解释 Rust 中的原子性
当处理原子性以及内存排序选项时理解它们可以帮助我们更好的理解多线程编程以及为什么 Rust 可以帮助我们编写安全高性能的多线程代码。
尝试通过阅读随机的文章或者 Rust (或 C++) 中的文档来理解原子性,就像是通过逆向工程E = MC^2来学物理一样。
我将会在本文中尽最大的努力来向你我解释这个概念。如果我成功了,比例将会是WTF?/AHA! < 1。
多处理器编程
当我们为多个 CPU 编写代码时,有一些细微的 (subtle) 的事情需要考虑。你将看到,如果编译器或 CPU 认为重排我们编写的代码可以获得更快的执行速度,它们就会这么做。在单线程的程序中,我们不需要考虑什么,但是一旦我们开始编写多线程程序时,编译器重排可能就会给我们带来问题。
然而,虽然编译器的顺序可以通过查看反汇编的代码进行检查,当系统运行在多个 CPU 之上时,事情可能会变得更加复杂。
当线程在不同的 CPU 上运行时,CPU 内部的指令重排可以导致一些难以调试的问题,因为我们大多数时候观察的只是 CPU 重排,执行推断 (speculative),流水线 (pipeline) 以及缓存的副作用。
我也不认为 CPU 可以提前知道它将如何运行你的代码。
原子性解决的问题与内存的加载与存储有关。任何不会操作内存的指令重排都不会对我们关心的内容产生影响。
除非另有说明,否则我在这里将使用一个主要参考:Intel® 64 and IA-32 Architectures Software Developer’s Manual Volume 3A。因此当我说参考了 Intel 开发人员参考手册的某一章节,便指的是这篇文章。
让我们从最底层开始,用适合我们的方式来获取更好的理解。
强 vs 弱内存排序
首先,我们需要正确的理解一些概念。在处理内存方面,CPU 提供了不同的保证。我们可以将其区分为从弱 (Weak) 到强 (Strong)。但是,这不是一个精确的规范,因此有些模型介于两者之间。
为了抽象这些差异,Rust 有一个抽象机的概念。它从 C++ 中借用了这个模型。这个抽象机需要一个抽象,它可以针对弱 CPU 和强 CPU (以及介于两者之间的状态)编程。
你可以看到,C++ 抽象机指定了很多访问内存的方式。如果我们在相同语言中针对强弱处理器应该使用相同的语义,则必须使用这些访问内存的方式。
具有强内存模型的 CPU 提供了一些重要的保证,让我们在抽象机中使用的语义不会做任何操作。这一点也不花哨,这仅是对编译器的提示,让其不要对程序员编写的内存操作顺序做任何改变。
然而在使用弱内存模型的系统中,可能需要设置内存栏栅或使用特殊的指令来防止同步问题。根据经验学习这种抽象机的最好方式是使用具有弱有序的 CPU。然而,因为大多数程序员都是在具有强内存模型的 CPU 上编程,因此我们将只需要指出差异就可以理解为什么该语义是它们表现的那样。
目前大多数使用 AMD 或 Intel 处理器的电脑都使用强有序。这就意味着 CPU 会保证不会重排确定的操作顺序。可以在 Intel 开发人员手册第 8.2.2 节找到这个保证的相关示例。
- 读操作不会和其他读操作重新排序。
- 写操作不会和旧的读操作重新排序。
- 写内存操作不会和其他(带有异常的)写操作重新排序。
重要的是,它还包含一个不受保证的示例:
- 读操作可能会与旧的写到不同地址的操作重新排序,但是不会与写到相同地址的操作重新排序。
最后一个示例对于理解后面的SeqCst内存排序至关重要,现在这里只是为它做个说明。
现在,在之后的章节,我将会试图理清它们的差异。但是我仍将使用抽象机的弱模型作为解释的基础...
