T 自身不可变且保证 在引用创建后 不会被 move 时才有可能。T 并不需要在编译时创建。 我们可以以内存泄漏为代价,在运行时动态创建随机数据,并返回其 'static 引用,比如:
#![allow(unused)] fn main() { use rand; // 在运行时生成随机 &'static str fn rand_str_generator() -> &'static str { let rand_string = rand::random::<u64>().to_string(); Box::leak(rand_string.into_boxed_str()) } }
T: 'static 是指 T 可以被安全地无期限地持有,甚至可以直到程序结束。 T: 'static 在包括了全部 &'static T 的同时,还包括了全部所有权类型, 比如 String, Vec 等等。 数据的所有者保证,只要自身还持有数据的所有权,数据就不会失效,因此所有者能够安全地无期限地持有其数据,甚至可以直到程序结束。T: 'static 应当视为 “T 满足 'static 生命周期约束” 而非 “T 有着 'static 生命周期”。 一个程序可以帮助阐述这些概念:
use rand; fn drop_static<T: 'static>(t: T) { std::mem::drop(t); } fn main() { let mut strings: Vec<String> = Vec::new(); for _ in 0..10 { if rand::random() { // 所有字符串都是随机生成的 // 并且在运行时动态分配 let string = rand::random::<u64>().to_string(); strings.push(string); } } // 这些字符串是所有权类型,所以他们满足 'static 生命周期约束 for mut string in strings { // 这些字符串是可变的 string.push_str("a mutation"); // 这些字符串都可以被 drop drop_static(string); // 编译通过 } // 这些字符串在程序结束之前就已经全部失效了 println!("i am the end of the program"); }
关键点回顾
T: 'static应当视为 “T满足'static生命周期约束”- 若
T: 'static则T可以是一个有'static生命周期的引用类型 或 是一个所有权类型 - 因为
T: 'static包括了所有权类型,所以T- 可以在运行时动态分配
- 不需要在整个程序运行期间都有效
- 可以安全,自由地修改
- 可以在运行时被动态的 drop
- 可以有不同长度的生命周期
3) &'a T 和 T: 'a 是一回事
这个误解是前一个误解的泛化版本。
&'a T 要求并隐含了 T: 'a ,因为如果 T 本身不能在 'a 范围内保证有效,那么其引用也不能在 'a 范围内保证有效。例如,Rust 编译器不会运行构造一个 &'static Ref<'a, T>,因为如果 Ref 只在 'a 范围内有效,我们就不能给它 'static 生命周期。
T: 'a 包括了全体 &'a T,但反之不成立。
// 只接受带有 'a 生命周期注解的引用类型 fn t_ref<'a, T: 'a>(t: &'a T) {} // 接受满足 'a 生命周期约束的任何类型 fn t_bound<'a, T: 'a>(t: T) {} // 内部含有引用的所有权类型 struct Ref<'a, T: 'a>(&'a T); fn main() { let string = String::from("string"); t_bound(&string); // 编译通过 t_bound(Ref(&string)); // 编译通过 t_bound(&Ref(&string)); // 编译通过 t_ref(&string); // 编译通过 t_ref(Ref(&string)); // 编译失败,期望得到引用,实际得到 struct t_ref(&Ref(&string)); // 编译通过 // 满足 'static 约束的字符串变量可以转换为 'a 约束 t_bound(string); // 编译通过 }
关键点回顾
T: 'a比&'a T更泛化,更灵活T: 'a接受所有权类型,内部含有引用的所有权类型,和引用&'a T只接受引用- 若
T: 'static则T: 'a因为对于所有'a都有'static>='a
4) 我的代码里不含泛型也不含生命周期注解
错误的推论
- 避免使用泛型和生命周期注解是可能的
这个让人爽到的误解之所以能存在,要得益于 Rust 的生命周期省略规则,这个规则能允许你在函数定义以及 impl 块中省略掉显式的生命周期注解,而由借用检查器来根据以下规则对生命周期进行隐式推导。
- 第一条规则是每一个是引用的参数都有它自己的生命周期参数
- 第二条规则是如果只有一个输入生命周期参数,那么它被赋予所有输出生命周期参数
- 第三条规则是如果是有多个输入生命周期参数的方法,而其中一个参数是
&self或&mut self, 那么所有输出生命周期参数被赋予self的生命周期。 - 其他情况下,生命周期必须有明确的注解
这里有不少值得讲的东西,让我们来看一些例子:
#![allow(unused)] fn main() { // 展开前 fn print(s: &str); // 展开后 fn print<'a>(s: &'a str); // 展开前 fn trim(s: &str) -> &str; // 展开后 fn trim<'a>(s: &'a str) -> &'a str; // 非法,没有输入,不能确定返回值的生命周期 fn get_str() -> &str; // 显式标注的方案 fn get_str<'a>() -> &'a str; // 泛型版本 fn get_str() -> &'static str; // 'static 版本 // 非法,多个输入,不能确定返回值的生命周期 fn overlap(s: &str, t: &str) -> &str; // 显式标注(但仍有部分标注被省略)的方案 fn overlap<'a>(s: &'a str, t: &str) -> &'a str; // 返回值的生命周期不长于 s fn overlap<'a>(s: &str, t: &'a str) -> &'a str; // 返回值的生命周期不长于 t fn overlap<'a>(s: &'a str, t: &'a str) -> &'a str; // 返回值的生命周期不长于 s 且不长于 t fn overlap(s: &str, t: &str) -> &'static str; // 返回值的生命周期可以长于 s 或者 t fn overlap<'a>(s: &str, t: &str) -> &'a str; // 返回值的生命周期与输入无关 // 展开后 fn overlap<'a, 'b>(s: &'a str, t: &'b str) -> &'a str; fn overlap<'a, 'b>(s: &'a str, t: &'b str) -> &'b str; fn overlap<'a>(s: &'a str, t: &'a str) -> &'a str; fn overlap<'a, 'b>(s: &'a str, t: &'b str) -> &'static str; fn overlap<'a, 'b, 'c>(s: &'a str, t: &'b str) -> &'c str; // 展开前 fn compare(&self, s: &str) -> &str; // 展开后 fn compare<'a, 'b>(&'a self, &'b str) -> &'a str; }
如果你写过
- 结构体方法
- 接收参数中有引用的函数
- 返回值是引用的函数
- 泛型函数
- trait object(后面将讨论)
- 闭包(后面将讨论)
那么对于上面这些,你的代码中都有被省略的泛型生命周期注解。
关键点回顾
- 几乎所有的 Rust 代码都是泛型代码,并且到处都带有被省略掉的泛型生命周期注解
5) 如果编译通过了,那么我标注的生命周期就是正确的
错误的推论
- Rust 对函数的生命周期省略规则总是对的
- Rust 的借用检查器总是正确的,无论是技巧上还是语义上
- Rust 比我更懂我程序的语义
让一个 Rust 程序通过编译但语义上不正确是有可能的。来看看这个例子:
struct ByteIter<'a> { remainder: &'a [u8] } impl<'a> ByteIter<'a> { fn next(&mut self) -> Option<&u8> { if self.remainder.is_empty() { None } else { let byte = &self.remainder[0]; self.remainder = &self.remainder[1..]; Some(byte) } } } fn main() { let mut bytes = ByteIter { remainder: b"1" }; assert_eq!(Some(&b'1'), bytes.next()); assert_eq!(None, bytes.next()); }
ByteIter 是一个 byte 切片上的迭代器,简洁起见,我这里省略了 Iterator trait 的具体实现。这看起来没什么问题,但如果我们想同时检查多个 byte 呢?
fn main() { let mut bytes = ByteIter { remainder: b"1123" }; let byte_1 = bytes.next(); let byte_2 = bytes.next(); if byte_1 == byte_2 { // 一些代码 } }
编译错误:
#![allow(unused)] fn main() { error[E0499]: cannot borrow `bytes` as mutable more than once at a time --> src/main.rs:20:18 | 19 | let byte_1 = bytes.next(); | ----- first mutable borrow occurs here 20 | let byte_2 = bytes.next(); | ^^^^^ second mutable borrow occurs here 21 | if byte_1 == byte_2 { | ------ first borrow later used here }
如果你说可以通过逐 byte 拷贝来避免编译错误,那么确实。当迭代一个 byte 数组上时,我们的确可以通过拷贝每个 byte 来达成目的。但是如果我想要将 ByteIter 改写成一个泛型的切片迭代器,使得我们能够对任意 &'a [T] 进行迭代,而此时如果有一个 T,其 copy 和 clone 的代价十分昂贵,那么我们该怎么避免这种昂贵的操作呢?哦,我想我们不能,毕竟代码都通过编译了,那么生命周期注解肯定也是对的,对吧?
错,事实上现有的生命周期就是 bug 的源头!这个错误的生命周期被省略掉了以至于难以被发现。现在让我们展开这些被省略掉的生命周期来暴露出这个问题。
#![allow(unused)] fn main() { struct ByteIter<'a> { remainder: &'a [u8] } impl<'a> ByteIter<'a> { fn next<'b>(&'b mut self) -> Option<&'b u8> { if self.remainder.is_empty() { None } else { let byte = &self.remainder[0]; self.remainder = &self.remainder[1..]; Some(byte) } } } }
感觉好像没啥用,我还是搞不清楚问题出在哪。这里有个 Rust 专家才知道的小技巧:给你的生命周期注解起一个更有含义的名字,让我们试一下:
#![allow(unused)] fn main() { struct ByteIter<'remainder> { remainder: &'remainder [u8] } impl<'remainder> ByteIter<'remainder> { fn next<'mut_self>(&'mut_self mut self) -> Option<&'mut_self u8> { if self.remainder.is_empty() { None } else { let byte = &self.remainder[0]; self.remainder = &self.remainder[1..]; Some(byte) } } } }
每个返回的 byte 都被标注为 'mut_self, 但是显然这些 byte 都源于 'remainder! 让我们来修复一下这段代码。
struct ByteIter<'remainder> { remainder: &'remainder [u8] } impl<'remainder> ByteIter<'remainder> { fn next(&mut self) -> Option<&'remainder u8> { if self.remainder.is_empty() { None } else { let byte = &self.remainder[0]; self.remainder = &self.remainder[1..]; Some(byte) } } } fn main() { let mut bytes = ByteIter { remainder: b"1123" }; let byte_1 = bytes.next(); let byte_2 = bytes.next(); std::mem::drop(bytes); // 我们现在甚至可以把这个迭代器给 drop 掉! if byte_1 == byte_2 { // 编译通过 // 一些代码 } }
现在我们再回过头来看看我们上一版的实现,就能看出它是错的了,那么为什么 Rust 会编译通过呢?答案很简单:因为这是内存安全的。
Rust 借用检查器对生命周期注解的要求只到能静态验证程序的内存安全为止。即便生命周期注解有语义上的错误,Rust 也能让程序编译通过,哪怕这样做为程序带来不必要的限制。
这儿有一个和之前相反的例子:在这个例子中,Rust 生命周期省略规则标注的生命周期是语义正确的,但是我们却在无意间使用了不必要的显式注解,导致写出了一个限制极其严格的方法。
#[derive(Debug)] struct NumRef<'a>(&'a i32); impl<'a> NumRef<'a> { // 我定义的泛型结构体以 'a 为参数,这意味着我也需要给方法的参数 // 标注为 'a 生命周期,对吗?(答案:错) fn some_method(&'a mut self) {} } fn main() { let mut num_ref = NumRef(&5); num_ref.some_method(); // 可变借用 num_ref 直至其生命周期结束 num_ref.some_method(); // 编译错误 println!("{:?}", num_ref); // 同样编译错误 }
如果我们有一个带 'a 泛型参数的结构体,我们几乎不可能去写一个带 &'a mut self 参数的方法。因为这相当于告诉 Rust “这个方法将独占借用该对象,直到对象生命周期结束”。实际上,这意味着 Rust 的借用检查器只会允许在该对象上调用至多一次 some_method, 此后该对象将一直被独占借用并会因此变得不再可用。这种用例极其罕见,但是因为这种代码能够通过编译,所以那些对生命周期还感到困惑的初学者们很容易写出这种 bug. 修复这种 bug 的方式是去除掉不必要的显式生命周期注解,让 Rust 生命周期省略规则来处理它:
#[derive(Debug)] struct NumRef<'a>(&'a i32); impl<'a> NumRef<'a> { // 不再给 mut self 添加 'a 注解 fn some_method(&mut self) {} // 上一行去掉语法糖后: fn some_method_desugared<'b>(&'b mut self){} } fn main() { let mut num_ref = NumRef(&5); num_ref.some_method(); num_ref.some_method(); // 编译通过 println!("{:?}", num_ref); // 编译通过 }
关键点回顾
- Rust 对函数的生命周期省略规则并不保证在任何情况下都正确
- 在程序的语义方面,Rust 并不比你懂
- 可以试试给你的生命周期注解起一个有意义的名字
- 试着记住你在哪里添加了显式生命周期注解,以及为什么要加
6) 已装箱的 trait 对象不含生命周期注解
之前我们讨论了 Rust 对函数 的生命周期省略规则。Rust 对 trait 对象也存在生命周期省略规则,它们是:
- 如果 trait 对象被用作泛型类型的一个类型参数,那么 trait 对象的的生命周期约束会依据该类型参数的定义进行推导
- 若该类型参数有唯一的生命周期约束,则将这个约束赋给 trait 对象
- 若该类型参数不止一个生命周期约束,则 trait 对象的生命周期约束需要显式标注
- 如果上面不成立,也就是说该类型参数没有生命周期约束,那么
- 若 trait 定义时有且仅有一个生命周期约束,则将这个约束赋给 trait 对象
- 若 trait 定义时生命周期约束中存在一个
'static, 则将'static赋给 trait 对象 - 若 trait 定义时没有生命周期约束,则当 trait 对象是表达式的一部分时,生命周期从表达式中推导而出,否则赋予 `'static``
以上这些听起来特别复杂,但是可以简单地总结为一句话“一个 trait 对象的生命周期约束从上下文推导而出。”看下面这些例子后,我们会看到生命周期约束的推导其实很符合直觉,因此我们没必要去记忆上面的规则:
#![allow(unused)] fn main() { use std::cell::Ref; trait Trait {} // 展开前 type T1 = Box<dyn Trait>; // 展开后,Box<T> 没有对 T 的生命周期约束,所以推导为 'static type T2 = Box<dyn Trait + 'static>; // 展开前 impl dyn Trait {} // 展开后 impl dyn Trait + 'static {} // 展开前 type T3<'a> = &'a dyn Trait; // 展开后,&'a T 要求 T: 'a, 所以推导为 'a type T4<'a> = &'a (dyn Trait + 'a); // 展开前 type T5<'a> = Ref<'a, dyn Trait>; // 展开后,Ref<'a, T> 要求 T: 'a, 所以推导为 'a type T6<'a> = Ref<'a, dyn Trait + 'a>; trait GenericTrait<'a>: 'a {} // 展开前 type T7<'a> = Box<dyn GenericTrait<'a>>; // 展开后 type T8<'a> = Box<dyn GenericTrait<'a> + 'a>; // 展开前 impl<'a> dyn GenericTrait<'a> {} // 展开后 impl<'a> dyn GenericTrait<'a> + 'a {} }
一个实现了 trait 的具体类型可以被引用,因此它们也会有生命周期约束,同样其对应的 trait 对象也有生命周期约束。你也可以直接对引用实现 trait, 引用显然是有生命周期约束的:
#![allow(unused)] fn main() { trait Trait {} struct Struct {} struct Ref<'a, T>(&'a T); impl Trait for Struct {} impl Trait for &Struct {} // 直接为引用类型实现 Trait impl<'a, T> Trait for Ref<'a, T> {} // 为包含引用的类型实现 Trait }
总之,这个知识点值得反复理解,新手在重构一个使用 trait 对象的函数到一个泛型的函数或者反过来时,常常会因为这个知识点而感到困惑。来看看这个示例程序:
#![allow(unused)] fn main() { use std::fmt::Display; fn dynamic_thread_print(t: Box<dyn Display + Send>) { std::thread::spawn(move || { println!("{}", t); }).join(); } fn static_thread_print<T: Display + Send>(t: T) { std::thread::spawn(move || { println!("{}", t); }).join(); } }
这里编译器报错:
#![allow(unused)] fn main() { error[E0310]: the parameter type `T` may not live long enough --> src/lib.rs:10:5 | 9 | fn static_thread_print<T: Display + Send>(t: T) { | -- help: consider adding an explicit lifetime bound...: `T: 'static +` 10 | std::thread::spawn(move || { | ^^^^^^^^^^^^^^^^^^ | note: ...so that the type `[closure@src/lib.rs:10:24: 12:6 t:T]` will meet its required lifetime bounds --> src/lib.rs:10:5 | 10 | std::thread::spawn(move || { | ^^^^^^^^^^^^^^^^^^ }
很好,编译器告诉了我们怎样修复这个问题,让我们修复一下。
#![allow(unused)] fn main() { use std::fmt::Display; fn dynamic_thread_print(t: Box<dyn Display + Send>) { std::thread::spawn(move || { println!("{}", t); }).join(); } fn static_thread_print<T: Display + Send + 'static>(t: T) { std::thread::spawn(move || { println!("{}", t); }).join(); } }
现在它编译通过了,但是这两个函数对比起来看起来挺奇怪的,为什么第二个函数要求 T 满足 'static 约束而第一个函数不用呢?这是个刁钻的问题。事实上,通过生命周期省略规则,Rust 自动在第一个函数里推导并添加了一个 'static 约束,所以其实两个函数都含有 'static 约束。Rust 编译器实际看到的是这个样子的:
#![allow(unused)] fn main() { use std::fmt::Display; fn dynamic_thread_print(t: Box<dyn Display + Send + 'static>) { std::thread::spawn(move || { println!("{}", t); }).join(); } fn static_thread_print<T: Display + Send + 'static>(t: T) { std::thread::spawn(move || { println!("{}", t); }).join(); } }
关键点回顾
- 所有 trait 对象都含有自动推导的生命周期
7) 编译器的报错信息会告诉我怎样修复我的程序
错误的推论
- Rust 对 trait 对象的生命周期省略规则总是正确的
- Rust 比我更懂我程序的语义
这个误解是前两个误解的结合,来看一个例子:
#![allow(unused)] fn main() { use std::fmt::Display; fn box_displayable<T: Display>(t: T) -> Box<dyn Display> { Box::new(t) } }
报错如下:
#![allow(unused)] fn main() { error[E0310]: the parameter type `T` may not live long enough --> src/lib.rs:4:5 | 3 | fn box_displayable<T: Display>(t: T) -> Box<dyn Display> { | -- help: consider adding an explicit lifetime bound...: `T: 'static +` 4 | Box::new(t) | ^^^^^^^^^^^ | note: ...so that the type `T` will meet its required lifetime bounds --> src/lib.rs:4:5 | 4 | Box::new(t) | ^^^^^^^^^^^ }
好,让我们按照编译器的提示进行修复。这里我们先忽略一个事实:返回值中装箱的 trait 对象有一个自动推导的 'static 约束,而编译器是基于这个没有显式说明的事实给出的修复建议。
#![allow(unused)] fn main() { use std::fmt::Display; fn box_displayable<T: Display + 'static>(t: T) -> Box<dyn Display> { Box::new(t) } }
现在可以编译通过了,但这真的是我们想要的吗?可能是,也可能不是,编译器并没有提到其他修复方案,但下面这个也是一个合适的修复方案。
#![allow(unused)] fn main() { use std::fmt::Display; fn box_displayable<'a, T: Display + 'a>(t: T) -> Box<dyn Display + 'a> { Box::new(t) } }
这个函数所能接受的实际参数比前一个函数多了不少!这个函数是不是更好?确实,但不一定必要,这取决于我们对程序的要求与约束。上面这个例子有点抽象,所以让我们看一个更简单明了的例子:
#![allow(unused)] fn main() { fn return_first(a: &str, b: &str) -> &str { a } }
报错:
#![allow(unused)] fn main() { error[E0106]: missing lifetime specifier --> src/lib.rs:1:38 | 1 | fn return_first(a: &str, b: &str) -> &str { | ---- ---- ^ expected named lifetime parameter | = help: this function's return type contains a borrowed value, but the signature does not say whether it is borrowed from `a` or `b` help: consider introducing a named lifetime parameter | 1 | fn return_first<'a>(a: &'a str, b: &'a str) -> &'a str { | ^^^^ ^^^^^^^ ^^^^^^^ ^^^ }
这个错误信息推荐我们给所有输入输出都标注上同样的生命周期注解。如果我们这么做了,那么程序将通过编译,但是这样写出的函数过度限制了返回类型。我们真正想要的是这个:
#![allow(unused)] fn main() { fn return_first<'a>(a: &'a str, b: &str) -> &'a str { a } }
关键点回顾
- Rust 对 trait 对象的生命周期省略规则并不保证在任何情况下都正确
- 在程序的语义方面,Rust 并不比你懂
- Rust 编译错误的提示信息所提出的修复方案并不一定能满足你对程序的需求
8) 生命周期可以在运行时动态变长或变短
错误的推论
- 容器类可以在运行时交换其内部的引用,从而改变自身的生命周期
- Rust 借用检查器能进行高级的控制流分析
这个编译不通过:
struct Has<'lifetime> { lifetime: &'lifetime str, } fn main() { let long = String::from("long"); let mut has = Has { lifetime: &long }; assert_eq!(has.lifetime, "long"); { let short = String::from("short"); // “转换到” 短的生命周期 has.lifetime = &short; assert_eq!(has.lifetime, "short"); // “转换回” 长的生命周期(实际是并不是) has.lifetime = &long; assert_eq!(has.lifetime, "long"); // `short` 变量在这里 drop } // 编译失败, `short` 在 drop 后仍旧处于 “借用” 状态 assert_eq!(has.lifetime, "long"); }
报错:
#![allow(unused)] fn main() { error[E0597]: `short` does not live long enough --> src/main.rs:11:24 | 11 | has.lifetime = &short; | ^^^^^^ borrowed value does not live long enough ... 15 | } | - `short` dropped here while still borrowed 16 | assert_eq!(has.lifetime, "long"); | --------------------------------- borrow later used here }
下面这个还是报错,报错信息也和上面一样:
struct Has<'lifetime> { lifetime: &'lifetime str, } fn main() { let long = String::from("long"); let mut has = Has { lifetime: &long }; assert_eq!(has.lifetime, "long"); // 这个代码块逻辑上永远不会被执行 if false { let short = String::from("short"); // “转换到” 短的生命周期 has.lifetime = &short; assert_eq!(has.lifetime, "short"); // “转换回” 长的生命周期(实际是并不是) has.lifetime = &long; assert_eq!(has.lifetime, "long"); // `short` 变量在这里 drop } // 还是编译失败, `short` 在 drop 后仍旧处于 “借用” 状态 assert_eq!(has.lifetime, "long"); }
生命周期必须在编译时被静态确定,而且 Rust 借用检查器只会做基本的控制流分析,所以它假设每个 if-else 块和 match 块的每个分支都能被执行,然后选出一个最短的生命周期赋给块中的变量。一旦一个变量被一个生命周期约束了,那么它将 永远 被这个生命周期所约束。一个变量的生命周期只能缩短,而且所有的缩短时机都在编译时确定。
关键点回顾
- 生命周期在编译时被静态确定
- 生命周期在运行时不能被改变
- Rust 借用检查器假设所有代码路径都能被执行,所以总是选择尽可能短的生命周期赋给变量
9) 将独占引用降级为共享引用是 safe 的
错误的推论
- 通过重借用引用内部的数据,能抹掉其原有的生命周期,然后赋一个新的上去
你可以将一个独占引用作为参数传给一个接收共享引用的函数,因为 Rust 将隐式地重借用独占引用内部的数据,生成一个共享引用:
fn takes_shared_ref(n: &i32) {} fn main() { let mut a = 10; takes_shared_ref(&mut a); // 编译通过 takes_shared_ref(&*(&mut a)); // 上面那行去掉语法糖 }
这在直觉上是合理的,因为将一个独占引用转换为共享引用显然是无害的,对吗?令人讶异的是,这并不对,下面的这段程序不能通过编译:
fn main() { let mut a = 10; let b: &i32 = &*(&mut a); // 重借用为不可变引用 let c: &i32 = &a; dbg!(b, c); // 编译失败 }
报错如下:
#![allow(unused)] fn main() { error[E0502]: cannot borrow `a` as immutable because it is also borrowed as mutable --> src/main.rs:4:19 | 3 | let b: &i32 = &*(&mut a); | -------- mutable borrow occurs here 4 | let c: &i32 = &a; | ^^ immutable borrow occurs here 5 | dbg!(b, c); | - mutable borrow later used here }
代码里确实有一个独占引用,但是它立即重借用变成了一个共享引用,然后自身就被 drop 掉了。但是为什么 Rust 好像把这个重借用出来的共享引用看作是有一个独占的生命周期呢?上面这个例子中,允许独占引用直接降级为共享引用是没有问题的,但是这个允许确实会导致潜在的内存安全问题。
use std::sync::Mutex; struct Struct { mutex: Mutex<String> } impl Struct { // 将 self 的独占引用降级为 str 的共享引用 fn get_string(&mut self) -> &str { self.mutex.get_mut().unwrap() } fn mutate_string(&self) { // 如果 Rust 允许独占引用降级为共享引用,那么下面这一行代码执行后, // 所有通过 get_string 方法返回的 &str 都将变为非法引用 *self.mutex.lock().unwrap() = "surprise!".to_owned(); } } fn main() { let mut s = Struct { mutex: Mutex::new("string".to_owned()) }; let str_ref = s.get_string(); // 独占引用降级为共享引用 s.mutate_string(); // str_ref 失效,变成非法引用,现在是一个悬垂指针 dbg!(str_ref); // 当然,实际上会编译错误 }
这里的关键点在于,你在重借用一个独占引用为共享引用时,就已经落入了一个陷阱:为了保证重借用得到的共享引用在其生命周期内有效,被重借用的独占引用也必须保证在这段时期有效,这延长了独占引用的生命周期!哪怕独占引用自身已经被 drop 掉了,但独占引用的生命周期却一直延续到共享引用的生命周期结束。
使用重借用得到的共享引用是很难受的,因为它明明是一个共享引用但是却不能和其他共享引用共存。重借用得到的共享引用有着独占引用和共享引用的缺点,却没有二者的优点。我认为重借用一个独占引用为共享引用的行为应当被视为 Rust 的一种反模式。知道这种反模式是很重要的,当你看到这样的代码时,你就能轻易地发现错误了:
#![allow(unused)] fn main() { // 将独占引用降级为共享引用 fn some_function<T>(some_arg: &mut T) -> &T; struct Struct; impl Struct { // 将独占的 self 引用降级为共享的 self 引用 fn some_method(&mut self) -> &self; // 将独占的 self 引用降级为共享的 T 引用 fn other_method(&mut self) -> &T; } }
尽管你可以在函数和方法的声明里避免重借用,但是由于 Rust 会自动做隐式重借用,所以很容易无意识地遇到这种情况。
#![allow(unused)] fn main() { use std::collections::HashMap; type PlayerID = i32; #[derive(Debug, Default)] struct Player { score: i32, } fn start_game(player_a: PlayerID, player_b: PlayerID, server: &mut HashMap<PlayerID, Player>) { // 从 server 中得到 player, 如果不存在就创建一个默认的 player 并得到这个新创建的。 let player_a: &Player = server.entry(player_a).or_default(); let player_b: &Player = server.entry(player_b).or_default(); // 对得到的 player 做一些操作 dbg!(player_a, player_b); // 编译错误 } }
上面这段代码会编译失败。这里 or_default() 会返回一个 &mut Player,但是由于我们添加了一个显式的类型标注,它会被隐式重借用成 &Player。而为了达成我们真正的目的,我们不得不这样做:
#![allow(unused)] fn main() { use std::collections::HashMap; type PlayerID = i32; #[derive(Debug, Default)] struct Player { score: i32, } fn start_game(player_a: PlayerID, player_b: PlayerID, server: &mut HashMap<PlayerID, Player>) { // 因为编译器不允许这两个返回值共存,所有这里直接丢弃这两个 &mut Player server.entry(player_a).or_default(); server.entry(player_b).or_default(); // 再次获取 player, 这次我们直接拿到共享引用,避免隐式的重借用 let player_a = server.get(&player_a); let player_b = server.get(&player_b); // 对得到的 player 做一些操作 dbg!(player_a, player_b); // 现在能编译通过了 } }
难用,而且很蠢,但这是我们为了内存安全这一信条所做出的牺牲。
关键点回顾
- 尽量避免重借用一个独占引用为共享引用,不然你会遇到很多麻烦
- 重借用一个独占引用并不会结束其生命周期,哪怕它自身已经被 drop 掉了
10) 对闭包的生命周期省略规则和函数一样
这更像是 Rust 的陷阱而非误解
尽管闭包可以被当作是一个函数,但是并不遵循和函数同样的生命周期省略规则。
fn function(x: &i32) -> &i32 { x } fn main() { let closure = |x: &i32| x; }
报错:
#![allow(unused)] fn main() { error: lifetime may not live long enough --> src/main.rs:6:29 | 6 | let closure = |x: &i32| x; | - - ^ returning this value requires that `'1` must outlive `'2` | | | | | return type of closure is &'2 i32 | let's call the lifetime of this reference `'1` }
去掉语法糖后,我们得到的是:
// 输入的生命周期应用到了输出上 fn function<'a>(x: &'a i32) -> &'a i32 { x } fn main() { // 输入和输出有它们自己各自的生命周期 let closure = for<'a, 'b> |x: &'a i32| -> &'b i32 { x }; // 注意:上一行并不是合法的语句,但是我们需要它来描述我们目的 }
出现这种差异并没有什么好处。只是在闭包最初的实现中,使用的类型推断语义与函数不同,而现在将二者做一个统一将是一个 breaking change, 因此现在已经没法改了。那么我们怎么显式地标注一个闭包的类型呢?我们有以下几种方案:
fn main() { // 转换成 trait 对象,但这样是不定长的,所以会编译错误 let identity: dyn Fn(&i32) -> &i32 = |x: &i32| x; // 可以分配到堆上作为替代方案,但是在这里堆分配感觉有点蠢 let identity: Box<dyn Fn(&i32) -> &i32> = Box::new(|x: &i32| x); // 可以不用堆分配而直接创建一个 'static 引用 let identity: &dyn Fn(&i32) -> &i32 = &|x: &i32| x; // 上一行去掉语法糖 :) let identity: &'static (dyn for<'a> Fn(&'a i32) -> &'a i32 + 'static) = &|x: &i32| -> &i32 { x }; // 这看起来很完美,但可惜不符合语法 let identity: impl Fn(&i32) -> &i32 = |x: &i32| x; // 这个也行,但也不符合语法 let identity = for<'a> |x: &'a i32| -> &'a i32 { x }; // 但是 "impl trait" 可以作为函数的返回值类型 fn return_identity() -> impl Fn(&i32) -> &i32 { |x| x } let identity = return_identity(); // 上一个解决方案的泛化版本 fn annotate<T, F>(f: F) -> F where F: Fn(&T) -> &T { f } let identity = annotate(|x: &i32| x); }
我想你应该注意到了,在上面的例子中,如果对闭包应用 trait 约束,闭包会和函数遵循同样的生命周期省略规则。
这里没有什么现实的教训或见解,只是说明一下闭包是这样的。
关键点回顾
- 每个语言都有其陷阱 🤷
11) 'static 引用总能被强制转换为 'a 引用
我之前有过这样的代码:
#![allow(unused)] fn main() { fn get_str<'a>() -> &'a str; // 泛型版本 fn get_str() -> &'static str; // 'static 版本 }
一些读者联系我,问这两者之间是否有实际的差异。我一开始并不确定,但一番研究过后遗憾地发现,是的,这二者确实有差异。
通常在使用值时,我们能用 'static 引用直接代替一个 'a 引用,因为 Rust 会自动把 'static 引用强制转换为 'a 引用。直觉上这很合理,因为在一个对生命周期要求比较短的地方用一个生命周期比较长的引用绝不会导致任何内存安全问题。下面的这段代码通过编译,和预期一致:
use rand; fn generic_str_fn<'a>() -> &'a str { "str" } fn static_str_fn() -> &'static str { "str" } fn a_or_b<T>(a: T, b: T) -> T { if rand::random() { a } else { b } } fn main() { let some_string = "string".to_owned(); let some_str = &some_string[..]; let str_ref = a_or_b(some_str, generic_str_fn()); // 编译通过 let str_ref = a_or_b(some_str, static_str_fn()); // 编译通过 }
然而当引用作为函数类型签名的一部分时,强制类型转换并不生效。所以下面这段代码不能通过编译:
use rand; fn generic_str_fn<'a>() -> &'a str { "str" } fn static_str_fn() -> &'static str { "str" } fn a_or_b_fn<T, F>(a: T, b_fn: F) -> T where F: Fn() -> T { if rand::random() { a } else { b_fn() } } fn main() { let some_string = "string".to_owned(); let some_str = &some_string[..]; let str_ref = a_or_b_fn(some_str, generic_str_fn); // 编译通过 let str_ref = a_or_b_fn(some_str, static_str_fn); // 编译错误 }
报错如下:
#![allow(unused)] fn main() { error[E0597]: `some_string` does not live long enough --> src/main.rs:23:21 | 23 | let some_str = &some_string[..]; | ^^^^^^^^^^^ borrowed value does not live long enough ... 25 | let str_ref = a_or_b_fn(some_str, static_str_fn); | ---------------------------------- argument requires that `some_string` is borrowed for `'static` 26 | } | - `some_string` dropped here while still borrowed }
很难说这是不是 Rust 的一个陷阱,把 for<T> Fn() -> &'static T 强制转换成 for<'a, T> Fn() -> &'a T 并不是一个像把 &'static str 强制转换为 &'a str 这样简单直白的情况。前者是类型之间的转换,后者是值之间的转换。
关键点回顾
for <'a,T> fn()->&'a T签名的函数比for <T> fn()->&'static T签名的函数要更灵活,并且泛用于更多场景
总结
T是&T和&mut T的超集&T和&mut T是不相交的集合T: 'static应当视为 “T满足'static生命周期约束”- 若
T: 'static则T可以是一个有'static生命周期的引用类型 或 是一个所有权类型 - 因为
T: 'static包括了所有权类型,所以T- 可以在运行时动态分配
- 不需要在整个程序运行期间都有效
- 可以安全,自由地修改
- 可以在运行时被动态的 drop
- 可以有不同长度的生命周期
T: 'a比&'a T更泛化,更灵活T: 'a接受所有权类型,内部含有引用的所有权类型,和引用&'a T只接受引用- 若
T: 'static则T: 'a因为对于所有'a都有'static>='a - 几乎所有的 Rust 代码都是泛型代码,并且到处都带有被省略掉的泛型生命周期注解e
- Rust 生命周期省略规则并不保证在任何情况下都正确
- 在程序的语义方面,Rust 并不比你懂
- 可以试试给你的生命周期注解起一个有意义的名字
- 试着记住你在哪里添加了显式生命周期注解,以及为什么要
- 所有 trait 对象都含有自动推导的生命周期
- Rust 编译错误的提示信息所提出的修复方案并不一定能满足你对程序的需求
- 生命周期在编译时被静态确定
- 生命周期在运行时不能被改变
- Rust 借用检查器假设所有代码路径都能被执行,所以总是选择尽可能短的生命周期赋给变量
- 尽量避免重借用一个独占引用为共享引用,不然你会遇到很多麻烦
- 重借用一个独占引用并不会结束其生命周期,哪怕它自身已经被 drop 掉了
- 每个语言都有其陷阱 🤷
for <'a,T> fn()->&'a T签名的函数比for <T> fn()->&'static T签名的函数要更灵活,并且广泛用于更多场景
讨论
可以在这些地方进行讨论
温馨提示
通过这些渠道获取最新消息
- Following pretzelhammer on Twitter or
- Watching this repo's releases (click on
Watchdropdown and selectReleases only)
拓展阅读
译者注
本文参考了
文中部分语句采用意译,部分单词不译。
生命周期型变示例
#![allow(unused)] #![allow(dead_code)] #![allow(unused_imports)] #![allow(unused_variables)] fn main() { //! 一个展示 Rust 中生命周期型变 (variance) 的示例 //! //! 这个示例可以通过 Cargo 进行编译及测试 use std::cell::Cell; use std::collections::HashSet; use std::fmt; // ------------------------- // (I) 建立一个直观感受 // ------------------------- // 这个函数传入了一个静态字符串,并缩短了其生命周期 fn lifetime_shortener<'a>(s: &'static str) -> &'a str { s } // 直观上来看,它的编译原则应该是:如果一个字符串在整个过程中持续存在,那么它的组成部分也应该持续存在。确实如此! // 现在,让它稍微复杂一些。让我们在图片中引入一个`Cell`。 // 提醒一下,`Cell`允许修改其内部的数据 #[cfg(feature = "compile-fail")] fn cell_shortener<'a, 'b>(s: &'a Cell<&'static str>) -> &'a Cell<&'b str> { s } // cell_shortener 函数不能编译:(你能说明是因为什么吗?花一分钟时间思考一下,尝试使用你的直觉 #[cfg(feature = "compile-fail")] fn cell_example() { // 思考一下这个 Cell。它持有一个静态的字符串 let foo: Cell<&'static str> = Cell::new("foo"); // 你认为这个可以起作用吗? let owned_string: String = "non_static".to_owned(); foo.replace(&owned_string); // 看起来好像不行,是吗?foo 承诺它包含的应该是一个 &'static str, // 但我们试图放入一个范围为该函数所拥有的字符串。 } #[cfg(feature = "compile-fail")] fn cell_counterexample() { let foo: Cell<&'static str> = Cell::new("foo"); let owned_string: String = "non_static".to_owned(); // 我们假设 cell_shortener 起作用了 let shorter_foo = cell_shortener(&foo); // 然后 shorter_foo 和 foo 将是彼此的别名,这意味着你可以使用 shorter_foo 将 foo 的 Cell 替换为非静态字符串 shorter_foo.replace(&owned_string); // 现在的 foo,是 shorter_foo 的别名,里面包含一个非静态字符串!哎呀呀 } // 不只是 Cell 会出现这种问题,RefCell,OnceCell,Mutex,&mut 引用 -- 某种可变上下文的内部都会出现这种问题 // 现在,假设 (hypothetical) 该函数会将 s 的生命周期变长会怎么样呢? #[cfg(feature = "compile-fail")] fn lifetime_lengthener<'a>(s: &'a str) -> &'static str { s } // 这显然是伪造的 (bogus),对吗?你不能将任意借用字符串的生命周期变得和整个过程的持续时间一样长。同样的还有: #[cfg(feature = "compile-fail")] fn cell_lengthener<'a, 'b>(s: &'a Cell<&'b str>) -> &'a Cell<&'static str> { s } // 但是这种呢?fn 是一个指向函数的指针,它以任意借用的字符串作为参数。 fn fn_ptr_lengthener<'a>(f: fn(&'a str) -> ()) -> fn(&'static str) -> () { f } // 啊啊啊,直觉是这应该可以工作。并且它确实如此。你可以使用一个传入任意借用字符串的回调,然后将其转换为采用静态字符串的回调。 // ------------------------- // (II) 形式化型变 // ------------------------- // 如何将所有这些直觉形式化?它是通过*型变*的想法完成的 // // 某些类型的内存生命周期比其他类型的内存更长。这是通过 *outlives* 关系的想法捕获的。如果 'b 的寿命比 'a 长,则写为 'b: 'a。举个例子,在定义中: struct OutlivesExample<'a, 'b: 'a> { a_str: &'a str, b_str: &'b str, } // 借用字符串`b_str`的生命周期至少和`a_str`一样长,可能会更久。 // Rust 编译器使用以下三个设置的其中之一来标注每一个生命周期。对于类型 T<'a>, 'a 可能是: // // * *协变 (covariant)*,它意味着如果 'b: 'a 则 T<'b>: T<'a>。这是不可变数据的默认配置。 // // * *不变 (invariant)*,它意味着即使 'b: 'a,也无法描述 T<'b> 和 T<'a> 之间的关系。满足这两个原因其中之一,就会发生这种情况: // // * 如果生命周期存在于某些可变上下文中 -- 无论是 &mut 引用,还是内部可变的结构 (如 Cell/RefCell/Mutex)。 // * 如果将生命周期用于型变冲突的多个位置。请看 (III) 的示例 // // * *逆变 (contravariant)*,它意味着如果 'b: 'a 则 T<'a>: T<'b>。这不是很常见,并且只在函数指针的参数中出现。 // // 参数的型变完全通过类型定义确定,没有为其标记特征。 // --- // 快速练习。在下面的结构中,每一种参数的生命周期都是哪一种型变? struct Multi<'a, 'b, 'c, 'd1, 'd2> { a: &'a str, b: Cell<&'b str>, c: fn(&'c str) -> usize, d: &'d1 mut &'d2 str, } // ... // 答案是: // * 'a 是协变,因为它只在不可变的上下文中显式。 // 这就意味着。和上面的 shortener 函数一样,你可以定义一个如下函数: fn a<'a, 'b, 'c, 'd1, 'd2>(x: Multi<'static, 'b, 'c, 'd1, 'd2>) -> Multi<'a, 'b, 'c, 'd1, 'd2> { x } // * 'b 是不变,因为它位于可变的 Cell 上下文中。 // (练习:尝试写出一个由于 'b 是不变,从而导致无法编译的函数) // * 'c is 逆变,因为它显式在回调的参数中。 fn c<'a, 'b, 'c, 'd1, 'd2>(x: Multi<'a, 'b, 'c, 'd1, 'd2>) -> Multi<'a, 'b, 'static, 'd1, 'd2> { x } // * 'd1 是*协变*!尽管它是一个可变引用,但它不在 &mut 指针中。 fn d1<'a, 'b, 'c, 'd1, 'd2>(x: Multi<'a, 'b, 'c, 'static, 'd2>) -> Multi<'a, 'b, 'c, 'd1, 'd2> { x } // * 'd2 是不变,因为它在可变引用里。 // ----------------------------------- // (III) 冲突和类型参数 // ----------------------------------- // 如果将一个生命周期参数用于不同型变的多个地方会怎样?举个例子 struct TwoSpots<'a> { foo: &'a str, bar: Cell<&'a str>, } // 如你所料: // * 如果所有的用法都满足一个特定的型变,则该参数具有该类型的型变。 // * 否则,该参数的生命周期默认为不变。 // 那么这种情况呢? struct TypeParams<T, U> { t: Vec<T>, u: fn(U) -> (), } // 当 T 和 U 被替换为包含生命周期参数的类型时,也会使用型变对其进行标注。举个例子: struct LifetimeParams<'a, 'b> { nested: TypeParams<&'a str, &'b str>, } // 在这里,'a 是一个型变,'b 是一个逆变。让我们一起对他们进行测试: fn lifetime_check<'a, 'b>(x: LifetimeParams<'static, 'b>) -> LifetimeParams<'a, 'static> { x } // ------------------------- // (IV) 实践中的型变 // ------------------------- // 那么,作为 Rust 开发人员,你为什么要关心呢? // 许多 Rust 开发人员开始使用引用计数的智能指针(如:`Rc` 或者 `Arc`),而不是到处借用数据。如果你这么做的话,你就不太可能遇到生命周期的问题。 // 但是最终你可能会为了更高的性能,尝试借用数据 -- 如果这样子的话,你可能会在你的代码中引入生命周期参数。这时型变就变得很重要。 // 一些最棘手的问题使得 rustc 接受普通使用借用数据的代码,并最终以某种方式产生型变。 // // 举个例子,考虑以下情景,从真实场景提取的 Rust 代码: // 考虑一下这个代表消息的结构。 struct Message<'msg> { message: &'msg str, } // ... 这个结构收集将要展示的消息。 struct MessageCollector<'a, 'msg> { list: &'a mut Vec<Message<'msg>>, } impl<'a, 'msg> MessageCollector<'a, 'msg> { // 这里在 list 的末尾添加了一条消息。 fn add_message(&mut self, message: Message<'msg>) { self.list.push(message); } } // 这个结构展示了收集的消息 struct MessageDisplayer<'a, 'msg> { list: &'a Vec<Message<'msg>>, } impl<'a, 'msg> fmt::Display for MessageDisplayer<'a, 'msg> { // 以换行作为分隔符,这里展示了所有的消息。 fn fmt(&self, f: &mut fmt::Formatter<'_>) -> fmt::Result { for message in self.list { write!(f, "{}\n", message.message)?; } Ok(()) } } fn message_example() { // 这是一个简单的消息池 let mut message_pool: HashSet<String> = HashSet::new(); message_pool.insert("ten".to_owned()); message_pool.insert("twenty".to_owned()); // 一切就绪,让我们尝试收集并展示一些消息! collect_and_display(&message_pool); } fn collect_and_display<'msg>(message_pool: &'msg HashSet<String>) { let mut list = vec![]; // 收集一些信息。(这很简单,但是你可以想象将收集器传递到其他的代码中)。 let mut collector = MessageCollector { list: &mut list }; for message in message_pool { collector.add_message(Message { message }); } // 现在,让我们展示这些消息 let displayer = MessageDisplayer { list: &list }; println!("{}", displayer); } // 它起作用了,但是可以更简单一点吗?让我们尝试减少生命周期参数的数量,首先,对于 displayer struct SimpleMessageDisplayer<'a> { list: &'a Vec<Message<'a>>, } impl<'a> fmt::Display for SimpleMessageDisplayer<'a> { // 这里展示了所有的消息 fn fmt(&self, f: &mut fmt::Formatter<'_>) -> fmt::Result { for message in self.list { write!(f, "{}\n", message.message)?; } Ok(()) } } fn collect_and_display_2<'msg>(message_pool: &'msg HashSet<String>) { // OK,让我们做与 collect_and_display 相同的事,除了使用简单的 displayer。 let mut list = vec![]; // 收集一些消息 let mut collector = MessageCollector { list: &mut list }; for message in message_pool { collector.add_message(Message { message }); } // 最后展示它们 let displayer = SimpleMessageDisplayer { list: &list }; println!("{}", displayer); } // OK,它起作用了。我们可以对 collector 做同样的事情吗?让我们尝试以下: struct SimpleMessageCollector<'a> { list: &'a mut Vec<Message<'a>>, } impl<'a> SimpleMessageCollector<'a> { // 在 list 的末尾添加一条消息 fn add_message(&mut self, message: Message<'a>) { self.list.push(message); } } #[cfg(feature = "compile-fail-final")] fn collect_and_display_3<'msg>(message_pool: &'msg HashSet<String>) { // OK,再一次 let mut list = vec![]; // 收集一些消息 let mut collector = SimpleMessageCollector { list: &mut list }; for message in message_pool { collector.add_message(Message { message }); } // 最后展示它们 let displayer = SimpleMessageDisplayer { list: &list }; println!("{}", displayer); } // 这没有用!rustc (1.43.1) 显式错误:“无法借用不可变的`list`,因为它也作为可变被借用了” // // 为什么减少生命周期参数对于 MessageDisplayer 起作用了,但是却没有对 MessageCollector 起作用?这都是因为型变。让我们再一次看下这个结构,首先查看 displayer: struct MessageDisplayer2<'a, 'msg> { // 两个生命周期参数 list: &'a Vec<Message<'msg>>, // 在这里,编译器可以独立的改变两者,因此 list 的生命周期可以比 'msg 更短,然后释放。 } // 简单的版本: struct SimpleMessageDisplayer2<'a> { // 'a 被用于两个位置: // // | | // v v list: &'a Vec<Message<'a>>, // // 但是由于它们两个都是协变的(在不可变的上下文中),'a 也是协变的。 // 这意味着编译器可以在内部将 &'a Vec<Message<'msg>> 转换为 &'a Vec<Message<'a>>,并将 list 保留较短的 'a 的持续时间。 } // 现在是 collector: struct MessageCollector2<'a, 'msg> { // 又是两个生命周期参数: list: &'a mut Vec<Message<'msg>>, // 在这里,'a 是一个协变,但是 'msg 是不变,因为它在 &mut 引用的内部。 // 编译器可以分别更改两者,这意味着 list 可以保留比 'msg 更短的生命周期。 } // 最后,有问题的简单版本: struct SimpleMessageCollector2<'a> { // 'a 再一次用于两个位置: // // | | // v v list: &'a mut Vec<Message<'a>>, // // 第一个 'a 是协变,第二个是不变,因为它在 &mut 引用的内部! // 这意味着 'a 是不变的,这最终造成编译器尝试并拥有比标准 MessageCollector 生命周期更长的 list。 } // --- // 如果要编写 Rust 库,请注意以下几点: // // 将参数(生命周期或类型)的型变从协变改为其他类型,或者从逆变改为其他类型,是一个巨大的变更。如果你遵循 semver,则只能使用最新的主要版本来完成。 // // 将参数从不变转换成协变或逆变,不是一种重大的变更 // --- // 无论如何,希望这可以让你在 Rust 代码中更自信的使用生命周期,他们是编写安全,快速代码的有效方式。但是在实践中,型变常常会造成晦涩的问题 -- 了解其工作的方式是有效使用生命周期的关键。 // 感谢以下同学的反馈: // * Nikolai Vazquez (@NikolaiVazquez on Twitter, nvzqz on GitHub) // * Inanna Malick (@inanna_malick on Twitter, inanna-malick on GitHub) }
Rust 如何实现线程安全
在我迄今为止的每一次演讲中,都会遇到 “Rust 是如何实现线程安全”的提问,我通常只是概述一下,而本文为感兴趣的人提供了更全面的解释。
你也可以参阅:Huon 关于此主题的博客
在之前的文章中,我稍微谈到了 Copy 特征。标准库中还有其他这样的“标记”特征,本文中与之相关的是 Send 和 Sync 特征。如果你对像 RefCell 和 Rc 这样的包装器类型不熟悉,我建议你阅读那篇文章,因为我将在本文中将它们作为示例;但是这里解释的概念在很大程度上是独立的。
处于本文的目的,我将线程安全限制为没有数据竞争或跨线程悬垂指针。Rust 的目的不是为了解决竞争条件。然而,有些项目利用类型系统来提供某种形式的额外安全,如 rust-session 尝试使用会话类型提供协议安全。
这些特征是使用被称为“可选的内置特征”自动实现的。举个例子,如果struct Foo仅包含 Sync 字段,则它也将是 Sync,除非我们使用impl !Sync for Foo {}明确说明不实现此特征。类似的,如果struct Foo包含至少一种非 Sync 类型,则它也不会是 Sync,除非它显式指定unsafe impl Sync for Foo {}。
这意味着,Send 类型的 Sender 本身就是 Send,但非 Send 类型的 Sender 将不是 Send。这种模式非常强大。它允许在单线程上下文中使用具有非线程安全数据的通道,而无需单独的“单线程”通道抽象。
同时,像 Rc 和 RefCell 这样包含 Send/Sync 字段的结构已经明确指出退出其中的一个或多个,因为它们依赖的不变量 (invariants) 在多线程的情况下不成立。
实际上可以在编译器之外设计你自己的具有类似线程安全保证的库 - 虽然这些标记特征由编译器特别处理,但它们的工作不需要特殊处理。这里可以使用任意两个可选 (opt-in) 的内置特性。
Send 和 Sync 的含义略有不同,但是功能有交织 (intertwined) 的部分。
Send 类型可以在线程之间移动而不会有问题。它回答了“如果某个变量被移动到另一个线程,仍然可以使用吗”的问题。大多数完全拥有其包含数据的对象都符合此要求。值得注意的是,Rc 没有(因为它是共享所有权)。另一个例外是 LocalKey,它确实拥有自己的数据,但对其他线程无效。借用的数据确实有资格被发送,但在大多数情况下,由于稍后会涉及的约束,它不能跨线程发送。
即使像 RefCell 这样的类型使用非原子引用计数,它也可以在线程之间安全的发送,因为这是所有权的转移 (move)。将 RefCell 发送到另一个线程将是一个 move,并且将无法在原来的线程中使用。
另一方面,Sync 与同步访问有关。它回答了“如果多个线程都试图访问这些数据,它会安全吗?”。Mutex 等类型和其他基于lock/atomic的类型以及原始类型都实现了这一点。包含指针的结构通常不是 Sync。
Sync 有点像 Send 的拐杖 (crutch)。它有助于在涉及共享时让其他类型具有 Send 特征。例如,&T和 [Arc共享/借用 (shared/borrowed)的数据是同步安全 (synchronous-safe) 的,则可以将具有共享/借用所有权的内容发送到另一个线程。
由于非原子引用计数,RefCell 是 Send 但不是 Sync。
把它们放在一起,所有这些的看门人 (gatekeeper) 是 thread::spawn()。它有签名:
#![allow(unused)] fn main() { pub fn spawn<F, T>(f: F) -> JoinHandle<T> where F: FnOnce() -> T, F: Send + 'static, T: Send + 'static }
诚然,这令人感到困惑,部分原因是它允许返回一个值,还返回了一个句柄,我们可以从中阻塞线程连接 (thread join)。不过,我们可以为我们的需要创造一个更简单的spawnAPI:
#![allow(unused)] fn main() { pub fn spawn<F>(f: F) where F: FnOnce(), F: Send + 'static }
可以这样调用:
#![allow(unused)] fn main() { let mut x = vec![1,2,3,4]; // `move` instructs the closure to move out of its environment thread::spawn(move || { x.push(1); }); // x is not accessible here since it was moved }
spawn() 将接受一个将被调用一次的可调用对象(通常是一个闭包),并包含 Send 和'static的数据。这里,'static只是意味着闭包中不包含借用的数据。这是前面提到的阻止跨线程共享借用数据的约束。如果没有它,我们将能够将借用的指针发送到一个线程,该线程很容易超过借用时间,从而导致安全问题。
这里有一个关于闭包的细微差别 - 闭包可以捕获外部变量,但默认情况下它们是通过引用进行的(因此有move关键字)。它们根据捕获子句自动实现 Send 和 Sync。有关它们内部的更多信息,请参阅 huon 的博客。在这种情况下,x将被捕获;即作为 Vec<T> (而不是类似于&Vec<T>或其他东西),所以闭包本身可以是 Send。如果没有move关键字,闭包就不会是'static,因为它包含借用的内容。
由于闭包继承了其捕获数据的Send/Sync/'static,捕获正确类型数据的闭包将满足F: Send + 'static边界。
此函数允许和不允许的一些示例(对于x类型):
Vec<T>,Box<T>是允许的,因为它们是 Send 和'static(当内部类型是相同类型时)。&T是不允许的,因为它不是'static的。这很棒,因为借用应该有一个静态已知的生命周期。将借用的指针发送到其他线程可能会导致释放后使用,或者以其他方式破坏别名规则 (aliasing rules)。Rc<T>不是 Send,所以是不允许的。我们可能会有其他一些Rc<T>闲置,并最终导致引用计数上的数据竞争。Arc<Vec<u32>>是允许的(如果内部类型Vec<T>是 Send 和 Sync);我们不能在这里造成安全违规。迭代器失效需要可变性,而Arc<T>默认不提供。Arc<Cell<T>>是不允许的。Cell<T>提供基于复制的内部可变性,并且不是Sync(因此Arc<Cell<T>>不是 Send)。如果允许这样做,我们可能会遇到较大的结构同时从不同的线程写入的情况,从而导致两者随机混杂,即数据竞争。Arc<Mutex<T>>或Arc<RwLock<T>>是允许的(对于Send T)。内部类型使用线程安全锁并提供基于锁的内部可变性。它们可以保证在任何时间点只有一个线程正在写入。因此,互斥体 (mutex) 是 Sync,只要其内部 T 是 Send 即可,Sync 类型可以与 Arc 等包装器安全的共享。从内部类型的角度来看,它一次只能被一个线程访问 (RwLock 的情况稍微复杂一点),因此不需要知道所涉及的线程。当涉及这些 Sync 类型时,就不会出现数据竞争。
如上所述,你实际上可以创建一对非 Send 对象的Sender/Receiver。这听起来有点违反直觉 (counterintuitive) - 我们不是应该只发送Send的值吗?但是 Sender<T> 仅当T为 Send 时才为 Send;所以即使我们可以使用非 Send 类型的 Sender,我们也不能将它发送到另一个线程,因此它不能用于破坏线程安全。
还有一种方法可以讲&T的 Send 用于某些Sync T,即 thread::scoped。这个函数没有'static边界,但它有一个RAII保护,它在借用结束之前强制 join。这使得不需要互斥体 (Mutex) 就可以轻松的实现 fork-join 并行性。可悲的是,当这与 Rc 循环交互时会出现问题,因此该 API 目前不稳定,将会重新设计。这不是语言设计或 Send/Sync 设计的问题,而是库中小设计的不一致导致的完美风暴。
无需 fork Clippy 就可以编写 Rust lints