⚠️ 我将指出使用这个提示的强有序 CPU 的差异。
CPU 缓存
通常,一个 CPU 有三种级别的缓存:L1,L2,L3。其中 L2 和 L3在各个核心之间共享,L1 是每个核心的缓存。我们的挑战就在这里开始。
L1 缓存使用了某种 MESI 缓存协议。名字听起来可能很神秘,但是该协议其实很简单。它是缓存中以下不同状态的首字母缩写 (acronym):
这些状态适用于 L1 缓存中的每一个缓存行:
(M) Modified - 修改(脏数据)。需要将数据写回主内存。
(E) Exclusive - 只存在 L1 缓存中。不需要被同步(清理)。
(S) Shared - 可能存在其他的缓存中。目前与主内存一起使用。
(I) Invalid - 缓存行是无效的。其他缓存可能会将其修改。
在 Intel 开发者手册的第 11.4 节中,有更多关于缓存状态的描述。
我们可以通过对 CPU 中的每一个缓存行分配一个带有四种状态的枚举,对 L1 缓存进行建模。
这听起来是不是很熟悉?
在 Rust 中我们有两种类型的引用 & 共享引用 (shared references) 和 &mut 独占引用(exclusive references)。
如果你不再将它们视为
mutable和immutable,这将对你有很大的帮助。因为并非一直如此。允许内部可变性 (interior mutability) 的原子和类型确实打破了这种心智模型。相反,我们应当将它们视为exclusive和shared。这确实可以很好的映射到 E 和 S (L1 缓存中可能存在的两种状态数据)。在语言中对其进行建模可以很好的提供一些优化,而其他不存在这些语义的语言却无法做到。
在 Rust 中,只有内存是
Exclusive且默认可以被修改。这意味着,只要我们不会打破规则以及可变的
Shared引用,所有的 Rust 程序可以假设运行在核心上的 L1 缓存是最新的,不需要做任何同步。当然,许多程序需要在核心之间
Shared内存才能工作,但是明确并谨慎这么做可以更好的让代码在多处理器上运行。
处理器之间的通信
如果我们确实想要访问并改变Shared内存,其他的核心是如何知道它们的 L1 缓存是非法的呢?
如果数据存在不同核心的 L1 缓存中(请记住,它处于Shared状态)并被修改时,缓存行是无效的。为了通知其他核心它们的缓存数据是无效的,就必须有一些可以在核心之间通信的方式,对吗?
是的,确实如此,但是,很难找到有关确切详细信息的文档。每个核心都有一个我们可以当作邮箱的东西。
该邮箱可以缓存一定数量的消息。每条缓存的消息总是可以避免中断 CPU 并且强制它立即处理发往其他核心的每条消息。
现在,CPU 会在某个时刻检查该邮箱并相应的更新其缓存。
让我们举一个关于标记为Shared缓存行的一个示例。
如果 CPU 修改了这个缓存行,它在其他缓存中就会无效。修改数据的核心会向其余的 CPU 发送一条消息。当其他核心检查它们的邮箱时,它们将会发现当前这个缓存行是无效的,然后它的状态会在其他核心中的每个缓冲中相应的更新。
在每个核心上的 L1 缓存接着在主内存(或 L2/L3 缓存)中拉取正确的值,并将它的装态重新设置为Shared。
⚠️ 在强有序的 CPU 中,这个模型以几种不同的方式进行工作。如果一个核心修改了一个
Shared缓存行,它将会在这个值实际被修改之前,强制其他核心将相应的缓存行设置为无效。这样的 CPU 有一个 缓存连贯性 (coherency) 机制,它可以改变其他核心中缓存的状态。
内存排序
既然我们对如何设计 CPU 之间的协调有了一些了解,我们可以介绍一些不同的内存排序以及它们的含义。
在 Rust 中,std::sync::atomic::Ordering 代表内存排序,它有 5 个可能的值。
心智模型
实际上,由于 Rust 的类型系统,很难对其构建一个心智模型(如:我们无法获取一个Atomic的指针),但是我发现想象一个观察者核心(即一个核心作为观察者)很有用。处于某种原因,这个观察者核心对我们执行原子操作的同一块内存很感兴趣,所以我们将每个模型一分为二:它在运行的核心上看起来怎样以及在观察者核心上看起来怎样。