本文主要介绍 Dylint,它是一个可以从动态库中加载 Rust lints 规则的工具。Dylint 可以让开发人员轻松维护自己的个人 lint 集合。
在此之前,编写一个新的 Rust lint 的最简单的方式就是 fork Clippy,它是 Rust 事实上的 (de facto) lint 工具。但是这种方式在运行或维护新 lint 时存在缺陷 (drawback)。Dylint 最大程度的减少了这方面的干扰 (distraction),让开发者可以专注于编写 lint。
首先,我们将回顾 (go over) Rust linting 的当前状态以及 Clippy 的工作原理。然后,我们将解释 Dylint 是如何改善现状 (quo) 并提供一些关于如何开始使用它的提示。如果你想直接编写 lint,请跳到最后一节。
Rust linting 和 Clippy
Clippy 等工具利用了 Rust 编译器对 linting 的专用支持。Rust linter 的核心组件(即“驱动程序”)可以链接到对应的库 (rustc_driver) 中。通过这种方式,驱动程序本质上是对 Rust 编译器做了封装。
为了运行 linter,环境变量 RUSTC_WORKSPACE_WRAPPER 需要指向驱动程序并运行cargo check。Cargo 会注意到该环境变量已被赋值并调用该驱动程序,而不是调用 rustc。当驱动程序被调用时,它在 Rust 编译器中的 Config 结构体中设置了一个 callback。该 callback 注册了一些 lint,它们将会与 Rust 内置的 lint 一起运行。
Clippy 执行一些检查以确保它已被启用,否则将以上述方式进行工作。(关于 Clippy 架构,请参阅图 1)。尽管它在安装之后人们对它的认识依旧不是那么的清晰,但是 Clippy 实际上有两个二进制文件:一个 Cargo 命令以及一个 rustc 驱动。你可以输入以下命令进行验证:
which cargo-clippy
which clippy-driver
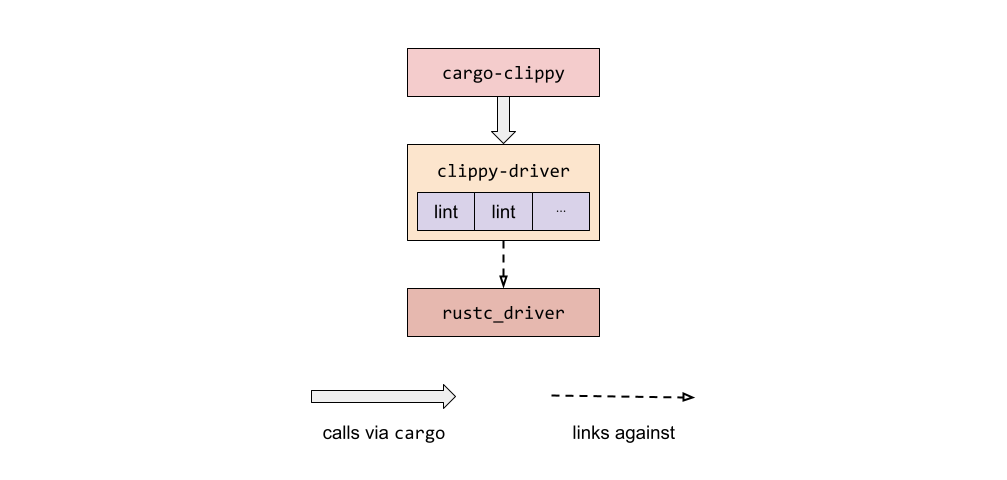
现在假设你想编写自己的 lint。你该怎么办?你需要一个驱动程序来运行它们,而 Clippy 有一个驱动程序,因此 fork Clippy 看起来是一个合理的步骤。但是这个解决方案有一些缺陷,即 (namely) 运行和维护你将开发的 lint。
首先,你的 fork 将拥有两个二进制文件的副本,确保它们可以被找到是一件很麻烦 (hassle) 的事情。你必须确保至少 cargo 命令在你的PATH中,并且你可能必须将二进制文件重命名,以保证它们不会干扰 Clippy。虽然这些问题不是难以克服 (insurmountable),但你可能会选择尽量避免它们。
其次,所有的 lint (包括 Clippy 的 lint) 都是在 unstable 编译器 API 之上构建的。一起编译的 lint 必须使用相同版本的 API。为了理解为什么会出现这个问题,我们将参考 clippy_utils - Clippy 作者慷慨地公开的一组实用程序。请注意,clippy_utils 使用与 lint 相同的编译器 API,并且同样不提供稳定性保证(参见下文)。
假设你已经 fork Clippy,然后你希望添加一个新的 lint。很显然,你希望新的 lint 使用最新版本 clippy_utils。但是假设 clippy_utils 使用的编译器版本是 B,而你 fork 的 Clippy 使用的编译器版本是 A。然后你将面临一个困境 (dilemma):你应该使用一个旧版本的 clippy_utils (使用的 A 版本的编译器)还是将 fork 中所有 lint 更新到 B 版本的编译器?两者都不是理想的选择。
Dylint 同时解决了这两个问题。首先,它提供了一个 Cargo 命令,使你不必管理多个这样的命令。其次,对于 Dylint,lint 是在一起编译的以生成动态库。因此在上述情况下,你可以简单地将新的 lint 存储在使用B 版本的编译器的新动态库中。你可以根据需要将这个新库与现有库一起使用,如果你愿意的话,可以将现有库升级到更新的库的编译器版本。
Dylint 提供了与重用中间编译结果相关的额外好处。要理解它,我们需要了解 Dylint 的工作原理。
Dylint 的工作原理
和 Clippy 一样,Dylint 提供了一个 cargo 命令。可以指定用户想要加载 lint 的动态库。Dylint 以确保在将控制权移交给 Rust 编译器之前注册 lint 的方式运行cargo check。
然而,Dylint 的 lint 注册过程比 Clippy 更复杂。Clippy 的所有 lint 都使用相同的编译器版本,因此只需要一个驱动程序。但是 Dylint 用户可以选择从不同编译器版本的库中加载 lint。
Dylint 按需即时 (on-the-fly) 构建驱动程序来处理此类情况。换句话说,如果用户想要 A 版本的编译器库中加载 lint,并且找不到 A 版本的驱动程序,Dylint 将构建一个新的 A 版本的驱动程序。驱动程序缓存在用户的主目录中,因此仅在必要时重建它们。
这给我们带来了上面暗指 (alluded to) 的额外好处。Dylint 根据它们使用的编译器版本对库进行分组,使用相同编译器版本的库一起加载,并在它们的 lint 一起运行。这允许在 lint 之间共享中间编译结果(如:符号解析,类型检查,特征求解等)。
举个例子,在图 2 中,如果库 U 和 V 都使用了 A 版本的编译器,这两个库将被放到同一个分组中。A 版本编译器的驱动程序将只被调用一次。驱动程序在将控制权移交给 Rust 编译器之前会在库 U 和库 V 中注册 lint。
为了理解为什么这种方式更好,可以做如下思考。假设 lint 由编译器驱动程序(而不是动态库)直接存储,并回顾一下驱动程序本质上是 Rust 编译器的封装。因此,如果在使用相同编译器版本的两个编译器的驱动程序中有两个 lint,则在同一代码上运行这两个驱动程序将等同于该代码进行了两次编译。通过将 lint 存储在动态库中并按照编译器版本对它们进行分组,Dylint 避免了这些低效的操作。
应用:特定项目的 lint
你是否知道 Clippy 包含 lint,其唯一目的是对 Clippy 的代码进行 lint?这是真的。Clippy 包含用于检查的 lint,例如:每个 lint 都有一个关联的 LintPass,它使用某些 Clippy 封装函数而不是它们自己封装的函数,并且每个 lint 都有一个非默认的描述。将这些 lint 应用于 Clippy 以外的代码是没有意义的。但是没有规定所有 lint 都必须是通用的,Clippy 就利用了这一点。
Dylint 包含 lint 的主要目的是对 Dylint 的代码进行 lint。例如:在开发 Dylint 时,我们发现自己编写了如下代码:
#![allow(unused)] fn main() { let rustup_toolchain = std::env::var("RUSTUP_TOOLCHAIN")?; ... std::env::remove_var("RUSTUP_TOOLCHAIN"); }
这么做不是很好。为什么?因为我们对字符串字面量进行 fat-fingered 只是时间问题。
#![allow(unused)] fn main() { std::env::remove_var("RUSTUP_TOOLCHIAN"); // Oops }
更好的方法是使用常量而不是字符串字面量,就如下代码所示:
#![allow(unused)] fn main() { const RUSTUP_TOOLCHAIN: &str = "RUSTUP_TOOLCHAIN"; ... std::env::remove_var(RUSTUP_TOOLCHAIN); }
因此当使用 Dylint 时,我们编写了一个 lint 来检查这种不适当的做法并提出适当的建议。我们将该 lint 应用到 Dylint 源码。lint 称其为 env_literal,其当前的核心实现如下:
#![allow(unused)] fn main() { impl<'tcx> LateLintPass<'tcx> for EnvLiteral { fn check_expr(&mut self, cx: &LateContext<'tcx>, expr: &Expr<'_>) { if_chain! { if let ExprKind::Call(callee, args) = expr.kind; if is_expr_path_def_path(cx, callee, &REMOVE_VAR) || is_expr_path_def_path(cx, callee, &SET_VAR) || is_expr_path_def_path(cx, callee, &VAR); if !args.is_empty(); if let ExprKind::Lit(lit) = &args[0].kind; if let LitKind::Str(symbol, _) = lit.node; let ident = symbol.to_ident_string(); if is_upper_snake_case(&ident); then { span_lint_and_help( cx, ENV_LITERAL, args[0].span, "referring to an environment variable with a string literal is error prone", None, &format!("define a constant `{}` and use that instead", ident), ); } } } } }
以下是它可以产生的警告示例:
warning: referring to an environment variable with a string literal is error prone
--> src/main.rs:2:27
|
2 | let _ = std::env::var("RUSTFLAGS");
| ^^^^^^^^^^^
|
= note: `#[warn(env_literal)]` on by default
= help: define a constant `RUSTFLAGS` and use that instead
回顾之前所说的,编译器以及 clippy_utils 都没有为它的 API 提供稳定性保证,因此 env_literal 的未来版本可能看起来有点不同。(实际上,当本文还在撰写的过程中,clippy_utils 某个 API 的变更就已经导致 env_literal 某个实现发生改变!)。当前版本的 env_literal 总是可以在 Dylint 仓库中的 examples 目录下找到。
但是 Clippy “自我 lint” 的方式与 Dylint 略有不同。Clippy 的内部 lint 被编译成启用了特定功能的 Clippy 版本。但是对于 Dylint,env_literal lint 被编译成了一个动态库。因此,env_literal 不是 Dylint 的一部分。它本质上是输入。
为什么这很重要?因为你可以为你的项目编写自定义 lint 并使用 Dylint 来运行它们,就像 Dylint 运行自己的 lint 一样。在 Dylint 仓库中 Dylint 运行的 lint 来源没有任何重要意义。Dylint 可以很轻易的在你的仓库中运行该仓库的 lint。
最重要的是 (The bottom line is this):如果你发现不喜欢自己编写的代码,并且可以使用 lint 检测该代码,Dylint 可以帮助你清除该代码并防止重新引入。
开始 linting
使用以下命令安装 Dylint:
cargo install cargo-dylint
我们还推荐安装 dylint-link 来处理超链接:
cargo install dylint-link
编写 Dylint 库的最简单的方式是 fork dylint-template 仓库。该仓库直接生成了一个可加载的库。你可以按如下方法进行验证:
git clone https://github.com/trailofbits/dylint-template
cd dylint-template
cargo build
cargo dylint fill_me_in --list
你只需实现 LateLintPass 特征并容纳要求填写的符号即可。
以下资源对你编写 lint 将很有帮助:
- 添加一个新的 lint (针对 Clippy 但依然很有用)
- 编写 lint 的常用工具
- rustc_hir 文档
也可以考虑使用上面提到的 clippy_utils。它包含许多底层任务的功能,如查找符号和打印诊断信息,可以让编写 lint 变得更加容易。
我们十分感谢 Clippy 作者将 clippy_utils 开放在 Rust 社区。我们也十分感谢 Philipp Krones 在本文的早期版本中提供了有用的建议。
使用 Mio 编写底层 TCP 服务器
是时候认识 (acquainted) 一下 Metal IO 了,它是在 epoll/kqueue 之上用 Rust 编写的跨平台抽象。
在本文中,我们将会展示并解释如何编写一个单线程异步 TCP 服务器,用它模拟 HTTP 协议,然后使用ab/wrk对其进行 benchmark。结果将会令人印象深刻。
Getting started
我使用的是mio = "0.6"。
首先,需要 TCP listener。
#![allow(unused)] fn main() { let address = "0.0.0.0:8080"; let listener = TcpListener::bind(&address.parse().unwrap()).unwrap(); }
然后创建Poll对象并将 listener 注册到Token(0)中用于可读事件 (readable events),由 edge (而不是 level) 激活。更多内容请参阅 edge vs level。
#![allow(unused)] fn main() { let poll = Poll::new().unwrap(); poll.register( &listener, Token(0), Ready::readable(), PollOpt::edge()).unwrap(); }
下一步我们要做的就是根据给定的容量创建Events对象以及主循环(本例中是无限循环)。在循环中,事件被一一轮询并处理。
#![allow(unused)] fn main() { let mut events = Events::with_capacity(1024); loop { poll.poll(&mut events, None).unwrap(); for event in &events { // handle the event } } }
Accepting connections (and dropping them)
事件可以是以下其中一种:
- listener 上的可读事件意味着有要准备接入的连接。
- 已连接的 socket 上的事件
- readable - socket 有数据可以读取
- writable - socket 已经写数据就绪
listener 以及 socket 事件可以被 token 区分,对于 listener token 它总是 0,因为它已在Poll中注册。
以下代码是最简单的事件处理方式,在循环中接受所有的传入连接,并且对于每个连接 - 只需删除 socket。它将会关闭连接。在你的服务中抛弃协议。
#![allow(unused)] fn main() { // handle the event match event.token() { Token(0) => { loop { match listener.accept() { Ok((socket, address)) => { // What to do with the connection? // One option is to simply drop it! println!("Got connection from {}", address); }, Err(ref e) if e.kind() == io::ErrorKind::WouldBlock => // No more connections ready to be accepted break, Err(e) => panic!("Unexpected error: {}", e) } } }, _ => () // Ignore all other tokens } }
listener 的.accept()方法返回std::io::Result<(TcpStream, SocketAddr)>(见 accept),因此我需要匹配并处理成功的响应或者错误。这里有一个特定的错误类型 io::ErrorKind::WouldBlock,它表示“我将等待(阻塞)以取得任何进展”。这是非阻塞 (non-blocking) 行为的本质 - 关键是不要阻塞(而是返回相应的错误)!遇到此类错误时,意味着此时没有更多的传入连接等待接入,因此循环中断,并处理下一个事件。
现在如果我运行服务器并尝试和它建立连接,我可以看到正在抛弃协议!是不是很神奇?
<span class="katex"><span class="katex-html" aria-hidden="true"><span class="base"><span class="strut" style="height:0.64444em;vertical-align:0em;"></span><span class="mord mathnormal">n</span><span class="mord mathnormal">c</span><span class="mord">127.0.0.18080</span></span></span></span>
Registering connections for events
接着说下一个事件。为了发生下一个事件,首先必须使用Poll注册 token-socket 对。在底层 (under the hook),Poll将会跟踪哪一个 token 对应哪一个 socket,但是客户端代码只能访问 token。这意味着如果服务器打算与客户端进行实际通信(我很确信大多数服务器都这样做),就必须以某种方式存储 token-socket 对。在本例中,我使用了简单的HashMap<Token, TcpStream>,但是使用 slab 可能会更加高效。
token 只是usize的一个封装器,因此简单的计数器就足以提供递增的 token 序列。一旦使用相应的 token 注册了 socket,它就会被插入到HashMap中。
#![allow(unused)] fn main() { let mut counter: usize = 0; let mut sockets: HashMap<Token, TcpStream> = HashMap::new(); // handle the event match event.token() { Token(0) => { loop { match listener.accept() { Ok((socket, _)) => { counter += 1; let token = Token(counter); // Register for readable events poll.register(&socket, token Ready::readable(), PollOpt::edge()).unwrap(); sockets.insert(token, socket); }, Err(ref e) if e.kind() == io::ErrorKind::WouldBlock => // No more connections ready to be accepted break, Err(e) => panic!("Unexpected error: {}", e) } } }, token if event.readiness().is_readable() => { // Socket associated with token is ready for reading data from it } } }
Reading data from client
当给定 token 发生可读事件时,意味着数据在相应的 socket 中读就绪。我将只使用字节数组作为读取数据的缓冲区。
在循环中执行读取操作,直到返回已知的WouldBlock错误。每次调用read将返回(如果成功的话)实际读取的字节数,当读取的字节数为 0 时 - 意味着客户端已经断开连接,此后保持 socket (或继续循环读取)没有意义。
#![allow(unused)] fn main() { // Fixed size buffer for reading/writing to/from sockets let mut buffer = [0 as u8; 1024]; ... token if event.readiness().is_readable() => { loop { let read = sockets.get_mut(token).unwrap().read(&mut buffer); match read { Ok(0) => { // Successful read of zero bytes means connection is closed sockets.remove(token); break; }, Ok(len) => { // Now do something with &buffer[0..len] println!("Read {} bytes for token {}", len, token.0); }, Err(ref e) if e.kind() == io::ErrorKind::WouldBlock => break, Err(e) => panic!("Unexpected error: {}", e) } } } ... }
Writing data to the client
对于接收可写事件的 token,它必须先在Poll中注册。oneshot选项对于安排可写事件可能很有用,该选项确保感兴趣的 (interest) 事件只被触发一次。
#![allow(unused)] fn main() { poll.register(&socket, token Ready::writable(), PollOpt::edge() | PollOpt::oneshot()).unwrap(); }
向客户端 socket 写入数据与之类似,也是通过缓冲区完成的,但是不需要显式循环,因为已经有一个方法在执行循环:write_all()。
如果我想让协议返回接收到的字节数,我将需要写入的实际字节数(HashMap将会做这件事),在发生可读事件时计算字节数,然后安排一次可写事件,以及何时发生可写事件 - 然后发送响应并断开连接。
#![allow(unused)] fn main() { let mut response: HashMap<Token, usize> = HashMap::new(); ... token if event.readiness().is_readable() => { let mut bytes_read: usize = 0; loop { ... // sum up number of bytes received } response.insert(token, bytes_read); // re-register for one-shot writable event } ... token if event.readiness().is_writable() => { let n_bytes = response[&token]; let message = format!("Received {} bytes\n", n_bytes); sockets.get_mut(&token).unwrap().write_all(message.as_bytes()).unwrap(); response.remove(&token); sockets.remove(&token); // Drop the connection }, }
What happens between reading and writing data?
此时我已经从 socket 上读取了数据,并且将数据写入 socket 中。但是写入事件永远也不会发生,因为没有为可写事件注册 token!
我应该什么时候为可写事件注册 token?好吧,当它有东西要写入的时候(进行注册)!听起来很简单,不是吗?在实践中,这意味着要真正实现一些协议了。
How do I implement a protocol?
我只想发回文本(或 JSON),而 TCP 是一种协议,一种传输级的传输控制协议。TCP 关心接收方以发送方发送的确切顺序来接收确切数量的字节!所以在传输级别,我必须处理两个字节流:一个从客户端到服务端,另一个直接返回。
与服务器打交道时应用层协议会很有用(如 HTTP)。应用层协议可以定义实体,如request - 服务器从客户端接收,以及response - 客户端从服务器接收回来。
值得一提的是,正确实现 HTTP 并不像听起来那么容易。但是已经有现成的 HTTP 库可供使用(如 hyper)。在这里,我不会为如何实现 HTTP 而烦恼,我要做的是让我的服务器表现的好像它真的理解 GET 请求,但总会用包含 6 个字节的响应来应答这样的请求:b"hello \n"。
Mocking HTTP
对于本文而言,mock HTTP 已经绰绰有余。我将把 HTTP 请求头与请求体(如果有的话)用 4 个字节b"\r\n\r\n"进行分割。因此,如果我跟踪当前客户端发送的内容,并且在任何时候那里都有 4 个字节,我就可以使用预定义的 HTTP 响应进行应答:
HTTP/1.1 200 OK
Content-Type: text/html
Connection: keep-alive
Content-Length: 6
hello
HashMap就已经足够用于跟踪所有接收到的字节。
#![allow(unused)] fn main() { let mut requests: HashMap<Token, Vec<u8>> = HashMap::new(); }
一旦读取结束,就需要检查请求是否已就绪:
#![allow(unused)] fn main() { fn is_double_crnl(window: &[u8]) -> bool { /* trivial */ } let ready = requests.get(&token).unwrap() .windows(4) .find(|window| is_double_crnl(*window)) .is_some(); }
如果已就绪,则可以安排一些数据写入!
#![allow(unused)] fn main() { if ready { let socket = sockets.get(&token).unwrap(); poll.reregister( socket, token, Ready::writable(), PollOpt::edge() | PollOpt::oneshot()).unwrap(); } }
写入完成之后,重要的是要保持连接打开,并重新注册 socket 以再次读取。
#![allow(unused)] fn main() { poll.reregister( sockets.get(&token).unwrap(), token, Ready::readable(), PollOpt::edge()).unwrap(); }
服务器已就绪!
<span class="katex"><span class="katex-html" aria-hidden="true"><span class="base"><span class="strut" style="height:0.69444em;vertical-align:0em;"></span><span class="mord mathnormal">c</span><span class="mord mathnormal">u</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal" style="margin-right:0.01968em;">ll</span><span class="mord mathnormal">oc</span><span class="mord mathnormal">a</span><span class="mord mathnormal" style="margin-right:0.01968em;">l</span><span class="mord mathnormal">h</span><span class="mord mathnormal">os</span><span class="mord mathnormal">t</span><span class="mspace" style="margin-right:0.2777777777777778em;"></span><span class="mrel">:</span><span class="mspace" style="margin-right:0.2777777777777778em;"></span></span><span class="base"><span class="strut" style="height:0.77777em;vertical-align:-0.08333em;"></span><span class="mord">8080</span><span class="mord mathnormal">h</span><span class="mord mathnormal">e</span><span class="mord mathnormal" style="margin-right:0.01968em;">ll</span><span class="mord mathnormal">o</span><span class="mord">‘‘‘</span><span class="mord cjk_fallback">好戏开始了</span><span class="mspace" style="margin-right:0.2222222222222222em;"></span><span class="mbin">−</span><span class="mspace" style="margin-right:0.2222222222222222em;"></span></span><span class="base"><span class="strut" style="height:0.77777em;vertical-align:-0.08333em;"></span><span class="mord cjk_fallback">让我们看看这个单线程服务器表现如何。我将会使用常用的工具:</span><span class="mord">‘</span><span class="mord mathnormal">ab</span><span class="mord">‘</span><span class="mord cjk_fallback">和</span><span class="mord">‘</span><span class="mord mathnormal" style="margin-right:0.02691em;">w</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal" style="margin-right:0.03148em;">k</span><span class="mord">‘</span><span class="mord cjk_fallback">。</span><span class="mspace" style="margin-right:0.2222222222222222em;"></span><span class="mbin">−</span><span class="mspace" style="margin-right:0.2222222222222222em;"></span></span><span class="base"><span class="strut" style="height:0.77777em;vertical-align:-0.08333em;"></span><span class="mord">‘</span><span class="mord mathnormal">ab</span><span class="mord">‘</span><span class="mord cjk_fallback">需要使用</span><span class="mord">‘</span><span class="mspace" style="margin-right:0.2222222222222222em;"></span><span class="mbin">−</span><span class="mspace" style="margin-right:0.2222222222222222em;"></span></span><span class="base"><span class="strut" style="height:0.8888799999999999em;vertical-align:-0.19444em;"></span><span class="mord mathnormal" style="margin-right:0.03148em;">k</span><span class="mord">‘</span><span class="mord cjk_fallback">选项以使用</span><span class="mord">‘</span><span class="mord mathnormal" style="margin-right:0.03148em;">k</span><span class="mord mathnormal">ee</span><span class="mord mathnormal">p</span><span class="mspace" style="margin-right:0.2222222222222222em;"></span><span class="mbin">−</span><span class="mspace" style="margin-right:0.2222222222222222em;"></span></span><span class="base"><span class="strut" style="height:0.77777em;vertical-align:-0.08333em;"></span><span class="mord mathnormal">a</span><span class="mord mathnormal" style="margin-right:0.01968em;">l</span><span class="mord mathnormal">i</span><span class="mord mathnormal" style="margin-right:0.03588em;">v</span><span class="mord mathnormal">e</span><span class="mord">‘</span><span class="mord cjk_fallback">并重用已有连接。</span><span class="mspace" style="margin-right:0.2222222222222222em;"></span><span class="mbin">−</span><span class="mspace" style="margin-right:0.2222222222222222em;"></span></span><span class="base"><span class="strut" style="height:0.77777em;vertical-align:-0.08333em;"></span><span class="mord">‘</span><span class="mord mathnormal" style="margin-right:0.02691em;">w</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal" style="margin-right:0.03148em;">k</span><span class="mord">2‘</span><span class="mord cjk_fallback">实际与</span><span class="mord">‘</span><span class="mord mathnormal" style="margin-right:0.02691em;">w</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal" style="margin-right:0.03148em;">k</span><span class="mord">‘</span><span class="mord cjk_fallback">用法相同,因此需要</span><span class="mord">‘</span><span class="mspace" style="margin-right:0.2222222222222222em;"></span><span class="mbin">−</span><span class="mspace" style="margin-right:0.2222222222222222em;"></span></span><span class="base"><span class="strut" style="height:0.77777em;vertical-align:-0.08333em;"></span><span class="mord">−</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal">a</span><span class="mord mathnormal">t</span><span class="mord mathnormal">e</span><span class="mord">‘</span><span class="mord cjk_fallback">参数。</span><span class="mspace" style="margin-right:0.2222222222222222em;"></span><span class="mbin">−</span><span class="mspace" style="margin-right:0.2222222222222222em;"></span></span><span class="base"><span class="strut" style="height:1em;vertical-align:-0.25em;"></span><span class="mord">‘</span><span class="mord mathnormal">ab</span><span class="mord">/</span><span class="mord mathnormal" style="margin-right:0.02691em;">w</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal" style="margin-right:0.03148em;">k</span><span class="mord">‘</span><span class="mord cjk_fallback">运行在不同的</span><span class="mord mathnormal" style="margin-right:0.22222em;">V</span><span class="mord mathnormal" style="margin-right:0.10903em;">M</span><span class="mord cjk_fallback">上而不是在服务器上</span><span class="mopen">(</span><span class="mord cjk_fallback">但是在相同的</span><span class="mord mathnormal">re</span><span class="mord mathnormal" style="margin-right:0.03588em;">g</span><span class="mord mathnormal">i</span><span class="mord mathnormal">o</span><span class="mord mathnormal">n</span><span class="mord cjk_fallback">中</span><span class="mclose">)</span><span class="mord cjk_fallback">。以下是我在某个云提供商的实例</span><span class="mord">‘</span><span class="mord mathnormal">n</span><span class="mord">1</span><span class="mspace" style="margin-right:0.2222222222222222em;"></span><span class="mbin">−</span><span class="mspace" style="margin-right:0.2222222222222222em;"></span></span><span class="base"><span class="strut" style="height:0.77777em;vertical-align:-0.08333em;"></span><span class="mord mathnormal">s</span><span class="mord mathnormal">t</span><span class="mord mathnormal">an</span><span class="mord mathnormal">d</span><span class="mord mathnormal">a</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal">d</span><span class="mspace" style="margin-right:0.2222222222222222em;"></span><span class="mbin">−</span><span class="mspace" style="margin-right:0.2222222222222222em;"></span></span><span class="base"><span class="strut" style="height:1em;vertical-align:-0.25em;"></span><span class="mord">8</span><span class="mopen">(</span><span class="mord">8</span><span class="mord mathnormal" style="margin-right:0.03588em;">v</span><span class="mord mathnormal" style="margin-right:0.13889em;">CP</span><span class="mord mathnormal" style="margin-right:0.10903em;">U</span><span class="mord mathnormal">s</span><span class="mpunct">,</span><span class="mspace" style="margin-right:0.16666666666666666em;"></span><span class="mord">30</span><span class="mord mathnormal" style="margin-right:0.05017em;">GB</span><span class="mord mathnormal">m</span><span class="mord mathnormal">e</span><span class="mord mathnormal">m</span><span class="mord mathnormal" style="margin-right:0.03588em;">ory</span><span class="mclose">)</span><span class="mord">‘</span><span class="mord cjk_fallback">上尝试对服务器进行</span><span class="mord mathnormal">b</span><span class="mord mathnormal">e</span><span class="mord mathnormal">n</span><span class="mord mathnormal">c</span><span class="mord mathnormal">hma</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal" style="margin-right:0.03148em;">k</span><span class="mord cjk_fallback">时得到的数字:</span><span class="mord">‘‘‘</span><span class="mord mathnormal">co</span><span class="mord mathnormal">n</span><span class="mord mathnormal">so</span><span class="mord mathnormal" style="margin-right:0.01968em;">l</span><span class="mord mathnormal">e</span></span></span></span> ab -n 1000000 -c 128 -k http://instance-1:8080/
<snip>
Requests per second: 105838.76 [#/sec] (mean)
Transfer rate: 9095.52 [Kbytes/sec] received
wrk -d 60s -t 8 -c 128 --rate 150k http://instance-1:8080/
<snip>
Requests/sec: 120596.75
Transfer/sec: 10.12MB
对于单线程来说,105k 与 120k 的 rps 不算太差。
当然,这次可以当作是作弊,但只要涉及真实网络(即使在同一区域内),这就是负载下的真实服务器,这可能(或多或少)是使用单线程完成此网络速度的重要底线。
完成可运行的代码地址是:github,每一个 pull-request 由一个逻辑章节组成:
Where to go from here
扩展到多线程:从这里开始。
「转」Unsafe Rust 的取舍
在本中,我将说明您需要了解的有关unsafe Rust的所有信息。我将专注于以下几个方面来讲解。
- 有关于
unsafe Rust代码的误解 - 什么时候不使用
unsafe代码 - 处理未初始化的内存
- 不可处理的异常
- 内在机制
- 内联汇编
- 接口外部功能
- 编写
unsafe Rust代码的工具
关于unsafe Rust代码的几个误解
在解释如何以及何时使用unsafe Rust(或不使用)之前,我想先说明一些关于 Rust 中不安全代码的常见误解。
误解1:所有 Rust 代码都不安全
不是的。 区别是微妙的,但是安全的 Rust 代码不能违反安全保证,只要编译器和它所构建的不安全代码都没有任何允许这种情况发生的bug。 因此,与其他低级语言不同,在其他低级语言中,代码的安全性取决于每一行代码和编译器实现,您可以显著减少需要审核错误的攻击面。
RustBelt 项目从数学上证明,如果你有一部分安全代码和一部分不安全代码来保护它的不变量,那么只要不安全代码不允许,安全代码就不能破坏保证。
顺便说一句,不变量是一种条件,它不会被某一类型的所有方法或模块的所有函数改变。
从统计上讲,在 crates.io 上发现的 Rust 代码中,只有不到 1% 是不安全的代码-这可能不到现有代码的50%,但仍然应该是一个足够有代表性的样本-而且许多项目里没有任何不安全的代码行。
误解2:它依赖于标准库代码,其中包含许多不安全因素
是的,标准库有比普通项目更多的不安全代码,这是意料之中的,因为它提供的许多抽象不能在Safe Rust中有效地实现,或者根本不能实现。
此外,我们可以放心,标准库已经收到了更多的审查,因此比您的项目更值得信赖。
这并不是说它是完美的-毕竟,过去也发现了很多错误。 尽管如此,在验证和模糊标准库的大部分方面还是做了很好的工作,这使得所有的 Rust 代码都更加安全。
误解3:一旦我们编写了 unsafe 代码,就感觉打开了地狱之门
不是的。 Rustonomicon 仔细地列出了不安全代码授予您的额外权限,以换取您保证维护该部分代码中的安全常量。 例如,您可以:
- 取消引用原始指针
- 调用
unsafe函数(包括C函数、编译器内部函数和原始分配器) - 实现
unsafetraits - 改变静态变量
- 访问联合体内的成员
然而,即使是那些看起来可能是安全的代码,也可能会产生你应该注意的后果:
- 原始指针不能保证指向它们声称要指向的数据的有效实例,因此取消对它们的引用可能会导致空域(很可能是分段错误),或者更糟糕的是,会导致类型混乱,在这种情况下,您破坏了数据,破坏了程序的状态,可能会造成不利的影响。
- 调用
unsafe函数有使用不符合其安全要求的参数调用它们的风险,这可能会造成可利用的漏洞。 - 为未能维护其不变式的类型实现
unsafetraits 还可能导致调用方无意中导致其安全要求失败,并可能造成不利的影响。 - 在另一个线程中观察静态变量时对其进行改变可能会导致数据竞争和读取异常,这意味着读取的值不再需要与旧值或新值相关。 根据读取的类型和使用方式的不同,这也可能导致未定义的行为,可能会造成不利的影响。
- 访问联合体的字段可能会让您将数据解释为它们不表示有效实例的类型,或者观察未初始化的数据(如果类型的长度不同,一个字段可以包括另一个字段的填充),这两种情况都会导致未定义的行为和可能被利用的漏洞。
因此,尽管不安全代码并不像某些人所说的那样可怕,但需要小心安全地处理它。 然后,您可以在不安全代码的基础上编写安全代码。
误解4:只要不会有人意外地使用参数调用我的安全代码,从而导致下面的不安全代码失败,我就没问题
不是的。一旦您在不安全的代码之上提供了一个安全接口,您的代码要么无论如何都会维护安全常量,要么您的代码是不健全的。
有些人对不健全的感觉非常强烈,没有理由大发雷霆。 这仍然是一个错误,你应该公开和冷静地解决它。 如果错误可以通过更仔细的设计来解决,那就去做吧。 同时,您可以公开声明您的代码不健全,用户需要格外小心,以免违反安全常量。 如果你想出了一个合理的设计,就把所有发布的不完善的版本都撤回,并报告漏洞。
误解5:我试过运行它,它运行得很好
未定义行为的问题不在于它会直接失败。 事实上,它可能永远不会失败。 在您将代码投入生产之前,它也可能一直正常工作,在这一点上,它可能会灾难性地失败。 或者,它可能会起作用,直到黑客尝试它,并手工制作正确的输入,以破解您的不健全的代码。 现在,您的所有用户都在其PC上安装了密码勒索特洛伊木马程序。
即使多次运行它,也不能保证下一次就能正常工作。 正如哥伦比亚号航天飞机灾难所显示的那样,仅仅因为它成功了135次并不意味着它在第136次尝试中就不会失败。
但如果这只发生在内存泄漏时呢?
内存泄漏无法可靠地避免,并且本身不会对内存安全构成任何危险-尽管操作系统可能会停止您的程序,或者在您耗尽可用内存时简单地崩溃,但这在最坏的情况下会导致拒绝服务。
因此,它被认为超出了内存安全保障的范围,mem::forget成为一个安全函数。
如果您的代码依赖于一些不泄漏的值来保证安全性,那么在某些时候,泄漏可能就会发生,安全保证的损失将由您承担。
请注意,这个误解是如此常见,直到Rust1.0之后,它才最终允许安全代码泄漏。 这种不安全来源的解决方案通常是泄漏放大-在尝试不安全操作之前,泄漏所有可能由泄漏导致的可观察到的损坏状态,然后将所有东西重新组合在一起。 这样,泄漏会变得更大,有时甚至更大,但至少不会破坏内存安全。
好的,我明白了。 一旦我的项目中有一行不安全的代码,所有其他代码都必须小心,以免违反安全规则
因此,通常的做法是在模块中创建不安全的代码。 这通常不打算从外部使用,但有时它可以是公开的,因为如果人们想要承担随后的责任以换取性能(或其他东西),他们可能会在代码中使用不安全的方法。
下一步是编写另一个模块,该模块将使用前面提到的不安全代码提供安全接口。 这个模块应该是允许所有其他用例的最低抽象,如果您愿意的话,它是核心功能。 省略所有可以通过构建此安全代码来实现的内容。 这是需要仔细审核的部分。
最后,在您的安全API之上编写您想让人们使用的实际接口。 因为您处于安全的 Rust 区域,所以这段代码不需要太多关注。 如果您在核心接口实现上做得很好,编译器将维护其所有保证。
既然我们已经消除了与unsafe Rust 代码相关的误解,在进入实际代码之前,我们只有一件事要讨论。
什么时候不该用 unsafe
通常, unsafe 实际上是在追求性能的过程中使用的。但是,正如我在 How to write CRaP Rust code 中所写的那样,即使只是作为要测试的快照和作为基准进行基准测试,也应该始终运行较慢但是安全的版本。
只是因为使用 unsafe 的代码有时可以更快,并不意味着一定要这样做。合理的评估情况, 在保持原有速度或者更快的时候, 就应该继续使用 safe 版本的代码。
例如,在尝试加快 Benchmark Game 条目之一作为练习时,我想通过使用数组而不是 Vec 来减少内存分配,这需要一些不安全的代码来处理未初始化的数据。但是,事实证明改用数组的版本要比基于 Vec 的版本慢,因为这个我就没继续下去了。克里夫·比佛尔( Cliff L. Biffle )在 Benchmark Game 一书中也谈到了类似的经历。 使用 unsafe 不仅会让编译器减少对代码的安全性的保证,也减少了要做的检查,因此实际上可能会禁用某些优化以避免破坏代码。因此,在切换到 unsafe 之前,请务必先进行评估,进尽量保持 safe 的代码。
好的,让我们开始吧!
处理未初始化的内存
当 Rust 版本更新到1.0.0时,标准库有一个 unsafe 函数来获取未初始化的内存: std::mem::uninitialized (还有 std::mem::zeroed(),但是两者之间的唯一区别是 后者将返回的内存区域用0初始化)。
人们普遍认为这是个坏主意,现在该函数已经处于废弃 (deprecated) 状态,建议使用std::mem::MaybeUnit 类型代替。 未初始化的麻烦的原因是,该值可能会在恐慌 (panic)或在之前返回时隐式删除。 例如:
#![allow(unused)] fn main() { let x = std::mem::uninitialized(); this_function_may_panic(); mem::forget(x); }
如果 this_function_may_panic 函数实际上 panic 了,则x会在我们调用 forget 之前就被 drop 。但是,删除未初始化的值是未定义的行为,并且由于删除通常是隐式的,因此很难避免这种情况。因此, MaybeUninit 被设计为能够处理潜在的未初始化数据。该类型永远不会自动 drop (如 std::mem::ManuallyDrop ),编译器知道该类型可能未初始化,并且具有许多函数来正确处理未初始化的数据。
让我们回顾一下。我们可能不会调用 std::ptr::read 去读未初始化内存。我们甚至不能引用它( & 或者 &mut ),因为引用规则要求引用的值必须是引用类型的有效实例,而未初始化的数据不是这种情况(除了使用 MaybeUninit<_> ,因为这显然不需要初始化)。
因此,我们也不应该 drop,因为这会创建一个可变的引用(注意,fn drop(&mut self)) 。我们可以将其转换为其他允许储存未初始化数据的类型( 创建一个未初始化的数组还是最简洁的方法)或用 std :: ptr :: write 到从 as_mut_ptr() 方法获得的指针,又或者使用 MaybeUninit 等等。请注意,即使类型未初始化,我们也可以分配给 MaybeUninit ,因为类型不会 drop 。
举例来说,假设我们要使用一个函数创建一个值数组。数组的没有实现 Copy 或没有const 的 initializer ,或者 LLVM 由于某种原因无法优化 double 。这种时候就用 unsafe :
#![allow(unused)] fn main() { use std::mem::{MaybeUninit, transmute}; unsafe { // first part: initialize the array. This is one of the rare cases where // directly calling `assume_init` is OK, because an array of // `MaybeUninit` may contain uninitialized data. // 第一部分: 初始化这个数组。这种就是几种特殊情况之一,直接 // 调用 `assume_init` 是可行的,因为 `MaybeUninit` 可以放未初 // 始化数组 let mut array: [MaybeUninit<MyType>; 256] = MaybeUninit::uninit().assume_init(); // second part: initialize the data. This is safe because we assign // to a `MaybeUninit`, which is exempt from `drop`. // 第二部分: 初始化数据。因为 `Maybeuninit` 避免了 `drop` for (i, elem) in array.iter_mut().enumerate() { *elem = MaybeUninit::new(calculate_elem(i)); } // third part: transmute to the initialized array. This works because // `MaybeUninit<T>` is guaranteed to have the same Layout as `T`. // 第三部分: 转换成初始化过的数组。这是可行的,因为 `MaybeUninit<T>` 保证了数据填充是和 `T` 一致的 transmute::<_, [MyType; 256]>(array) } }
如果任何 calculate_elem(_) 调用失败,则将删除整个 MaybeUninits 数组。 因为 MaybeUninit 不会 drop ,所以现在所有的数据都将泄漏。
为了避免这种情况,我们应该加入额外的移动语义的部分:
#![allow(unused)] fn main() { use std::mem::{forget, MaybeUninit, transmute}; // first extra part: We need a "guard" that drops all *initialized* elements // on drop // 加入的第一个额外部分: 我们需要一个 "guard"(守护) 来销毁所有初始化过的元素 struct Guard<'a> { // a mutable ref to access the array from array: &'a mut [MaybeUninit<MyType>; 256], // the index until which all elements are initialized index: usize, // 一个可变引用允许用索引访问,使得所有元素都被初始化 } impl Drop for Guard<'_> { // drop all elements that are initialized // 销毁所有被初始化的元素 fn drop(&mut self) { for i in 0..self.index { unsafe { std::ptr::drop_in_place(self.array[i].as_mut_ptr()); } } } } unsafe { let mut array: [MaybeUninit<MyType>; 256] = MaybeUninit::uninit().assume_init(); // second extra part: here we initialize the guard. From here on, it // borrows our array mutably. All access will be done through the guard // (because the borrow checker won't let us access `array` directly // while it's mutably borrowed). // 加入的第二个额外部分: 这里我们用 `&mut array` 初始化了 `guard`。 // (当使用可变借用时,借用检查器并不让我们直接访问数组) let mut guard = Guard { array: &mut array, index: 0 }; for i in 0..256 { guard.array[guard.index] = MaybeUninit::new(calculate_elem(i)); // update the index so `drop` will include the newly created element. // 更新索引,使得包含新创建的元素 guard.index += 1; } // third extra part: forget the guard to avoid dropping the initialized // elements and also end the borrow. // 加入的第三部分: 调用 `forget` ,销毁 `guard`,防止内存泄漏 forget(guard); transmute::<_, [MyType; 256]>(array) } }
如果你认为只是为了初始化数组居然就需要这么多步骤,你是对的。同样,在这一点上,一定要衡量对性能的影响。当然不是和 Vec <MyType> 比。
无论如何,这显示了处理未初始化数据的规范方法:标志一个不变量(“在index 之前的都应该不可变 ”),对其进行维护(“写入一个元素后索引增加”),你可以从中受益——在这种情况下,panic 时也不会发生泄漏。
这种方法也适用于其他数据结构,但那里通常使用不同的不变量。例如,Vec 在 resize 操作前, 将内存拷贝一份放在后备内存里,并将长度设置为零,并在操作完成后将其恢复(发生泄漏时,泄漏的内存其实是比 vec 长度要大的)。这确保了 drop 不会用在未初始化或已经释放的内存上。
取决于不同的数据机构,这个不变量将变的晦涩难懂。例如,可以使用一个 bit set 对初始化的元素进行编码,因此需要比普通数组多八分之一的内存,但允许随机访问任意元素。在这种情况下,将是“初始化和 bit set 一一对应”。 Rust的 HashMaps 基本上是这样做的。
译者注: bit set 其实就是位示图法
不可变的转换
Rust关于引用的规则非常严格——在每个给定的时间点可以读取或写入多少变量。 但是有时候我们确实需要稍微改变规则。
为此,Rust为内部可变性提供了一种(显然得用 unsafe)类型,它可以使用 get(&self)方法从不可变的借项中获得一个可变的指针(当然不是引用)。 还有一个get_mut(&mut self) 的方法,该方法向内容返回可变的借用。
这意味着编译器将假定所有 UnsafeCell 中的内容都被引用了。 标准库在顶层提供了许多安全抽象,特别是 Cell,RefCell ,RwLock ,Mutex 和各种Atomic*类型。
译者注: Atomic* 的意思是以Atomic开头的类型 , 这是正则表达式的一种
例如,AtomicBool 的定义如下(为简洁起见删除了注释):
#![allow(unused)] fn main() { pub struct AtomicBool { v: UnsafeCell<u8>, } }
当然,该实现必须确保避免数据竞争(是指在非线程安全的情况下,多线程对同一个地址空间进行写操作),通过 LLVM 内部函数使用实际的原子操作来完成的。 我还没有检查即将到来的 Cranelift 后端的功能,但它似乎也有某种类似的实现。 同样,在直接使用 UnsafeCell 之前,请检查是否有任何 safe 的替代品可用,虽然确定 unsafe 是否会给你带来足够的性能提升(或其他好处)。
使用CPU的特有指令集
Rust的标准库在std:: arch 模块中有按CPU类型分类的固有函数。它们都被定义为 unsafe 的,主要是因为它们可能未在你的CPU上实现。 幸运的是,有一种规范的方法可以确保你在编译时或运行时拥有相应的CPU。
假设你以"标准"的方式编写了算法,看了生成的汇编,觉得编译器生成的代码不够好。是时候掏出"屠龙刀"了。 但基本上就是在 Rust 里编写汇编了(因为 arch 内部函数是和不同架构一一对应的)。 如上所述,你需要确保用户的平台和你的一致。 以下代码显示了在编译时和运行时检查 CPU是否支持的方法:
#![allow(unused)] fn main() { // compile time check 编译时检查 #[cfg(any(target_arch = "x86", target_arch = "x86_64"))] mod simd { fn calculate() -> .. { // this is a std library macro that allows us to safely access CPU // features by doing runtime detection // 这里是标准库的一个宏,通过它我们可用进行CPU的编译器检查 if is_x86_feature_detected!("avx2") { // code using avx2 intrinsics here } else if is_x86_feature_detected!("sse2") // code using sse2 intrinsics here } else { // code using no special features, using e.g. avx2 intrinsics // would be UB! } } } #[cfg(not(any(target_arch = "x86", target_arch = "x86_64")))] mod simd { // fallback code here } }
此示例仅具有针对x86和x86_64架构的专用代码,以及各种运行时检测到的CPU功能。 如果你希望程序在其他平台(例如ARM-NEON)上使用SIMD内部函数,则需要添加另一个 #[cfg] 声明。不用多说,最后你就得写上不少代码。
除了可用性之外,一些指令还要考虑内存对齐。 为了简化 bit ,内存对齐告诉我们有些地址的最后几位必须为零。 例如,一个32位值的对齐方式可能为 4 ,这意味着其地址的最后两位应为零。 请参阅库文档以获取详细信息,并参考 上一章 以获取适当的帮助。
内联汇编
假设你正在编写内核,并且需要使用堆栈指针来处理一些"奇怪"的事情,或者其他不得不需要用汇编的地方。 Rust有两个 FFI 接口:一个是C语言,另一个是汇编。 不幸的是,这既不稳定又不安全,所以你就得使用nightly 版本来编译#[feature(asm)] 和 unsafe 的块。 显然,Rust无法检查你在汇编中所做的事情。 使用内联汇编的细节不在本文讨论范围之内。 请查看 Rust Book chapter 或者 RFC text。 就本文而言,不需要你熟悉 FFI 。
与其他语言交互
假如你有非常庞大的 C 代码库,并希望将其移至 Rust,不用多说,这是一项艰巨的任务。你可以先使用外部函数接口来重写代码库的一小部分,然后逐个模块进行重写,直到整个程序都用 Rust 编写,然后你就可以扔掉C了(😀)(顺带一说 librsvg 就是这样做的)。或者在 C ++ 中使用 Rust。
无论如何,你都得在安全的,充满温暖的 Rust 世界与艰难而又无情的世界之间架起一座桥梁。既然外面的世界很危险,显然你得用 unsafe 与之交互。 首先,请确保你拥有正确的接口,以免你在调试时踩坑。 bindgen(用于从 Rust 访问 C )和cbindgen(用于从 C 访问 Rust)的工具箱就显得非常有用。 如果你从 C ( 使用C接口的C++ ) 访问 Rust,请注意对象的生命周期,并将Rust对象的生存期保留在Rust代码中-也就是说,让Rust删除它们; 而对于 C 的指针,就让 C 处理它们。众所周知,Rust 有非常特殊的管理生命周期的方法,记住你的需求。
另一方面,如果将 C((或是C++ 使用了 extern ) 包装在Rust中,则会发现 C 库通常还需要考虑数据的生命周期。一旦有了绑定,就尝试考虑类型的生命周期的问题。 unofficial patterns book 有这样一章 instructive chapter 。
如果与 C++ 交互,需要使用 cxx 。但是,请注意,与通常的 bindings generators 不同,cxx 不会用 unsafe 标记你的函数 !我在这里的看法是,绑定机制部分是在 Rust 中构建的,一部分是在 C++ 中构建的,它是否是 safe 的,这取决于你审查 C++ 的代码。你可能仍然希望将结果接口包装在一个友好的接口中,并且不会以不安全的方式被滥用。
编写 unsafe rust 的工具
正如我们所见,编写 unsafe Rust比 safe 的 Rust 需要多做许多工作,因为这样将不再依靠编译器检查。 因此,要踏上这条道路,最好先"带上"下面的这些工具:
Miri
Miri 是 Rustc 的 MIR (中级中间语言),这是 Rust 在移交给 LLVM 或者Cranelift之前用来优化程序的中间表示,是一种解释器。 你可以用 rustup 运行 rustup component add miri 安装它。 它跑在 cargo miri 上-例如,cargo miri test 将在解释器中运行测试。 Miri 采用了很多可以检测未定义行为的技术,例如访问未初始化的数据,并会指出问题所在。 但是,它只会在被执行的代码上检测未定义行为,因此不能完整的覆盖代码。
Clippy and Rust lints
Rust的官方 lints (静态分析工具) 中有很多对编写 unsafe 有帮助的 lint。 至少,missing_safety_docs棉绒将帮助您将所有不安全方法的要求记录在案。 另外,Rust编译器默认情况下不会激活所有棉绒; 致电rustc -W help将显示最新列表。
Prusti
Prusti 仍在开发中(目前在更新到最新的稳定Rust时存在一些问题,因此最新的稳定版本针对某些2018 Rust编译器),但是这个工具非常有前景,可让你在数学上验证给定特定条件的代码的安全性。
基本上,你可以用数学证明代码中某些不变量是 "真的" 保持不变的,这对于必须支持不安全代码的不变量的安全抽象是理想的。 有关更多信息,请参见用户指南。
Fuzzers
Rust Fuzz Book 列出了许多可与Rust一起使用的 Fuzzer (模糊测试器)。目前,可使用的Fuzzer 有 cargo-fuzz/libfuzzer 和 American Fuzzy Lop / afl.rs的。两者都将为的代码创建大量的测试输入,并运行它以查找触发崩溃的某种组合。
译者注: 这个地方的 Fuzzer 是安全测试里面常用的模糊测试工具, 常见的就是上文提到的AFL 。而这种随机生成的测试样例被用于保证代码覆盖率, 每当遇到 crash (崩溃的样例) 并会记录下, 提示此处可能有漏洞。
为了检测未初始化内存的使用,libdiffuzz是一个侵入式内存分配器,它将使用不同的值来初始化每个内存分配。通过运行两次代码并比较结果,可以确定未初始化内存的哪一部分是造成了问题。更不错的是,memory sanitizer 是每天更新的(tracking lssue列出了各种memory sanitizer及其在各个平台上的支持),会监测每一次对未初始化内存的读取,哪怕没有造成任何问题。
尽管从统计学上讲, Fuzzer 比普通的属性测试更有可能找到代码路径,但不能保证他们会在任何时间后找到特定的代码路径。比如说我曾经遇到的标记化函数的 bug,就是由我在互联网上的一个随机文档中发现的一个 unicode 宽的空格触发的,当在运行了数十亿个测试案例的模糊测试一周后也并未发现。Rust fuzz 在 trophy case 上展示了不少没被 Fuzzing 到的 bug。如果你找到一个同样的 bug ,请添加它。
译者注: Fuzzer 不保证100%的代码覆盖率, 因为种子是随机的
rutenspitz 是一个过程宏,非常适合对状态代码(例如数据结构)进行模型测试。模型测试意味着您拥有一个 “模型” ,即一个简单但缓慢的版本,可以对要确保的行为进行建模,然后使用它来测试不安全的实现。然后它将生成一系列操作,以测试相等关系是否成立。如果你遵循了我的上述建议,则应该已经有一个安全的实施方案可以进行测试。
Rust 中的类型强转
Rust 支持多种类型转换,它可以隐式的将一种类型转换成另一种类型。与其他支持类型转换的语言一样,Rust 在易读性与易写性之间做了权衡。虽然对于 Rust 支持类型转换的清单是否最好存在分歧,但是学习类型转换是有意义的,因为有些是惯用的 (idiomatic) Rust 代码的核心。在本文中,我将描述 Rust 支持什么样的类型转换,以及在何处应用。
说明:本文介绍的所有类型强制转换都是隐式强制转换,将简称为强转。
什么是(类型)强转
在讨论类型强转之前,最好先弄清楚它的含义。Rust 支持多种类型转换的方式。From和Into特性用于库级别的可靠 (infallible) 转换。TryFrom和TryInto用于处理易出错的类型转换。AsRef,AsMut,Borrow和ToOwned提供了更多不同类型之间库级转换。但是,这些都是显式的。要执行转换,用户必须调用相关的函数。相比之下,强转是隐式的,这些转换的隐式属性意味着它们仅在其裨益依赖于易用性时才是可用的,并且隐式类型更改造成的潜在危害最小。使用as关键字完成的转换是显式的,并且允许的显式强转 (cast) 的种类比隐式强转 (coercion) 要多。
INFO 1 ,
transmute- unsafe 转换
标准库中有一个函数std::mem::transmute,它可以将任意类型转换成其他类型。该函数是unsafe的,因为它不能保证输入类型的有效位可以表示为输出类型的有效位。确保这两种类型兼容由用户决定。有一个致力于在 Rust 中开发“safe transmute”选项的工作,可以称之为“Project Safe Transmute”。他们的工作正在进行中,目的是当讨论的转化合法时,不需要使用
unsafe版本的transmute(意味着源类型的有效位始终是目标类型中的有效位)。
有哪些类型强转 (coercion) 呢?
Rust 支持多种隐式的类型强转,尽管它们的定义都是非正式的,但是仍然需要进行一定程度的标准化。事实上,这些转换的长期规范预计将成为最终标准化过程的一部分,因为它们对于理解 Rust 的类型系统至关重要。
INFO 2,标准化编程语言
由于缺乏规范,Rust 不如 C/C++ 值得信赖的批评定期出现,在这里我要解释一下:首先,Rust 确实没有像 C/C++ 那样的规范(由国际标准组织发布和管理),但这并不意味着 Rust 完全没有标准。Rust 有一个 reference,它编纂 (codify) 了该语言的大部分预期语义。它还具有管理语言变化的 RFC 流程,以及监督 (oversee) 语言发展的团队。这些团队包括不安全代码指南工作组 (Unsafe Code Guidelines Working Group),旨在更好的指定影响 unsafe Rust 代码的语义,要求和保证。该小组开发了
miri,这是 Rust 中的 MIR (Mid-Level Internal Representation) 语言的解释器,它可以自动验证 MIR 代码是否与 Rust 语义中的“stacked borrows”模型(由 UCG WG 提出)一致。主要的 Rust 编译器也经过彻底测试,包括实验特性变更和新编译器版本的自动回归测试。rustc 有一个可用的替代实现 - mrustc,尽管它通常不供最终用户使用。在实现支持 Rust 的 GNU 编译器集合方面还有更新的工作,称为“rust-gcc”。
Ferrocene 一直在致力于获得 Rust 认证以用于关键的安全领域,包括航空电子(avionic) 和自动化行业。它由 Ferrous Systems (一家 Rust 咨询公司) 维护,其团队中包括主要的语言和社区贡献者。
最终,正式指定的挑战以及证明 Rust 的保证已经在学术中得到解决,多个项目构建了模型,包括 Patina,Oxide,RustBelt,KRust 和 K-Rust。这些工作在 Alexa White 的硕士学位论文 Towards a Complete Formal Semantics of Rust 中得到了研究和扩展,该论文是理解这些不同科研工作的一个很好的切入点。
所有这些虽然不是标准,但是提高了 Rust 的水平,使其可以达到它所保证的能力。主 Rust 编译器中存在可靠性漏洞,这些漏洞会随着时间的推移被跟踪解决。如 RFC 1122 所述,Rust 稳定性策略为修复可靠性漏洞的破坏性更改留下了一个例外。还值得注意的是,C 语言在 1972 年引入,而 C 语言标准的第一个正式非草案版本在 1989 年问世 (ANSI X3.159-1989 “编程语言 - C,” 现已撤回)。C++ 于 1985 年推出,其标准的第一个非草案版本于 1998 年发布 (ISO/IEC 14882:1998 “编程语言 — C++”)。
Rust 第一个公开版本是在 2010 年发布的,它在 2015 年 5 月 15 日对早期版本的语言进行了重大更改后,发布了 1.0 版本。从 1.0 发布之日算起,已经过去了 6 年。标准化需要时间,耐心是一种美德。
引用降级强转
引用降级强转是一种非常常见的强转操作,它可以将&mut T强转为&T。显然,这种强转总是安全的,因为不可变引用会受到更多的限制。它还允许借用检查器接受一些你可能认为不会编译或正常工作的代码。
一个引用降级强转的例子如下所示:
struct RefHolder<'a> { x: &'a i64, } impl<'a> RefHolder<'a> { fn new(x: &'a i64) -> RefHolder<'a> { RefHolder { x } } } fn print_num(y: &i64) { println!("y: {}", y); } fn main() { // Create `x` let mut x = 10; // Make sure `y` is `&mut i64`. let y = &mut x; // Package the downgraded reference into a struct. let z = RefHolder::new(y); // Print `y` downgrading it to an `&i64`. print_num(y); // Use the `z` reference again. println!("z.x: {}", z.x); }
在该例中,我们可以看到print_num函数只需要&i64,但它传入了一个&mut i64。它可以正常运行是因为引用降级强转成了一个不可变引用。这也解决了给可变借用起别名的问题。RefHolder类型的构造函数也会发生同样的情况。
请注意该强转发生的次数。这里有一个类似的无法编译的例子。
struct RefHolder<'a> { x: &'a i64, } impl<'a> RefHolder<'a> { fn new(x: &'a i64) -> RefHolder<'a> { RefHolder { x } } } fn print_num(y: &i64) { println!("y: {}", y); } fn main() { // Create `x` let mut x = 10; // Make sure `y` is `&mut i64`. let y = &mut x; // Package the downgraded reference into a struct. // //--------------------------------------------------- // NOTE: this is a _fresh_ reference now, instead of // being `y`. //--------------------------------------------------- let z = RefHolder::new(&mut x); // Print `y` and update it, downgrading it // to `&i64`. print_num(y); // Use the `z` reference again. println!("z.x: {}", z.x); }
在该例中,即使引用在函数签名中降级,借用检查器仍然观察到在同一作用域内(针对同一内存)创建了两个可变引用,这是不被允许的。
ALERT 1 引用降级往往不是你想要的
正如 pretzelhammer 的 Common Rust Lifetime Misconceptions 所述,引用降级通常是不可取的,并且可能会造成意料之外的后果。
解引用强转
下一种强转是 Rust 人体工程学 (ergonomics) 的基石 (cornerstone)。“解引用强转”是由两个特征的实现产生的强转:Deref和DerefMut。这些(特征)明确存在的目的是选择加入这种强转,让容器可以透明使用它们包含的类型(这些容器通常称为“智能指针”)。
这类特征定义如下所示:
#![allow(unused)] fn main() { pub trait Deref { type Target: ?Sized; pub fn deref(&self) -> &Self::Target; } pub trait DerefMut: Deref { pub fn deref_mut(&mut self) -> &mut Self::Target; } }
第一个特征Deref定义了一个类型,可以提供对其他“目标”类型的引用。这个目标是一个关联类型,而不是一个类型参数,因为每个“智能指针”应该只能被解引用为一种类型。如果它被定义为Deref<Target>,则任何类型都可以提供尽可能多的实现,因为它们可以提供内部类型,然后编译器根据某种机制来选择正确的内部类型。解引用强转的关键在于它们是隐式的,因此通常明确的类型注释会与解引用强转功能的好处相冲突。
DerefMut特征需要Deref作为超类型,这既可以让其访问 Target 关联类型,也可以确保Deref和DerefMut的目标类型始终一致。否则,你可能会在可变上下文中启用对一种类型的强转,而在不可变上下文中启用对另一种类型的强转。这种级别的灵活性为解引用强转增加了更多的复杂性,但没有明显的好处,因此它不可用。
这两个特征所需的方法deref和deref_mut,在实现这些特征的类型上调用方法时会被隐式调用。比如,在Box<T>上实现了Deref<Target = T>,因此可以透明地调用其包含类型的方法,这使得Box<T>比用户必须为每个操作显式访问其内容更符合人体工程学。
ASIDE 2,分配器类型
这里显式的leak函数签名包括Box的A类型参数,它是分配器 (allocator) 的类型。这是为了让 Rust 的容器对需要替代分配器的用例更友好,相对于更改整个程序的分配器,它可以做到更精细的控制。leak函数返回一个引用,其生命周期为A: 'a,它直观的表示分配器的生命周期至少与从中借用的数据一样长。否则,分配器可能会在它的引用仍然存在时被释放,从而导致悬垂引用,这会导致内存不安全。
但是,如果包含类型也想定义方法,那么在该类型上存在解引用强转也会导致潜在的歧义。鉴于此,“智能指针”通常将它们的方法作为关联函数而不是方法。如Box::leak方法,它在值不释放的情况下其进行拆箱(因此最终的释放操作留给用户),该关联方法的函数签名为fn leak<'a>(b: Box<T, A>) -> &'a mut T where A: 'a,因此它通过Box::leak(my_boxed_type)进行调用,而不是my_boxed_type.leak()。
裸指针强转
Rust 的裸指针可能会从*mut T强转为*const T。尽管通过解引用来使用这些指针是 unsafe 的,并且受制于 Rust 对指针的安全性要求(即访问永远不会悬垂或未对齐),但是这些转换是 safe Rust 的一部分(即不是为在 unsafe 上下文中使用而保留的功能)。
裸指针的强转示例如下所示:
#[derive(Debug)] struct PtrHandle { ptr: *const i32, } fn main() { let mut x = 5; let ptr = &mut x as *mut i32; // The coercion happens on this line, where // a `*mut i32` is set as the value for a field // with type `*const i32`, coercing to that type. let handle = PtrHandle { ptr }; println!("{:?}", handle); }
INFO 3 指针转换的安全性
Rust 还允许将*const T通过as转换成*mut T。
虽然允许将*const T转换为*mut T似乎让人感到惊讶,但有时这种转换是必要的。例如,FFI 代码可能会从Box::into_raw中创建一个*mut T,但只想为 API 的 C 使用者提供一个*const T。因此 FFI 接口提供的等效删除函数需要将*const T作为参数,将其转换回*mut T以将其传递给Box::from_raw,从而使 Rust 在函数结束时对Box进行释放。
虽然指针出处 (provenance) 的细节意味着这种转换并不总是未定义的行为,但如果指针的原始出处不是可变的,则它可能是未定义的行为。换句话说,如果一个值最初是*mut T类型,它可以在将来用作*mut T,即使类型在此期间 (interim) 被转换为*const T。
引用与裸指针强转
你可以将&T转换为*const T,将&mut T转换为*mut T。尽管产生的裸指针只能在 unsafe 的代码块中解引用,但是这些强转是 safe 的。
和上一个例子类似,但是这一次是将引用转换成指针而不是改变指针类型的可变性。
// Notice that these coercions work when // generic types are present too. #[derive(Debug)] struct ConstHandle<T> { ptr: *const T, } #[derive(Debug)] struct MutHandle<T> { ptr: *mut T, } fn main() { let mut x = 5; let c_handle = ConstHandle { // Coercing `&i32` into `*const i32` ptr: &x, }; let m_handle = MutHandle { // Coercing `&mut x` into `*mut i32` ptr: &mut x, }; println!("{:?}", c_handle); println!("{:?}", m_handle); }
函数指针强转
闭包是函数加上其执行的上下文。这使得它们在许多情况下非常有用,但有时它们携带的这种额外状态会阻碍 (impede) 它们的使用,特别是没有实际的状态捕获时。在 Rust 中,除了编译时生成的无名闭包类型之外,还有函数指针类型表示没有上下文环境的函数。为了使闭包尽可能灵活,,当且仅当它们不从上下文中捕获任何变量时,闭包才会强制使用指针。
一个函数指针的示例如下:
// This function takes in a function pointer, _not_ a generic type // which implements one of the function traits (`Fn`, `FnMut`, or // `FnOnce`). fn takes_func_ptr(f: fn(i32) -> i32) -> i32 { f(5) } fn main() { let my_func = |n| n + 2; // The coercion happens here, and is possible because `my_func` // doesn't capture any variables from its environment. println!("{}", takes_func_ptr(my_func)); }
请注意,在 Rust 中使用泛型实现Fn,FnMut,FnOnce特征的方式比使用函数指针要常见的多。如果你想要传递或存储从上下文中捕获的闭包,则需要使用这三种特征的其中一个。
子类型强转
令某些人惊讶的是,Rust 支持子类型强转。虽然 Rust 的类型系统通常被认为仅支持参数多态性,但实际上它也支持子类型多态性,适用于生命周期。当一个生命周期比另一个生命周期更长时,Rust 中的生命周期会彼此形成子类型关系。在这种情况下,生命周期较长的是子类型,生命周期较短的是超类型。因为在子类型多态中,任何子类型都可以代替超类型,这对于生命周期就意味着当预期的生命周期较短时,可以安全地使用较长的生命周期。
这种强转意味着允许在强转点“缩短”生命周期,因此可以使用更长的生命周期来代替函数所需的较短边界。对于 Rustacean 来说,这样做的最终结果是编译器可以接受更多的程序。
像 Rust 一样支持参数和子类型多态的语言中出现的一个共同问题是范型类型的子类型关系如何与其范型参数的子类型关系相关联。该属性称为型变 (variance)。
范型类型有三个有用的变型。它们每一个都与特定的通用类型相关;如果一个类型有多个范型参数,它将对每个参数进行单独的型变确定。
-
协变 (Covariance):对于类型
A<T>,如果T是U的子类型,则A<T>是A<U>的子类型。容器的子类型与其范型参数子类型相匹配。 -
逆变 (Contravariance):对于类型
A<T>,如果T是U的子类型,则A<U>是A<T>的子类型。容器的子类型与其范型参数的子类型互逆。 -
不变 (Invariance):对于类型
A<T>,在A<T>与A<U>之间不存在子类型关系。容器没有子类型。
在 Rust 中,由于子类型只存在于生命周期中,并且生命周期表示数据存活的时间,这就意味着:
-
协变类型的生命周期允许比预期的更长(这些生命周期允许“缩短”,这样不会有问题是因为引用的使用时间总是少于它们的有效时间)。
-
逆变类型的生命周期允许延长(就像通过要求使用
'static而不是'a的生命周期,来避免函数指针携带引用类型)。 -
不变类型没有子类型关系,需要一个既不会缩短也不会延长的生命周期。
也许一个带有子类型强转的逆变生命周期示例可以帮助理解:
struct FnHolder { f: fn(&'static str) -> i32, } fn number_for_name<'a>(name: &'a str) -> i32 { match name { "Jim" => 32, _ => 5, } } fn main() { // Voila! A subtype coercion! In this case coercing a // lifetime in a contravariant context (the lifetime in // the function pointer type parameter) from `'a` to `'static`. // // `'static` is longer than `'a`, which in this case is safe // because it's always fine to make the function _less_ accepting. // // Once it's been assigned into the `FnHolder` type, it'll only // accept string literals (which have a `'static` lifetime). let holder = FnHolder { f: number_for_name }; // The extra parentheses are part of the syntax for calling // functions as fields, to disambiguate between this and // calling a method on the `FnHolder` type. println!("{}", (holder.f)("Jim")); }
never 强转
Rust 类型系统中有一个特殊的类型 - never 类型(写作!)。此类型可以强转为其他所有类型,通常表示非终止 (non-termination)。例如,unimplemented!,unreachable!和todo!宏都返回!类型。!类型强转可以利用这些宏类型检查,如果它们在运行时中执行,则!被实现为当前线程有保证的 panic。退出当前进程的std::process::exit函数返回!也是出于相同的原因。
never 类型强转让程序可以使用 panic 或 exit 通过类型检查。
// Turn off some warnings about unreachable code. #![allow(unreachable_code)] #![allow(unused_variables)] #![allow(dead_code)] struct Value { x: bool, y: String, } fn never() -> ! { // `loop`s without some way to exit // like this have the `!` type, because // the expression (and, in this case, // the containing function) will never // terminate / return. loop {} } fn main() { let x = never(); let v = Value { x: todo!("uhhh I haven't gotten to this"), y: unimplemented!("oh, not this either"), }; // This program compiles because `never`, // `todo!`, and `unimplemented!` all return // the `!` type, which coerces into any type. }
切片强转
切片强转是指从数组到切片的转换。它们是“未知大小强转”集合(以及特征对象强转和 trailing unsized 强转)中的一部分。之所以这么称呼它们,是因为它们涉及从有大小的类型(在编译时已知大小并实现了Sized特征的类型)到未知大小的类型(在编译时不知道其类型的大小,并且没有实现 Sized特征)。在切片强转的过程中,已知大小的类型为[T; n](具有固定大小 n 的 T 数组),未知大小的类型为[T](T 数组的切片)。
切片强转发生的次数可能比你想到的还要多:
#[derive(Debug)] struct SliceHolder<'a> { slice: &'a [i32], } fn main() { let nums = [1, 2, 3, 4, 5]; // It may not look like, but there's a coercion here! // // The type of `&nums` is `&[i32; 5]`, which is coerced // into `&[i32]` to match the `slice` field on `SliceHolder`. let holder = SliceHolder { slice: &nums }; println!("{:#?}", holder); }
请注意,虽然也可以将Vec<T>强转为&[T],但它不是切片强转,而是解引用强转。由于语言的历史原因,数组无法与 const 泛型一起使用(因为 const 泛型没有实现Deref),因此需要特殊的强转将其静默转换成切片。
特征对象强转
特征对象是 Rust 的动态调度机制,并且特征对象强转的存在是为了可以轻松构建特征对象。这种强转从某种类型T转换成dyn U,其中U是被T实现的特征,并且U满足 Rust 的对象安全规则。我们之前已经讨论过对象安全规则,但要点是对象特征类型必须是可构造的(这意味着它在任何地方都不依赖在编译时不确定的泛型类型(泛型不包括关联的函数,没有引用Self的方式 - 在编译时期无法确定,并且在不包含Self: Sized边界的情况下,不包括按值获取Self的函数)。
一个函数通过特征对象强转进行调用的示例:
trait HasInt { fn get(&self) -> i32; } struct IntHolder { x: i32, } impl HasInt for IntHolder { fn get(&self) -> i32 { self.x } } fn print_int(x: &dyn HasInt) { println!("{}", x.get()); } fn main() { let holder = IntHolder { x: 5 }; // The coercion happens here, from `&IntHolder` // into `&dyn HasInt`. print_int(&holder); }
trailing unsized 强转
trailing unsized 强转意味着,如果类型T的最后一个字段是已知大小的且可以转换为未知大小的类型,并存在一个U类型,它是T类型但执行了最后一个字段的强转,那么T可以被强转为U。因为这个定义非常特殊,我们可以具体说明:
T必须是一个结构体T的字段A必须可以强转为未知大小的B类型T的最后一个字段必须包含AT的其他字段不能包含A- 如果
T最后一个字段本身就是包含A的结构体,则该结构体必须可以强转为另一种类型,该类型包含未知大小的,用来替换A的B类型。
这比最初的解释更准确。本质上,当相关字段是最后一个字段时,允许在结构体内进行有限的 unsized 强转。
最小上限强转
有时 Rust 需要同时在多个强转点进行强转,这样它们都可以变成相同的类型。例如,这可能发生在if/else表达式中,其中条件的每个分支都返回一个需要强转的类型。在这种情况下,Rust 试图找到最通用的类型,这被称为“最小上限强转”。
该强转可以被以下情况触发:
- 一系列
if/else分支 - 一系列
match分支 - 一系列数组元素
- 在闭包中的一系列
返回值 - 在函数中的一系列
返回值
执行此强转的过程是遍历每个系列中的每种类型,检查它们是否可以转换为先前确定的相同类型。如果可以,则继续。如果不能,则尝试找出一种类型C,可以将先前看到的类型A与最新的类型B都强转为类型C。最终的类型C被确定为该系列中所有表达式的类型。
传递性强转
Rust 支持传递性强转,如果类型A可以强转为类型B,并且类型B可以强转为类型C,则类型A可以强转为类型C。这个特性目前正在开发,可能不是总是有效。
哪里会发生强转
代码中发生类型强转的位置被称为“强转点 (coercion sites)”,Rust 中有多种类型的强转点。
强转点
首先是变量的声明,不管是通过let,const还是static进行声明。在这些情况下,如果在左侧显式声明变量的类型,则右侧将被强转为该类型。如果无法进行这种强转,则会发出编译器错误。
接下来是函数参数,其中实参被强转为型参的类型。在方法调用中,接收者类型(Self的类型)只能使用 unsized 强转。
然后你就可以拥有任何结构或枚举的字面量实例。这些数据类型中的字段被实例化的位置是强转点,实际类型被强转为整体数据类型声明中定义的正式类型。
强转传播的表达式
有些表达式被认为是“强转传播 (coercion propagating)”,这意味着它们会将强转检查传递给它们的子表达式。
数组字面量是强转传播的,并传播到数组字面量声明的每个元素定义中。如果与重复语法一起使用,该语法将重复给定次数的元素的初始定义。
元组在它们内部的每个单独表达式上也类似的进行强转传播。
如果表达式带有括号,则强转将传播到括号内的表达式。如果它被括号括起来,使它成为一个块,那么强转将传播到该块的最后一行。
unsized 强转和强转点
与其他强转相比,unsized 强转(上述对切片,特征对象或 trailing unsized 类型的强转)可以在一个额外的上下文中发生。具体来说,如果有一个指向类型 T 的引用,裸指针或(有所有权的)指针,其中 T 具有对类型 U 的 usized 强转,则可以通过引用或指针类型进行强转。
这意味着以下强转点仅对 unsized 强转有效:
&T到&U&mut T到&mut U*const T到*const U*mut T到*mut UBox<T>到Box<U>
这就是为什么上述切片强转的示例可以正常运行的原因!这种情况下的强转发生在引用之后,将[i32; 5]强转为[i32]。
结论
强转功能十分强大,因为它们是隐式的,有时会引起争议 (controversial)。
无论你对正确使用强转有何看法,重要的是了解什么是可能的强转,以及它们可能发生的位置。在本文中,我们命名并描述了 Rust 中所有可能的强转,并描述了哪些类型的表达式可能包含强转,以及哪些表达式可以传播强转。希望这有助于使 Rust 中这个经常被隐藏的部分变得更加清晰。
std::pin
定义:一种将数据固定在内存中的类型
描述
从对象在内存中位置不变的意义上来说,保证对象不移动有时很有用。这种情况的一个主要示例就是构建自引用结构,因为使用指向自身的指针移动对象会使他们无效,这可能导致未定义的行为。
从较高的层次来说,Pin<P>可以确保任何类型的指针P在内存中都有固定的位置,这意味着它不能被移动到其他地方,并且在删除之前不能释放其内存。当讨论将固定数据和非固定数据结合在一起组成类型时,事情将变得更加微妙。
默认情况下,Rust中所有类型都是可移动的。Rust允许按值传递类型。普通的智能指针类型(例如BoxBox<T>或者使用mem::swap。Pin<P>封装了一个指针类型P,因此Pin<Box<T>>功能和常规类型Box<T>非常相似。当Pin<Box<T>>被销毁时,其包含的内容也将被销毁,并且其占用的内存也被释放。同样的,Pin<&mut T>和&mut T非常像。但是Pin<P>不会让使用者真的去包含Box<T>或者&mut T来固定数据,这意味着不能使用mem::swap之类的操作。
#![allow(unused)] fn main() { use std::pin::Pin; fn swap_pins<T>(x: Pin<&mut T>, y: Pin<&mut T>) { // `mem::swap` needs `&mut T`, but we cannot get it. // We are stuck, we cannot swap the contents of these references. // We could use `Pin::get_unchecked_mut`, but that is unsafe for a reason: // we are not allowed to use it for moving things out of the `Pin`. } }
值得重申的是,Pin<P>不会改变Rust编译器允许所有类型都是可移动的事实。mem::swap依然可以调用任意类型T。取而代之的是,Pin<P>使调用需要&mut T的方法变得不可能来阻止一些(由Pin<P>封装的指针所指向的)值被移动(如mem::swap)。
Pin<P>可用于包装任何类型的指针P,因此他可以与Deref和DerefMut交互。Pin<P> where P: Deref应该被视为固定P::Target的P型指针。因此,Pin<Box<T>>是一个固定T的指针,Pin<Rc<T>>是固定T的指针计数器。为了确保正确性,Pin<P>依赖Deref和DerefMut的实现使其不能移出其自身参数,并且总是只返回一个指向固定数据的Pin指针。
Unpin
即使不固定,许多类型也始终可以自由移动,因为他们不依赖于具有稳定的地址。这包括所有基本类型(如bool,i32和引用类型)以及仅用这些类型组成的类型。不需要固定的类型将实现Unpin特征,从而取消了Pin<P>的影响。对于T: Unpin,Pin<Box<T>>和Box<T>的功能相同,Pin<&mut T>和&mut T的作用相同。
值得注意的是,Pin和Unpin只影响指向类型P::Target,而不影响封装在Pin<P>中的P类型本身。例如,Box<T>是否为Unpin对Pin<Box<T>>的行为没有影响
例子1: 自引用结构(self-referential struct)
在进一步解释Pin<T>之前,先讨论如何使用它的一些示例。
#![allow(unused)] fn main() { use std::pin::Pin; use std::marker::PhantomPinned; use std::ptr::NonNull; // This is a self-referential struct because the slice field points to the data field. // We cannot inform the compiler about that with a normal reference, // as this pattern cannot be described with the usual borrowing rules. // Instead we use a raw pointer, though one which is known not to be null, // as we know it's pointing at the string. struct Unmovable { data: String, slice: NonNull<String>, _pin: PhantomPinned, } impl Unmovable { // To ensure the data doesn't move when the function returns, // we place it in the heap where it will stay for the lifetime of the object, // and the only way to access it would be through a pointer to it. fn new(data: String) -> Pin<Box<Self>> { let res = Unmovable { data, // we only create the pointer once the data is in place // otherwise it will have already moved before we even started slice: NonNull::dangling(), _pin: PhantomPinned, }; let mut boxed = Box::pin(res); let slice = NonNull::from(&boxed.data); // we know this is safe because modifying a field doesn't move the whole struct unsafe { let mut_ref: Pin<&mut Self> = Pin::as_mut(&mut boxed); Pin::get_unchecked_mut(mut_ref).slice = slice; } boxed } } let unmoved = Unmovable::new("hello".to_string()); // The pointer should point to the correct location, // so long as the struct hasn't moved. // Meanwhile, we are free to move the pointer around. let mut still_unmoved = unmoved; assert_eq!(still_unmoved.slice, NonNull::from(&still_unmoved.data)); // Since our type doesn't implement Unpin, this will fail to compile: // let mut new_unmoved = Unmovable::new("world".to_string()); // std::mem::swap(&mut *still_unmoved, &mut *new_unmoved); }