请记住,Rust 从 C++20 中继承了原子的内存模型,C 同样也是从 C++ 中拷贝的。在这些语言中,类型系统不会像在 Safe Rust 中一样约束你,因此使用指针访问
Atomic更容易。
Relaxed
在当前 CPU 中:
原子性中的 Relaxed 内存排序将会阻止编译器进行指令重排,但是,在弱排序的 CPU 中,它可能会重排所有其他的内存访问顺序。如果你只是将计数器加 1,那当然没有问题,但是如果你使用了一个 flag 实现了自旋锁 (spin-lock),它可能会给你带来一些问题,因为你不相信 flag 前后的“正常”内存访问已被设置,没有重新排序。
在观察者 CPU 中:
编译器和 CPU 都可以自由地对其他任何内存访问进行过重排,除了彼此切换两个Relaxed的加载/存储。观察者核心可能观察到操作的顺序与我们代码中编写的顺序不一样。如果我们按此顺序编写它们,它们将始终可以在Relaxed操作 B 之前看到Relaxed操作 A。
因此,Relaxed是可能的内存排序中最弱的。这表明该操作不会与其他 CPU 进行任何的同步。
在强有序的 CPU 中,所有的内存操作默认都具有 Acquire/Release 语义。因此,这仅是向编译器提示“这些操作不能在它们之间重新排序”。在强有序的系统中使用这些操作的原因是:它们允许编译器在合适的情况下对所有其他内存访问操作进行重排。
如果你想知道为什么似乎可以使用
Relaxed并获得与Acquire/Release相同的结果,这就是原因。然而,重要的是尝试理解“抽象机”模型,而不仅仅是依靠在强有序 CPU 中运行实验中所获得的经验。你的代码可能在不同的 CPU 中被中断。查看这篇文章,它们在强有序和弱有序的 CPU 中运行相同的代码,以了解它们之间的区别。
Acquire
在当前 CPU 中:
在Acquire访问操作之后写入的任何内存操作都将保留在该操作之后。这意味着它与Release内存排序标志配对,形成了一种“内存三明治”。所有在加载 (load) 和存储 (store) 之间的内存访问操作都将与其他 CPU 进行同步。
在弱有序的系统中,这可能导致在Acquire操作之前使用专门的 CPU 指令,它会强制当前的核心处理其邮箱中所有的消息(许多 CPU 都具有序列化及内存排序指令)。很有可能还会实现内存栏栅,以防止 CPU 在Acquire加载之前对内存访问操作的顺序进行重排。
内存栏栅 (memory fences)
由于我们是第一次遇到这个术语,就不要假装所有人都了解它然后将它放过。内存栏栅是个硬件概念。它通过强制 CPU 在隔离之前完成对内存的
loads/stores以防止对 CPU 指令进行重排,因此请确保在对栏栅重新排序之前没有进行任何此类操作,而后才可以对其进行此类操作。为了能够区分只读,只写以及读写指令,它们被命名为不同的名称。可以防止读写指令重排的栏栅被称为 full fence。
让我们快速浏览 Intel 开发者手册中的一个 full fence。(比较简短,我还做了总结)
程序的同步也可以通过序列化指令进行(参阅 8.3 节)。这些指令通常用于关键过程或任务边界,以强制完成之前的所有指令,然后跳转到新的代码块或进行上下文切换。和 I/O 指令及锁指令一样,处理器在执行序列化指令之前,一直等到之前的所有指令都已完成,并且所有缓存的写操作都已在内存中执行。SFENCE,LFENCE 以及 MFENCE 指令提供了一种性能高效的方式,可确保在在产生弱有序结果及消耗该数据的惯例之间加载和存储内存排序操作。
MFENCE - 在程序指令流中,序列化在 MFENCE 指令之前发生的所有存储和加载操作。
你可以参阅 Intel 开发者手册的第 8.2 节及 8.3 节文档,发现 MFENCE 是这样的一个指令。在强有序处理器上不会经常看到这些指令,因为很少需要它们,但在弱有序系统中,它们对于实现抽象机中使用的
Acquire/Release模型至关重要。
在观察者 CPU 中:
因为Acquire是一个load操作,它不会修改内存,所以不需要对其进行观察。
但是,这里有个注意事项 (caveat),如果观察者核心本身做了Acquire加载操作,它将会看到Acquire加载到Release存储(包括存储)之间发生的所有内存操作。这意味着需要执行一些全局的同步。让我们在之后介绍到Release时再进行讨论。
Acquire通常用于写锁,在成功获取锁之后,某些操作需要保留。出于这个确切的原因,Acquire仅在加载 (load) 操作时有意义。如果你将Acquire作为存储 (store) 操作的内存排序进行传递,Rust 中涉及存储的大多数原子方法都会发生恐慌 (panic)。
⚠️ 在强有序的 CPU 中,这将是一个 no-op,因此不会在性能方面产生任何成本。但是,这将阻止编译器对在
Acquire操作之后发生的所有写入的内存操作进行重新排序,以使它们在Acquire操作之前发生。
Release
在当前 CPU 中:
与Acquire相反,任何在Release内存排序标志之前编写的内存操作都将停留在该标志之前。这意味着它与Acquire内存排序标志配对。
在弱有序 CPU 中,编译器可能会插入一个内存栏栅来确保 CPU 不会对Release操作之前的内存操作进行重排,让这些操作在Release之后发生。这也做了一个保证,其他所有执行Acquire的核心一定可以看到在Acquire之后,Release之前的所有内存操作。
因此,不仅需要在本地正确地对操作进行排序,还保证了此时更改对于观察者核心必须是可见的。
这意味着一些全局同步一定会在每一个Acquire访问之前,或Release存储之后发生。这基本上给了我们两个选择:
Acquire加载 (load) 必须确保它处理了所有的消息,并且如果有任何其他的核心将我们载入的内存设置为无效,它可以拉取到正确的值。Release存储 (store) 必须是原子性的并且在它修改某个值之前,将其他所有持有该值的缓存置为无效。
不过,仅执行其中一项就足够了。这部分使其比SeqCst弱,但是性能更高。
在观察者 CPU 中:
观察者 CPU 可能看不到任何特定顺序的这些更改,除非它本身使用内存的Acquire加载 (load)。如果确实是这样,它会看到在Acquire和Release之间修改过的所有内存,包括Release存储 (store) 本身。
Release经常与Acquire一起使用以写锁。对于一个函数锁,在成功获取到锁之后 (在锁释放之前),一些操作需要被保留。出于这个原因,与Acquire排序相反,如果你传递Release排序操作,Rust 中的大多数加载 (load) 方法都会发生恐慌 (panic)。
⚠️ 在强有序的 CPU 中,在修改值之前,共享(
Shared)值的所有实例在该值存在的所有 L1 缓存中均无效。这意味着Acquire加载 (load) 对所有相关的内存都已经有了一个更新后的视图,Release存储 (store) 将立即将其他包含数据的核心上的任何缓存行置为无效。这就是为什么这些语义在这样的系统上没有性能成本的原因。
AcqRel
该语义旨在用于同时加载 (load) 并存储 (store) 一个值时的操作。AtomicBool::compare_and_swap就是一个这样的操作。因为这个操作既加载 (load) 又存储 (store) 某个值,与Relaxed操作相比,这在弱有序系统上可能很重要。
我们可以或多或少的将这个操作看作是栏栅。在它之前写入的内存操作不会跨越此边界重新排序,而在它之后写入的内存操作不会在此边界之前重新排序。
⚠️ 阅读
Acquire和Release段落,此处同样适用。
SeqCst
⚠️ 在本文的这个部分,我将使用强有序的 CPU 作为基础进行讨论。你在这里将看不到“强有序”的片段。
SeqCst代表顺序一致性 (Sequential Consistency),它不仅给了和Acquire/Release一样的保证,还承诺建立一个单一的全量修改顺序。
SeqCst已经因为用作推荐的排序方式而受到批评,并且很难证明有充足的理由使用它,因此我对使用它有很多反对意见。也有人批评它有点功能破损。
此图应该可以说明SeqCst在哪些方面可能无法维持其保证:
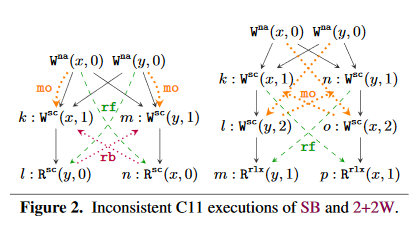
如何将其修复请参阅Repairing Sequential Consistency in C/C++11 。
明白了吗?从现在开始,我们将关注于SeqCst的实践方面,而不是其理论基础。