例子2: 侵入式双向链表(intrusive doubly-linked list)
在侵入式双向链表中,不会真的为表中的元素分配内存空间,如何分配由使用者控制,并且元素可以分配在(比链表存活时间更短暂的)栈帧上。
双向链表中每个元素都有指针分别指向它的前驱和后继元素。只有当链表中的元素位置在内存中都是固定的才可以添加元素,因为移动一个元素可能会使指针失效。并且,链表中的元素实现Drop会在它被移除出链表时,修复指向它前驱和后继元素的指针。
至关重要的是,如果一个元素在不调用Drop::drop的情况下被释放或者以其他方式失效,则其相邻元素指向该元素的指针将变为无效,这将破坏数据结构。
因此,Pin也许附带Drop相关的保证。
Drop保证
Pin的目的是为了能够依赖内存中数据的位置。因此不仅限制了移动数据,还限制了用于存储数据的内存的重新分配。具体来说,对于固定的数据,从固定到drop被调用的那一刻之前,它的内存都不会失效或者被重新利用,只有当drop返回或者panic,该内存才可以重用。
内存可以因为被释放而“失效”,也可以用None来代替Some(v),或者调用Vec::set_len来消灭数组中的元素。可以通过ptr::write覆写来重新利用它,而无需事先调用析构函数。未经调用drop的固定数据均不允许使用这些方法。
注意这个保证并不意味着不会产生内存泄漏!你依然可以不去调用固定元素的drop方法(如:你可以对Pin<Box<T>>使用mem::forget方法),在双向列表的示例中,元素将只保存在列表中,但是如果不调用drop方法,将无法释放或重新使用内存。
Drop实现
如果你的数据类型使用Pin,在实现Drop时需要格外注意,drop函数携带&mut self参数,即使你的类型先前已经固定,也将调用该函数,好像编译器会自动调用Pin::get_unchecked_mut。
这永远不会在安全代码中引起问题,因为实现需要固定的类型需要unsafe的代码。请注意,如果在你的类型中使用Pin(如在Pin<&Self>或Pin<&mut Self>)会对Drop实现产生影响:如果你的类型中的一个元素已经被固定,你必须将Drop视为隐式获取Pin<&mut Self>。
举个例子,你可以像如下代码一样实现Drop:
#![allow(unused)] fn main() { impl Drop for Type { fn drop(&mut self) { // `new_unchecked` is okay because we know this value is never used // again after being dropped. inner_drop(unsafe { Pin::new_unchecked(self)}); fn inner_drop(this: Pin<&mut Type>) { // Actual drop code goes here. } } } }
inner_drop函数具有drop应有的类型,所以这确保你不会偶发的在这种与Pin互相矛盾的方式中使用self/this。
而且,如果你的字段被#[repr(packed)]修饰,编译器将自动移除字段。它甚至可以对恰好对齐的字段执行此操作。所以你不能将Pin和#[repr(packed)]一起使用。
投影和结构固定
在处理固定结构时,会遇到一个问题,如何访问方法中结构(Pin<&mut Struct>)的字段。通常是写辅助方法(即投影)将Pin<&mut Struct>转化成字段中的一个引用。但是该引用应该具有什么类型?是Pin<&mut Field>还是&mut Field呢?枚举字段和容器字段(Vec<T>)或者封装类型(Box<T>或RefCell<T>)也会出现相同的问题(这个问题适用于可变引用和共享引用,我们仅在此处使用可变引用的更常见情况进行说明)。
实际上,是由数据结构的作者决定是否为特殊的字段固定投影来将Pin<&mut Struct>转换为Pin<&mut Field>或者&mut Field。这里有一些限制,最大的限制就是一致性:每个字段都可以被投射到固定的引用上,或者作为投影的一部分去掉了Pin。如果同一个字段同时满足这两个条件将是有问题的。
作为数据结构的作者,你需要为每个字段决定是否需要将Pin(的影响)“传播”到这个字段上。传播中的Pin也被称为结构化,因为它遵循该类型的结构。在以下小结中,我们描述了两种选择都必须考虑的因素。
std::pin
定义:一种将数据固定在内存中的类型
描述
从对象在内存中位置不变的意义上来说,保证对象不移动有时很有用。这种情况的一个主要示例就是构建自引用结构,因为使用指向自身的指针移动对象会使他们无效,这可能导致未定义的行为。
从较高的层次来说,Pin<P>可以确保任何类型的指针P在内存中都有固定的位置,这意味着它不能被移动到其他地方,并且在删除之前不能释放其内存。当讨论将固定数据和非固定数据结合在一起组成类型时,事情将变得更加微妙。
默认情况下,Rust中所有类型都是可移动的。Rust允许按值传递类型。普通的智能指针类型(例如BoxBox<T>或者使用mem::swap。Pin<P>封装了一个指针类型P,因此Pin<Box<T>>功能和常规类型Box<T>非常相似。当Pin<Box<T>>被销毁时,其包含的内容也将被销毁,并且其占用的内存也被释放。同样的,Pin<&mut T>和&mut T非常像。但是Pin<P>不会让使用者真的去包含Box<T>或者&mut T来固定数据,这意味着不能使用mem::swap之类的操作。
#![allow(unused)] fn main() { use std::pin::Pin; fn swap_pins<T>(x: Pin<&mut T>, y: Pin<&mut T>) { // `mem::swap` needs `&mut T`, but we cannot get it. // We are stuck, we cannot swap the contents of these references. // We could use `Pin::get_unchecked_mut`, but that is unsafe for a reason: // we are not allowed to use it for moving things out of the `Pin`. } }
值得重申的是,Pin<P>不会改变Rust编译器允许所有类型都是可移动的事实。mem::swap依然可以调用任意类型T。取而代之的是,Pin<P>使调用需要&mut T的方法变得不可能来阻止一些(由Pin<P>封装的指针所指向的)值被移动(如mem::swap)。
Pin<P>可用于包装任何类型的指针P,因此他可以与Deref和DerefMut交互。Pin<P> where P: Deref应该被视为固定P::Target的P型指针。因此,Pin<Box<T>>是一个固定T的指针,Pin<Rc<T>>是固定T的指针计数器。为了确保正确性,Pin<P>依赖Deref和DerefMut的实现使其不能移出其自身参数,并且总是只返回一个指向固定数据的Pin指针。
Unpin
即使不固定,许多类型也始终可以自由移动,因为他们不依赖于具有稳定的地址。这包括所有基本类型(如bool,i32和引用类型)以及仅用这些类型组成的类型。不需要固定的类型将实现Unpin特征,从而取消了Pin<P>的影响。对于T: Unpin,Pin<Box<T>>和Box<T>的功能相同,Pin<&mut T>和&mut T的作用相同。
值得注意的是,Pin和Unpin只影响指向类型P::Target,而不影响封装在Pin<P>中的P类型本身。例如,Box<T>是否为Unpin对Pin<Box<T>>的行为没有影响
例子1: 自引用结构(self-referential struct)
在进一步解释Pin<T>之前,先讨论如何使用它的一些示例。
#![allow(unused)] fn main() { use std::pin::Pin; use std::marker::PhantomPinned; use std::ptr::NonNull; // This is a self-referential struct because the slice field points to the data field. // We cannot inform the compiler about that with a normal reference, // as this pattern cannot be described with the usual borrowing rules. // Instead we use a raw pointer, though one which is known not to be null, // as we know it's pointing at the string. struct Unmovable { data: String, slice: NonNull<String>, _pin: PhantomPinned, } impl Unmovable { // To ensure the data doesn't move when the function returns, // we place it in the heap where it will stay for the lifetime of the object, // and the only way to access it would be through a pointer to it. fn new(data: String) -> Pin<Box<Self>> { let res = Unmovable { data, // we only create the pointer once the data is in place // otherwise it will have already moved before we even started slice: NonNull::dangling(), _pin: PhantomPinned, }; let mut boxed = Box::pin(res); let slice = NonNull::from(&boxed.data); // we know this is safe because modifying a field doesn't move the whole struct unsafe { let mut_ref: Pin<&mut Self> = Pin::as_mut(&mut boxed); Pin::get_unchecked_mut(mut_ref).slice = slice; } boxed } } let unmoved = Unmovable::new("hello".to_string()); // The pointer should point to the correct location, // so long as the struct hasn't moved. // Meanwhile, we are free to move the pointer around. let mut still_unmoved = unmoved; assert_eq!(still_unmoved.slice, NonNull::from(&still_unmoved.data)); // Since our type doesn't implement Unpin, this will fail to compile: // let mut new_unmoved = Unmovable::new("world".to_string()); // std::mem::swap(&mut *still_unmoved, &mut *new_unmoved); }
例子2: 侵入式双向链表(intrusive doubly-linked list)
在侵入式双向链表中,不会真的为表中的元素分配内存空间,如何分配由使用者控制,并且元素可以分配在(比链表存活时间更短暂的)栈帧上。
双向链表中每个元素都有指针分别指向它的前驱和后继元素。只有当链表中的元素位置在内存中都是固定的才可以添加元素,因为移动一个元素可能会使指针失效。并且,链表中的元素实现Drop会在它被移除出链表时,修复指向它前驱和后继元素的指针。
至关重要的是,如果一个元素在不调用Drop::drop的情况下被释放或者以其他方式失效,则其相邻元素指向该元素的指针将变为无效,这将破坏数据结构。
因此,Pin也许附带Drop相关的保证。
Drop保证
Pin的目的是为了能够依赖内存中数据的位置。因此不仅限制了移动数据,还限制了用于存储数据的内存的重新分配。具体来说,对于固定的数据,从固定到drop被调用的那一刻之前,它的内存都不会失效或者被重新利用,只有当drop返回或者panic,该内存才可以重用。
内存可以因为被释放而“失效”,也可以用None来代替Some(v),或者调用Vec::set_len来消灭数组中的元素。可以通过ptr::write覆写来重新利用它,而无需事先调用析构函数。未经调用drop的固定数据均不允许使用这些方法。
注意这个保证并不意味着不会产生内存泄漏!你依然可以不去调用固定元素的drop方法(如:你可以对Pin<Box<T>>使用mem::forget方法),在双向列表的示例中,元素将只保存在列表中,但是如果不调用drop方法,将无法释放或重新使用内存。
Drop实现
如果你的数据类型使用Pin,在实现Drop时需要格外注意,drop函数携带&mut self参数,即使你的类型先前已经固定,也将调用该函数,好像编译器会自动调用Pin::get_unchecked_mut。
这永远不会在安全代码中引起问题,因为实现需要固定的类型需要unsafe的代码。请注意,如果在你的类型中使用Pin(如在Pin<&Self>或Pin<&mut Self>)会对Drop实现产生影响:如果你的类型中的一个元素已经被固定,你必须将Drop视为隐式获取Pin<&mut Self>。
举个例子,你可以像如下代码一样实现Drop:
#![allow(unused)] fn main() { impl Drop for Type { fn drop(&mut self) { // `new_unchecked` is okay because we know this value is never used // again after being dropped. inner_drop(unsafe { Pin::new_unchecked(self)}); fn inner_drop(this: Pin<&mut Type>) { // Actual drop code goes here. } } } }
inner_drop函数具有drop应有的类型,所以这确保你不会偶发的在这种与Pin互相矛盾的方式中使用self/this。
而且,如果你的字段被#[repr(packed)]修饰,编译器将自动移除字段。它甚至可以对恰好对齐的字段执行此操作。所以你不能将Pin和#[repr(packed)]一起使用。
投影和结构固定
在处理固定结构时,会遇到一个问题,如何访问方法中结构(Pin<&mut Struct>)的字段。通常是写辅助方法(即投影)将Pin<&mut Struct>转化成字段中的一个引用。但是该引用应该具有什么类型?是Pin<&mut Field>还是&mut Field呢?枚举字段和容器字段(Vec<T>)或者封装类型(Box<T>或RefCell<T>)也会出现相同的问题(这个问题适用于可变引用和共享引用,我们仅在此处使用可变引用的更常见情况进行说明)。
实际上,是由数据结构的作者决定是否为特殊的字段固定投影来将Pin<&mut Struct>转换为Pin<&mut Field>或者&mut Field。这里有一些限制,最大的限制就是一致性:每个字段都可以被投射到固定的引用上,或者作为投影的一部分去掉了Pin。如果同一个字段同时满足这两个条件将是有问题的。
作为数据结构的作者,你需要为每个字段决定是否需要将Pin(的影响)“传播”到这个字段上。传播中的Pin也被称为结构化,因为它遵循该类型的结构。在以下小结中,我们描述了两种选择都必须考虑的因素。
std::sync::Condvar
定义:一种条件变量
描述
条件变量代表阻塞线程的能力,以使线程在等待时间发生时不占用CPU时间。条件变量通常与布尔谓词(predicate)和互斥锁相关联,在验证线程必须阻塞之前,始终在互斥对象内部验证该谓词。
该模块中的函数将阻止当前执行的线程,并在可能的情况下绑定系统提供的条件变量。请注意,此模块对系统条件变量又一个附加限制:每一个Condvar在运行时可以与一个Mutex一起使用。任何在同一条件变量上使用多个互斥锁的尝试都将引起运行时panic。如果不希望这样,在sys中的unsafe原语将没有这种限制,但是可能会导致为定义的行为。
#![allow(unused)] fn main() { use std::sync::{Arc, Mutex, Condvar}; use std::thread; let pair = Arc::new((Mutex::new(false), Condvar::new())); let pair2 = pair.clone(); // Inside of our lock, spawn a new thread, and then wait for it to start. thread::spawn(move|| { let (lock, cvar) = &*pair2; let mut started = lock.lock().unwrap(); *started = true; // We notify the condvar that the value has changed. println!("111"); cvar.notify_one(); }); // Wait for the thread to start up. let (lock, cvar) = &*pair; let mut started = lock.lock().unwrap(); println!("222"); while !*started { println!("333"); started = cvar.wait(started).unwrap(); println!("444"); } }
输出
222
333
111
444
实现
impl Condvar
pub fn new() -> Condvar
创建一个新的条件变量,并随时等待并通知它。
#![allow(unused)] fn main() { use std::sync::Condvar; let condvar = Condvar::new(); }
pub fn wait<'a, T>(&self, guard: MutexGuard<'a, T>) -> LockResult<MutexGuard<'a, T>>
阻塞当前线程,直到条件变量接收到一个通知。
这个函数将会自动解锁指定的MutexGuard并且阻塞当前线程。这意味着在互斥体(mutex)解锁后,任何逻辑上的调用notify_one和notify_all方法都是唤醒该线程的候选对象。当函数返回时,将重新获得指定的锁。
请注意,这个方法易受虚假唤醒的影响。条件变量通常使用布尔谓词和他们建立关联,并且该方法每次返回时都必须检查谓词以防止虚假唤醒。
❗️:如果正在等待的互斥锁在此线程重新获取锁时中毒,该方法将返回错误。想要了解更多信息,请参阅有关资料: 中毒的互斥体(Mutex)。
😱:如果同时使用多个互斥体将会触发panic!。每个条件变量都动态的绑定在一个互斥体上以确保跨平台行为定义。如果不需要此限制,则需提供sys中的unsafe原语。
#![allow(unused)] fn main() { use std::sync::{Arc, Mutex, Condvar}; use std::thread; let pair = Arc::new((Mutex::new(false), Condvar::new())); let pair2 = pair.clone(); thread::spawn(move|| { let (lock, cvar) = &*pair2; let mut started = lock.lock().unwrap(); *started = true; // We notify the condvar that the value has changed. cvar.notify_one(); }); // Wait for the thread to start up. let (lock, cvar) = &*pair; let mut started = lock.lock().unwrap(); // As long as the value inside the `Mutex<bool>` is `false`, we wait. while !*started { started = cvar.wait(started).unwrap(); } }
pub fn wait_while<'a, T, F>(&self, guard: MutexGuard<'a, T>, condition: F) -> LockResult<MutexGuard<'a, T>> where F: FnMut(&mut T) -> bool
阻塞当前线程直到条件变量收到一个通知并且所提供的条件为false为止。
这个函数将会自动解锁指定的MutexGuard并且阻塞当前线程。这意味着在互斥体(mutex)解锁后,任何逻辑上的调用notify_one和notify_all方法都是唤醒该线程的候选对象。当函数返回时,将重新获得指定的锁。
❗️:如果正在等待的互斥锁在此线程重新获取锁时中毒,该方法将返回错误。想要了解更多信息,请参阅有关资料: 中毒的互斥体(Mutex)。
#![allow(unused)] fn main() { use std::sync::{Arc, Mutex, Condvar}; use std::thread; let pair = Arc::new((Mutex::new(true), Condvar::new())); let pair2 = pair.clone(); thread::spawn(move|| { let (lock, cvar) = &*pair2; let mut pending = lock.lock().unwrap(); *pending = false; // We notify the condvar that the value has changed. cvar.notify_one(); }); // Wait for the thread to start up. let (lock, cvar) = &*pair; // As long as the value inside the `Mutex<bool>` is `true`, we wait. let _guard = cvar.wait_while(lock.lock().unwrap(), |pending| { *pending }).unwrap(); }
pub fn wait_timeout<'a, T>(&self, guard: MutexGuard<'a, T>, dur: Duration) -> LockResult<(MutexGuard<'a, T>, WaitTimeoutResult)>
在此条件变量上等待通知,在指定的持续时间之后超时。
此函数的语义等同于wait(除了线程被阻塞的时间不超过dur),由于诸如抢占或平台差异之类的异常可能不会导致等待的最大时间精确地变短,因此该方法不应用于精确的计时。
⚠️:已尽最大的努力确保等待时间是由单调时间测量的,并且不会被系统时间修改所影响。这个函数容易受到虚假唤醒的影响。条件变量通常都会有一个布尔谓词
索引
模式:Service Mesh
自从数十年前首次推出以来,我们了解到分布式系统可以提供我们之前甚至无法想到的用例,但是它们也引入了很多新的问题。
当这些系统很少且很简单的时候,工程师们通过减少远程交互的数量来应对新增的复杂性。处理分发 (distribution) 最安全的方式就是尽可能避免它,即使这可能导致跨系统的逻辑与数据重复。
但是,我们的工业需求推动我们进一步从几台大型中央计算机发展到成千上万台小型服务器。在这个新的领域,我们必须勇往直前,应对新的挑战和问题。首先逐例使用点对点 (ad-hoc) 的解决方案,然后 (subsequently) 使用更加复杂的解决方案。随着我们发现有关问题领域更多的信息并设计出更好的解决方案,我们开始将一些最通用的需求凝结 (crystallise) 成模式,库,最终是平台。
当我们第一次启动网络计算机时发生了什么
自从人们第一次对两个或更多计算机之间相互通信进行思考,他们设想 (envision) 以下模型:
两个服务进行对话以实现用户的某些目标。这显然是过于简化的视图,因为缺少了在代码层面操作的字节与通过电线发送和接收的电信号之间转换的许多层。但是对于我们的讨论而言,这种抽象已经足够。让我们通过将网络堆栈显示为不同的组件来添加更多的细节。
上面模型的变体已经在 1950 年就投入使用。最初,计算机比较稀有且很昂贵,因此两个节点间的每个连接需要被精心设计 (craft) 以及维护。当计算机变得廉价且更加流行时,它们之间的连接数量以及通过它们地数据量会剧烈的 (drastically) 增长。随着人们越来越依赖网络系统,工程师需要确保它们构建的软件符合用户要求的服务质量。
而且,想要达到所需(服务)质量的水平,还需要回答许多问题。人们需要一种方式,让机器可以互相发现;可以在同一根电缆中同时处理多个连接;当机器没有直连时,也允许彼此之间的通信;可以在网络中路由数据包,加密流量等等。
其中,有一个被称为 流控 的东西,我们将用它来举个例子。流控是一种机制,它可以阻止服务器发送超过下游服务处理能力的数据包。这是很有必要的,因为在一个网络系统中,你至少有两台彼此独立的计算机,它们互相都不了解。计算机 A 使用指定的速率向 计算机 B 发送字节流,但是不能保证 B 能够以一致且足够快的速度处理接收的字节流。举个例子,B 可能在并行运行其他的任务,或者数据包可能会乱序到达,但是 B 会阻塞等待应该首先到达的数据包。这意味着不仅 A 不会获得 B 的预期性能,它可能还会使事情变得更糟,因为它可能会让 B 过载导致其必须将这些传入的数据包排队进行处理。
一段时间以来,人们期望构建的网络服务和应用程序可以处理上面代码中显示的挑战。在我们的流控示例中,意味着应用程序自身必须包含相应的逻辑以确保我们不会因(传入过多的)数据包而使服务过载。繁重的网络逻辑与你的业务逻辑并存。对应的抽象图表如下所示:
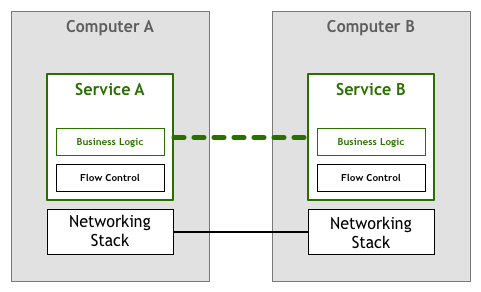
幸运的是,科技迅速发展,并很快有了足够的标准(如 TCP/IP)将流控的解决方案以及网络堆栈中的其他许多问题集成 (incorporate) 起来。这意味着那段代码依然存在,但是它已经从你的应用程序中剥离出来,并放到操作系统提供的网络层中:
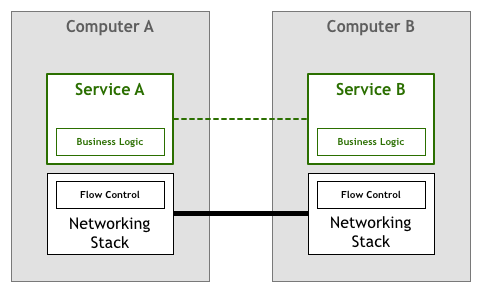
这个模型取得了巨大的成功。很多组织仅使用商业操作系统携带的 TCP/IP 协议栈来驱动他们的业务发展,且它已经足以应对高性能和可靠性的要求。
当我们第一次启动微服务时发生了什么
几年之后,计算机变得更加便宜并随处可见,上面描述的网络栈已经证明自己是实现系统间可靠连接事实上的 (do-facto) 工具集。有了更多的节点和稳定的连接,行业中就玩起了各种各样的网络系统,从细粒度的 (fine-grained) 的分布式代理和对象到广泛使用的分布式组件组成的面向服务的体系结构。
这种极端的分布带来了许多有趣的高级用例和收益,但是它依然要面对很多挑战。其中的某些挑战是全新的,而其他则只是我们讨论的原始网络挑战的更高版本。
在上世纪 90 年代,Peter Deutsch 和他在 Sun Microsystems 公司的工程师同伴合编了”分布式计算的 8 个谬论 (Fallacy)“,其中列出了人们在使用分布式系统时倾向做出的一些假设。Peter 的观点是,这些可能在原始网络架构或理论模型中是正确的,但是在现代界中却不成立:
- 网络是可靠的
- 没有网路延迟
- 无限带宽
- 网络是安全的
- 拓扑结构 (Topology) 不会改变
- 只有一个管理员
- 传输是零成本开销
- 网络是同质的(homogeneous),即各处的网络状态完全一样
将上述的列表抨击 (Denounce) 为”谬论“是因为工程师无法忽视这些问题,他们需要明确的处理它们。
为了使问题进一步复杂化,在我们经常称之为微服务架构的分布式系统中,在可操作性方面引入了新的需求。我们在之前讨论过这些细节,但是在这里,我们将其归纳成一个清单:
- 快速配置 (provisioning) 计算机资源
- 基础监控
- 快速发布
- 易于配置存储
- 易于访问边界
- 鉴权/授权
- 标准化的 RPC
因此,尽管数十年前开发的 TCP/IP 协议栈和通用网络模型仍然是可以让计算机彼此通信的强大工具,但是更复杂的体系构又引入了另一层要求,必须由在这样的架构中工作的工程师来实现。
例如服务发现和服务熔断,这是用于解决上面列出的一些弹性 (resiliency) 和分布式挑战的技术。
正如历史会周期性的出现,基于微服务构建系统的第一批组织使用的策略与前几代联网计算机使用的策略十分相似。这意味着处理上面列出的需求的责任留给了编写服务的工程师。
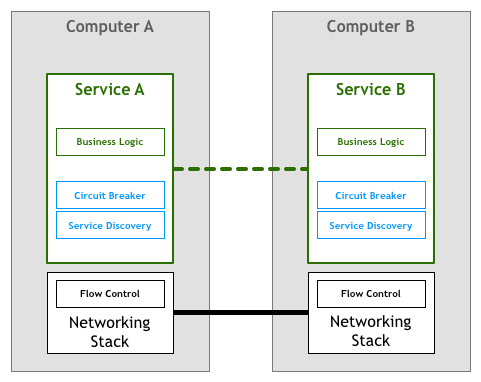
服务发现是一个自动查找哪些服务实例满足给定查询的过程。例如,一个名为Teams的服务使用值为production的environment属性查询名为Players服务的实例。你将会调用一些服务发现的进程,这些进程将返回合适的服务节点的列表。对于更加整体 (monolithic) 架构,这是一个简单的任务,通常使用 DNS,负载均衡和一些关于端口的约定 (convention) 来实现(例如,所有服务将其 HTTP 服务绑定到 8080 端口)。在分布式环境中,这类任务将变得更加复杂,以前可以盲目的依靠 DNS 查找依赖关系的服务现在必须处理诸如客户端的负载均衡,多个不同环境(如:staging 和 production),地理位置分散的服务器等。如果你之前只需一行代码来解析主机名,那么现在你的服务就需要更多的样板代码来处理分布式引入的各种极端情况 (various corner cases)。
熔断器是 Michael Nygard 在他的 Release It 书中分类的 (catalogued) 一种模式。我喜欢 Martin Fowler 对这个模式的总结:
熔断器的原理非常简单。你在用于检测故障的熔断器对象中封装了一个受保护的函数调用。一旦故障达到某个阈值,熔断器将会跳闸,并且所有对该熔断器进一步的调用都会返回错误,根本不会进行被保护的调用。通常如果熔断器跳闸,你还需要某种监视器告警。
这些都是简单出色的设备,可以为服务之间的交互增加更多的可靠性。然而,就像其他所有的内容一样,随着分布式水平的提高,它们往往会变得更加复杂。系统中出现问题的可能性随着分布式水平的提高呈现指数级增长,因此,即使诸如“熔断器跳闸时出现某种监视器告警”之类的简单事情也不一定变得直接了当。一个组件中的某个故障会在许多客户端之间造成级联影响,从而触发成千上万的线路同时跳闸。过去仅需几行代码,现在又需要大量的样板代码来处理仅在这个新的领域中存在的问题。
事实上,上面的两个例子很难正确的实现,以至于某些大型且复杂的库(如 Twitter 的 Finagle 和 Facebook 的 Proxygen) 非常受欢迎,因为它避免在每个服务中重写相同的逻辑。
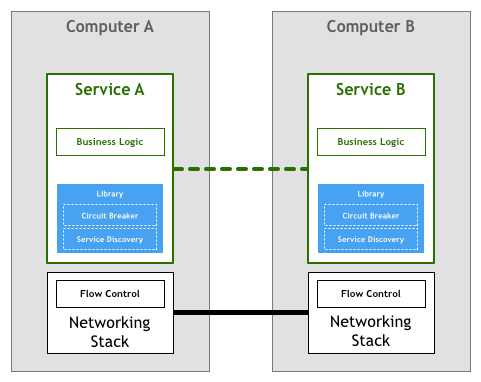
上面描述的 (depict) 的模型被大多数开创了微服务架构的组织所采用,例如:Netflix,Twitter 以及 SoundCloud。随着系统中服务数量的增加,它们还偶然发现 (stumble upon) 了这类方法的各种缺点。
即使使用像 Finagle 这样的库,最大的挑战可能是组织仍需要花费其工程团队的时间来构建将库与其他生态系统联系起来的粘合剂。根据我在 SoundCloud 和 DigitalOcean 的经验,我估计在 100 到 250 人的工程师组织中采取这种策略后,需要让 1/10 的员工专门负责构建工具。有时,这笔费用是明确的,因为工程师被分配到了专门负责构建工具的团队中,但是价格标签通常是不可见的,因为它会随着你使用产品时间的增长而消失。
第二个问题是,以上设置限制了微服务的工具,运行时和语言。微服务的库通常是为特定平台编写的,无论是编程语言还是诸如 JVM 之类的运行时。如果组织使用库不支持的平台时,通常需要先将代码移植到新平台中。这浪费了宝贵的 (scarce) 工程时间。工程师不必再致力于核心业务和产品,而必须再次构建工具和基础架构。这就是为什么像 SoundCloud 和 DigitalOcean 之类的中型组织决定仅支持其内部服务的一个平台的原因,分别是 Scala 和 Go。
这个模型值得讨论的最后一个问题是治理 (governance)。库模型可以抽象化处理微服务体系结构中所需功能的实现,但是它本身仍然是需要维护的组件。确保成千上万的服务实例使用相同或至少兼容的库版本并非易事,并且每次更新都意味着所有服务的的集成,测试以及重新部署,即使该服务本身并未发生改动。
下一个合乎逻辑的步骤
与我们在网络堆栈中看到的类似,非常需要将大规模分布式服务所需的功能提取到基础平台中。
人们使用 HTTP 等高级协议编写非常复杂的应用程序和服务,而无需考虑 TCP 如何控制该网络上的数据包。这种场景正是微服务所需要的,在微服务中,从事服务的工程师可以专注于他们的业务逻辑,避免浪费时间编写自己的服务基础架构的代码或管理整个团队中的库和框架。
将这个想法整合到我们图表中,我们可能会得到如下所示的结果:
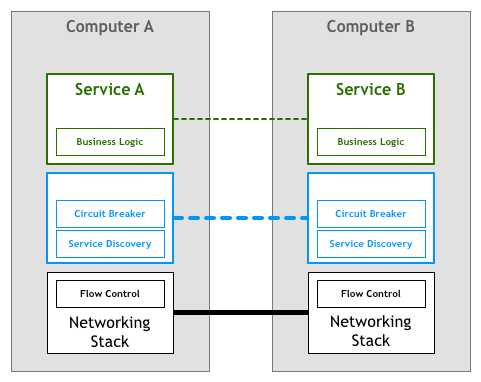
不幸的是,修改网络堆栈以添加此层不是一项可行的 (feasible) 任务。许多从业人员使用的解决方案是将其作为一组代理来实现。这里的想法是,服务不会直接连接其下游依赖项,而是将所有流量通过一小段程序透明的添加所需的功能。
在这个领域中,第一次使用了边车 (sidecar) 的概念。边车是一个辅助 (auxiliary) 进程,运行在你的应用程序周围,并为它提供额外的功能。在 2013 年,Airbnb 编写了 Synapse 和 Nerve,这是边车的开源实现。一年后,Netflix 推出了 Prana,它是一种边车,致力于允许非 JVM 应用从 Netflix OSS 生态系统中受益。在 SoundCloud 中,我们构建了边车,使我们的传统 Ruby 程序可以使用我们为 JVM 微服务构建的基础架构。
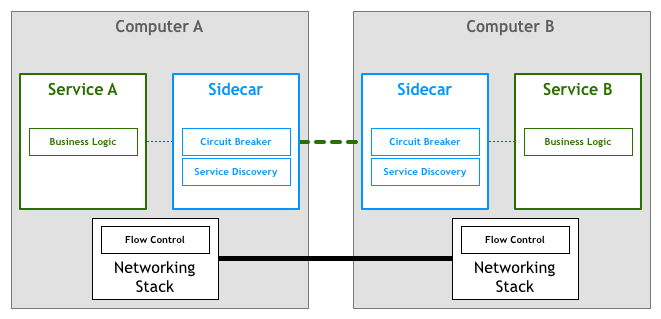
尽管所许多此类开源代理的实现,但它们往往被设计成与特定的基础架构的组件一起使用。例如,在服务发现方面,Airbnb 的 Nerve & Synapse 假定服务注册在 Zookeeper 中,而对于 Prana,则应使用 Netflix 自己的 Eureka 服务注册组件。
随着微服务架构的日益普及,最近我们看到了新一轮的代理浪潮,这些代理足够灵活,可以适应不同的基础架构组件和偏好设置。这个领域第一个广为人知的系统是 Linkerd,它是由 Buoyant 根据工程师在 Twitter 微服务平台上的先前工作创建的。很快,Lyft 工程团队发布了 Envoy,它遵循类似的原则。
Service Mesh
在这种模型中,你的每一个服务都将伴随一个代理边车 (sidecar),鉴于服务仅通过边车代理相互通信,因此最终我们得到了如下图所示的部署:
Buoyant 公司的 CEO William Morgan 观察到,代理之间的互联形成了网状网络。在 2017 年初,William 为该平台下了一个定义,并称其为 Service Mesh:
Service Mesh 是用于处理服务到服务之间通信的专用基础架构层。它负责通过构建现代云原生应用程序的复杂服务拓扑来可靠地传递请求。实际上,Service Mesh 通常被实现为轻量级网络代理的阵列,这些代理与应用程序的代码一起部署,但是不需要了解应用程序的具体逻辑。
他的定义中最有力的方面可能是,它摆脱了将代理视为独立组件的想法,并认识到它们形成的网络本身就是有价值的东西。
随着组织将其微服务部署移至更复杂的运行时(如 k8s 和 Mesos),人们和组织已经开始使用那些平台提供的工具来正确的实现这个网状网络的思想。它们正在从一组隔离工作的独立代理转移到一个适当的,有点集中 (centralise) 的控制平面。
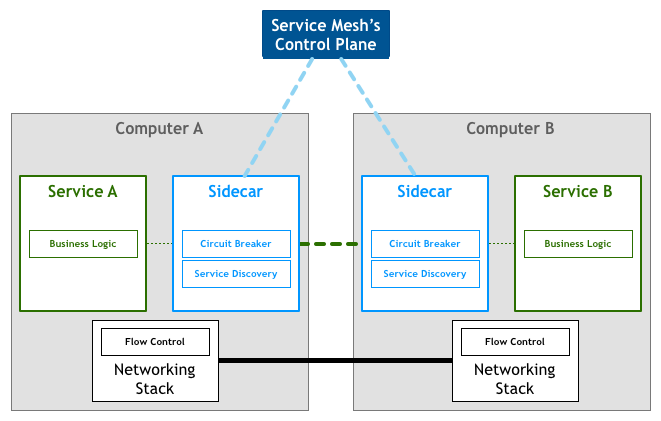
纵观我们的鸟瞰图,我们看到实际的服务流量仍然直接地从代理流向代理,但是控制平面知道每一个代理实例。它使代理可以实现诸如访问控制和指标收集之类的事情,这需要协作:
最近发布的 Istio 项目就是此类系统最突出 (prominent) 的示例。
全面了解 Service Mesh 在大规模系统中的影响还为时过早。这个方法的两个好处对我来说已经很明显 (evident) 了。首先,不必编写定制软件来处理微服务体系结构的最终商品代码,这将使许多较小的组织可以使用到以前仅大型企业才能使用的特性,从而创建各种有趣的用例。其次,这种体系结构可能让我们最终实现使用最佳工具/语言完成工作的梦想,而不用担心每个平台库和模式的可用性。
xDS REST 和 gRPC 协议
Envoy 通过文件系统或查询一台或多台管理服务器来发现它的各种动态资源。这些发现服务和它们对应的 API 统称为 xDS。可以通过订阅,指定要监控的文件系统路径,初始化 gRPC 流或轮询 REST-JSON 的 URL 来请求资源。后两种方法中涉及发送带有 DiscoveryRequest 协议载荷的请求。在所有方法中,资源都是通过 DiscoveryResponse 协议载荷进行交付的。我们在下面讨论每种类型的订阅。
资源类型
xDS API 中的每个配置资源都有与之相关联的类型。资源类型遵循版本控制方案。资源类型的版本与下面描述的传输方式无关。
支持以下 v3 版本的 xDS 资源类型。
- envoy.config.listener.v3.Listener
- envoy.config.route.v3.RouteConfiguration
- envoy.config.route.v3.ScopedRouteConfiguration
- envoy.config.route.v3.VirtualHost
- envoy.config.cluster.v3.Cluster
- envoy.config.endpoint.v3.ClusterLoadAssignment
- envoy.extensions.transport_sockets.tls.v3.Secret
- envoy.service.runtime.v3.Runtime
类型的 URL 的概念显示在下面,格式为type.googleapis.com/<resource type> - 例如,Cluster资源的 URL 是type.googleapis.com/envoy.config.cluster.v3.Cluster。在来自 Envoy 的各种请求以及管理服务器的响应中,都声明了资源类型的 URL。
文件系统订阅
下发动态配置最简单的方式就是将其放置在 ConfigSource 指定的文件系统路径下。Envoy 将会使用inotify (macOS 中的kqueue) 监控文件的变更并解析更新文件中的 DiscoveryResponse 协议,DiscoveryResponse 支持二进制 protobuf,JSON,YAML 以及 proto 文本格式。
除了统计计数器和日志外,文件系统订阅没有其他可用于更新 ACK/NACK 的机制。如果配置更新请求被拒,则 xDS API 上一次更新的配置将仍然有效。
流式 gRPC 订阅
API 流
对于典型的 HTTP 路由场景 (scenarios),客户端配置的核心资源类型是Listener,RouteConfiguration,Cluster以及ClusterLoadAssignment。每个Listener资源可能指向一个RouteConfiguration资源,每个RouteConfiguration资源可能指向一个或多个Cluster资源,每个Cluster资源可能指向一个ClusterLoadAssignment资源。
Envoy 在启动时会拉取所有的Listener和Cluster资源。然后它会拉取Listener和Cluster资源所需的RouteConfiguration和ClusterLoadAssignment资源。实际上,每个Listener和Cluster资源都是 Envoy 配置树的根的一部分。
诸如 gRPC 之类的非代理客户端在启动时可能仅会拉取它感兴趣的特定Listener资源。然后再拉取这些Listener资源所需的RouteConfiguration资源,RouteConfiguration资源所需的Cluster资源,以及Cluster资源所学的ClusterLoadAssignment资源。实际上,最初的Listener资源是客户端配置树的根。
xDS 传输协议的变体
四种变体
流式 gRPC 使用了四种 xDS 传输协议的变体,它涵盖了二维的所有组合。
第一个维度是世界状态 (SotW) vs 增量。SotW 方案是 xDS 最初使用的机制,其中客户端必须在每个请求中指定它感兴趣的所有资源的名称(在 LDS/CDS 中发出的通配符请求除外),服务器必须返回客户端在每个 (LDS/CDS) 请求中订阅的所有资源。这意味着如果客户端已经订阅了 99 个资源,并且想要添加一个额外的资源,它必须发送带有这 100 个资源名称的请求,而不是仅发送新添加资源的名称。并且服务器必须发送全部的 100 个资源对其做出响应,即使那 99 个已订阅的资源并没有做任何变更(在 LDS/CDS 中)。这个机制可能导致弹性(可伸缩性)受限,这也是引入增量协议变体的原因。增量方式允许客户端和服务器仅指示相对于其先前状态的增量 - 即客户端可以告诉服务器它想要添加或移除一个特定资源名称的订阅关系,而不必重发那些未发生改变的资源的名称,服务器也只需发送那些变更资源的更新即可。增量协议也提供了一种资源的懒加载机制。有关增量协议的详细内容,可以参阅下面的增量 xDS。
第二个维度是每个资源类型使用单独的 gRPC 流 vs 将所有资源类型聚合到一个 gRPC 流中。前者是 xDS 最初使用的机制,它提供了最终一致性模型。而后者是在需要显示控制顺序的环境中所使用。可以在最终一致性思考中查看更详细的内容。
因此,这四种 xDS 传输协议的变体是:
- 世界的状态(基础 xDS):SotW,为每个资源类型提供独立的 gRPC 流
- 增量 xDS:增量的,为每个资源类型提供独立的 gRPC 流
- 聚合发现服务 (ADS:Aggregated Discovery Service):SotW,为所有的资源类型提供一个聚合的 gRPC 流
- 增量 ADS:增量的,为所有的资源类型提供一个聚合的 gRPC 流
每种变体的 RPC 服务和方法
对于非聚合的协议变体,每个资源类型都有一个独立的 RPC 服务。每个 RPC 服务都可以为每个 SotW 和增量协议变体提供一个方法。以下是每一种资源类型的 RPC 服务和方法:
- Listener:Listener 发现服务 (LDS:Listener Discovery Service)
- SotW:ListenerDiscoveryService.StreamListeners
- 增量:ListenerDiscoveryService.DeltaListeners
- RouteConfiguration:路由发现服务 (RDS:Route Discovery Service)
- SotW:RouteDiscoveryService.StreamRoutes
- 增量:RouteDiscoveryService.DeltaRoutes
- ScopedRouteConfiguration:域路由发现服务 (SRDS:Scoped Route Discovery Service)
- SotW:ScopedRouteDiscoveryService.StreamScopedRoutes
- 增量:ScopedRouteDiscoveryService.DeltaScopedRoutes
- VirtualHost:虚拟主机发现服务 (VHDS:Virtual Host Discovery Service)
- SotW:N/A
- 增量:VirtualHostDiscoveryService.DeltaVirtualHosts
- Cluster:集群发现服务 (CDS:Cluster Discovery Service)
- SotW:ClusterDiscoveryService.StreamClusters
- 增量:ClusterDiscoveryService.DeltaClusters
- ClusterLoadAssignment:终结点发现服务 (EDS:Endpoint Discovery Service)
- SotW:EndpointDiscoveryService.StreamEndpoints
- 增量:EndpointDiscoveryService.DeltaEndpoints
- Secret:隐秘服务发现 (SDS:Secret Discovery Service)
- SotW:SecretDiscoveryService.StreamSecrets
- 增量:SecretDiscoveryService.DeltaSecrets
- Runtime:运行时服务发现 (RTDS:Runtime Discovery Service)
- SotW:RuntimeDiscoveryService.StreamRuntime
- 增量:RuntimeDiscoveryService.DeltaRuntime
在聚合的协议变体中,所有的资源类型都会多路复用到一个 gRPC 流中,在该聚合流中,每一个资源类型都被当做一个独立的逻辑流对待。实际上,它通过将每种资源类型的请求和响应视为单个聚合流上的独立子流,从而将上述所有独立的 API 简单的组合到单个流中。聚合协议变体的 RPC 服务和方法是:
- SotW:AggregatedDiscoveryService.StreamAggregatedResources
- 增量:AggregatedDiscoveryService.DeltaAggregatedResources
对于所有的 SotW 方法,请求类型都是 DiscoveryRequest,且响应类型是 DiscoveryResponse。
对于所有的增量方法,请求类型是 DeltaDiscoveryRequest,且响应类型是 DeltaDiscoveryResponse。
配置使用哪一种变体
在 xDS API 中,ConfigSource 消息指示如何获取指定类型的资源。如果 ConfigSource 包含一个 gRPC 的 ApiConfigSource,它指向管理服务器的上游集群;这将为每种资源类型 (可能到不提供的管理服务器) 初始化一个独立的双向 (bidirectional) gRPC 流。如果 ConfigSource 包含一个 AggregatedConfigSource,它是在告诉客户端使用 ADS。
目前,客户端需要一些本地配置以获知如何获取 Listener 和 Cluster 资源。Listener 资源可能包含一个 ConfigSource,该 ConfigSource 指示如何获取 RouteConfiguration 资源,Cluster 资源可能包含一个 ConfigSource,该 ConfigSource 指示如何获取 ClusterLoadAssignment 资源。
客户端配置
在 Envoy 中,引导 (bootstrap) 文件包含两个 ConfigSource 消息,一个指示如何获取 Listener 资源,另一个指示如何获取 Cluster 资源。它还包含一个独立的 ApiConfigSource 消息指示如何与 ADS 服务器通信,只要 ConfigSource 消息(在引导文件中或在从管理服务器中获取到的 Listener 或 Cluster 资源中)包含一个 AggregatedConfigSource 消息,就会使用该消息。
在使用 xDS 的 gRPC 客户端中,仅支持 ADS,并且包含 ADS 服务器名称的引导文件将会用于所有的资源。Listener 和 Cluster 资源中的 ConfigSource 消息必须包含 AggregatedConfigSource 消息。
xDS 传输协议
Transport API 版本
除了上述描述的资源类型版本之外,xDS 有线协议还要与之关联的 transport 版本。它为诸如 DiscoveryRequest 和 DiscoveryResponse 的消息提供了类型版本控制 (versioning)。它也以 gRPC 方法名称进行编码,因此服务器可以根据调用的方法确定客户端使用的版本。
基础协议概览
每个 xDS 流从客户端发送的 DiscoveryRequest 消息开始,该消息指定了将要订阅的资源列表,与已订阅资源相对应的类型 URL,节点标志符以及一个可选的资源类型实例版本,该版本表明客户端已经感知到资源类型的最新版本(详细信息请查阅 ACK/NACK 及资源类型的实例版本)。
然后,服务器将会发送一个 DiscoveryResponse 消息,其中包含客户端指示其已感知到的自上一个资源类型实例版本以来,客户端已订阅且发生变更的任何资源。当订阅的资源发生变更时,服务器可以随时发送其他响应。
客户端无论何时接收到一个新的响应,它将会发送另一个请求,该请求指示响应中的资源是否有效(详细信息请查阅 ACK/NACK 及资源类型的实例版本)。
每个服务器的响应都会包含一个nonce,并且随后所有的客户端请求都必须将 response_nonce 字段设置为从该流中的服务器接收到的最新随机数。这可以让服务器决定给定的请求与哪一个响应相关联,它避免了在 SotW 协议变体中的各种竞争 (race) 条件。请注意,随机数仅在单个 xDS 流的上下文中有效;它在流重启后不再存活。
只有流上的第一个请求保证携带节点标志符。该流中随后的发现请求可能携带空的节点标志符。无论是否接受同一流上的发现响应,都是正确的。如果流中出现了多个节点标志符时,节点标志符应该总是完全相同的 (identical)。仅检查第一条消息中的节点标志符作为结果即可。
ACK/NACK 和 资源类型实例版本
每一个 xDS 资源类型都有一个字符串类型的版本,它表示该资源类型的版本。当某个资源类型改变时,该版本字符串也将改变。
在 xDS 服务器发送的响应中,version_info 字段表示该资源类型的当前版本。然后客户端向服务器发送另一个带有 version_info 字段的请求,表明客户端已经知道最新的合法版本。这为服务器提供了一种确定何时发送客户端认为无效版本的方法。
(在增量协议变体中,system_version_info 字段中的资源类型实例版本被服务器发送。然而,客户端实际上并不使用此信息来传达哪些资源有效,因为增量 API 变体对此有单独的机制)。
对于每一个资源类型来说,资源类型实例版本是独立的。当使用了聚合协议变体,尽管所有资源类型都被发送到了同一个流中,但是每个资源类型都具有它自己的版本。
对于每一个 xDS 服务器 (其中 xDS 服务器由唯一的 ConfigSource 标识) 来说,资源类型实例版本同样是独立的。当在多个 xDS 服务器中获取到给定类型的资源时,每个 xDS 服务器将会有不同的版本概念 (notion)。
请注意,资源类型实例版本不是单个 xDS 流的属性,而是资源本身的属性。如果流被中断且客户端创建了一个新流,客户端在新流上的初始化请求应该表明是客户端在之前的流中看到的最新版本。服务器将会决定不重发客户端在上一个流中已看到的资源进行优化,但是仅当它们知道该客户端没有订阅在上一个流中未订阅的新资源时会进行重发。举个例子,对于服务器来说,对通配符 LDS 和 CDS 请求执行此优化通常是安全的,并且在客户端将始终订阅完全相同的资源集的环境中这么做是安全的。
一个 EDS 请求示例可能如下所示:
version_info:
node: { id: envoy }
resource_names:
- foo
- bar
type_url: type.googleapis.com/envoy.config.endpoint.v3.ClusterLoadAssignment
response_nonce:
管理服务器可以立即响应请求,也可以在请求带有 DiscoveryResponse 的资源可用时进行响应,例如:
version_info: X
resources:
- foo ClusterLoadAssignment proto encoding
- bar ClusterLoadAssignment proto encoding
type_url: type.googleapis.com/envoy.config.endpoint.v3.ClusterLoadAssignment
nonce: A
在处理完 DiscoveryResponse 之后,Envoy 将在流中发送一个新请求,指定成功应用的最新版本以及管理服务器提供的随机数。该版本为 Envoy 和管理服务器提供了当前已应用配置的共享概念,以及 ACK/NACK 配置更新的机制。
ACK
如果成功应用了更新,则按照顺序图所示,version_info 将会是 X:

NACK
如果 Envoy 拒绝了配置更新 X,它将使用 error_detail 和先前的版本 (在此图中是空的初始化版本) 对其进行回应。error_detail 在消息字段中具有关于确切错误消息的更多详细信息:

在顺序图中,以下格式被用于缩略消息:
- DiscoveryRequest:(V = version_info,R = resource_names,N = response_nonce,T = type_url)
- DiscoveryResponse:(V = version_info,R = resources,N = nonce,T = type_url)
在 NACK 之后,API 可能会在新版本 Y 上更新成功:

服务器检测 NACK 的首选机制是在客户端发送的请求中查找 error_detail 字段的存在。某些较旧的服务器可能会通过查看请求中的版本和随机数来检测 NACK:如果请求中的版本与服务器使用该随机数发送的版本不相等,则客户端已拒绝了最新版本。但是这种方法不适用于客户端的 LDS 和 CDS 以外的 API,这些 API 可能会动态修改其订阅的资源集,除非服务器以某种方式安排了每当一个客户端订阅一个新资源时就增加资源类型实例版本。具体来说,请考虑以下示例:

ACK 与 NACK 语义总结
- xDS 客户端应该对管理服务器收到的每个 DiscoveryResponse 进行 ACK 或 NACK。response_nonce 字段告诉服务器,ACK 或 NACK 关联的是哪一个响应。
- ACK 表示更新配置成功,且包含来自 DiscoveryResponse 中的 version_info
- NACK 表示更新配置失败,且此值是通过出现 error_detail 字段来表示的。version_info 表示客户端正在使用的最新版本,尽管在客户端在现有版本中订阅了新的资源且该新资源无效的情况下,该版本可能不是较旧的版本(参考上面的示例)。
何时发送一个更新请求
管理服务器仅当 DiscoveryResponse 中的资源发生变更时才会将更新发送给 Envoy 客户端。Envoy 在被接受或拒绝后,立即使用包含 ACK/NACK 的 DiscoveryRequest 答复 DiscoveryResponse。如果管理服务器提供了相同的资源集而不是等待 (资源) 发生变更,这将导致客户端和服务管理器进行不必要的工作,可能会严重的影响性能。
在流中,新的 DiscoveryRequests 将会取代 (supersede) 所有具有相同资源类型的先前 DiscoveryRequests。这意味着对于任何给定的资源类型,管理服务器只需响应每个流上的最新 DiscoveryRequest。
客户端如何指定返回哪一种资源
xDS 允许客户端指定一组资源名称,作为服务器对客户端感兴趣资源的提示。在 SotW 协议变体中,这是通过在 DiscoveryRequest 中指定 resource_names 完成的;在增量协议变体中,是通过 DeltaDiscoveryRequest 中的 resource_names_subscribe 和 resource_names_unsubscribe 字段来完成的。
通常(查看下面的异常),请求必须指定客户端感兴趣的资源集的名称。管理服务器必须提供被请求的资源(如果存在)。客户端将忽略未明确请求任何提供的资源。当客户端发送一个新请求来更改请求的资源集时,服务器必须重新发送任何新请求的资源,即使该服务没有请求先前发送的那些资源,并且自那时以来资源也没有发生变化。如果资源名称列表为空,则意味着客户端不再对指定类型的任何资源感兴趣。
对于 Listener 和 Cluster 资源类型,这里也有一个“通配符”模式,它将在该资源类型的流上初始化不包含资源名称的请求时被触发。在这种情况下,服务器通常根据客户端的节点标识,使用特定站点的业务逻辑来确定客户端感兴趣的全部资源。请注意对于给定的资源类型,一旦流进入了通配符模式,就无法让流脱离通配符模式;流上随后请求中的特定资源名称将被忽略。
客户端行为
对于 Listener 和 Cluster 资源,Envoy 将总是使用通配符模式。然而,其他的 xDS 客户端(如使用 xDS 的 gRPC 的客户端)将会为这些资源类型指定明确的资源名称,例如,如果它们只有一个 listener 且已经从某些带外 (out-of-band) 数据中知道了它的名称。
将资源分组到响应中
在增量协议变体中,服务器会在它自己的响应中发送每个资源。这意味着如果服务器在之前发送了 100 个资源且其中只有一个资源发生了变更,它可能发送只包含变更资源的响应;它不需要重发那 99 个未发生变更的资源,客户端也不会删除未改变的资源。
在 SotW 协议变体中,除 Listener 和 Cluster 之外,所有的资源类型都会以增强协议变体相同的方式分组到响应中。然而,Listener 和 Cluster 资源类型处理的方式不一样:服务器必须包括世界的完整状态,意味着必须包括客户端需要的相关类型的所有资源,即使自从上一个响应之后它们不再发生改变。这意味着服务器之前已经发送了 100 中资源并且只有其中一种资源发生了变更,它必须重发所有的资源,即使那 99 种资源并没有发生变更。
请注意,所有协议变体都以整个命名资源为单位进行操作。这里没有机制提供命名资源中重复字段的增量更新。最值得注意 (notably) 的是,目前尚无增量更新 EDS 响应中各个终结点的机制。
重复资源名称
服务器发送的单个响应中包含两个相同的资源名是错误的。客户端应该对包含多个相同资源名称的实例进行 NACK 响应。
删除资源
在增量协议变体中,服务器通过响应中的 removed_resources 字段告诉客户端该资源应该被删除。这告诉客户端需要从其本地的缓存中移除资源。
在 SotW 协议变体中,删除资源的标准 (criteria) 更加复杂。对于 Listener 和 Cluster 资源来说,如果在新的响应中没有发现之前的资源,则表示资源已经被移除了,因此客户端必须将它删除;一个不包含任何资源的响应表示删除了该类型的所有资源。然而,对于其他资源类型来说,API 没有提供任何机制让服务器告诉客户端该资源已被删除;取而代之的是,通过将父资源更改为不再引用子资源来隐式表示删除操作。例如,当客户端接收到一个 LDS 更新时,移除之前指向 RouteConfiguration A 的 Listener,如果没有其他 Listener 指向 RouteConfiguration A,客户端可能会将 A 删除。对这些资源类型,从客户端的角度来说,空的 DiscoveryResponse 是一个有效的空操作。
知道何时请求的资源不存在
SotW 协议变体不提供给任何显式的机制来确定何时请求的资源不存在。
Listener 和 Cluster 资源类型的响应必须包含客户端请求的所有资源。然而,客户端无法仅 (solely) 基于响应中缺少的资源来判断资源是否不存在,因为更新操作最终是一致的:如果客户端最初发送对资源 A 的请求,然后发送对资源 A 和 B 的请求,然后看到某个响应中仅包含资源 A,客户端不能得出资源 B 不存在的结论,因为在服务器看到第二个请求之前,是根据第一个请求发送的响应。
对于其他资源类型,由于每个资源类型可以在它们各自响应中发送,(客户端) 没有任何办法知道在下一个响应中是否存在新请求的资源,因为下一个响应可能是先前已订阅的另一个资源的更新。
因此,客户端应在发送新资源的请求后使用超时 (建议持续时间为 15 秒),此后,如果未收到资源,客户端将认为请求的资源不存在。在 Envoy 中,这是在 资源预热 期间对 RouteConfiguration 和 ClusterLoadAssignment 资源所做的事情。
注意到,在 Listener 和 Cluster 资源类型使用通配符模式时,该超时并非绝对需要,因为在这种情况下,每个响应都包含与客户端相关的所有现有资源,因此客户端在下一个响应中没有发现某个资源,就可以确定该资源不存在。然而,在这种情况下,仍建议使用超时,因为这样可以防止管理服务器无法及时发送响应的情况
请注意,尽管该资源可能在客户端请求的那一刻不存在,但是它可以在任何时间被创建。管理服务器必须记住客户端请求的资源集,如果这些资源在之后出现 (spring into),服务器必须将这些新资源的更新发送给客户端。最初看到资源不存在的客户端必须为随时创建该资源做好准备。
取消资源的订阅
在增量协议变体中,资源可以通过 resource_names_unsubscribe 字段取消订阅。
在 SotW 协议变体中,每一个请求必须在 resource_names 字段中包含将要订阅的完整资源名称列表,因此,取消订阅资源集是通过发送一个新请求来完成的,该请求包含仍在订阅的所有资源名称,但是不包含将要取消订阅的资源名称。举个例子,如果客户端之前已经订阅了资源 A 和 B,但是想要取消订阅资源 B,它必须发送一个仅包含资源 A 的新请求。
请注意,对于流处于“通配符”模式的 Listener 和 Cluster 资源类型(有关详细信息,请参见 客户端如何指定要返回的资源),要订阅的资源集是服务器而不是客户端决定的,因此客户端没有取消订阅资源的机制。
在单个流中请求多个资源
对于 EDS/RDS,Envoy 可以为给定类型的每种资源生成不同的流(例如,对于管理服务器来说,每个 ConfigSource 都具有不同的上游集群),或者当它们注定 (destined for) 要使用同一个管理服务器时,可以在给定资源类型的情况下将多个资源请求组合在一起。尽管这会留给实现细节,但是对于每个请求中给定的资源类型来说,管理服务器应该能够处理一个或多个 resource_names。以下两个顺序图对于获取两个 EDS 资源{foo, bar}都是有效的。


资源更新
如上所述,Envoy 可以在每个给特定 DiscoveryResponse 发送 ACK/NACK 的 DiscoveryRequest 中更新它提供给管理服务器的 resource_names 列表。此外,Envoy 稍后可能会在给定的 version_info 上发出其他的 DiscoveryRequest,以使用新的资源提示更新管理服务器。例如,如果 Envoy 为 EDS 的 X 版本,并且仅知道集群foo,但是随后又接收到了 CDS 更新并了解了bar的信息,则它可能会使用{foo, bar}作为resource_names发送针对 X 的附加 DiscoveryRequest。

这里可能会发生一个竞争条件;如果 Envoy 在 X 发出资源提示更新之后,但是在管理服务器处理更新之前,它用新版本 Y 答复,则可以通过提供 X 的 version_info 将资源提示更新解释为拒绝 Y。为避免这种情况,管理服务器提供了一个随机数,Envoy 使用该随机数来指示每个 DiscoveryRequest 对应的特定 DiscoveryResponse。

管理服务器不应为任何具有过期 (stale) 随机数的 DiscoveryRequest 发送 DiscoveryResponse。在 DiscoveryResponse 中向 Envoy 显示新的随机数后,旧的随机数随即过时。在确定有可用新版本之前,管理服务器无需发送更新。这样一来,早期版本的请求也会过时。它可能会在一个新版本中处理多个 DiscoveryRequest,直到准备好新版本为止。

上述资源更新序列的含义 (implication) 是,Envoy 并不期望它发出的每个 DiscoveryRequests 都具有 DiscoveryResponse。
资源预热
Cluster 和 Listener 需要经过预热才能提供服务。这个过程在 Envoy 初始化阶段和Cluster及Listener更新时都会发生。仅当管理服务器提供 ClusterLoadAssignment 响应时,Cluster 预热才算完成。同样的,如果 Listener 指向一个 RDS 配置时,仅当管理服务器提供 RouteConfiguration 时,Listener 预热才算完成。管理服务器在预热阶段会提供 EDS/RDS 更新。如果管理服务器没有提供 EDS/RDS 响应,Envoy 在初始化阶段不会自行初始化,并且在提供 EDS/RDS 响应之前,通过 CDS/LDS 发送的更新将不会产生生效。
最终一致性思考
因为 Envoy 的 xDS API 是最终一致性的,因此在更新期间流量可能会短暂下降。例如,如果通过 CDS/EDS 只能发现集群 X,RouteConfiguration引用集群X,并且在 CDS/EDS 更新提供集群 Y 之前将其调整为集群 Y,在此期间流量将被”丢进黑洞“ (blackholed,即流量像被丢进黑洞一样被丢弃),知道 Envoy 实例发现了集群 Y。
对于一些应用,短暂的流量下降是可以接受的,在客户端或者通过其他的 Envoy 边车 (Sidecar) 重试将隐藏这次流量下降。然而在其他一些场景,流量下降是不可被容忍的,它可以通过同时提供集群 X 和 Y 的 CDS/EDS 更新,然后将 RDS 更新从 X 指向 Y,然后 CDS/EDS 更新丢弃 X 来避免流量下降。
通常,为了避免流量下降,更新的顺序应该遵循先立后破 (make before break) 模型,其中:
- 必须首先推送 CDS 更新 (如果有)
- EDS 更新 (如果有) 必须在各自集群的 CDS 更新之后到达
- LDS 更新必须在相应的 CDS/EDS 更新之后到达
- 和新添加的 Listener 关联的 RDS 必须在 CDS/EDS/RDS 更新之后到达
- 和新添加的 RouteConfiguration 关联的 VHDS 更新 (如果有) 必须在 RDS 更新之后到达
- 过期的 (stale) CDS 集群以及相关的 EDS 终结点 (不再被引用) 可以在之后被移除
如果没有新的 cluster/route/listener 添加或者短暂的流量下降可以被接受,xDS 更新可以独自被推送。请注意,在进行 LDS 更新的情况下,Listener 将在接收流量之前预热,即 RDS 将会拉取配置的从属路由。添加/删除/更新集群时,集群会预热。另一方面,路由未预热,即在推送路由更新之前,管理平面必须确保被路由引用的集群已经到位。
TTL
如果管理服务器无法访问,Envoy 将会保留最新收到的已知配置,直到重新建立连接为止。对于某些服务,这可能不是理想的。例如在提供故障注入服务的情况下,管理服务器在错误的时间崩溃可能会使 Envoy 处于不良 (undesirable) 状态。如果与管理服务器失去联系,TTL 设置允许 Envoy 在指定的时间段后删除一组资源。例如,当无法再访问管理服务器时,可以使用它来终止故障注入测试。
对于支持xds.config.supports-resource-ttl特性的客户端,可以在每个资源上指定 TTL 字段。每个资源都有其 TTL 过期时间。每种 xDS 类型可能有不同的方式来处理这种过期。
为了更新与某个资源相关的 TTL,管理服务器使用新的 TTL 重新发送该资源。为了移除 TTL,管理服务器将会重新发送不带 TTL 字段的资源。
为了允许进行轻量级的 TTL 更新(”心跳“),可以发送未设置 resource 字段的 Resource,并且可以使用与最近发送版本匹配的版本来更新 TTL。这些资源不会视为资源更新,而仅视为 TTL 更新。
SotW TTL
为了将 TTL 与 SotW xDS 一起使用,必须将相关资源封装在 Resource 中。这允许在不更改 SotW API 的情况下设置用于 Detla xDS 和 SotW 的相同 TTL 字段。SotW 也支持心跳:响应中任何看起来像心跳资源的资源都将仅用于更新 TTL。
此功能由客户端的xds.config.supports-resource-in-sotw特性控制。
聚合发现服务 (ADS)
要在顺序方面提供上述保证,以避免在分发管理服务器时流量下降是一项挑战。ADS 允许单个管理服务器通过单个 gRPC 流传递所有 API 更新。这提供了严格的顺序更新以避免流量下降的功能。对于 ADS,单个流与通过类型 URL 多路复用的多个独立的 DiscoveryRequest/DiscoveryResponse 顺序一起使用。对于任何给定类型的 URL,都适用上述 DiscoveryRequest 和 DiscoveryResponse 消息的顺序。一个顺序更新的示例如下所示:

每个 Envoy 实例都有一个可用的 ADS 流。
ADS 配置的最小bootstrap.yaml片段示例如下所示:
node:
# set <cluster identifier>
cluster: envoy_cluster
# set <node identifier>
id: envoy_node
dynamic_resources:
ads_config:
api_type: GRPC
transport_api_version: V3
grpc_services:
- envoy_grpc:
cluster_name: ads_cluster
cds_config:
resource_api_version: V3
ads: {}
lds_config:
resource_api_version: V3
ads: {}
static_resources:
clusters:
- name: ads_cluster
connect_timeout: 5s
type: STRICT_DNS
load_assignment:
cluster_name: ads_cluster
endpoints:
- lb_endpoints:
- endpoint:
address:
socket_address:
# set <ADS management server address>
address: my-control-plane
# set <ADS management server port>
port_value: 777
# It is recommended to configure either HTTP/2 or TCP keepalives in order to detect
# connection issues, and allow Envoy to reconnect. TCP keepalive is less expensive, but
# may be inadequate if there is a TCP proxy between Envoy and the management server.
# HTTP/2 keepalive is slightly more expensive, but may detect issues through more types
# of intermediate proxies.
typed_extension_protocol_options:
envoy.extensions.upstreams.http.v3.HttpProtocolOptions:
"@type": type.googleapis.com/envoy.extensions.upstreams.http.v3.HttpProtocolOptions
explicit_http_config:
http2_protocol_options:
connection_keepalive:
interval: 30s
timeout: 5s
upstream_connection_options:
tcp_keepalive: {}
增量 xDS
增量 xDS是一个单独的 xDS 终结点,它支持:
- 允许协议根据资源/资源名称增量 (”Delta xDS“) 在线路上进行通信。这可用于支持 xDS 资源可伸缩性的目标。管理服务器只需交付已更改的单个集群,而不是在修改单个集群时交付所有的 100k 个集群。
- 允许 Envoy 按需/惰性地请求其他资源。例如仅当该集群的请求到达时才请求该集群。
增量 xDS 会话 (session) 始终在 gRPC 双向流的上下文中。这使 xDS 服务器可以跟踪与其连接的 xDS 客户端状态。尚无 REST 版本的增量 xDS。
在 增量 (delta) xDS 有线协议中,nonce字段是必填字段,用于将 DeltaDiscoveryResponse 与 DeltaDiscoveryRequest ACK/NACK 配对。存在仅用于调试目的的响应消息级别 system_version_info。
DeltaDiscoveryRequest 可以在以下情况下发送:
- 在 xDS 双向 gRPC 流中的初始消息
- 作为对先前 DeltaDiscoveryResponse 的 ACK/NACK 响应。在这种情况下,response_nonce 在响应中设置为随机值。ACK/NACK 由 error_detail 的存在与否决定。
- 来自客户端的自发 (Spontaneous) DeltaDiscoveryRequests。这样做可以从跟踪的 resource_names 集合中动态添加或删除元素。在这种情况下,必须省略 response_nonce。
请注意,虽然可以在请求中设置 response_nonce,但是即使nonce已经过时,服务器也必须接受服务状态的更改,nonce可用于将 ack/nack 与服务器响应相关联,但不用于拒绝旧的请求。
在此第一个示例中,客户端连接并接收其 ACK 的第一个更新。第二个更新失败,客户端将对该更新进行 NACK。然后,xDS 客户端自发请求 ”wc“ 资源。

重新连接时,增量 xDS 客户端可以通过在 initial_resource_versions 中发送它已知的资源,以避免服务器通过网络重新发送这些资源。因为在前一个流中假定没有保留状态,所以重连的客户端必须向服务器提供感兴趣的所有资源名称。请注意,对于通配符请求 (CDS/LDS/SRDS),请求中都必须没有资源在 resource_names_subscribe 以及 resource_names_unsubscribe 中。

资源名称
资源由资源名称或别名标识。资源的别名(如果存在)可以通过 DeltaDiscoveryResponse 资源中的 alias 字段进行标识。资源名称将在 DeltaDiscoveryResponse 资源的 name 字段中返回。
订阅资源
为了订阅一个资源,客户端在 DeltaDiscoveryRequest 的 resource_names_subscribe 字段中发送资源的别名或名称。应该同时检查资源的名称和别名,以确定有关实体是否已经订阅。
resource_names_subscribe 字段可能包含服务器认为客户端已经订阅的资源名称,此外还有其最新版本。但是服务器仍必须在响应中提供这些资源。由于服务器上隐藏了实现细节,客户端可能已经”忘记了“那些资源,尽管它们显示仍在订阅中。
取消资源订阅
当客户端对某些资源失去兴趣时,它将使用 DeltaDiscoveryRequest 的 resource_names_unsubscribe 字段进行表示。与 resource_names_unsubscribe 一样,它们可以是资源名或别名。
resource_names_unsubscribe 字段可能包含多余的 (superfluous) 资源名称,服务器认为该客户端尚未订阅。服务器必须干净地处理这样的请求;它可以简单地忽略这些未订阅的幻象 (phantom) 资源名称。
知道何时请求的资源不存在
客户端订阅的资源不存在时,服务器将会发送一个 Resource,该 Resource 的 name 字段匹配客户端订阅的名称且其 resource 字段未被设置。这允许客户端不用等待超时时间即可确定资源是否存在,就像在 SotW 协议变体中所做得那样。然而,仍然鼓励客户端使用超时时间来防止管理服务器无法及时发送响应的情况。
REST-JSON 轮询订阅
通过 REST 终结点进行的同步(长)轮询也可用于 xDS 单例 API。除了无持久流与管理服务器进行交互外,消息的顺序与上述两种订阅方式 (监控文件系统路径或初始化 gRPC 流) 类似。预计在任何时间点都只有一个未完成的请求,因此响应中的随机数 (response_nonce) 在 REST-JSON 中是可选的。proto3 中的 JSON 规范转换用于编码 DiscoveryRequest 和 DiscoveryResponse 消息。ADS 不可用与 REST-JSON 轮询。
如果将轮询周期设置为一个较小的值(目前进行的是长轮询),那么除非通过资源更新对基础 (underlying) 资源进行了更改,否则还需要避免发送 DiscoveryResponse。
索引
开放容器倡议 (OCI) 规范概述
OCI (Open Container Initiative) 是一个由行业合作提出的倡议,旨在定义有关容器镜像格式与运行时的开放容器规范。就开源世界的合作与竞争而言,从最初的分歧到如何一步步到达今天地位上的历史是一个非常有趣的故事。
如今,容器生态系统的所有主要玩家都遵循 OCI 容器规范。对于任何想要了解容器工作原理的同学,这是一门你绝不想错过的技术。
概览
OCI 有两项规范,Image spec 和 Runtime spec。
下图显示了它们涵盖的内容和交互的方式。
OCI 镜像可以从其他地方下载(如 Docker Hub) 并在 OCI 运行时文件系统包中解压。然后 OCI 运行时包将会运行在 OCI 运行时中。其中,OCI 运行时规范定义了如何运行一个”文件系统包“。
镜像规范 (image-spec)
镜像规范定义了 OCI 容器镜像的格式,其中包含 manifest,镜像索引 (image index),一组文件系统层以及一个配置文件。这个规范的目标是创建互操作工具,用于构建,传输,以及准备要运行的容器镜像。
在顶层视角,容器镜像只是个 tarball 压缩包,在解压之后,它拥有以下布局。
├── blobs
│ └── sha256
│ ├── 4297f0* (image.manifest)
│ └── 7ea049 (image.config)
├── index.json
└── oci-layout
如果没有说明这些东西都是些什么以及它们是如何关联的,该布局就没那么有用。
我们可以简单的忽略oci-layout文件。index.json是入口点,它包含了主要的manifest,其中列出了所有用于单个容器镜像的”资源“。
manifest包含主要的config和layers。
将它使用图表表示:

配置 (config) 包含:
- 镜像的配置,它将会转换成 OCI 运行时包的运行时配置文件。
- layers,构成 OCI 运行时包的根文件系统
- 一些与镜像历史相关的元数据
层级 (layers) 构成最终的rootfs。第一层级是基础,其他所有层级仅包含第一次层级的变更。在下一节中我们深入研究一下什么是 OCI 层级规范。
层级
规范中本质上关于层级定义了以下两点:
- 如何表示一个层级
- 对于基础层级, 压缩所有的内容
- 对于非基础层级,压缩所有与其主层级比较后变更内容的集合
- 因此,首先检测变更,形成一个
changeset;然后压缩此变更集合以表示该层级
- 如何联合所有层级
在主层级的顶层应用所有的变更集合。将会给你带来rootfs。
运行时规范 (runtime-spec)
一旦在磁盘文件系统中将镜像解压到 OCI 运行时包中,你可以将其运行起来。此时是 OCI 运行时规范在起作用。该规范指定了容器的配置,执行环境以及生命周期。
容器配置包含必要的元数据用来创建及运行此容器。其中包含要使用的运行线程,环境变量,资源限制以及沙盒功能等。一些配置与平台无关,可用于 Linux,Windows,Solaris 以及特定的虚拟机;但另一些配置与平台相关,可能仅适用于 Linux。
OCI 运行时规范还定义了容器的生命周期,这是一系列从容器创建到停止时发生的事件。
容器生命周期
容器拥有生命周期,从本质上讲,它可以用以下状态图建模。
你可以添加一些其他的动作和状态,如pause和paused,但是这些都是最oci基础的。
此状态图比较常规,但是这里有一个重要的事情需要提及一下 - Hooks。你可能有些惊讶,容器规范并没有定义如何设置网络,它实际上依赖 hook 来正确的设置网络,比如在容器启动之前创建网络并在容器停止之后删除它。
容器配置
我们之前提过容器的配置包含创建和运行容器的必要配置,我们将更仔细地查看一些配置,以了解容器的真正含义,并且我们将专注于 Linux 平台上的所有配置。
-
Root
它定义了容器的根文件系统。
-
Mounts
它指定了可以挂在到根文件系统上的附加文件系统。你在使用它挂载本地路径或者分布式路径(如 Ceph)。
-
Process
它指定了与你要在容器中运行的进程相关的所有内容。包括环境变量和进程参数。
对于 Linux 进程,你可以额外指定有关进程安全方面的内容,如 capabilities,rlimits 以及 selinux 标签。
-
Hooks
你可以在此处连接到容器的生命周期,并执行网络设置与清理操作。
-
Linux 命名空间
Linux 平台的大量配置专用于命名空间配置。实际上,命名空间是容器技术的基础。换句话说,没有命名空间就没有容器。Linux 提供了 7 种命名空间,它们都得到了 OCI 运行时规范的支持。
| 名称 | 宏定义 | 隔离的资源 |
|---|---|---|
| IPC | CLONE_NEWIPC | System V IPC (信号量,消息队列和共享内存),POSIX message queues |
| Network | CLONE_NEWNET | Network devices,stacks,ports (网络设备,网络栈,端口等) |
| Mount | CLONE_NEWNS | Mount points (文件系统挂载点) |
| PID | CLONE_NEWPID | Process IDs (进程编号) |
| User | CLONE_NEWUSER | User and group IDs (用户和用户组) |
| UTS | CLONE_NEWUTS | Hostname and NIS domain name (主机名与 NIS 域名) |
| Cgroup | CLONE_NEWCGROUP | Cgroup root directory (cgroup 的根目录) |
- 注释
除了容器应该运行的内容和方式之外,还可以通过注释标记容器。基于某些属性标记和选择容器的能力是容器编排 (orchestration) 平台的基本要求。
镜像,容器和进程
容器通过(容器)镜像创建。你可以通过一个镜像创建多个容器,还可以重新打包容器(这些容器通常带有一些基础容器的变更内容)以创建新的镜像。
在你获取容器之后,你可以在容器内部运行进程,而无需容器的所有优点。最值得注意的是,一旦我们容器化一个应用程序,它就会称为自包含的,不会与宿主环境混淆,因此它可以”run everwhere“。
以下是各种概念,镜像,容器和进程之间的关系,将它们理清楚是至关重要的。
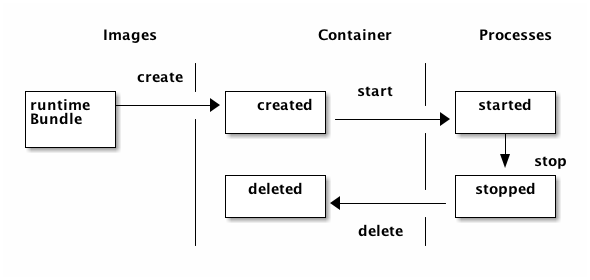
Docker 和 Kubernetes
Docker 使容器称为行业趋势,很多人认为 Docker 是容器,容器是 Docker。Docker 在这里绝对值得称赞,但从技术角度来看,Docker 是应用最广泛的容器实现。Docker 实现的架构从一个版本到另一个版本的演变非常快。在撰写本文时,它如下所示:
该图遵循github]Org/project的格式。大多数组件源自 Docker,但目前在不同的 Github 组织和项目下。最上面使我们日常使用的 Docker 命令工具,它是 Docker Inc. 的商业产品;Docker 工具以来于一个名为 moby 的开源项目,该项目又使用了 runc,它是 oci 运行时规范的参考实现。runc 严重以来 libcontainer,它也是 Docker Inc. 捐赠的。
容器编排
如果我们只需要 1 到 2 个容器,Docker 可能就够了。但是如果我们要运行成千上万的容器,我们就有很多的问题需要解决。仅举几例:
- 调度:容器放在哪个主机上?
- 更新:如何更新容器镜像?
- 伸缩性:当需要扩容时如何添加更多的容器?
这是容器编排系统的工作。Kubernetes 是其中之一,但是截至目前,我认为它是最有前途。这里我们不会深入研究 Kubernetes,而是从容器运行时如何适应容器编排平台的角度简要介绍一下。
下图中展示了 Kubernetes 是如何与容器运行时进行交互的。
Kubernetes 使用容器运行时接口对运行时实现进行解耦。简单来说,CRI 定义了创建,启动,停止和删除容器的接口。它允许 Kubernetes 使用可插拔式容器运行时,你不必锁定到某一个特定的运行时。目前有几种实现方式,如cri-containerd和cri-o,两者最终都会使用oci/runc。
总结
本文是对 OCI 运行时镜像和运行时规范的概述。它涵盖了每个规范的责任以及它们如何相互协作,我们回顾了容器生命周期和运行时规范的主要配置。然后介绍了 Docker 和runc的关系,并简要介绍了容器编排以及容器运行时是如何融入其中的。
索引
「转」详解 KCP 协议的原理和实现
1. 引言
KCP 是一个快速可靠的 ARQ (Automatic Repeat-reQuest, 自动重传请求) 协议, 采用了不同于 TCP 的自动重传策略, 有着比 TCP 更低的网络延迟. 实际通常使用 KCP over UDP 代替 TCP, 应用在网络游戏和音视频传输中. KCP 的实现短小精悍, 非常适合学习. KCP 的 ARQ 机制与 TCP 类似, 只是部分策略不同, 学习 KCP 也有助于我们理解 TCP. 本文讨论 KCP 的原理和实现, 包括它的 ARQ 机制, 拥塞控制等.
笔者并不想直接贴出大段代码然后逐行分析, 因此本文各节会先用图文介绍 KCP 的各个机制, 然后再展示代码并分析它的实现. KCP 源码的可读性还是比较好的, 建议大家阅读本文的同时也结合 KCP 源码.
我们首先在第 2 节看下 KCP 的各个主要的接口; 接着第 3 节开始介绍 KCP 中的数据结构, 包括报文段, KCP 对象, 队列; 第 4 节开始介绍 KCP 的发送, 接收与重传机制; 第 5 节分析 KCP 的拥塞控制机制; 最后简单做一个总结. 本文的篇幅有些长, 不过其中很多是代码展示, 我认为整体还是不复杂的.
2. 使用接口
我们从 KCP 的使用接口出发. 打开 ikcp.h, 关注这几个接口:
// 一个 ikcpcb 实例代表一个 KCP 连接
typedef struct IKCPCB ikcpcb;
// 创建一个 KCP 实例
ikcpcb* ikcp_create(IUINT32 conv, void *user);
// 释放一个 KCP 实例
void ikcp_release(ikcpcb *kcp);
// 设置下层协议输出回调函数
void ikcp_setoutput(ikcpcb *kcp, int (*output)(const char *buf, int len,
ikcpcb *kcp, void *user));
// 接收数据
int ikcp_recv(ikcpcb *kcp, char *buffer, int len);
// 发送数据
int ikcp_send(ikcpcb *kcp, const char *buffer, int len);
// 时钟更新
void ikcp_update(ikcpcb *kcp, IUINT32 current);
// 下层协议输入
int ikcp_input(ikcpcb *kcp, const char *data, long size);
// flush 发送缓冲区, 会在 ikcp_update 中调用
void ikcp_flush(ikcpcb *kcp);
ikcp_create 创建一个 KCP 实例. 传入的 conv 参数标识这个 KCP 连接, 也就是说, 这个连接发出去的每个报文段都会带上 conv, 它也只会接收 conv 与之相等的报文段. 通信的双方必须先协商一对相同的 conv. KCP 本身不提供任何握手机制, 协商 conv 交给使用者自行实现, 比如说通过已有的 TCP 连接协商.
KCP 是纯算法实现的, 不负责下层协议收发, 内部没有任何系统调用, 连时钟都要外部传进来. 因此我们需要:
- 调用
ikcp_setoutput设置下层协议输出函数. 每当 KCP 需要发送数据时, 都会回调这个输出函数. 例如下层协议是 UDP 时, 就在输出回调中调用sendto将数据发送给对方. 输出回调的user参数等于ikcp_create传入的user参数. - 当下层协议数据到达时, 调用
ikcp_input将数据传给 KCP. - 以一定的频率调用
ikcp_update以驱动 KCP 的时钟.current表示当前时间, 单位为毫秒.
设置好下层协议和时钟后, 就可以调用 ikcp_recv 和 ikcp_send 收发 KCP 数据了.

在深入细节之前, 先简单浏览下这几个函数, 我们就能知道它们大概会做什么:
ikcp_send将数据放在发送队列中等待发送;ikcp_recv从接收队列中读取数据;ikcp_input读取下层协议输入数据, 解析报文段; 如果是数据, 就将数据放入接收缓冲区; 如果是 ACK, 就在发送缓冲区中标记对应的报文段为已送达;ikcp_flush调用输出回调将发送缓冲区中的数据发送出去.
接下来几节我们会逐步深入探索 KCP 的实现细节.
3. 数据结构
3.1 报文段
3.1.1 报文段结构
我们先来看 KCP 的报文段结构. 首先, KCP 的有四种报文段, 或者说四个 Command:
- 数据报文
IKCP_CMD_PUSH - 确认报文
IKCP_CMD_ACK - 窗口探测报文
IKCP_CMD_WASK, 询问对端剩余接收窗口的大小. - 窗口通知报文
IKCP_CMD_WINS, 通知对端剩余接收窗口的大小.
无论是那种报文段, 其结构都是这样的:
0 4 5 6 8 (BYTE)
+---------------+---+---+-------+
| conv |cmd|frg| wnd |
+---------------+---+---+-------+ 8
| ts | sn |
+---------------+---------------+ 16
| una | len |
+---------------+---------------+ 24
| |
| DATA (optional) |
| |
+-------------------------------+
可以看到有这么几个字段:
conv4 字节: 连接标识, 前面已经讨论过了.cmd1 字节: Command.frg1 字节: 分片数量. 表示随后还有多少个报文属于同一个包.wnd2 字节: 发送方剩余接收窗口的大小.ts4 字节: 时间戳.sn4 字节: 报文编号.una4 字节: 发送方的接收缓冲区中最小还未收到的报文段的编号. 也就是说, 编号比它小的报文段都已全部接收.len4 字节: 数据段长度.data: 数据段. 只有数据报文会有这个字段.
首先, 每个数据报文和 ACK 都会带上 sn, 唯一标识一个报文; 发送方发送一个数据报文, 接收方收到后回一个 ACK, 接收方收到 ACK 后根据 sn 将对应的报文标记为已送达; 同时, 每个报文都会带上 una, 发送方也会根据 una 将相应的报文标记已送达.
ts 可以用来估算 RTT (Round-Trip Time, 往返时间), 从而计算出 RTO (Retransmission TimeOut, 重传超时时间). 我们会根据 RTO 确定每个报文的超时时间, 如果报文在超时时间内未被标记为已送达, 就会被重传.
数据包的大小可能会超过一个 MSS (Maximum Segment Size, 最大报文段大小). 这个时候需要进行分片, frg 表示随后的分片数量, 即随后还有多少个报文属于同一个包.
每个报文都会带上 wnd, 告诉对端发送方剩余接收窗口的大小, 这有助于对端控制发送速率. 我们会在第 5 节详细讨论.
3.1.2 实现
在 KCP 的实现中, 使用如下的结构体表示一个 KCP 报文段:
struct IKCPSEG
{
struct IQUEUEHEAD node;
IUINT32 conv;
IUINT32 cmd;
IUINT32 frg;
IUINT32 wnd;
IUINT32 ts;
IUINT32 sn;
IUINT32 una;
IUINT32 len;
IUINT32 resendts;
IUINT32 rto;
IUINT32 fastack;
IUINT32 xmit;
char data[1];
};
除了报文的几个字段之外, 还有如下字段:
node: 链表节点. 我们会在 3.3 节详细讨论.resendts: 重传时间戳. 超过这个时间表示该报文超时, 需要重传.rto: 该报文的 RTO.fastack: ACK 失序次数. 也就是 KCP Readme 中所说的 "跳过" 次数.xmit: 该报文传输的次数.
3.2 KCP 实例
一个 struct IKCPCB 实例表示一个 KCP 连接. 它的字段比较多, 这里先列出每个字段的含义. 不必现在就细看每个字段的含义, 可以先跳过这一段, 需要的时候再返回来查.
struct IKCPCB
{
IUINT32 conv, mtu, mss, state;
IUINT32 snd_una, snd_nxt, rcv_nxt;
IUINT32 ts_recent, ts_lastack, ssthresh;
IINT32 rx_rttval, rx_srtt, rx_rto, rx_minrto;
IUINT32 snd_wnd, rcv_wnd, rmt_wnd, cwnd, probe;
IUINT32 current, interval, ts_flush, xmit;
IUINT32 nrcv_buf, nsnd_buf;
IUINT32 nrcv_que, nsnd_que;
IUINT32 nodelay, updated;
IUINT32 ts_probe, probe_wait;
IUINT32 dead_link, incr;
struct IQUEUEHEAD snd_queue;
struct IQUEUEHEAD rcv_queue;
struct IQUEUEHEAD snd_buf;
struct IQUEUEHEAD rcv_buf;
IUINT32 *acklist;
IUINT32 ackcount;
IUINT32 ackblock;
void *user;
char *buffer;
int fastresend;
int fastlimit;
int nocwnd, stream;
int logmask;
int (*output)(const char *buf, int len, struct IKCPCB *kcp, void *user);
void (*writelog)(const char *log, struct IKCPCB *kcp, void *user);
};
conv: 连接标识, 前面已经讨论过了.mtu,mss: 最大传输单元 (Maximum Transmission Unit) 和最大报文段大小. mss = mtu - 包头长度(24).state: 连接状态, 0 表示连接建立, -1 表示连接断开. (注意state是 unsigned int, -1 实际上是0xffffffff)snd_una: 发送缓冲区中最小还未确认送达的报文段的编号. 也就是说, 编号比它小的报文段都已确认送达.snd_nxt: 下一个等待发送的报文段的编号.rcv_nxt: 下一个等待接收的报文段的编号.ts_recent,ts_lastack: 未使用.ssthresh: Slow Start Threshold, 慢启动阈值.rx_rto: Retransmission TimeOut(RTO), 超时重传时间.rx_rttval,rx_srtt,rx_minrto: 计算rx_rto的中间变量.snd_wnd,rcv_wnd: 发送窗口和接收窗口的大小.rmt_wnd: 对端剩余接收窗口的大小.cwnd: congestion window, 拥塞窗口. 用于拥塞控制.probe: 是否要发送控制报文的标志.current: 当前时间.interval: flush 的时间粒度.ts_flush: 下次需要 flush 的时间.xmit: 该链接超时重传的总次数.nrcv_buf,nsnd_buf,nrcv_que,nsnd_que: 接收缓冲区, 发送缓冲区, 接收队列, 发送队列的长度.nodelay: 是否启动快速模式. 用于控制 RTO 增长速度.updated: 是否调用过ikcp_update.ts_probe,probe_wait: 确定何时需要发送窗口询问报文.dead_link: 当一个报文发送超时次数达到dead_link次时认为连接断开.incr: 用于计算 cwnd.snd_queue,rcv_queue: 发送队列和接收队列.snd_buf,rcv_buf: 发送缓冲区和接收缓冲区.acklist,ackcount,ackblock: ACK 列表, ACK 列表的长度和容量. 待发送的 ACK 的相关信息会先存在 ACK 列表中, flush 时一并发送.buffer: flush 时用到的临时缓冲区.fastresend: ACK 失序fastresend次时触发快速重传.fastlimit: 传输次数小于fastlimit的报文才会执行快速重传.nocwnd: 是否不考虑拥塞窗口.stream: 是否开启流模式, 开启后可能会合并包.logmask: 用于控制日志. 本文不讨论它.output: 下层协议输出函数.writelog: 日志函数. 本文不讨论它.
3.3 队列与缓冲区
我们先来看 snd_queue, rcv_queue, snd_buf 和 rcv_buf 这四个字段. 它们分别是发送队列, 接收队列, 发送缓冲区和接收缓冲区. 队列和缓冲区其实都是循环双链表, 链表节点的类型都是 struct IKCPSEG.
调用 ikcp_send 发送数据时会先将数据加入 snd_queue 中, 然后再伺机加入 snd_buf. 每次调用 ikcp_flush 时都将 snd_buf 中满足条件的报文段都发送出去. 之所以不将报文直接加入 snd_buf 是为了防止一次发送过多的报文导致拥塞, 需要再拥塞算法的控制下伺机加入 snd_buf 中.
调用 ikcp_input 收到的数据解包后会先放入 rcv_buf 中, 再在合适的情况下转移到 rcv_queue 中. 调用 ikcp_recv 接收数据时会从 rcv_queue 取出数据返回给调用者. 这样做是因为报文传输的过程中会出现丢包, 失序等情况. 为了保证顺序, 需要将收到的报文先放入 rcv_buf 中, 只有当 rcv_buf 中的报文段顺序正确才能将其移动到 rcv_queue 中供调用者接收. 如下图所示, rcv_buf 中节点为灰色表示可以移动到 rcv_queue 中. 只有当 2 号报文重传成功后, 才能将 2, 3, 4 号报文移动到 rcv_queue 中.