只知道围绕它进行了一些讨论,并且Acquire/Release很可能解决你的大部分难题,至少在强有序的 CPU 上。
让我们考虑将SeqCst与Acquire/Release操作进行对比。
我将使用这个 Gotbolt 示例进行解释:
代码如下所示:
#![allow(unused)] fn main() { use std::sync::atomic::{AtomicBool, Ordering}; static X: AtomicBool = AtomicBool::new(true); static Y: AtomicBool = AtomicBool::new(true); pub fn example(val: bool) -> bool { let x = X.load(Ordering::Acquire); X.store(val | x, Ordering::Release); let y = Y.load(Ordering::Acquire); x || y } }
使用Acquire/Release输出的汇编程序如下所示:
movb example::X.0.0(%rip), %al # load(Acquire)
testb %al, %al
setne %al
orb %dil, %al
movb %al, example::X.0.0(%rip) # store(Release)
movb 1, %al # load(Acquire)
retq
在弱有序的 CPU 中,指令可能不同,但是结果必须是一致的。
使用Release内存排序的存储 (store) 操作是movb %al, example::X.0.0(%rip)。我们知道在强有序的系统中,如果其他缓存中包含这个数据,可以确保能够立即在其他缓存中将其设置为Invalid。
所以问题是什么?
为了将其指明,我们浏览一下在 C++ 规范中关于 Release-Acquire 的相关部分:
仅在 Release 和 Acquire 相同原子变量的线程之间建立同步。其他线程可以看到不同于同步线程中看到的内存访问顺序。
Rust 的Release文档再次重申 (re-iterates) 并指出:
特别是,所有之前的写入操作对执行此值的 Acquire (或更强)加载 (load) 的所有线程都是可见的。
现在是时候仔细看看我在开始时提到的 non-guarantee。Intel 开发者手册 在第 8.2.3.4 节进行了更详细的说明:
8.2.3.4:Loads 可能会与早期的 Stores 一起重排到不同的位置
Intel 64 位内存排序模型允许将加载 (load) 与早期的存储 (store) 重排到不同的位置。然而,加载 (load) 不会与存储 (store) 重排到相同的位置。
所以,如果我们将这个信息放在一起,我们可以有以下情形:
#![allow(unused)] fn main() { let x = X.load(Ordering::Acquire); X.store(val | x, Ordering::Release); # earlier store to different location let y = Y.load(Ordering::Acquire); # load // *Could* get reordered on the CPU to this: let x = X.load(Ordering::Acquire); let y = Y.load(Ordering::Acquire); X.store(val | x, Ordering::Release); }
现在,我已经尽我最大的努力在 Intel CPU 上引发导致问题的情况,但是我无法得到一个简单的示例可以可靠地表明这一点。但是从理论上讲,从抽象机的规格和描述来看,Acquire/Release并不能阻止这种情况。
如果我们将代码改为:
#![allow(unused)] fn main() { use std::sync::atomic::{AtomicBool, Ordering}; static X: AtomicBool = AtomicBool::new(true); static Y: AtomicBool = AtomicBool::new(true); pub fn example(val: bool) -> bool { let x = X.load(Ordering::SeqCst); X.store(val | x, Ordering::SeqCst); let y = Y.load(Ordering::SeqCst); x || y } }
我们得到了如下汇编代码:
movb example::X.0.0(%rip), %al
testb %al, %al
setne %al
orb %dil, %al
xchgb %al, example::X.0.0(%rip)
movb 1, %al
retq
一个有趣的改变是存储 (store) 操作从简单的加载 (load) 变为特殊的指令xchgb %al, example::X.0.0(%rip)。这是一个原子操作(xchg有一个隐式的lock前缀)。
因为xchg指令是一个locked指令,当内存被获取,并在修改后置为无效,它将会确保在其他核心上的所有缓存行指的是同一块被锁住的内存。此外,它还可以作为内存的 full fence,我们可以在 Intel 开发者手册中得出:
8.2.3.9:加载 (load) 和存储 (store) 不会与锁指令一起重排
内存排序模型可以防止使用较早或较晚的锁指令对加载 (load) 和存储 (store) 进行重排。本节的示例仅说明在加载 (load) 或存储 (store) 之前执行锁指令的情况。读者应该注意,如果在加载 (load) 或存储 (store) 后执行了锁指令,则也将阻止重排。
对于我们的观察者核心这是一个可观测的改变。
顺序一致性 (Sequential Consistency)
如果我们依赖于加载 (load) 操作发生后获取到的某个值,如标记
Release之后,如果我们使用Acquire/Release语义,我们可以在Release操作之前观察到该值确实被改变了。至少在理论上是这样。
使用锁指令可以防止这种情况。因此,除了有
Acquire/Release保证之外,它还确保在这两者之间不会发生任何其他内存操作(读取或写入)。单一的全量修改顺序
在弱有序的 CPU 中,
SeqCst也提供了一些保证,这些保证在默认情况下只能在强有序的 CPU 中得到,其中最重要的是单一全量修改顺序。这意味着如果我们有两个观察者核心,它们将以相同的顺序看到所有的
SeqCst操作。Acquire/Release不会提供这种保证。观察者 a 可以以与观察者 b 不同的顺序看到两个修改(请记住邮箱的类比 (analogy))。假设核心 A 需要使用了基于
Acquire排序的compare_and_swap获取标志 X,而核心 B 在 Y 上执行了相同的操作。两者都执行相同的操作,然后使用Release存储 (store) 将标志的值改回。没有什么可以阻止观察者 A 看到标志 Y 在标志 X 之前变回,观察者 B则相反。
SeqCst阻止了这一切的发生。在强有序的系统中,在其他所有的核心中都可以立即看到每个存储 (
store),因此在这里修改顺序不是一个真正的问题。
SeqCst是最强的内存排序,它的开销也比其他的略高。
你可以在上面看到一个解释了为什么的例子,因为每个原子指令都涉及 CPU 缓存一致性机制并锁定其他缓存中内存位置的开销。在拥有正确程序的情况下,我们所需的此类指令越少,性能就越好。
原子操作
除了上面讨论的内存栏栅之外,在std::sync::atomic模块中使用原子类型还可以访问一些我们通常在 Rust 中看不到的重要 CPU 指令:
从多核 Intel® EM64T 和 IA32 架构实现可扩展的原子锁开始:
用户级锁涉及利用处理器的原子指令来原子地更新存储空间。原子指令涉及利用指令上的锁前缀,并将目标操作数分配给内存地址。以下指令可以在当前的 Intel 处理器上带上一个锁前缀从而可以原子的运行:ADD,ADC,AND,BTC,BTR,BTS,CMPXCHG,CMPXCH8B,DEC,INC,NEG,NOT,OR,SBB,SUB,XOR,XADD 以及 XCHG...