3.3.1 链表的实现
队列和缓冲区都是循环双链表, 它是由一组宏实现的:
struct IQUEUEHEAD {
struct IQUEUEHEAD *next, *prev;
};
#define IQUEUE_HEAD_INIT(name) { &(name), &(name) }
#define IQUEUE_HEAD(name) \
struct IQUEUEHEAD name = IQUEUE_HEAD_INIT(name)
#define IQUEUE_INIT(ptr) ( \
(ptr)->next = (ptr), (ptr)->prev = (ptr))
#define IOFFSETOF(TYPE, MEMBER) ((size_t) &((TYPE *)0)->MEMBER)
#define ICONTAINEROF(ptr, type, member) ( \
(type*)( ((char*)((type*)ptr)) - IOFFSETOF(type, member)) )
#define IQUEUE_ENTRY(ptr, type, member) ICONTAINEROF(ptr, type, member)
#define IQUEUE_ADD(node, head) ( \
(node)->prev = (head), (node)->next = (head)->next, \
(head)->next->prev = (node), (head)->next = (node))
#define IQUEUE_ADD_TAIL(node, head) ( \
(node)->prev = (head)->prev, (node)->next = (head), \
(head)->prev->next = (node), (head)->prev = (node))
#define IQUEUE_DEL(entry) (\
(entry)->next->prev = (entry)->prev, \
(entry)->prev->next = (entry)->next, \
(entry)->next = 0, (entry)->prev = 0)
#define IQUEUE_IS_EMPTY(entry) ((entry) == (entry)->next)
struct IQUEUEHEAD 为带头节点的循环双链表的一个节点, 它有两个指针, next 指向后一个节点, prev 指向前一个节点; IQUEUE_INIT 初始化时将 next 和 prev 都指向自己, 这标志着链表为空 (见 IQUEUE_IS_EMPTY). IQUEUE_ADD 将节点插入到 head 后面; IQUEUE_ADD_TAIL 将节点插入到 head 前面, 因为是循环链表, 所以插到头节点前面就相当于插到链表末尾. 这些都很好理解.
struct IKCPSEG 中的 node 字段为链表节点. 将一个报文段插入链表时, 实际上是将它的 node 字段插入链表中. 那么从链表中取出节点时怎么将它还原成报文段呢? IQUEUE_ENTRY 这个宏通过链表节点获取包含这个节点的对象. IQUEUE_ENTRY 需要传入节点的指针, 包含这个节点的对象的类型, 以及节点所在的成员. 例如对于链表节点指针 p, 我们要还原成 struct IKCPSEG 指针, 只需调用 IQUEUE_ENTRY(p, struct IKCPSEG, node). 原理是通过 IOFFSETOF 这个宏获取节点成员在结构体中的地址偏移, 然后再用节点的地址减去地址偏移, 就能得到这个结构体对象的地址. &((TYPE *)0)->MEMBER 这个表达式对 NULL 指针执行 -> 操作, 但因为只是取地址而并没有访问那个地址, 所以没有任何问题.
4. 发送, 接收与重传
前面介绍数据结构时我们知道了 ACK 报文为数据报文的确认, 队列和缓冲区的关系. 这一节我们详细讨论 KCP 的整个 ARQ 流程. 首先介绍发送, 接收和重传的整体流程, 然后是 KCP 发送和接收的滑动窗口, 以及它们在发送和接收中的变化情况; 接着会讨论快速重传和 RTO 计算方式; 最后展示 KCP 的代码, 看它具体是如何实现的.
4.1 整体流程
KCP 的整个发送, 接收与重传的流程大体如下:
-
调用
ikcp_send发送数据, 创建报文段实例, 加入snd_queue中. -
ikcp_update会在合适的时刻调用ikcp_flush. -
ikcp_flush会做:- 发送 ACK 列表中所有的 ACK;
- 检查是否需要发送窗口探测和通知报文, 如果需要就发送相应的报文;
- 根据发送窗口大小, 将适量的报文段从
snd_queue移入到snd_buf中; - 将
snd_buf中满足条件的报文段都发送出去. 这里的条件有:- 新加入
snd_buf中, 从未发送过的报文直接发送出去; - 发送过的, 但是在 RTO 内未收到 ACK 的报文, 需要重传;
- 发送过的, 但是 ACK 失序若干次的报文, 需要执行快速重传.
- 新加入
- 根据丢包情况计算 ssthresh 和 cwnd.
这样, 刚才调用
ikcp_send传入的数据就在ikcp_flush中被发送出去了. -
报文到达对端.
-
ikcp_input会被调用, 解析收到的数据:- 所有的报文都有 una 字段, 根据 una 将相应的报文标记为已送达;
- 如果是 ACK 报文, 就将相应的报文标记为已送达;
- 如果是数据报文, 就将它放入
rcv_buf, 然后将rcv_buf中顺序正确的报文移入rcv_queue; 接着将相关信息插入 ACK 列表, 在稍后的ikcp_flush调用中会发送相应的 ACK; - 如果是窗口探测报文, 就标记 "需要发送窗口通知". 在稍后的
ikcp_flush调用中会发送窗口通知报文; - 包括窗口通知报文在内的所有报文都有 wnd 字段, 据此更新
rmt_wnd; - 根据 ACK 失序情况决定快速重传;
- 计算 cwnd.
-
调用
ikcp_recv接收数据, 从rcv_queue中读取数据.
之后 ACK 会返回给发送方, 发送方在 ikcp_input 中解析到 ACK, 将对应的报文标记为已送达, 这就完成了一次发送. 如果发生了丢包, 发送方最终收不到 ACK. 这会导致重传.
发送队列和接收队列确实是队列, 报文总是先进先出的, 因此上面说的诸如 "加入 snd_queue" 和 "从 rcv_queue 中读取", 都是简单的入队出队. 但是发送缓冲区和接收缓冲区就相对复杂些, 下一节我们详细讨论这个问题.
4.2 滑动窗口
发送缓冲区 snd_buf 和接收缓冲区 rcv_buf 中活动的报文都是在滑动窗口之中的. 滑动窗口实际是一个抽象的概念, 不能简单地认为它是缓冲区的一部分, 稍后我们能看到, 接收窗口的一部分是接收队列.
4.2.1 发送
发送窗口的结构如下图所示. 灰色节点表示已送达的报文, 白色节点表示已发送但尚未确认到达的报文. 其中白色节点表示的报文存在于 snd_buf 中, 而灰色节点表示的已确认送达的报文已经从 snd_buf 中删除. 这里还有两个指针: snd_una 指向第一个尚未确认到达的报文, 也就是说在它之前的报文都已确认到达; snd_nxt 指向下一个插入缓冲区的位置. 滑动窗口的起始位置是 snd_una, 大小为 cwnd.

每次 flush 时都会从 snd_queue 中取出报文插入 snd_buf 中 snd_nxt 指向的位置, 然后 snd_nxt 向右移动. KCP 会动态计算窗口大小 cwnd, 当 snd_nxt - snd_una >= cwnd 时, 便不允许新的报文加入 snd_buf. 这时须等报文确认到达, snd_una 向右移动, 方可继续发送. 每次 flush 其实是将发送窗口中的报文尽可能地发送出去. 因此, cwnd 的大小决定了发送速率.
在 KCP 的实现中, snd_buf 是一个报文段链表, 链表中的报文段编号始终递增. 报文段插入 snd_buf 时会追加到链表的尾部, 确认到达的报文段则会从链表中删除.
发送窗口中未确认到达的报文何时重传, 取决于这个报文的 RTO. 报文在一个 RTO 时间内仍未确认到达, 就会重传. 报文的 RTO 初始值会被赋为 rx_rto, 之后每次超时重传, RTO 都会以某种方式增长. KCP 的 RTO 增长速率可配置, 或翻倍, 或翻 0.5 倍. 此外还有快速重传机制, 我们会在 4.3 节中讨论.
4.2.2 接收
接收窗口结构如下图所示. 这里灰色节点表示顺序正确, 已经移动到 rcv_queue 中的报文. 注意下图表示的是 snd_queue 和 snd_buf 的结合体, 灰色节点都在 rcv_queue 中, 其余 rcv_nxt 及其右边的部分为 rcv_buf. 滑动窗口的起始位置为 rcv_queue 的队首, 大小为 rcv_wnd.

每收到一个数据报文, 都会根据它的编号将它插入到 rcv_buf 对应的位置中. 接着检查 rcv_nxt 能否向右移动, 只有当报文的顺序正确且连续才能移动. 在上图的例子中由于 4 号报文的缺失, rcv_nxt 只能处于 4 号位置等待, 5, 6 号报文也不能移动到 rcv_queue 中. 需等到 4 号报文到达后, 才能将 4, 5, 6 号报文一并移动到 rcv_queue 中; 同时 rcv_nxt 会右移到 7 号位置.
nrcv_que 为接收队列的长度. KCP 会通知发送方剩余接收窗口的大小为 rcv_wnd - nrcv_que, 发送方应根据这个值调整 cwnd, 确保发送速率不超过对方的接收速率; 接收方也应该及时读取 rcv_queue 中的数据, 让窗口向右滑动, 以保证有充足的接收窗口. 如果接收到数据报文的编号大于 rcv_nxt + rcv_wnd, 远超窗口之外, 这个报文就会被丢弃.
在 KCP 的实现中, rcv_buf 同样是一个报文段链表, 链表中报文段编号始终递增. 当收到新的报文时, 会根据编号插入到链表中相应的位置中; 顺序正确的报文会从链表头部弹出, 移动到 rcv_queue 中.
回想起 3.1 节中所说的, 每个报文都会带上 una 字段, 表示该报文发送者的接收缓冲区中最小还未收到的报文编号. 不难发现, 这其实就是 rcv_nxt. 因此 KCP 发送的每个报文都会将 una 字段赋值为 rcv_nxt. 这样就有了 ACK + UNA 双重确认机制, 即使 ACK 丢包, 也可以通过稍后的 una 确认报文已送达.
4.2.3 例子
我们举个简单的例子演示整个 ARQ 的流程. 下图中实线箭头表示数据报文, 虚线箭头表示 ACK.

- t1 时刻发送方发送 1 号报文, 1 号报文放入发送缓冲区中,
snd_una指向 1,snd_nxt指向 2. - t2 至 t3 时刻发送方依次发送 2 至 3 号报文,
snd_nxt依次后移. - 1 号报文丢包.
- t4, t5 时刻接收方收到 3 号和 2 号报文, 放入
rcv_buf中; 随后回复 3 号和 2 号 ACK. 此时由于 1 号报文缺失,rcv_nxt始终指向 1. - 3 号 ACK 丢包.
- t7 时刻发送方收到 2 号 ACK, 将 2 号报文标记为已送达. 此时由于 3 号 ACK 丢包, 3 号报文未标记为已送达. 由于 1 号报文未确认送达,
snd_una亦指向 1. - t8 时刻 1 号报文超时, 重传.
- t9 时刻接收方收到 1 号报文, 放入
rcv_buf中; 这时 1, 2, 3 号报文顺序正确,rcv_nxt右移到 4 号位置. 接收方回复 1 号 ACK, 同时带上 una = 4. - t10 时刻发送方收到 1 号 ACK, 将 1 号报文标记为已送达. 同时 una 表明 1, 2, 3 号报文均已送达, 因此也将 3 号报文标记为已送达.
snd_una移动到 4.
4.3 快速重传
除了超时重传, KCP 还有快速重传机制. 假设发送方依次发送了 1, 2, 3, 4 号报文, 随后收到 1, 3, 4 号 ACK. 收到 3 号 ACK 时, 我们知道 2 号 ACK 失序了一次, 收到 4 号 ACK 时, 我们知道 2 号失序了两次. ACK 失序次数越多说明它丢包的概率越大, KCP 会直接重传失序次数过多的报文, 而不用等待其超时.

每个报文的 fastack 字段记录了它检测到 ACK 失序的次数. 每当 KCP 收到一个编号为 sn 的 ACK 时, 就会检查 snd_buf 中编号小于 sn 且未确认送达的报文, 将其 fastack 加一. 我们可以通过配置 fastresend 指定失序多少次就执行快速重传. 每次调用 ikcp_flush 时都会重传 snd_buf 中 fastack 不小于 fastresend 的报文.
报文也不会无限制地执行快速重传. 每个报文的 xmit 字段记录它被传输的次数, KCP 的 fastlimit 字段规定了传输次数小于 fastlimit 的报文才能执行快速重传.
4.4 计算 RTO
每个报文 RTO 的会随着重传次数的增加而增加, 其初始值保存在字段 rx_rto 中. 一个设置得当的 RTO 是保证 ARQ 性能的关键. KCP 计算 RTO 初始值的方法是 TCP 的标准方法, 规定在 RFC 6298 中.
标准方法通过 RTT 计算 RTO. 这是容易理解的: 报文从发出到收到 ACK 经过的时间应为一个 RTT, 如果某个报文在一个 RTT 内未收到 ACK, 说明它很有可能丢包了. 因此 RTO 应该与 RTT 呈正相关, 且应高于 RTT 以容忍一定程度的抖动.
计算过程要维护两个中间变量, srtt 和 rttvar, 每次收到一个 ACK 都能得到一个 RTT, 然后计算更新中间变量, 然后得出 RTO. 具体方法如下:
和 是常数, 取 , 取 . 为计时器粒度, 也就是调用 ikcp_flush 的时间间隔. 这种算法称为指数加权移动平均, srtt 是对一段时间内 RTT 平均值的估计, 新的 srtt 有 取决于旧的 srtt, 取决于当前 RTT; 而 rttvar 是对 RTT 平均偏差的估计, 新的 rttvar 有 取决于旧的 rttvar, 取决于当前偏差. 最终 RTO 等于 RTT 的平均值加上四倍的 RTT 平均抖动值, 并且至少为一个计时器粒度.
srtt 和 rttvar 会按上述方法更新, 但在此之前也需要设置初始值. 标准方法的做法是测得第一个 RTT 时初始化 srtt 和 rttvar, 其值为:
4.5 实现
我们最后再来看 KCP 的代码是如何实现的. 前面几节已经介绍过 KCP 的 ARQ 原理, 这一节就直接展示注释过的 KCP 源码. 代码比较长, 这里适当做精简, 建议读者对照 KCP 源码阅读.
4.5.1 发送
ikcp_send 根据传入的数据, 创建若干个报文段对象, 放入 snd_queue 中.
int ikcp_send(ikcpcb *kcp, const char *buffer, int len)
{
IKCPSEG *seg;
int count, i;
assert(kcp->mss > 0);
if (len < 0) return -1;
if (kcp->stream != 0) {
// 如果是流模式就合并包, 将 buffer 中的数据尽可能地追加到 snd_queue 中的最后一个报文中
...
}
// 计算出分片数量 = buffer 长度 / 最大报文段大小(mss), 向上取整.
if (len <= (int)kcp->mss) count = 1;
else count = (len + kcp->mss - 1) / kcp->mss;
if (count >= (int)IKCP_WND_RCV) return -2;
if (count == 0) count = 1;
// 创建 count 个报文段对象并加入 snd_queue
for (i = 0; i < count; i++) {
int size = len > (int)kcp->mss ? (int)kcp->mss : len;
seg = ikcp_segment_new(kcp, size); // 创建报文段对象
assert(seg);
if (seg == NULL) {
return -2;
}
if (buffer && len > 0) {
memcpy(seg->data, buffer, size); // 复制数据
}
seg->len = size;
seg->frg = (kcp->stream == 0)? (count - i - 1) : 0; // 剩余分片数量
iqueue_init(&seg->node);
iqueue_add_tail(&seg->node, &kcp->snd_queue); // 加入 snd_queue
kcp->nsnd_que++;
if (buffer) {
buffer += size; // buffer 指针后移
}
len -= size;
}
return 0;
}
之后在 ikcp_update 的驱动下, 会调用到 ikcp_flush.
void ikcp_flush(ikcpcb *kcp)
{
IUINT32 current = kcp->current; // 当前时间
char *buffer = kcp->buffer; // 临时缓冲区
char *ptr = buffer;
int count, size, i;
IUINT32 resent, cwnd;
IUINT32 rtomin;
struct IQUEUEHEAD *p;
int change = 0; // 是否执行过快速重传
int lost = 0; // 是否执行过超时重传
IKCPSEG seg;
if (kcp->updated == 0) return;
seg.conv = kcp->conv;
seg.cmd = IKCP_CMD_ACK; // ACK 报文段
seg.wnd = ikcp_wnd_unused(kcp); // 通知对端剩余接收窗口大小为 rcv_wnd - nrcv_que (4.2.2 节)
seg.una = kcp->rcv_nxt; // 将 una 赋值为 rcv_nxt (4.2.2 节)
// seg.frg, seg.len, seg.sn, seg.ts 均赋值为 0
...
// 发送 ACK 列表中所有的 ACK
count = kcp->ackcount;
for (i = 0; i < count; i++) {
size = (int)(ptr - buffer);
if (size + (int)IKCP_OVERHEAD > (int)kcp->mtu) { // buffer 中累计的数据将要大于一个 MTU, 就发送 buffer 中的数据.
ikcp_output(kcp, buffer, size); // 之后会多次出现这段代码, 以 <FLUSH_BUFFER> 代替之.
ptr = buffer;
}
ikcp_ack_get(kcp, i, &seg.sn, &seg.ts); // 从 ACK 列表中取出 ACK 的编号和时间戳
ptr = ikcp_encode_seg(ptr, &seg); // ACK 报文写入 buffer
}
kcp->ackcount = 0;
if (kcp->rmt_wnd == 0) {
// 对端剩余接收窗口大小为 0, 可能需要发送窗口探测报文. 根据 ts_probe 和 probe_wait 确定当前时刻是否需要发送探测报文.
...
} else {
kcp->ts_probe = 0;
kcp->probe_wait = 0;
}
if (kcp->probe & IKCP_ASK_SEND) { // 检查是否需要发送窗口探测报文
seg.cmd = IKCP_CMD_WASK;
<FLUSH_BUFFER>
ptr = ikcp_encode_seg(ptr, &seg); // 报文写入 buffer
}
if (kcp->probe & IKCP_ASK_TELL) { // 检查是否需要发送窗口通知报文
seg.cmd = IKCP_CMD_WINS;
... // 同窗口探测报文
}
kcp->probe = 0;
cwnd = ... // 计算 cwnd
// 将报文从 snd_queue 移动到 snd_buf. snd_nxt - snd_una 不超过 cwnd. (4.2.1 节)
while (_itimediff(kcp->snd_nxt, kcp->snd_una + cwnd) < 0) {
IKCPSEG *newseg;
if (iqueue_is_empty(&kcp->snd_queue)) break; // snd_queue 为空, break
newseg = iqueue_entry(kcp->snd_queue.next, IKCPSEG, node); // 取队首的报文段
iqueue_del(&newseg->node); // 出队
iqueue_add_tail(&newseg->node, &kcp->snd_buf); // 插入 snd_buf
kcp->nsnd_que--;
kcp->nsnd_buf++;
// 给 newseg 的各个字段赋值. 这里作部分省略
newseg->cmd = IKCP_CMD_PUSH;
newseg->sn = kcp->snd_nxt++; // snd_nxt 自增
...
}
// 快速重传, fastresend 为 0 便不执行快速重传
resent = (kcp->fastresend > 0)? (IUINT32)kcp->fastresend : 0xffffffff;
rtomin = (kcp->nodelay == 0)? (kcp->rx_rto >> 3) : 0;
// 将 snd_buf 中满足条件的报文段都发送出去 (4.1 节)
for (p = kcp->snd_buf.next; p != &kcp->snd_buf; p = p->next) {
IKCPSEG *segment = iqueue_entry(p, IKCPSEG, node);
int needsend = 0;
if (segment->xmit == 0) { // 新加入 snd_buf 中, 从未发送过的报文直接发送出去
needsend = 1;
segment->xmit++;
segment->rto = kcp->rx_rto; // RTO 初始为 rx_rto
segment->resendts = current + segment->rto + rtomin; // 重传时间戳
}
else if (_itimediff(current, segment->resendts) >= 0) { // 发送过的, 但是在 RTO 内未收到 ACK 的报文, 需要重传
needsend = 1;
segment->xmit++;
kcp->xmit++; // 超时重传的总次数
// 每超时重传一次, RTO 都增长
if (kcp->nodelay == 0) {
segment->rto += _imax_(segment->rto, (IUINT32)kcp->rx_rto); // RTO 翻倍增长
} else {
IINT32 step = (kcp->nodelay < 2)?
((IINT32)(segment->rto)) : kcp->rx_rto;
segment->rto += step / 2; // RTO 翻 0.5 倍增长
}
segment->resendts = current + segment->rto; // 重传时间戳
lost = 1;
}
else if (segment->fastack >= resent) { // 发送过的, 但是 ACK 失序超过 resent 次的报文, 需要执行快速重传. (4.3 节)
if ((int)segment->xmit <= kcp->fastlimit ||
kcp->fastlimit <= 0) { // 快速重传次数限制
needsend = 1;
segment->xmit++;
segment->fastack = 0;
segment->resendts = current + segment->rto;
change++;
}
}
if (needsend) {
int need;
// 赋值 segment->ts, segment->wnd, segment->una
...
<FLUSH_BUFFER>
ptr = ikcp_encode_seg(ptr, segment); // 报文写入 buffer
if (segment->len > 0) {
memcpy(ptr, segment->data, segment->len); // 报文的数据段也要写入 buffer
ptr += segment->len;
}
if (segment->xmit >= kcp->dead_link) { // 报文传输次数大于一定值, 连接断开
kcp->state = (IUINT32)-1;
}
}
}
// 发送 buffer 中剩余的报文段
size = (int)(ptr - buffer);
if (size > 0) {
ikcp_output(kcp, buffer, size);
}
// 根据丢包情况计算 ssthresh 和 cwnd. 会在第 5 节中讨论
...
}
4.5.2 接收
数据到达会调用 ikcp_input.
int ikcp_input(ikcpcb *kcp, const char *data, long size)
{
IUINT32 prev_una = kcp->snd_una; // 收到报文后, snd_una 可能会向右移动. 这里保存移动前的 snd_una
IUINT32 maxack = 0, latest_ts = 0;
int flag = 0;
...
if (data == NULL || (int)size < (int)IKCP_OVERHEAD) return -1;
while (1) {
// 报文的各个字段
IUINT32 ts, sn, len, una, conv;
IUINT16 wnd;
IUINT8 cmd, frg;
IKCPSEG *seg;
if (size < (int)IKCP_OVERHEAD) break;
... // 调用 ikcp_decode* 解包, 为各个字段赋值.
if (conv != kcp->conv) return -1; // 检查 conv
size -= IKCP_OVERHEAD;
if ((long)size < (long)len || (int)len < 0) return -2;
if (cmd != IKCP_CMD_PUSH && cmd != IKCP_CMD_ACK &&
cmd != IKCP_CMD_WASK && cmd != IKCP_CMD_WINS) // 检查 cmd
return -3;
kcp->rmt_wnd = wnd; // 更新 rmt_wnd
ikcp_parse_una(kcp, una); // 根据 una 将相应已确认送达的报文从 snd_buf 中删除
ikcp_shrink_buf(kcp); // 尝试向右移动 snd_una
if (cmd == IKCP_CMD_ACK) { // ACK 报文
if (_itimediff(kcp->current, ts) >= 0) {
// 这里计算 RTO, _itimediff(kcp->current, ts) 便是 RTT.
// 其计算方法与 4.4 节列出的公式一致, 具体代码不展示了, 读者可自行参阅 KCP 源码.
ikcp_update_ack(kcp, _itimediff(kcp->current, ts));
}
ikcp_parse_ack(kcp, sn); // 将已确认送达的报文 snd_buf 中删除.
ikcp_shrink_buf(kcp); // 尝试向右移动 snd_una
if (flag == 0) { // 这里计算出这次 input 得到的最大 ACK 编号
flag = 1;
maxack = sn;
} else {
if (_itimediff(sn, maxack) > 0) {
maxack = sn;
...
}
}
...
}
else if (cmd == IKCP_CMD_PUSH) { // 数据报文
...
if (_itimediff(sn, kcp->rcv_nxt + kcp->rcv_wnd) < 0) {
ikcp_ack_push(kcp, sn, ts); // 将相关信息 (报文编号和时间戳) 插入 ACK 列表中
if (_itimediff(sn, kcp->rcv_nxt) >= 0) {
seg = ikcp_segment_new(kcp, len);
seg->conv = conv;
... // 赋值各个字段
if (len > 0) {
memcpy(seg->data, data, len);
}
ikcp_parse_data(kcp, seg); // 插入 rcv_buf
}
}
}
else if (cmd == IKCP_CMD_WASK) { // 窗口探测
kcp->probe |= IKCP_ASK_TELL; // 标记需要发送窗口通知报文
}
else if (cmd == IKCP_CMD_WINS) { // 窗口通知
// 什么都不用做, wnd 字段前面已经取得了
}
else {
return -3;
}
data += len;
size -= len;
}
if (flag != 0) {
ikcp_parse_fastack(kcp, maxack, latest_ts); // 检查 snd_buf 中编号小于 maxack 且未确认送达的报文, 将其 fastack 加一
}
... // 计算 cwnd. 会在第 5 节中讨论
return 0;
}
对于 ACK, 会调用 ikcp_parse_ack 将对应已送达的报文从 snd_buf 中删除. 删除之后, 之后的 ikcp_flush 调用中自然不用考虑重传问题了. ikcp_parse_una 的做法与之类似, 这里只展示 ikcp_parse_ack:
static void ikcp_parse_ack(ikcpcb *kcp, IUINT32 sn)
{
struct IQUEUEHEAD *p, *next;
if (_itimediff(sn, kcp->snd_una) < 0 || _itimediff(sn, kcp->snd_nxt) >= 0)
return;
for (p = kcp->snd_buf.next; p != &kcp->snd_buf; p = next) { // 遍历 snd_buf
IKCPSEG *seg = iqueue_entry(p, IKCPSEG, node);
next = p->next;
if (sn == seg->sn) { // 找到对应编号的报文, 将它删除
iqueue_del(p);
ikcp_segment_delete(kcp, seg);
kcp->nsnd_buf--;
break;
}
if (_itimediff(sn, seg->sn) < 0) {
break;
}
}
}
对于数据报文, 则调用 ikcp_parse_data 将其插入 rcv_buf, 然后会尽可能地将顺序正确的报文移入 rcv_queue.
void ikcp_parse_data(ikcpcb *kcp, IKCPSEG *newseg)
{
struct IQUEUEHEAD *p, *prev;
IUINT32 sn = newseg->sn;
int repeat = 0;
// 如果接收到数据报文的编号大于 rcv_nxt + rcv_wnd 或小于 rcv_nxt, 这个报文就会被丢弃. (4.2.2 节)
if (_itimediff(sn, kcp->rcv_nxt + kcp->rcv_wnd) >= 0 ||
_itimediff(sn, kcp->rcv_nxt) < 0) {
ikcp_segment_delete(kcp, newseg);
return;
}
// 在 rcv_buf 中寻找一个合适的位置以便插入
for (p = kcp->rcv_buf.prev; p != &kcp->rcv_buf; p = prev) { // 从后往前遍历
IKCPSEG *seg = iqueue_entry(p, IKCPSEG, node);
prev = p->prev;
if (seg->sn == sn) { // 如果遇到编号相等的, 则是重复报文
repeat = 1;
break;
}
if (_itimediff(sn, seg->sn) > 0) { // 找到第一个编号比它小的
break;
}
}
if (repeat == 0) { // 插入
iqueue_init(&newseg->node);
iqueue_add(&newseg->node, p);
kcp->nrcv_buf++;
} else { // 重复报文直接丢弃
ikcp_segment_delete(kcp, newseg);
}
while (! iqueue_is_empty(&kcp->rcv_buf)) { // rcv_nxt 尝试向后移动, 将顺序正确的报文移动到 rcv_queue 中 (4.2.2 节)
IKCPSEG *seg = iqueue_entry(kcp->rcv_buf.next, IKCPSEG, node);
if (seg->sn == kcp->rcv_nxt && kcp->nrcv_que < kcp->rcv_wnd) { // 保证接收窗口大小不小于 0
iqueue_del(&seg->node);
kcp->nrcv_buf--;
iqueue_add_tail(&seg->node, &kcp->rcv_queue);
kcp->nrcv_que++;
kcp->rcv_nxt++;
} else {
break;
}
}
}
最后接收方调用 ikcp_recv 从 rcv_queue 中读取数据.
int ikcp_recv(ikcpcb *kcp, char *buffer, int len)
{
struct IQUEUEHEAD *p;
int ispeek = (len < 0)? 1 : 0;
int peeksize;
int recover = 0;
IKCPSEG *seg;
assert(kcp);
if (iqueue_is_empty(&kcp->rcv_queue)) return -1;
if (len < 0) len = -len;
peeksize = ikcp_peeksize(kcp); // rcv_queue 中第一个包的大小. 这需要考虑到分片
if (peeksize < 0) return -2;
if (peeksize > len) return -3;
if (kcp->nrcv_que >= kcp->rcv_wnd) recover = 1;
for (len = 0, p = kcp->rcv_queue.next; p != &kcp->rcv_queue; ) { // 从 rcv_queue 取出报文读入 buffer
int fragment;
seg = iqueue_entry(p, IKCPSEG, node);
p = p->next;
if (buffer) {
memcpy(buffer, seg->data, seg->len); // 复制到 buffer 中
buffer += seg->len;
}
len += seg->len;
fragment = seg->frg;
if (ispeek == 0) { // 如果 len 小于 0, 则不消耗 rcv_queue
iqueue_del(&seg->node);
ikcp_segment_delete(kcp, seg);
kcp->nrcv_que--;
}
if (fragment == 0)
break;
}
assert(len == peeksize);
while (! iqueue_is_empty(&kcp->rcv_buf)) { // rcv_queue 空些了, 再尝试从 rcv_buf 中取些报文到 rcv_queue
seg = iqueue_entry(kcp->rcv_buf.next, IKCPSEG, node);
... // 与 ikcp_parse_data 中相同
}
// fast recover
if (kcp->nrcv_que < kcp->rcv_wnd && recover) {
// ready to send back IKCP_CMD_WINS in ikcp_flush
// tell remote my window size
kcp->probe |= IKCP_ASK_TELL;
}
return len;
}
5. 拥塞控制
报文不能无限制地发送. 因为网路容量是有限的, 接收方缓冲区的大小也是有限的; 如果无限制地发送数据, 必然会导致网路和缓冲区无法容纳发送的数据, 从而导致大量丢包. 此外网路中的连接不只一个, 如果所有的连接都无限制地发送报文, 便会导致恶性竞争, 最终网路的拥塞会导致所有人都无法使用. 因此即使是为流速设计的 KCP, 拥塞控制也是不可或缺的.
前面 4.2.1 节讨论了, cwnd 的大小决定了发送速率. 因此, 拥塞控制实际上就是动态计算 cwnd 的过程. KCP 拥塞控制的策略与 TCP 类似, 分为慢启动(Slow Start), 拥塞避免(Congestion Avoidance)和快速恢复(Fast Recovery).
5.1 拥塞控制策略
理想情况下, 发送数据的速率正好等于网路的容量, 然而我们并不知道网路的实际容量. 我们的做法是先将 cwnd 设为 1, 随后平均每经过一个 RTT 时间 cwnd 都翻一倍, 以探测到何时会出现丢包. 这种方法便是慢启动.
在慢启动中 cwnd 会指数增长, 这个过程显然不能一直持续下去. 当 cwnd 超过一个阈值之后, 便会进入拥塞避免阶段. 这个阈值我们称为慢启动阈值(Slow Start Threshold), 通常记作 ssthresh. 在拥塞避免阶段, cwnd 会近似于线性增长.
无论是慢启动还是拥塞避免, 随着 cwnd 的增长, 网路容量会被逐步填满. 网络容量填满之后, 就会不可避免地出现丢包. 这就意味着我们的发送速率过大, cwnd 应该减小了. KCP 称之为丢包退让. 此时有两种策略: 一种是将 ssthresh 置为当前 cwnd 的一半, 然后 cwnd 置为 1, 重新执行慢启动; 另一种也会将 ssthresh 置为当前 cwnd 的一半, 但 cwnd 置为比 ssthresh 稍高的值, 然后进入快速恢复阶段. 快速恢复阶段中, cwnd 会以与拥塞避免相同的方式线性增长. KCP 采用的策略是, 如果发生超时重传, 就进入慢启动; 如果发生快速重传, 就进入快速恢复.
下图展示了拥塞控制中 cwnd 和 ssthresh 的变化情况.

此外无论如何发送速率都不应该超过对端的接收速率, 否则数据一定会超出对端接收缓冲区的容量. 因此 接收方会不断地向对端汇报接收窗口的剩余大小, 发送方会限制 cwnd 不超过 rmt_wnd.
KCP 为流速设计, 在传递一些及时性要求很高的小数据时, 可以选择不执行慢启动和拥塞避免. 此时 cwnd 的大小仅取决于 snd_wnd 和 rmt_wnd 二者的最小值, 其中 snd_wnd 为配置值.
5.2 慢启动
慢启动时, 平均每经过一个 RTT 时间 cwnd 都翻一倍. 实际的做法是, 每收到一个 ACK cwnd 都加一. 初始 cwnd 为 1, 发送 1 个报文段, 随后收到 1 个 ACK, cwnd 加一等于 2; 现在 cwnd 为 2, 发送 2 个报文段, 随后收到 2 个 ACK, cwnd 自增两次等于 4. 以此类推, cwnd 就会指数增长.
慢启动中 cwnd 的变化情况如下图所示.

5.3 拥塞避免和快速恢复
在拥塞避免阶段, 差不多要等当前发送窗口发的报文都确认到达之后, cwnd 才增加 1. 这时的 cwnd 近似于线性增长, 这种增长方式与慢启动的指数增长相比缓慢许多. 拥塞避免阶段的 cwnd 变化情况如下图所示.