当我们使用一个原子的方法时,如 AtomicUsize 中的fetch_add,编译器实际上会更改它发出的指令,将两个数字在 CPU 上相加。相反,其汇编代码看起来像(一个 AT&T 方言)lock addq ..., ...而不是我们通常期望的addq ..., ...。
原子操作是作为一个不可分割的 (indivisible) 单元执行的一组操作。禁止任何观察者在对其操作时看到任何子操作或获取相同的数据。来自其他核心中针对相同数据的冲突操作 B 必须等待,直到第一个原子操作 A 完成。
让我们举一个增加计数器的例子。这里有三步:
加载数据,修改数据,存储数据。对于每个步骤,另一个核心可能会在我们完成之前加载相同的数据,对其进行修改并将值进行存储。
LOAD NUMBER ---- a competing core can load the same value here ---- INCREASE NUMBER ---- a competing core can increase the same value ---- ---- a competing core can store its data here ---- STORE NUMBER ---- we overwrite that data here ----通常,在存储数据之前,我们希望阻止任何人从加载数据的角度进行观察和干预。这就是原子操作要为我们解决的问题。
原子的一个普通用例是自旋锁 (spin-locks)。一个非常简单(并且 unsafe)的代码如下所示:
#![allow(unused)] fn main() { static LOCKED: AtomicBool = AtomicBool::new(false); static mut COUNTER: usize = 0; pub fn spinlock(inc: usize) { while LOCKED.compare_and_swap(false, true, Ordering::Acquire) {} unsafe { COUNTER += inc }; LOCKED.store(false, Ordering::Release); } }
它的汇编代码如下所示:
#![allow(unused)] fn main() { xorl %eax, %eax lock cmpxchgb %cl, example::LOCKED(%rip) jne .LBB0_1 addq %rdi, example::COUNTER(%rip) movb 0, example::LOCKED(%rip) retq }
lock cmpxchgb %cl, example::LOCKED(%rip)是我们在compare_and_swap中做的原子操作。lock cmpxchgb是一个锁操作;它读取一个标志,并且在条件满足时,将值修改。
在 Intel 开发者手册的第 8.2.5 节中:
多处理器系统中的处理机制可能取决于强有序模型。在这里,程序可以使用诸如 XCHG 指令或 LOCK 前缀之类的锁指令来确保原子的执行对内存的 read-modify-write 操作。锁操作通常类似于 I/O 操作,因为它们需要等待之前所有的指令完成,并且等待所有缓存的写操作在内存中执行(请参阅第 8.1.2 节 “总线锁定”)。
这个锁 (lock) 指令前缀干了什么?
这变得有点技术含量,但是据我所知,对此进行建模的一种简单方法是,当从缓存中获取内存时,它已将缓存行状态设置为Modified。
这样,从核心的 L1 缓存中获取数据的那一刻起,就将其标记为Modified。处理器使用缓存一致性机制确保存在该状态的所有其他缓存都将其更新为Invalid - 即使它们尚未处理其邮箱中的所有消息。
如果消息传递是同步变更的正常方式,则锁指令(以及其他内存排序或序列化指令)涉及一种更昂贵,功能更强大的机制,它可以绕过消息传递,将缓存行锁定在其他缓存中(因此当缓存在运行时,不会发生加载或存储操作),并相应地将其设置为无效,这会迫使缓存从内存中获取更新后的值。
如果你对这一方面感兴趣,请参阅 Intel® 64 和 IA-32 架构软件开发者手册。
在 64 位系统中,缓存行通常是 64 个字节。 这可能因具体的 CPU 而异,但是要考虑的重要一点是,如果内存跨越两条缓存行,则使用的锁机制要昂贵的多,并且可能涉及总线锁定和其他硬件技术。
跨缓存行边界的原子操作在不同的体系结构中具有不同的支持。
结论
你还在这儿吗?如果在的话,请放轻松,今天我们要讲的内容已经结束了。感谢你一直陪伴我并读完了这篇文章,我真诚的希望你可以享受本文并可以从中获得一些收获。
我从根本上相信,即使你在日常生活中从未使用过std::sync::atomic模块,但围绕自己在努力处理的问题建立良好的心智模型对你的个人目的以及编写代码的方式都会有很多好处。
下次再见👋!