在 KCP 的实现中, 拥塞避免阶段的 cwnd 仍然会在每收到一个 ACK 的时候增长, 只不过不是增加 1, 而是增加零点几. KCP 的做法是维护一个中间变量 incr, 其含义可以认为是 cwnd 的 mss 倍. 在拥塞避免阶段, 每收到一个 ACK, incr 都会以如下方式增长:
然后当 incr 累计增加的值超过一个 mss 时, cwnd 增加 1, 保持 incr 与 cwnd 之间的倍数关系. 因为 , 所以有
如果抛开后面的 不看, 实际上相当于每收到一个 ACK, cwnd 都自增 . 这就满足了前面所说的, 要等当前发送窗口发的报文都确认到达之后, cwnd 才增加 1. 事实上 (1) 式去掉后面的 就是 TCP 拥塞避免阶段 cwnd 的增长方式. KCP 在这个基础上加上了 , 让 cwnd 的增长速度比 TCP 稍快一些.
5.4 实现
最后我们来看 KCP 的实现. 这里同样直接展示注释过的代码.
5.4.1 丢包退让
在 ikcp_flush 中检测到丢包, 即出现超时重传或快速重传时, 就执行丢包退让, 调整 cwnd 和 ssthresh, 进入慢启动或快速恢复.
void ikcp_flush(ikcpcb *kcp)
{
...
int change = 0; // 是否执行过快速重传
int lost = 0; // 是否执行过超时重传
...
cwnd = _imin_(kcp->snd_wnd, kcp->rmt_wnd); // cwnd 不超过对端剩余接收窗口大小 rmt_wnd
if (kcp->nocwnd == 0) cwnd = _imin_(kcp->cwnd, cwnd); // 如果设置了 nocwnd, 则 cwnd 只取决于 snd_wnd 和 rmt_wnd
...
if (change) { // 发生快速重传, 进入快速恢复
IUINT32 inflight = kcp->snd_nxt - kcp->snd_una; // 发送窗口中报文的数量, 这个值小于等于 cwnd
kcp->ssthresh = inflight / 2; // ssthresh 置为 inflight 的一半
if (kcp->ssthresh < IKCP_THRESH_MIN)
kcp->ssthresh = IKCP_THRESH_MIN;
kcp->cwnd = kcp->ssthresh + resent; // cwnd 置为比 ssthresh 稍高的值, resent 等于 fastresend
kcp->incr = kcp->cwnd * kcp->mss; // incr 为 cwnd 的 mss 倍
}
if (lost) { // 发生超时重传, 进入慢启动
kcp->ssthresh = cwnd / 2; // ssthresh 置为 cwnd 的一半
if (kcp->ssthresh < IKCP_THRESH_MIN)
kcp->ssthresh = IKCP_THRESH_MIN;
kcp->cwnd = 1; // cwnd 置为 1, 进入慢启动
kcp->incr = kcp->mss;
}
if (kcp->cwnd < 1) {
kcp->cwnd = 1;
kcp->incr = kcp->mss;
}
}
5.4.2 计算 cwnd
ikcp_input 中收到 ACK 时会以某种方式增加 cwnd, 取决于当前是慢启动还是拥塞避免.
int ikcp_input(ikcpcb *kcp, const char *data, long size)
{
...
if (_itimediff(kcp->snd_una, prev_una) > 0) { // 收到了能让 snd_una 移动的 ACK
if (kcp->cwnd < kcp->rmt_wnd) { // cwnd 不超过 rmt_wnd
IUINT32 mss = kcp->mss;
if (kcp->cwnd < kcp->ssthresh) { // cwnd 小于 ssthresh, 慢启动
kcp->cwnd++; // cwnd 增加 1
kcp->incr += mss;
} else {
if (kcp->incr < mss) kcp->incr = mss;
kcp->incr += (mss * mss) / kcp->incr + (mss / 16); // 即 5.3 节中的 (1) 式
if ((kcp->cwnd + 1) * mss <= kcp->incr) { // 当 incr 累计增加的值超过一个 mss 时, cwnd 增加 1
kcp->cwnd++;
}
}
if (kcp->cwnd > kcp->rmt_wnd) { // 保持 cwnd 不超过 rmt_wnd
kcp->cwnd = kcp->rmt_wnd;
kcp->incr = kcp->rmt_wnd * mss;
}
}
}
return 0
6. 总结
笔者一直对 KCP 这个仅用一千多行实现的 ARQ 协议很感兴趣, 直到最近才花时间仔细阅读了 KCP 的源码, 再结合找到的一些资料, 弄清楚了它的原理. 目前互联网上详细讲解 KCP 的文章比较少, 对其中的一些重要实现细节也少有涉及. 笔者大学时的计算机网络课程也没有深入探讨 TCP 的一些细节. 所以趁此机会在这篇文章中较为全面深入地探讨了 KCP 协议的实现原理, 同时这也是 ARQ 协议的原理, 一方面加深自己的学习效果, 另一方面也希望对大家有所帮助.
参考资料:
- KCP 源码剖析
- TCP/IP 详解 卷1: 协议, 机械工程出版社
索引
索引
分布式事务/系统之底层原理揭秘
标题:分布式事务/系统之底层原理揭秘
作者:潘建锋
原文:HTTPS://strikefreedom.top/distributed-transaction-theorems-uncovering
导言
分布式事务是分布式系统必不可少的组成部分,基本上只要实现一个分布式系统就逃不开对分布式事务的支持。本文从分布式事务这个概念切入,尝试对分布式事务以及分布式系统最核心的底层原理逐一进行剖析,内容包括但不限于 BASE 原则、两阶段原子提交协议、三阶段原子提交协议、Paxos/Multi-Paxos 分布式共识算法的原理与证明、Raft 分布式共识算法和分布式事务的并发控制等内容。
事务
事务是访问并可能更新各种数据项的一个程序执行单元(unit)。事务由一个或多个步骤组成,一般使用形如begin transaction和end transaction语句或者函数调用作为事务界限,事务内的所有步骤必须作为一个单一的、不可分割的单元去执行,因此事务的结果只有两种:1. 全部步骤都执行完成,2. 任一步骤执行失败则整个事务回滚。
事务最早由数据库管理系统(database management system,DBMS)引入并实现,数据库事务是数据库管理系统执行过程中的一个逻辑单位,由一个有限的数据库操作序列构成。数据库事务严格遵循ACID原则,属于刚性事务,一开始数据库事务仅限于对单一数据库资源对象的访问控制,这一类事务称之为本地事务 (Local Transaction),后来随着分布式系统的出现,数据的存储也不可避免地走向了分布式,分布式事务(Distributed Transaction)便应运而生。
刚性事务
刚性事务(如单一数据库事务)完全遵循ACID规范,即数据库事务的四大基本特性:
-
Atomicity(原子性):一个事务(transaction)中的所有操作,或者全部完成,或者全部不完成,不会结束在中间某个环节。事务在执行过程中发生错误,会被回滚(Rollback)到事务开始前的状态,就像这个事务从来没有执行过一样。即,事务不可分割、不可约简。
-
Consistency(一致性):在事务开始之前和事务结束以后,数据库的完整性没有被破坏。这表示写入的资料必须完全符合所有的预设约束、触发器、级联回滚等。
-
Isolation(隔离性):数据库允许多个并发事务同时对其数据进行读写和修改的能力,隔离性可以防止多个事务并发执行时由于交叉执行而导致数据的不一致。事务隔离分为不同级别,包括未提交读(Read uncommitted)、提交读(read committed)、可重复读(repeatable read)和串行化(Serializable)。
-
Durability(持久性):事务处理结束后,对数据的修改就是永久的,即便系统故障也不会丢失。
刚性事务也能够以分布式 CAP 理论中的 CP 事务来作为定义。
柔性事务
在电商领域等互联网场景下,传统的事务在数据库性能和处理能力上都遇到了瓶颈。因此,柔性事务被提了出来,柔性事务基于分布式CAP理论以及延伸出来的BASE理论,相较于数据库事务这一类完全遵循ACID的刚性事务来说,柔性事务保证的是 “基本可用,最终一致”,CAP原理相信大家都很熟悉了,这里我们讲一下BASE原则:
-
基本可用(Basically Available):系统能够基本运行、一直提供服务。
-
软状态(Soft-state):系统不要求一直保持强一致状态。
-
最终一致性(Eventual consistency):系统需要在某一时刻后达到一致性要求。
柔性事务(如分布式事务)为了满足可用性、性能与降级服务的需要,降低一致性(Consistency)与隔离性(Isolation)的要求,遵循BASE理论,传统的ACID事务对隔离性的要求非常高,在事务执行过程中,必须将所有的资源对象锁定,因此对并发事务的执行极度不友好,柔性事务(比如分布式事务)的理念则是将锁资源对象操作从本地资源对象层面上移至业务逻辑层面,再通过放宽对强一致性要求,以换取系统吞吐量的提升。
此外,虽然柔性事务遵循的是BASE理论,但是还需要遵循部分ACID规范:
-
原子性:严格遵循。
-
一致性:事务完成后的一致性严格遵循;事务中的一致性可适当放宽。
-
隔离性:并行事务间不可影响;事务中间结果可见性允许安全放宽。
-
持久性:严格遵循。
本地事务
本地事务(Local Transaction)指的是仅仅对单一节点/数据库资源对象进行访问/更新的事务,在这种事务模式下,BASE理论派不上用场,事务完全遵循ACID规范,确保事务为刚性事务。
分布式事务
在分布式架构成为主流的当下,系统对资源对象的访问不能还局限于单节点,多服务器、多节点的资源对象访问成为刚需,因此,本地事务无法满足分布式架构的系统的要求,分布式事务应运而生。
访问/更新由多个服务器管理的资源对象的平面事务或者嵌套事务称之为分布式事务(Distributed Transaction),分布式事务是相对于本地事务来说的。
平面事务:单一事务,访问多个服务器节点的资源对象,一个平面事务完成一次请求之后才能发起下一个请求。
嵌套事务:多事务组成,顶层事务可以不断创建子事务,子事务又可以进一步地以任意深度嵌套子事务。
对于分布式事务来说,有两个最核心的问题:
- 如何管理分布式事务的提交/放弃决定?如果事务中的一个节点在执行自己的本地事务过程中遇到错误,希望放弃整个分布式事务,与此同时其他节点则在事务执行过程中一切顺利,希望提交这个分布式事务,此时我们应该如何做决策?
- 如何保证并发事务在涉及多个节点上资源对象访问的可串行性(规避分布式死锁)?如果事务 T 对某一个服务器节点上的资源对象 S 的并发访问在事务 U 之前,那么我们需要保证在所有服务器节点上对 S 和其他资源对象的冲突访问,T 始终在 U 之前。
问题 1 的解决需要引入一类分布式原子提交协议的算法如两阶段提交协议等,来对分布式事务过程中的提交或放弃决策进行管理,并确保分布式提交的原子性。而问题 2 则由分布式事务的并发控制机制来处理。
原子提交协议
原子性是分布式事务的前置性约束,没有原子性则分布式事务毫无意义。
原子性约束要求在分布式事务结束之时,它的所有操作要么全部执行,要么全部不执行。以分布式事务的原子性来分析,客户端请求访问/更新多个服务器节点上的资源对象,在客户端提交或放弃该事务从而结束事务之后,多个服务器节点的最终状态要么是该事务里的所有步骤都执行成功之后的状态,要么恢复到事务开始前的状态,不存在中间状态。满足这种约束的分布式事务协议则称之为原子提交协议。
当一个分布式事务结束时,事务的原子特性要求所有参与该事务的服务器节点必须全部提交或者全部放弃该事务,为了实现这一点,必须引入一个协调者(Coordinator)的角色,从参与事务的所有服务器节点中挑选一个作为协调者,由它来保证在所有服务器节点上最终获得同样的结果。协调者的工作原理取决于分布式事务选用的协议。
一般来说,分布式事务中包含的两个最基础的角色就是:
- Coordinator -- 协调者
- Participants -- 参与者
单阶段原子提交协议
单阶段原子提交协议(one-phase atomic commit protocol, 1APC)是最简单的一种原子提交协议,它通过设置一个协调者并让它不断地向所有参与者发送提交(commit)或放弃(abort)事务的请求,直到所有参与者确认已执行完相应的操作。
1APC 协议的优点是简单易用,对一些事务不复杂的场景比较合适,但在复杂事务场景则显得捉襟见肘,因为该协议不允许任何服务器节点单方面放弃事务,事务的放弃必须由协调者来发起,这个设计会导致很多问题:首先因为只有一次通信,协调者并不会收集所有参与者的本地事务执行的情况,所以协调者决定提交还是放弃事务只基于自己的判断,在参与者执行事务期间可能会遇到错误从而导致最终事务未能真正提交,错误一般与事务的并发控制有关,比如事务执行期间对资源对象加锁,遇到死锁,需要放弃事务从而解开死锁,而协调者并不知道,因此在发起下一个请求之前,客户端完全不知道事务已被放弃。另一种情况就是利用乐观并发控制机制访问资源对象,某一个服务器节点的验证失败将导致事务被放弃,而协调者完全不知情。
两阶段提交协议
定义
两阶段提交协议(two-phase commit protocol, 2PC)的设计初衷是为了解决 1APC 不允许任意一个服务器节点自行放弃它自己的那部分本地事务的痛点,2PC 允许任何一个参与者自行决定要不要放弃它的本地事务,而由于原子提交协议的约束,任意一个本地事务被放弃将导致整个分布式事务也必须放弃掉。
两阶段提交协议基于以下几个假设:
-
存在一个节点作为协调者(Coordinator),分布式事务通常由协调者发起(当然也可以由参与者发起),其余节点作为参与者(Participants),且节点之间可以自由地进行网络通信,协调者负责启动两阶段提交流程以及决定事务最终是被提交还是放弃。
-
每个节点会记录该节点上的本地操作日志(op logs),日志必须持久化在可靠的存储设备上(比如磁盘),以便在节点重启之后需要恢复操作日志。另外,不记录全局操作日志。
-
所有节点不能发生永久性损坏,也就是说节点就算是损坏了也必须能通过可靠性存储恢复如初,不允许出现数据永久丢失的情况。
-
参与者对协调者的回复必须要去除掉那些受损和重复的消息。
-
整个集群不会出现拜占庭故障(Byzantine Fault)-- 服务器要么崩溃,要么服从其发送的消息。
原理
两阶段提交协议,顾名思义整个过程需要分为两个阶段:
-
准备阶段(Prepare Phase)
-
提交阶段(Commit Phase)
在进行两阶段提交的过程中,协调者会在以下四种状态间流转:
-
init -
preparing -
committed -
aborted
而参与者则会在以下三种状态间流转:
-
working -
prepared -
committed
阶段 I(投票表决阶段)
-
任意一个参与者发起分布式事务 T 并执行本地事务成功,接着将一条
<ready T>记录追加到本地日志 buffer 中并 flush 到可靠性存储设备如磁盘上,从working状态进入prepared状态,然后向协调者发送prepare T消息; -
收到参与者发来的
prepare T消息后,协调者将一条<prepare T>记录追加到日志中,然后从init状态进入preparing状态,紧接着向分布式事务的其他参与者发出canCommit?消息,发起事务表决过程; -
当参与者收到
canCommit?请求后,除了发起事务的那一个之外,其他还在working状态的参与者会先尝试执行本地事务,如果本地事务执行成功,则会往本地日志 buffer 写入一条<ready T>记录并 flush 到可靠性存储中,但不提交事务,进入prepared状态,然后回复一条ready T消息对此事务投 YES 票;如果本地事务执行失败,则参与者会往本地日志 buffer 写入一条<don't commit T>记录并 flush 到可靠性存储中,然后回复一条don't commit T消息投 NO 票。
阶段 II(收集投票结果完成事务)
-
协调者收集所有的投票(包括它自己的投票);
(a) 如果所有的投票都是
ready T,则表示没有故障发生,那么协调者决定提交该事务,首先它会在其本地日志中追加一条<commit T>记录,从preparing状态进入committed状态,然后向所有的参与者发送doCommit请求消息,要求参与者提交它们的本地事务;(b) 如果有任一个投票是 No,则协调者决定放弃掉该事务,首先它会往本地日志中追加一条 记录,从
preparing状态进入aborted状态,然后发送doAbort请求消息给所有的参与者,通知它们回滚各自的本地事务。 -
投了 YES 票的参与者阻塞等待协调者给它发来
doCommit或doAbort消息,如果接收到的是doCommit消息则提交本地事务并在此过程中记录日志<commit T>,然后进入committed状态,最后回复一个haveCommitted的消息通知协调者本地事务已经成功提交;反之,如果收到的是doAbort消息则回滚本地事务并写入日志<abort T>,然后进入aborted状态。
上面的过程是一种更通用的流程,即由任意的参与者发起一个分布式事务,而在实践中一般把分布式事务的发起交给协调者来做,减少事务发起者确认该事务已被提交所需等待的网络消息延迟:
性能
网络 I/O 开销
假设两阶段提交过程一切运行正常,即协调者和参与者都不出现崩溃和重启,网络通信也都正常。那么假设有一个协调者和 N 个参与者,两阶段提交过程中将会发送如下的消息:
-
任意一个参与者从
working状态进入prepared状态并发送Prepared消息给协调者,1 条消息。 -
协调者收到消息后,向其他参与者发送
canCommit?请求消息,N - 1 条消息。 -
收到
canCommit?消息的参与者各自回复协调者投票消息,N - 1 条消息。 -
协调者统计投票情况之后,发送
doCommit消息给其他参与者,N 条消息。
所以,事务发起者在经过 4 条网络消息延迟之后确认该分布式事务已被提交,而整个过程共计发送 3N - 1 条网络消息(因为haveCommitted在 2PC 仅仅是用于最后通知协调者而已,属于可有可无的一次网络消息,2PC 在该消息缺省的情况下也能正常运行,因此haveCommitted一般不计入网络延迟成本中)。
前面我们提到,在实践中一般是由协调者来发起事务,如果考虑这种情况的话,事务发起者 -- 协调者在经过 3 条网络消息延迟之后确认该分布式事务已经被提交,而整个过程实际发送的网络消息则变成 3N 条。
总而言之,两阶段提交协议的网络通信开销和集群节点的数量成 3 倍正比。
本地存储设备 I/O 开销
基于前文中叙述的两阶段提交协议的基本假设之一:每个节点会通过日志来记录在本地执行的操作,以便在节点发生故障并重启节点之后能利用日志恢复到故障前的状态,因此两阶段提交过程中除了网络 I/O 的开销之外,还有本地存储设备 I/O 的开销:
-
发起事务的参与者执行本地事务,1 次写操作。
-
其余参与者执行各自的本地事务,N - 1 次写操作。
-
协调者统计投票结果并决定提交事务,1 次写操作。
所以事务发起者在经过 3 次本地存储设备 I/O 延迟之后确认该事务已被提交,整个过程总计有 N + 1 次本地存储设备 I/O,而如果由协调者来发起事务的话,则还是需要 N + 1 次本地存储设备 I/O,但是只需要经过 2 次本地存储设备 I/O 延迟即可确认事务已被提交。
恢复
在分布式事务中,所有的参与者节点都可能发生故障,所以我们需要保证在该故障节点恢复时发生的一切都和分布式事务 T 的全局决策保持一致。节点在恢复的时候会读取 T 的最后一个本地日志记录并作出相应的操作:
-
如果 T 的最后一条日志记录是
<commit T>,那么说明协调者在节点发生故障时的全局决策是提交 T,根据本地事务所使用的日志方式,在该节点上可能需要执行redo T。 -
如果 T 的最后一条日志记录是
<abort T>,那么说明协调者在节点发生故障时的全局决策是中止 T,根据本地事务所使用的日志方式,在该节点上可能需要执行 undo T。 -
如果 T 的最后一条日志记录是
<don't commit T>,则和第 2 中情况类似,执行undo T。 -
如果 T 的最后一条日志记录是
<ready T>,这种情况比较麻烦,因为恢复节点无法确认在它故障之后协调者发出的最终全局决策是什么,因此它必须要和集群中其余至少一个节点取得联系,询问 T 的最终结果是什么:恢复节点先尝试询问协调者,如果此时协调者正在工作,则告知恢复节点 T 的最终结果,如果是提交就执行redo T,中止就执行undo T;如果协调者因故不在工作,则恢复节点可以要求其他某一个参与者节点去查看本地日志以找出 T 的最终结果并告知恢复节点。在最坏的情况下,恢复节点无法和集群中其他所有节点取得联系,这时恢复节点只能阻塞等待,直至得知 T 的最终结果是提交还是中止。 -
如果本地日志中没有记录任何关于 T 在两阶段提交过程中的操作,那么根据前面的两阶段提交流程可知恢复节点还没来得及回复协调者的
canCommit?请求消息就发生了故障,因此根据两阶段算法,恢复节点只能执行undo T。
缺陷
-
同步阻塞:两阶段提交协议是一个阻塞的协议,在第二阶段期间,参与者在事务未提交之前会一直锁定其占有的本地资源对象,直到接收到来自协调者的
doCommit或doAbort消息。 -
单点故障:两阶段提交协议中只有一个协调者,而由于在第二阶段中参与者在收到协调者的进一步指示之前会一直锁住本地资源对象,如果唯一的协调者此时出现故障而崩溃掉之后,那么所有参与者都将无限期地阻塞下去,也就是一直锁住本地资源对象而导致其他进程无法使用。
-
数据不一致:如果在两阶段提交协议的第二阶段中,协调者向所有参与者发送
doCommit消息之后,发生了局部网络抖动或者异常,抑或是协调者在只发送了部分消息之后就崩溃了,那么就只会有部分参与者接收到了doCommit消息并提交了本地事务;其他未收到doCommit消息的参与者则不会提交本地事务,因而导致了数据不一致问题。
XA 标准接口
2PC 两阶段提交协议本身只是一个通用协议,不提供具体的工程实现的规范和标准,在工程实践中为了统一标准,减少行业内不必要的对接成本,需要制定标准化的处理模型及接口标准,国际开放标准组织 Open Group 定义了分布式事务处理模型DTP(Distributed Transaction Processing)Model,现在 XA 已经成为 2PC 分布式事务提交的事实标准,很多主流数据库如 Oracle、MySQL 等都已经实现 XA。
两阶段事务提交采用的是 X/OPEN 组织所定义的 DTP Model 所抽象的 AP(应用程序), TM(事务管理器)和 RM(资源管理器) 概念来保证分布式事务的强一致性。 其中 TM 与 RM 间采用 XA 的协议进行双向通信。 与传统的本地事务相比,XA 事务增加了准备阶段,数据库除了被动接受提交指令外,还可以反向通知调用方事务是否可以被提交。TM可以收集所有分支事务的准备结果,并于最后进行原子提交,以保证事务的强一致性。
Java 通过定义 JTA 接口实现了 XA 模型,JTA 接口中的ResourceManager需要数据库厂商提供 XA 驱动实现,TransactionManager则需要事务管理器的厂商实现,传统的事务管理器需要同应用服务器绑定,因此使用的成本很高。 而嵌入式的事务管器可以以 jar 包的形式提供服务,同 Apache ShardingSphere 集成后,可保证分片后跨库事务强一致性。
通常,只有使用了事务管理器厂商所提供的 XA 事务连接池,才能支持 XA 的事务。Apache ShardingSphere 在整合 XA 事务时,采用分离 XA 事务管理和连接池管理的方式,做到对应用程序的零侵入。
三阶段提交协议
由于前文提到的两阶段提交协议的种种弊端,研究者们后来又提出了一种新的分布式原子提交协议:三阶段提交协议(three-phase commit protocol, 3PC)。
三阶段提交协议是对两阶段提交协议的扩展,它在特定假设下避免了同步阻塞的问题。该协议基于以下两个假设:
-
集群不发生网络分区;
-
故障节点数不超过 K 个(K 是预先设定的一个数值)。
基于这两个假设,三阶段提交协议通过引入超时机制和一个额外的阶段来解决阻塞问题,三阶段提交协议把两阶段提交协议的第一个阶段拆分成了两步:1) 评估,2) 资源对象加锁,最后才真正提交:
-
CanCommit 阶段:协调者发送
CanCommit请求消息,询问各个参与者节点,参与者节点各自评估本地事务是否可以执行并回复消息(可以执行则回复 YES,否则回复 NO),此阶段不执行事务,只做判断; -
PreCommit 阶段:协调者根据上一阶段收集的反馈决定通知各个参与者节点执行(但不提交)或中止本地事务;有两种可能:1) 所有回复都是 YES,则发送
PreCommit请求消息,要求所有参与者执行事务并追加记录到 undo 和 redo 日志,如果事务执行成功则参与者回复 ACK 响应消息,并等待下一阶段的指令;2) 反馈消息中只要有一个 NO,或者等待超时之后协调者都没有收到参与者的回复,那么协调者会中止事务,发送Abort请求消息给所有参与者,参与者收到该请求后中止本地事务,或者参与者超时等待仍未收到协调者的消息,同样也中止当前本地事务。 -
DoCommit 阶段:协调者根据上一阶段收集到的反馈决定通知各个参与者节点提交或回滚本地事务,分三种情况:1) 协调者收到全部参与者回复的 ACK,则向所有参与者节点广播
DoCommit请求消息,各个参与者节点收到协调者的消息之后决定提交事务,然后释放资源对象上的锁,成功之后向协调者回复 ACK,协调者接收到所有参与者的 ACK 之后,将该分布式事务标记为committed;2) 协调者没有收到全部参与者回复的 ACK(可能参与者回复的不是 ACK,也可能是消息丢失导致超时),那么协调者就会中止事务,首先向所有参与者节点广播Abort请求消息,各个参与者收到该消息后利用上一阶段的undo日志进行事务的回滚,释放占用的资源对象,然后回复协调者 ACK 消息,协调者收到参与者的 ACK 消息后将该分布式事务标记为aborted;3) 参与者一直没有收到协调者的消息,等待超时之后会直接提交事务。
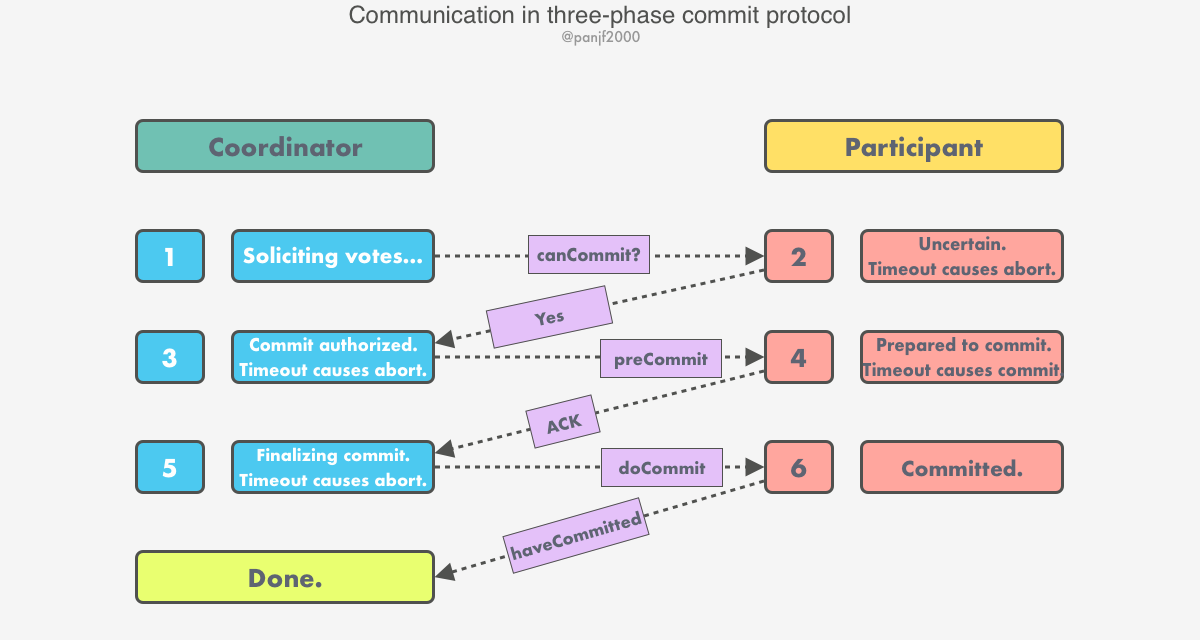
事实上,在最后阶段,协调者不是通过追加本地日志的方式记录提交决定的,而是首先保证让至少 K 个参与者节点知道它决定提交该分布式事务。如果协调者发生故障了,那么剩下的参与者节点会重新选举一个新的协调者,这个新的协调者就可以在集群中不超过 K 个参与者节点故障的情况下学习到旧协调者之前是否已经决定要提交分布式事务,若是,则重新开始协议的第三阶段,否则就中止该事务,重新发起分布式事务。
在最后的DoCommit阶段,如果参与者一直没有收到协调者的DoCommit或者Abort请求消息时,会在等待超时之后,直接提交事务。这个决策机制是基于概率学的:当已经进入第三阶段之后,说明参与者在第二阶段已经收到了PreCommit请求消息,而协调者发出PreCommit请求的前提条件是它在第二阶段开头收集到的第一阶段向所有参与者发出的CanCommit请求消息的反馈消息都是 YES。所以参与者可以根据自己收到了PreCommit请求消息这一既定事实得出这样的一个结论:其他所有参与者都同意了进行这次的事务执行,因此当前的参与者节点有理由相信,进入第三阶段后,其他参与者节点的本地事务最后成功提交的概率很大,而自己迟迟没有收到DoCommit或Abort消息可能仅仅是因为网络抖动或异常,因此直接提交自己的本地事务是一个比较合理的选择。
三阶段提交协议主要着重于解决两阶段提交协议中因为协调者单点故障而引发的同步阻塞问题,虽然相较于两阶段提交协议有所优化,但还是没解决可能发生的数据不一致问题,比如由于网络异常导致部分参与者节点没有收到协调者的Abort请求消息,超时之后这部分参与者会直接提交事务,从而导致集群中的数据不一致,另外三阶段提交协议也无法解决脑裂问题,同时也因为这个协议的网络开销问题,导致它并没有被广泛地使用,有关该协议的具体细节可以参阅本文最后的延伸阅读一节中的文献进一步了解,这里不再深入。
并发控制
在分布式事务中,集群中的每个服务器节点要管理很多资源对象,每个节点必须保证在并发事务访问这些资源对象时,它们能够始终保持一致性。因此,每个服务器节点需要对自己的管理的资源对象应用一定的并发控制机制。分布式事务中需要所有服务器节点共同保证事务以串行等价的的方式执行。
也就是说,如果事务 T 对某一个服务器节点上的资源对象 S 的并发访问在事务 U 之前,那么我们需要保证在所有服务器节点上对 S 和其他资源对象的冲突访问,T 始终在 U 之前。
锁并发控制
在分布式事务中,某个对象的锁总是本地持有的(在同一个服务器节点上)。是否加锁是由本地锁管理器(Local Lock Manager,LLM)决定的。LLM 决定是满足客户端持锁的请求,还是阻塞客户端发起的分布式事务。但是,事务在所有服务器节点上被提交或者放弃之前,LLM 不能释放任何锁。在使用加锁机制的并发控制中,原子提交协议在进行的过程中资源对象始终被锁住,并且是排他锁,其他事务无法染指这些资源对象。但如果事务在两阶段提交协议的阶段一就被放弃,则互斥锁可以提前释放。
由于不同服务器节点上的 LLM 独立设置资源对象锁,因此,对于不同的事务,它们加锁的顺序也可能出现不一致。考虑一个场景:事务 T 和 U在服务器 X 和 Y 之间的交错执行:
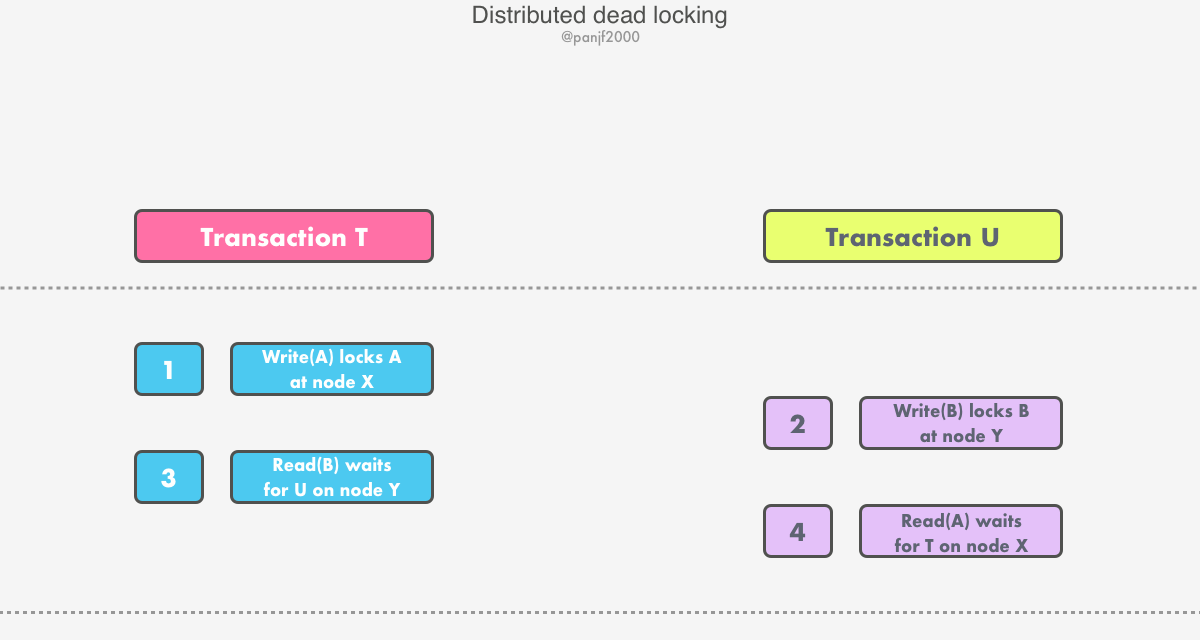
-
事务 T 锁住了服务器节点 X 上的资源对象 A,做写入操作;
-
事务 U 锁住了服务器节点 Y 上的资源对象 B,做写入操作;
-
事务 T 试图读取服务器节点 Y 上的资源对象 B,此时 B 被事务 U 锁住,因此 T 等待锁释放;
-
事务 U 试图读取服务器节点 X 上的资源对象 A,此时 A 被事务 T 锁住,因此 U 等待锁释放。
在服务器节点 X 上,事务 T 在事务 U 之前;而在服务器节点 Y 上,事务 U 在事务 T 之前。这种不一致的事务次序导致了事务之间的循环依赖,从而引起分布式死锁。分布式死锁需要通过特定的方法/算法来检测并解除,一旦检测到死锁,则必须放弃其中的某个事务来解除死锁,然后通知事务协调者,它将会放弃该事务所涉及的所有参与者上的事务。
时间戳并发控制
对于单一服务器节点的事务来说,协调者在每个事务启动时会为其分配一个全局唯一的时间戳。通过按照访问资源对象的事务时间戳顺序提交资源对象的版本来强制保证以事务执行的串行等价性。在分布式事务中,协调者必须保证每个事务都会附带全局唯一的时间戳。全局唯一的时间戳由事务访问的第一个协调者发给客户端。如果任意一个服务器节点上的资源对象执行了事务中的一个操作,那么事务时间戳会被发送给该服务器节点上的协调者。
分布式事务中的所有服务器节点共同保证事务以串行等价的方式执行。例如,如果在某服务器节点上,由事务 U 访问的资源对象版本在事务 T 访问之后提交;而在另一个服务器节点上,事务 T 和事务 U 又访问了同一个资源对象,那么它们也必须按照相同的次序提交资源对象。为了保证所有服务器节点上的事务执行的相同顺序,协调者必须就时间戳排序达成一致。时间戳是一个二元组 < 本地时间戳,服务器 ID > 对。在时间戳的比较排序过程中,首先比较本地时间戳,然后再比较服务器 ID。
一个可靠的时间戳并发控制应该保证即使各个服务器节点之间的本地时间不同步,也能保证事务之间的相同顺序。但是考虑到效率,各个协调者之间的时间戳还是最好还是要求大致同步。这样的话,事务之间的顺序通常与它们实际开始的时间顺序相一致。可以利用一些本地物理时钟同步方法来保证时间戳的大致同步。
如果决定利用时间戳机制进行分布式事务的并发控制,那么还需要通过某些方法来解决事务冲突问题。如果为了解决冲突需要放弃某个事务时,相应的协调者会收到通知,并且它将在所有的参与者上放弃该事务。这样,如果事务能够坚持到客户端发起提交请求命令的那个时候,那么这个事务就总能被提交。因此在两阶段提交协议中,正常情况下参与者都会同意提交,唯一一种不同意提交的情况是参与者在事务执行过程中曾经崩溃过。
乐观并发控制
加锁机制这一类悲观并发控制有许多明显的缺陷:
-
锁的维护带来了很多新的开销。这些开销在不支持对共享数据并发访问的系统中是不存在的。即使是只读事务(如查询),就算这一类事务不会改变数据的完整性,却仍然需要利用锁来保证数据在读取过程中不会被其他事务修改,然而锁却只在最极端的情况下才会发挥作用。
-
锁机制非常容易引发死锁。预防死锁会严重降低并发度,因此必须利用超时或者死锁检测来解除死锁,但这些死锁解除方案对于交互式的程序来说并不是很理想。
-
锁周期过长。为了避免事务的连锁(雪崩)放弃,锁必须保留到事务结束之时才能释放,这再一次严重降低了系统的并发度。
由于锁这一类的悲观并发控制有上述的种种弊端,因此研究者们提出了另一种乐观并发控制的机制,以求规避锁机制的天然缺陷,研究者们发现这样的一个现象:在大多数应用中两个客户端事务访问同一个资源对象的可能性其实很低,事务总是能够成功执行,就好像事务之间不存在冲突一样。
所以事务的乐观并发控制的基本思路就是:各个并发事务只有在执行完成之后并且发出closeTransaction请求时,再去检测是否有冲突,如果确实存在冲突,那么就放弃一些事务,然后让客户端重新启动这些事务进行重试。
在乐观并发控制中,每个事务在提交之前都必须进行验证。事务在验证开始时首先要附加一个事务号,事务的串行化就是根据这些事务号的顺序实现的。分布式事务的验证由一组独立的服务器节点共同完成,每个服务器节点验证访问自己资源对象的事务。这些验证在两阶段提交协议的第一个阶段进行。
关于分布式事务的并发控制就暂时介绍到这里,如果想要继续深入学习更多并发控制的细节,可以深入阅读《分布式系统:概念与设计》、《数据库系统实现》和《数据库系统概念》等书籍或者其他资料
总结
本文通过讲解BASE 原则、两阶段原子提交协议、三阶段原子提交协议、Paxos/Multi-Paxos 分布式共识算法的原理与证明、Raft 分布式共识算法和分布式事务的并发控制等内容,为读者全面而又深入地讲解分析了分布式事务以及分布式系统的底层核心原理,特别是通过对原子提交协议中的 2PC/3PC 的阐述和分析,以及对分布式共识算法 Paxos 的原理剖析和正确性的证明,最后还有对分布式事务中几种并发控制的介绍,相信能够让读者对分布式事务和分布式系统底层的一致性和并发控制原理有一个深刻的认知,对以后学习和理解分布式系统大有裨益。
本文不仅仅是简单地介绍分布式事务和分布式系统的底层原理,更是在介绍原理的同时,通过层层递进的方式引导读者去真正地理解分布式系统的底层原理和设计思路,而非让读者死记硬背一些概念,所以希望通过这篇抛砖引玉的文章,能够对本文读者在以后学习、操作甚至是设计分布式系统以及分布式事务时的思路有所开拓。